python
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import f1_score
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
python
# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False
# 设备配置
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")使用设备: cuda
python
# 参数配置
LATENT_DIM = 10
EPOCHS = 10000
BATCH_SIZE = 32
LR = 0.0002
BETA1 = 0.5
python
# 1. 加载并预处理数据
data = pd.read_csv("e:/python打卡/python60-days-challenge/heart.csv")
X = data.drop('target', axis=1).values
y = data['target'].values
# 只选择有心脏病的样本(target=1)
X_patient = X[y == 1]
scaler = MinMaxScaler(feature_range=(-1, 1))
X_scaled = scaler.fit_transform(X_patient)
# 转换为PyTorch Tensor并创建DataLoader
real_data_tensor = torch.from_numpy(X_scaled).float()
dataset = TensorDataset(real_data_tensor)
dataloader = DataLoader(dataset, batch_size=BATCH_SIZE, shuffle=True)
python
# 2. 构建模型
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.model = nn.Sequential(
nn.Linear(LATENT_DIM, 16),
nn.ReLU(),
nn.Linear(16, 32),
nn.ReLU(),
nn.Linear(32, 13), # 13个特征
nn.Tanh()
)
def forward(self, x):
return self.model(x)
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(13, 32),
nn.LeakyReLU(0.2),
nn.Linear(32, 16),
nn.LeakyReLU(0.2),
nn.Linear(16, 1),
nn.Sigmoid()
)
def forward(self, x):
return self.model(x)
# 实例化模型
generator = Generator().to(device)
discriminator = Discriminator().to(device)
# 损失函数和优化器
criterion = nn.BCELoss()
g_optimizer = optim.Adam(generator.parameters(), lr=LR, betas=(BETA1, 0.999))
d_optimizer = optim.Adam(discriminator.parameters(), lr=LR, betas=(BETA1, 0.999))
python
# 3. 训练循环
print("\n--- 开始训练 ---")
for epoch in range(EPOCHS):
for i, (real_data,) in enumerate(dataloader):
real_data = real_data.to(device)
current_batch_size = real_data.size(0)
# 训练判别器
d_optimizer.zero_grad()
# 真实数据
real_labels = torch.ones(current_batch_size, 1).to(device)
real_output = discriminator(real_data)
d_loss_real = criterion(real_output, real_labels)
# 生成数据
noise = torch.randn(current_batch_size, LATENT_DIM).to(device)
fake_data = generator(noise).detach()
fake_labels = torch.zeros(current_batch_size, 1).to(device)
fake_output = discriminator(fake_data)
d_loss_fake = criterion(fake_output, fake_labels)
d_loss = d_loss_real + d_loss_fake
d_loss.backward()
d_optimizer.step()
# 训练生成器
g_optimizer.zero_grad()
noise = torch.randn(current_batch_size, LATENT_DIM).to(device)
fake_data = generator(noise)
fake_output = discriminator(fake_data)
g_loss = criterion(fake_output, real_labels)
g_loss.backward()
g_optimizer.step()
if (epoch + 1) % 1000 == 0:
print(f"Epoch [{epoch+1}/{EPOCHS}], Discriminator Loss: {d_loss.item():.4f}, Generator Loss: {g_loss.item():.4f}")--- 开始训练 ---
Epoch 1000/10000, Discriminator Loss: 1.9460, Generator Loss: 0.4685
Epoch 2000/10000, Discriminator Loss: 1.1531, Generator Loss: 0.8496
Epoch 3000/10000, Discriminator Loss: 1.2105, Generator Loss: 0.9245
Epoch 4000/10000, Discriminator Loss: 1.3388, Generator Loss: 0.8858
Epoch 5000/10000, Discriminator Loss: 0.8793, Generator Loss: 1.0353
Epoch 6000/10000, Discriminator Loss: 0.8470, Generator Loss: 0.6334
Epoch 7000/10000, Discriminator Loss: 1.0139, Generator Loss: 1.3785
Epoch 8000/10000, Discriminator Loss: 1.2486, Generator Loss: 1.8814
Epoch 9000/10000, Discriminator Loss: 1.0721, Generator Loss: 1.3251
Epoch 10000/10000, Discriminator Loss: 0.7876, Generator Loss: 1.5542
python
# 4. 生成新数据并评估
# 生成样本
generator.eval()
with torch.no_grad():
num_new_samples = len(X_patient) # 生成与原始样本相同数量的数据
noise = torch.randn(num_new_samples, LATENT_DIM).to(device)
generated_data_scaled = generator(noise)
# 转换回原始尺度
generated_data = scaler.inverse_transform(generated_data_scaled.cpu().numpy())
python
# 这里使用一个简单的分类器作为示例
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier(random_state=42)
clf.fit(X_train, y_train)
original_f1 = f1_score(y_test, clf.predict(X_test))
# 使用GAN生成数据后的评估
# 将生成的数据标记为1(心脏病)
generated_y = np.ones(len(generated_data))
# 合并原始数据和生成数据
X_augmented = np.vstack([X_train, generated_data])
y_augmented = np.hstack([y_train, generated_y])
python
# 重新训练
clf.fit(X_augmented, y_augmented)
augmented_f1 = f1_score(y_test, clf.predict(X_test))
print(f"\n原始F1分数: {original_f1:.4f}")
print(f"使用GAN数据增强后F1分数: {augmented_f1:.4f}")原始F1分数: 0.8400
使用GAN数据增强后F1分数: 0.8163
python
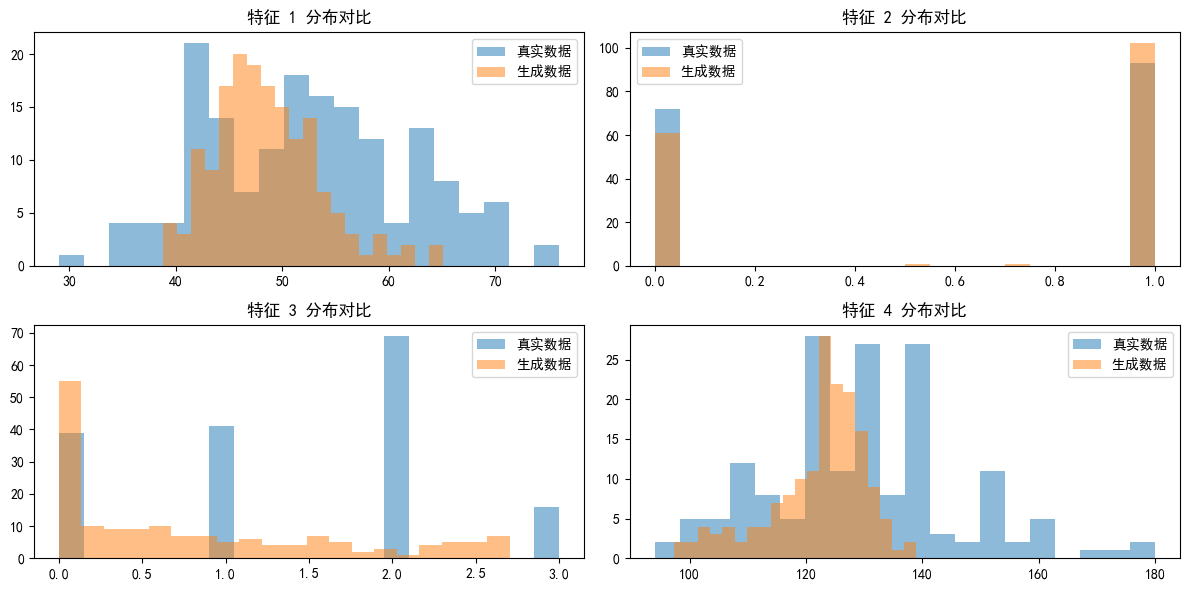
# 6. 可视化部分特征对比
plt.figure(figsize=(12, 6))
for i in range(4): # 只可视化前4个特征
plt.subplot(2, 2, i+1)
plt.hist(X_patient[:, i], bins=20, alpha=0.5, label='真实数据')
plt.hist(generated_data[:, i], bins=20, alpha=0.5, label='生成数据')
plt.title(f'特征 {i+1} 分布对比')
plt.legend()
plt.tight_layout()
plt.show()