A Survey on Open-Set Image Recognition
Abstract
- 开集图像识别(Open-set image recognition,OSR)旨在对测试集中已知类别的样本进行分类,并识别未知类别的样本,在许多实际应用中支持鲁棒的分类器,如自动驾驶、医疗诊断、安全监控等。近年来,开集识别方法得到了越来越多的关注,因为通常很难获得关于开放世界的整体信息用于模型训练。鉴于近两三年来OSR方法的快速发展,本文旨在总结其最新进展。具体来说,我们首先介绍了一个新的分类,在此分类下,我们全面回顾了现有的基于DNN的OSR方法。然后,在标准数据集和交叉数据集下,比较了一些典型的和最新的OSR方法在粗粒度数据集和细粒度数据集上的性能,并给出了比较分析。最后,我们讨论了这个社区中一些开放的问题和可能的未来方向。
- 论文地址:[2312.15571 A Survey on Open-Set Image Recognition](https://arxiv.org/abs/2312.15571)
- OSR 的核心任务是在测试时同时完成已知类样本的分类和未知类样本的识别。与封闭集识别不同,OSR 假设测试集中存在训练时未接触过的新类别,要求模型具备 "拒绝未知" 的能力。例如,在自动驾驶场景中,模型不仅需识别已知的车辆、行人等类别,还需对未训练过的新型障碍物发出警告。
- 核心挑战:语义偏移(Semantic Shift) ,训练集仅包含已知类样本,而测试集包含已知类与未知类,导致模型因深度神经网络(DNN)的 "数据驱动" 特性,将未知类误判为已知类。具体表现为决策边界偏差 :DNN 在封闭集训练时倾向于压缩已知类特征空间,挤占未知类空间。高置信度误判:Softmax 层强制将未知类样本映射到已知类,产生错误高置信度预测。
- OSR 方法体系与关键技术
-
归纳式方法(Inductive Methods),无需测试集参与训练,是 OSR 的主流方案,分为三类:
- 判别模型(Discriminative Models) ,距离 - based 方法 :通过约束特征距离(如 L2 距离、余弦距离)区分已知 / 未知类。例如,PMAL 算法通过原型挖掘策略为每个已知类生成多样原型,增强类内紧凑性和类间区分度。分数校准方法 :改进 Softmax 分数或引入辅助分数(如 EVT-based 分数),通过阈值拒绝未知类。OpenMax 首次将极值理论(EVT)用于建模特征距离的 Weibull 分布,设定拒绝阈值。重建方法:利用自编码器(AE)的重建误差区分样本,已知类重建误差通常低于未知类。C2AE 通过类条件自编码器,结合重建误差与分类分数识别未知类。
- 生成模型(Generative Models) ,GAN-based 方法 :通过生成未知类样本或特征,填充开放空间。OpenGAN 结合生成对抗网络与异常暴露(Outlier Exposure),生成接近真实分布的未知类特征,优化决策边界。AE-based 方法:显式建模已知类分布,如 MoEP-AE 使用指数幂分布混合模型,更灵活地表示复杂特征分布。
- 因果模型(Causal Models),通过引入因果关系解耦特征中的混淆因素。例如,iCausalOSR 利用可逆因果模型,将特征分解为因果表示和非因果噪声,提升未知类识别鲁棒性。
-
转导式方法(Transductive Methods),利用测试集未标注样本辅助训练,缓解分布偏移。例如,IT-OSR-TransP 通过双空间一致采样策略筛选可靠测试样本,并结合条件生成网络增强特征判别性,迭代优化模型。
-
INTRODUCTION
-
由于近年来深度学习技术的发展,闭集图像识别任务已经取得了重大突破。然而,在许多真实场景中,通常存在一些新的对象,它们的类别不同于已知的训练对象类别。现有的闭集识别方法不能有效地处理这种情况,因为它们不可避免地将未知类别的对象图像预测为已知类别之一。这个问题鼓励研究人员关注开集识别技术,该技术旨在对已知类别的图像进行分类,并识别未知类别的图像。闭集识别和开集识别之间的区别如图1所示。
-
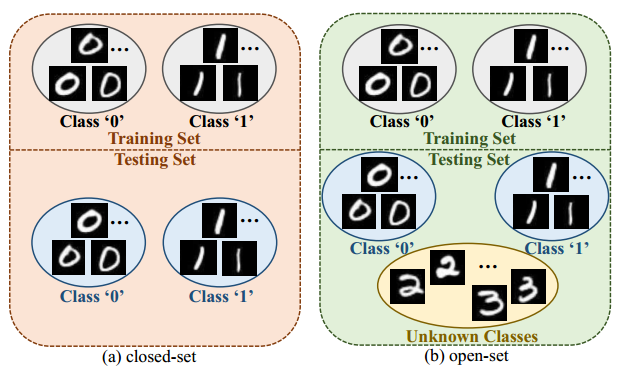
-
图一:闭集识别与开集识别的比较(以MNIST数据集为例):闭集识别模型只需要对与训练图像具有相同标签的测试图像进行分类(例如,类"0"和"1"的图像),而开集识别模型既需要对已知类别的图像进行分类,测试集中的类别图像,其标签不属于训练类别(例如,类别"2"和"3")。
-
-
分布偏移可分为两类:(I)语义偏移,其中训练集和测试集中的标签不同 ,以及(ii)协变量偏移,其中训练样本和测试样本之间的特征分布(如图像样式)不同 。OSR任务中存在的主要挑战是仅包含已知类样本的训练集和包含已知类和未知类样本的测试集之间的语义偏移。由于DNNs(深度神经网络)是数据驱动的模型,并且严重依赖于同分布假设,这种语义转移问题将导致模型以高置信度将未知类别的测试样本预测为已知类别之一。
-
为了解决上述问题,文献中提出了很多 OSR 方法,特别是随着深度学习技术的发展。必须指出的是,据作者所知,在 2021 年之前或前后,关于 OSR 任务的调查报告为数不多。然而,由于 OSR 技术适应现实场景,发展速度非常快,而且最近两三年提出了各种基于 DNN 的新方法,因此总结该技术的最新发展情况将对该领域的研究人员有所帮助。因此,本文对现有的基于 DNN 的 OSR 方法进行了分类。然后,我们对最近的 OSR 作品进行了全面回顾,并对它们的性能进行了比较。此外,我们还讨论了这一领域的一些未决问题和未来可能的发展方向。本文的主要贡献如下:
- 我们对最新的基于 DNN 的 OSR 方法进行了分类和全面评述,提供了该领域的基本技术和最先进的处理方法。
- 为了方便读者了解现有 OSR 方法的共同特点,我们比较分析了两种数据集设置下典型 OSR 方法和最先进 OSR 方法在多个数据集上的模型性能。
- 我们对现有 OSR 方法中的未决问题以及处理 OSR 任务的未来研究方向提出了一些见解。
-
本文的其余部分安排如下。首先,我们在第二节中对现有的基于 DNN 的 OSR 方法提出了一个新的分类标准。然后,我们在第三节中介绍了 OSR 任务中常用的数据集和指标,以及一些基于 DNN 的代表性 OSR 方法的比较结果。接下来,我们将在第四部分介绍 OSR 的一些开放性问题和未来研究方向。最后,我们将在第五部分给出结论。
METHODOLOGIES
- 在本节中,我们首先描述用于对现有的基于DNN的OSR方法进行分类的分类法,如图2所示。接下来,我们回顾基于分类法的基本任务中的OSR方法。这些方法大致可以分为两类:归纳方法和直推方法,分别进行详细介绍。最后,我们还介绍了几个扩展任务,其中我们回顾了相应任务中的一些典型方法 。
-
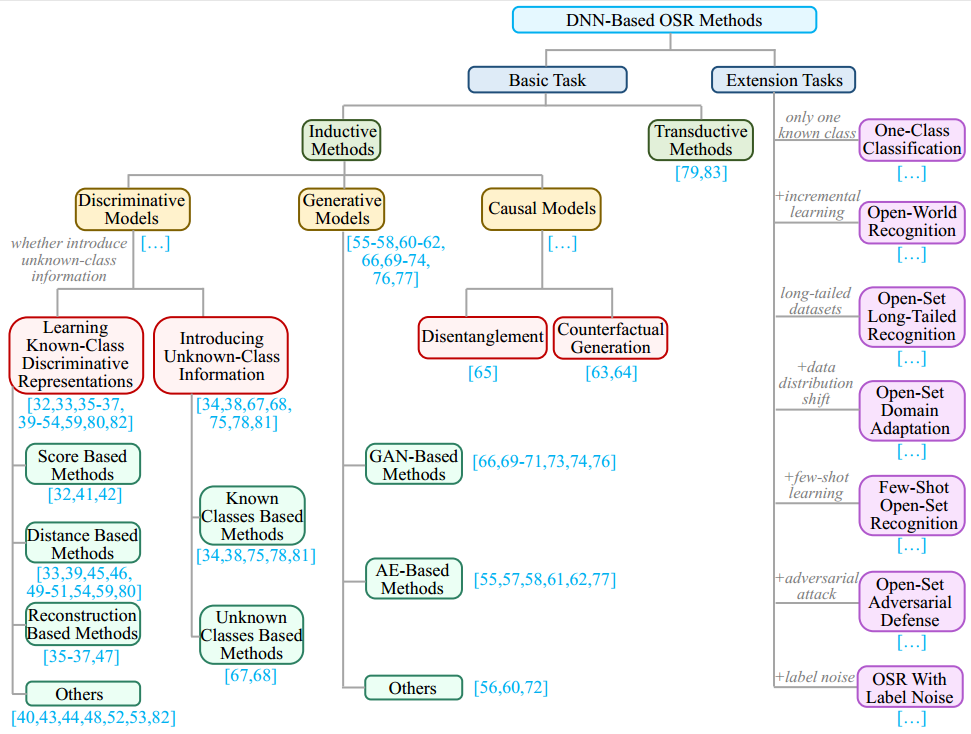
-
图2:现有基于DNN的开集图像识别方法的分类。
-
Taxonomy
- 根据最初的定义,OSR任务可以分为两组:基本的OSR任务,其中模型只需要识别测试集中的已知和未知类别(即,对已知类别的测试样本进行多类别分类,并将未知类别的测试样本与已知类别的测试样本区分开来),以及一些扩展任务,其中模型不仅需要满足基本的OSR任务的要求,还需要处理真实场景中的各种情况。
- 根据测试样本是否用于模型训练,现有的基于DNN的处理基本OSR任务的方法通常可以分为两组:归纳方法和直推方法,如图2所示。这两组方法将在下面的小节中讨论。
Inductive Methods
-
归纳方法认为测试数据在训练阶段是不可用的。大多数现有的OSR方法是归纳方法,根据其主要使用的模型的不同,可以进一步分为三类:1)直接学习决策规则的判别模型,2)学习训练数据分布的生成模型,以及3)将因果关系引入由DNNs懒惰学习的统计模型的因果模型。
- 1)鉴别模型:鉴别OSR模型直接学习鉴别特征表示或分类器,用于识别已知类别样本和未知类别样本。根据是否在训练过程中引入未知类别信息,判别模型可以进一步分为两组:(I)一组模型,旨在仅根据已知类别训练样本来学习已知类别判别表示,以及(ii)另一组模型,旨在引入未知类别信息以减少训练类别和测试类别之间的差异
-
(i) 至于第一类学习已知类别判别表征的方法,现有的基于 DNN 的 OSR 方法大致可分为四类:基于分数的方法 、基于距离的方法、基于重构的方法,以及其他方法。
-
基于分数的方法。在 OSR 任务中,与传统方法相比,DNN 更容易受到未知类别样本的影响,这是因为 softmax 层的封闭集假设,该层通常用于获取分类概率作为指示分数。从 softmax 层输出的属于所有已知类别的每个样本的分数总和为 1,传统分类方法将出现最大分数的指数作为预测标签,因此不会考虑被排除在已知类别之外的未知类别。
-
为了解决这个问题,Bendale 和 Boult 将极值理论(EVT)引入到网络倒数第二层输出的训练样本的激活向量与每个已知类别的平均激活向量之间的距离分布建模中。具体来说,首先计算每个已知类别的上述距离,然后选择最大值的部分距离拟合威布尔分布,作为相应已知类别的极值分布。在测试阶段,根据激活向量与每个已知类别的平均激活向量之间的距离,计算测试样本属于每个已知类别的概率,并将其归入相应类别的极值分布模型中,从而得到已知类别得分。此外,他们还根据已知类得分的加权组合和修正后的权重计算未知类得分。最后,如果测试样本的最大得分出现在已知类得分处,且大于阈值,则被确定为已知类之一;否则,将被归类为未知类。Weibull 分布常用来模拟极值分布,这种方法为后来的 OSR 方法拟合已知类特征分布并使用阈值区分未知类样本和已知类样本铺平了道路。
-
然而,由于计算复杂,许多 OSR 方法逐渐放弃了基于 EVT 的分数,而结合比较阈值的简单 softmax 分数仍被广泛使用。最近,Dai 等人发现,在 OSR 任务中,原始 logit 向量比软最大层额外计算的概率分数表现更好,因为输入 logit 向量的翻译不变性削弱了分数捕捉细粒度信息的能力。随后,Vaze 等人也强调了基于 logit 的分数在提高模型性能方面的有效性。
-
基于 EVT 的分数也可以看作是基于距离的分数之一,因为分数是根据特定实例特征与特定类别原型之间的距离计算的。这种基于距离的分数可用于识别不同的类别,因为模型经过训练后会缩小类内距离,扩大类间距离,这将在下文中详细介绍。
-
-
基于距离的方法。与传统封闭集分类方法的发展过程类似,从分类损失函数的研究中延伸出了一个研究分支,即研究基于距离的损失函数,对特征施加约束,以学习更紧凑、更具区分度的特征。这一研究分支对于 OSR 来说是合理的,因为造成未知类样本识别困难的主要原因之一是已知类特征过度占据了本应留给未知类特征的空间,造成已知类特征和未知类特征之间的混淆。
-
基于距离的损失函数受到 Fisher's criterion 的启发,其目的是最小化类内差异,最大化类间差异。这种约束特征表征的思想现已形成一个研究方向,即表征学习。Hassen 和 Chan 应用了一种简单的表示学习方法来处理 OSR 任务。他们将 logit 向量作为输入图像在不同空间(即 logit 空间)的特征表示,并通过每批训练更新每个已知类别的平均向量。然后,结合交叉熵分类损失(传统封闭集分类任务中常用的损失)和成对损失项来训练网络,成对损失项用于限制每个训练样本与相应的特定类别均值向量之间的 L2 距离(即欧氏距离)变小,成对损失项用于限制不同特定类别均值向量之间的欧氏距离变大。Jia 和 Chan将损失扩展为表征损失,提取网络倒数第二层输出的激活向量,形成表征矩阵,用于在训练阶段强调幅度最大的特征和幅度最小的特征,从而学习更具区分性的特征表征。
-
然而,固定的原型在约束特征鉴别方面的作用有限。因此,Xia等人提出了一个约束损失项,用于控制这些特征原型的空间位置,使其更具鉴别力。与已知类特征倾向于占据与未知类特征相同的特征空间中心部分的先前方法相比,该方法将已知类的原型限制在特征空间的边缘区域,通过约束原型到特征空间中心距离的方差来实现,从而缓解了已知类特征与未知类特征的混淆。考虑到以前的方法中每个已知类都有一个原型表示,忽略了每个类内的特征多样性,Lu等人在优化特征空间之前设计了一个原型挖掘策略,为每个已知类挖掘高质量和多样性的原型。
-
对比损失作为自监督任务中通过数据增强来约束来自同一图像或不同图像的特征对之间距离的有效工具,近年来受到越来越多的关注。Kodama等人应用监督对比度损失来约束来自相同已知类或不同已知类的特征对,类似地,Xu等人也利用监督对比学习来提高学习的特征表示的质量。
-
此外,一些OSR方法旨在设计具有角度的特征表示或分类器,以改善类间相似性和类间差异。Park等人提出学习发散角度表示,这改善了全局方向特征变化。Cevikalp和Saglamlar 引入了准线性多面体圆锥分类器,其将已知类区域约束为 L1 或 L2球。
-
-
基于重构的方法。在OSR任务中存在一种观点,即重构对于模型的可分辨性是有价值的,因为已知类样本通常具有比模型从未见过的未知类样本更小的重构误差。遵循这一点,一些OSR方法利用重构网络、重构样本或重构误差中的潜在特征来提高模型的可分辨性。
-
Yoshihashi等人 除了使用网络预测进行分类外,还使用了重建网络中的潜在特征表示。他们提出了一种特殊的自动编码器,即深度分层重建网络,用于提取每层的潜在特征。在训练阶段,通过联合使用分类损失和重建损失来训练网络,其中分类损失使用基于EVT的分数。在测试阶段,分类分数用于识别已知和未知类别的样本。
-
Oza 和 Patel 将自动编码器的整个训练过程分为两步。首先,他们通过传统的交叉熵分类损失训练编码器和与潜在特征连接的分类器。然后,固定编码器和分类器的权重,并通过精心设计的成对重建损失训练解码器。在这一步,输入到解码器的特征图由两部分控制:通过线性调制编码特征和条件向量,从而获得原始/重建图像对。解码器被训练为最大化标签不匹配对的重建误差,同时最小化标签匹配对的重建误差。在测试阶段,对测试图像的编码特征进行全类条件向量线性调制,得到所有已知类对应的重构误差,并与阈值进行比较,确定预测标签。
-
Huang et al 集成了原型学习和重构,他们提出重构特定于类的语义特征映射,而不是特定于实例的图像,以提高模型的语义区分度。他们为潜在空间中的每个已知类建模了一个自动编码器,该方法用于重建骨干编码器从输入图像中提取的特征图。该方法将智能重构误差映射作为logit,通过softmax层和pooling层将其转换为传统的logit向量,在训练阶段,用分类损失约束logit向量进行训练,在测试阶段,利用所有类自编码器对应的重构误差进行辨识.
-
Perera等人发现了一种利用重建信息的新途径,其中使用了重建图像。他们首先训练生成模型(例如vanilla自动编码器,条件自动编码器等)以获得已知类别的重建图像,然后通过将重建图像作为学习分类器的新维度来扩展原始图像。
-
-
一些方法旨在从数据增强、集体决策、多任务学习、梯度、空间变换、层次注意力中挖掘有区别的信息,甚至在视觉心理物理学的帮助下。
-
Perera 和 Patel 发现极端的几何变换可能会导致不同的特征表示,因此,他们通过并行网络分支传递与变换图像对应的特征,并使用多数投票进行最终预测。
-
随着网络骨干的发展,视觉 Transformer 由于其更好的性能而得到越来越广泛的应用。Azizmalayeri 和 Rohban 经验观察到,以视觉Transformer为骨干并使用softmax概率进行分类可以获得比其他OSR方法更好的性能。此外,他们还发现,精心选择的数据增强而不是标准的训练增强有助于提高模型的可辨别性。
-
此外,Jang 和 Kim 提出集成多个 one-vs-rest 网络作为特征提取器,并将多个决策组合起来用于对输入图像的最终决策得分进行建模。Oza和Patel 提出了一种OSR的多任务学习方法,该方法同时训练潜在特征空间中的分类损失和自动编码器末端的重建损失,Lee和AlRegib 利用基于梯度的特征表示进行识别,因为梯度包含关于模型需要更新多少才能正确表示已知类样本的信息。Baghbaderani等人提出利用三个空间之间的变换(即,原始图像空间、潜在特征空间和丰度空间),用于利用更多的判别信息。Liu等人提出了一种用于约束特征空间的定向优化策略和一种用于捕获特征空间中的全局依赖关系的分层空间注意机制,进一步提高了特征的可区分性。Sun等人提出了一种用于学习细粒度已知类特征的分层注意力网络,其逐渐聚合每个分层注意特征图中的分层注意特征和上下文特征。Huang等人 OSR任务对计算机视觉算法具有挑战性,而对人类来说很容易,这一事实受到启发,他们将 psychophysical loss 和相应的网络架构纳入深度学习,这可以支持反应时间测量来模拟人类感知。
-
(ii)对于第二类将未知类信息引入模型训练,现有的基于DNN的OSR方法根据未知类信息来源的不同,大致可以分为两类:利用来自已知类样本的未知类信息的方法,以及引入来自离群类样本的未知类信息的方法的一个例子。
-
已知类利用。第一组OSR方法陷入瓶颈,因为仅旨在学习更具区分性的已知类特征或分类器不足以处理模型将在测试集中遇到的未知类。解决这个问题,一些方法旨在通过混合,增强,分裂等基于已知类图像或特征利用未知类信息。
-
Mixup是一种数据增强策略,它线性混合来自两个不同类别的图像和相应的标签。Vanilla mixup 通过使用线性插值在输入空间中产生新样本,而流形mixup 在潜在特征空间中产生新特征。Zhou等通过流形mixup产生新特征来学习未知类别的数据占位符,作为一个额外的类,与已知类样本一起沿着用于训练模型。通过生成未知类特征,约束已知类特征更加紧凑和具有区分力,从而缓解OSR任务的过度占用问题。此外,他们还提出学习分类器占位符,它代表了一个区分未知类样本和已知类样本的类特定阈值。具体来说,他们在分类器的输出向量中为未知类提供了一个额外的维度,作为区分已知类和未知类的可学习阈值,这是通过将额外维度的值限制为所有维度中的第二大来进行的,因为可以区分目标类和非目标类的可学习阈值被认为具有区分已知类和未知类的能力。
-
此外,Wang等人提出了一种新的度量,通过关于已知类和未知类特征的成对公式化来耦合闭集和开集性能,并将该公式化转化为最小化相应风险的优化问题。类似于,他们通过流形混合来生成未知类特征,Jiang等人通过混合它们来生成高质量的负图像,这被证明可以降低封闭空间结构风险和开放空间风险。
-
-
除了 mixup 之外,一些方法使用基于增强的相似性学习,类内分裂或多类交互来基于已知类数据挖掘未知类信息 。Esmaeilpour等人采用相似性损失来鼓励模型学习如何区分已知类别和未知类别的样本,其中未知类别的图像是通过分布移位数据增强生成的。具体来说,他们对模型训练进行了两个步骤。在第一步,通过随机旋转原始图像90°的倍数来生成未知类别的图像。在第二步中,一个分类模型进行了训练与已知类的训练图像和生成的 unknownclass 图像,并施加两个损失:一个交叉熵损失分类已知类的图像和二进制交叉熵损失学习集群的已知类和unknownclass图像通过相似性监督。
-
Schlachter等人利用已知类别训练图像中的未知类别信息。具体来说,他们通过闭集分类器将训练图像分成典型子集和非典型子集。然后,非典型子集作为未知类数据,作为第(C + 1)个样本加入训练集,(其中C是已知类的数量)类,用于训练(C + 1)类分类模型。这两种方法对于构建未知类数据相对直接和简单。为了捕获更精确的未知类信息,一些研究者探索了基于已知类特征学习未知类特征的可学习策略。
-
Chen等人定义了用于捕获每个已知类别的未知类别信息的 discriminative reciprocal points,包含从其他已知类别提取的图像特征和一组可学习的特征作为未知类别特征。在训练过程中,从一个已知类中提取的特征被推到远离相应已知类的倒数点,从而学习到的已知类特征位于特征空间的外围,而未知类特征则被限制在特征空间中心的有界区域内。在这种情况下,未知空间被缩小并有界,这可以防止分类网络对未知类别的测试样本产生高置信度。
-
离群类介绍。利用已知类中未知类信息的方法仍然受到训练集的限制。有时,当训练集的分布明显偏离测试集的分布时,或者当数据量很小时,原始训练集不足以支持模型探索有效的未知类信息。在这种情况下,一些方法试图将离群数据引入模型训练。
-
离群数据的使用可以追溯到对象检测任务,其中分类网络也由指示在提议中没有感兴趣的对象的背景类来训练。离群类样本的引入可以防止网络对未知类样本输出过度自信的错误预测 。Dhamija等人借鉴了这一思想,他们将NIST字母数据集中某些类别的数字图像作为已知类别样本,而将NIST字母的其余类别图像作为未知类别样本进行测试,并将CIFAR10 和MNIST 的图像作为异常样本。他们首先发现未知类别的特征通常比已知类别的特征具有更低的特征量和更高的软最大熵。基于这种默认观察,他们设计了基于熵的损失和基于量级的损失,以约束模型训练中的已知类样本和离群样本,从而增加这种分离,这提高了模型对训练中不可用的未知类样本的鲁棒性。
-
这种在模型训练中引入离群类样本的操作也被用于分布外(OOD)检测任务,其中模型拒绝未知类样本的能力更受关注。然而,在开集方法或OOD检测方法中,已知类样本被归类到离群类相关损失的一个组中,这可能会影响OSR任务中的闭集分类性能。此外,这些方法在不同数据集上的不同已知类和离群类之间采用相同的间隔,限制了开集识别性能。
-
为了解决上述问题,Cho和Choo 基于线性判别分析(LDA)的原理,而不是通常使用的SoftMax分类器,选择了多个基于距离的分类器。此外,他们设计了一种类别包含损失,鼓励每个离群样本远离最近的类别超球分类器,这进一步提高了模型的可分辨性。他们从ImageNet数据集中选择图像作为离群类样本。除了上面介绍的鉴别方法,生成OSR方法也采用离群点暴露来增加训练集,这将在下面的段落中介绍。
-
2)生成模型:随着生成模型的发展,越来越多的OSR方法注重采用生成学习技术来提高模型的可分辨性。生成OSR模型 主要从已知类样本中学习分布,在此基础上建立如何识别未知类样本和分类已知类样本的判别标准。根据使用的具体生成模型,这些方法可以进一步分为三组:基于生成对抗网络(GAN)的方法,基于自动编码器(AE)的方法,以及其他方法。
-
基于GAN方法。考虑到GANs能够生成各种新样本,一些方法利用GANs生成未知类样本来填充关于开放空间的缺失信息。他们通过对抗性训练来隐式地对数据分布建模,而不是通过拟合特定的参数化分布来显式地建模。大多数基于GAN的方法仅基于已知类训练样本生成未知类样本或特征,并且寻求关于未知类样本/特征的位置的不同假设以及利用所生成的未知类样本/特征的不同策略。
-
Ge等人假设未知类别样本位于已知类别分布的混合分布中。他们修改了条件GAN的训练过程,其中混合了几个先前已知的类分布。基于生成的未知类样本,他们通过提供关于未知类的显式概率估计来扩展OpenMax 。
-
Neal等人假设未知类别样本位于特征空间中任何已知类别分布之外,但同时与像素空间中的已知类别图像相似。每个未知类别样本是基于编码器-解码器从已知类别训练图像生成的。具体地,它们最小化输入已知类别图像和生成图像之间的重构误差,以保证像素空间中的相似性,同时最小化生成图像被分类到相应已知类别的分类概率。然后,将生成的图像作为一个附加类来扩充训练集,并用于训练(C + 1)类(其中C是已知类的数量)分类器。
-
Jo等人假设未知类特征位于已知类的相邻特征空间中。因此,他们将GAN中的生成与边缘去噪自动编码器相结合,以模拟远离每个已知类别的分布。在生成未知类别特征的情况下,他们训练了一个C类分类模型,该模型具有附加的基于熵的正则化损失,以鼓励模型对未知类别特征具有高不确定性,这收紧了已知类别的决策边界。
-
Chen等人 扩展了他们以前的判别性OSR方法,基于对抗性训练策略生成混淆样本,以提高模型的判别力。具体而言,生成的特征被约束为欺骗鉴别器,同时它们也被约束为通过最大化分类器的输出熵来接近倒数点。此时,生成的混淆特征位于已知类特征和倒易点之间的边界。在特征生成之后,他们为训练分类模型设计了三个损失,包括两个对比损失,这两个损失都最大化每个倒易点与其对应的已知类原型的距离,并将距离限制在可学习的范围内,以降低经验分类风险和限制开放空间风险,以及一个基于距离的熵损失,约束生成的混淆特征位于倒易点附近,以进一步增强已知类和未知类之间的区分。
-
将已知类特征推到特征空间的边缘,而将未知类特征限制在特征空间的中心,夏等人生成了未知类特征,这些特征位于已知类原型附近,但在已知类原型中心的可学习距离之外。他们还引入了对抗运动属性,使距离边缘的对抗运动成为可能,这进一步降低了经验风险和开放空间风险。
-
然而,上述方法通常会产生决策边界之外的未知类样本,这些样本容易被区分,并且忽略了对开集识别性能更重要的"硬否定"样本。为了解决这个问题,Moon等人从分类器的角度考虑了生成未知类别样本的不同难度。他们训练了一个多组卷积分类网络和一个复制的对应物,其层由基于多级知识提取的相同预定义标准分离,以生成难度或难度级别的特征,并与GAN连接以生成不同难度级别的多个特征。当最终训练分类器时,生成的未知类别特征被赋予统一的概率作为标签。
-
考虑到有时离群数据集是可用的,一些判别OSR方法引入了离群样本来模拟未知类别样本。然而,这种模型对不同的未知类样本表现出较差的泛化能力,因为训练中使用的离群样本不能完全覆盖开放空间。为了解决这个问题,Kong和Ramanan 提出了OpenGAN,它基于原始已知类训练样本和引入的离群类样本训练了一个与C-way分类器相结合的GAN,并在GAN中采用鉴别器来区分未知类样本和已知类样本。模型选择也是基于离群验证样本来操作的,即使离群验证样本是稀疏的或有偏差的,这也被发现是有效的。
-
基于 AE 的方法。如前所述,一些基于重建的区别性OSR方法基于从自动编码器输出的差异重建误差来区分未知类样本和已知类样本。近年来,一些生成OSR方法已经利用自动编码器来显式地对已知类分布建模,使得如果未知类样本不属于被建模的已知类分布之一,则未知类样本可以被拒绝,并且已知类样本也可以根据它属于哪个已知类分布来分类。
-
作为一种典型的自动编码器,变分自动编码器(VAE) 已经广泛应用于许多视觉任务,它将已知类样本建模为标准高斯分布。然而,使用VAE将所有已知类别的特征分布建模为高斯分布会破坏两个不同已知类别之间的可区分性 。孙等将VAE扩展为基于概率梯形架构的分类识别自动编码器。具体地,编码器将每个图像编码成高斯分布的两个分布参数(即,平均值和标准偏差)。由学习分布采样的潜在特征被强制逼近相应已知类别的高斯分布,其标准偏差是单位矩阵,均值从独热标签映射。在推理阶段,未知类别图像不仅可以根据其偏差分布来检测,还可以根据其较高的重建误差来检测。随后,他们还以类似的方式将对立自动编码器(AAE) 扩展到另一个类别区分自动编码器。
-
受上述方法的启发,Guo等人用胶囊网络取代了CNN主干,其中网络中的每个潜在神经元输出一个矢量而不是一个标量,这样编码的潜在特征可以表示更多样的信息。他们没有像中那样使用额外的分类器来使潜在特征具有区分性,而是利用具有余量的对比损失来迫使编码特征位于相应的已知类别区域,并保持不同的已知类别特征彼此远离。
-
然而,将每个已知类特征分布建模为单个高斯分布不能很好地表示类内差异。为了解决这个问题,Li和Yang 假设每个已知类特征分布遵循高斯混合分布,它可以通过不同的高斯分量来表示类内差异。他们嵌入了神经高斯混合模型进入自动编码器,将潜在特征映射到边缘分布,该分布被称为双分布,因为可以从中推导出两个相反的概率:i)潜在特征属于已知类的概率,ii)潜在特征属于未知类的概率,训练模型编码的已知类特征或未知类特征都可以形成一个分布峰值,因此,可以根据潜在空间中的分布峰值来识别测试样本,一旦测试样本靠近已知类峰值,它将被潜在空间中的已知类分类器进一步分类。
-
类似地,Cao等人也将每个已知类的特征分布建模为高斯混合,但他们直接修改了高斯混合VAE ,而不是嵌入神经高斯混合模型。结合条件VAE 和原型学习,将每个已知类的特征分布约束为多个高斯分布,也可以将其视为高斯混合分布,考虑到一些复杂的特征分布不能用单高斯或高斯混合来表示,(例如,亚高斯和超高斯),Sun等人基于新的重新参数化策略将指数幂分布的混合引入网络,其通过指数幂分布的不一致混合来对来自不同已知类别的特征分布进行建模。
-
一般来说,这组OSR方法的主要研究方向是寻求更有效的显式表示已知类的特征分布,以及研究如何更好地利用重构误差来提高特征的可分辨性,其中第二个动机与基于重构的判别OSR方法相一致。
-
其他。除了基于GAN和基于AE的方法之外,还存在一些OSR方法,它们采用其他生成模型(例如,基于流的模型),或者仅采用编码器来建模特征分布,或者生成用于转移学习的实例权重。
-
基于流的生成模型生成质量与GAN相当的图像或特征,但由于其可逆架构,可以显式地对训练分布进行建模,该模型还将潜在空间中的训练类特征分布建模为标准高斯分布,正如VAE中所做的那样。Zhang et al 将典型的流网络Resflow 与潜在空间中的已知类分类器相结合。Resflow用作检测未知类的密度估计器,而潜在分类器用于保持已知类分类精度。
-
考虑到基于AE的方法中的图像级重建将考虑所有图像像素,其中许多像素与类别无关甚至容易引起误导,Sun等人去除了自动编码器中的解码器,并使用Kullback-Leibler(KL)发散损失来约束潜在特征,使得每个已知类别的特征分布被建模为单个高斯分布。他们设计了一种多尺度互信息最大化策略,用于建立输入图像与其潜在特征之间的相关性,这进一步提高了特征的可区分性。
-
另一种创新的生成式OSR方法是学习用于生成新样本的中间向量,而不是直接生成图像或特征,这是由Fang等人提出的。受迁移学习理论和可能的近似正确理论的启发,他们将已知类别的样本与辅助域中的样本对齐通过这种实例加权策略,可以利用实例权值检测未知类样本。
-
3)因果模型:无论是上面提到的判别式模型还是生成式模型,它们都容易陷入懒惰学习的陷阱,因为一旦模型寻找到一组可以最小化损失函数的权重参数,这种懒惰的学习必然会导致模型学习到容易学习但相对脆弱的相关关系。为了解决这个问题,针对这个问题,人们提出了一些因果模型,旨在从训练数据中寻找因果关系,从而以两种方式减轻非因果OSR方法学习的特征中的混淆因素:从高度耦合的相关特征中解开鲁棒表示,并基于反事实生成生成更可靠的已知类样本。
- 因果解缠。Yang提出了一种用于开放集识别的可逆因果模型,该模型由可逆编码器(此处使用 i-RevNet )和类函数组成,前者用于将图像编码为特征,后者用于提供属于每个已知类的编码特征的分布先验。与将特征分布建模为显式固定分布的基于 AE 的生成式 OSR 方法不同,这里的类函数是以结构因果模型(SCM) 的形式构建的,每个结构因果模型都是一个有向无环图。在训练阶段,编码特征受限于匹配相应的先验类函数。在推理阶段,与大多数基于 AE 的生成式 OSR 方法的推理策略类似,根据样本属于这些类函数的概率对样本进行分类/检测。
- 反事实生成。由于生成模型对已知类特征分布具有很强的建模能力,而训练样本在某些情况下可能不足,因此生成式 OSR 方法成为处理 OSR 任务的主流。然而,这些方法大多直接根据单点类标签生成样本或特征,忽略了渗透到不同已知类中的非因果混杂因素,导致生成的样本或特征存在偏差。为了解决这个问题,一些方法采用了 counterfactual generation来生成更可靠的样本或特征。
-
Yue等人73提出了一种基于 TF-VAEGAN 的反事实生成方法来处理OSR任务,该方法由一个将图像编码为潜在特征的编码器、一个根据潜在特征和所提供的单击标签重建/生成反事实图像的解码器/生成器以及一个用于区分真实图像(真)和反事实图像(假)的判别器组成。他们用三种损失来训练网络:β-VAE 损失,用于将潜在特征分布建模为各向同性高斯分布;对比损失,用于最小化(或最大化)输入图像与其基于匹配(或不匹配)标签重建的图像之间的重建误差;以及 GAN 损失,用于鼓励生成的图像欺骗判别器。在推理阶段,将测试图像与其根据 C 个单次热已知类别标签生成的 C 个反事实图像之间的最小距离与检测未知类别图像的阈值进行比较。如果距离小于阈值,测试图像就会被预测为与最小距离相对应的已知类别。Zhou 等人在处理开放集合成孔径雷达(SAR)图像目标识别任务时也采用了类似的方法,结果仍然优于其他 OSR 方法。
Transductive Methods
-
转导式方法考虑到测试样本在训练阶段就已存在,因此在模型训练中同时使用有标记的训练集和无标记的测试集。正如在其他视觉任务(如零/少样本学习和域适应)中证明的那样,转导式学习能有效缓解分布偏移问题,这也启发了两种转导式 OSR 方法。
-
Yang等人首次提出了转导式OSR方法。首先,他们根据基于分数的策略从测试样本中筛选出一些类外样本,同时用基线分类模型对这些样本进行伪标记。然后,利用原始训练样本和过滤出的伪标签测试样本共同更新模型。
-
尽管这种直推式学习方法提高了模型的性能,但仍然存在两个问题:(1)样本选择问题:如何选择伪标签更可靠的测试样本;(ii)已知/未知类别不平衡问题:已知类别样本(包含原始训练样本和被伪标记为已知类别的选定测试样本)的数量通常大于未知类别样本(仅包含被伪标记为未知类别的选定测试样本)的数量。
-
为了解决这两个问题,Sun和Dong 在他们提出的迭代转换OSR框架中设计了一种采样策略和生成方法。具体来说,他们设计了一种用于样本选择的双空间一致性采样策略,该策略将不可靠的测试样本从候选样本中移除,这些样本在输出空间中分配的伪标签与其在特征空间中的大多数邻居不一致。此外,他们设计了一个用于特征生成的条件生成网络,在网络中增加了一个区分已知类特征和未知类特征的附加权值,以提高生成特征的可分辨性;然后,基于他们设计的采样和生成方法,提出了一个迭代的直推OSR框架,该框架迭代地进行样本选择、特征生成和模型更新。
Extension Tasks
-
除了基本的OSR任务外,我们还介绍了一些扩展任务。在现实中,OSR任务部署在复杂多变的环境中。这里,我们简要回顾了OSR任务7个典型扩展场景中的一些代表性方法:1)只有一个已知类可用的一类分类,2)训练数据递增的开放世界识别,3)开集长尾识别,其中数据分布呈现长尾分布,4)开集域自适应,其中数据分布也存在,5)少样本开集识别,其中训练数据非常充足,6)开集对抗防御,其中输入图像受到对抗攻击,以及7)具有标签噪声的开集识别,其中标签是有噪声的或不准确的。
-
1)One-Class Classification: 在常见场景下,训练集中存在不止一个已知类,训练模型能够区分不同的已知类也在一定程度上提高了模型区分未知类的能力。在极端场景下,只有一个已知类可用,称为 One-Class Classification,其中依赖于提升已知类别特征可辨别性来改进OSR性能的一些辨别性OSR方法可能失败。
- 为了解决这个问题,一些判别方法将单类支持向量机嵌入到损失函数中,或者应用特定的数据变换来捕获已知类的唯一几何结构信息。然而,由于在模型训练中无法获得负样本,考虑到生成式模型能够模拟已知类数据的分布,生成式方法被广泛应用于一类分类任务,该方法根据未知类样本的分布与已知类样本分布的偏差来识别未知类样本。此外,重建误差仍然可以用来区分未知类样本和已知类样本。
-
2)开放世界识别: 在常见场景中,数据集通常是静态和固定的,OSR模型仅在一个时间从现有数据集学习。然而,现实场景中的数据通常是动态呈现的,并且可以周期性地甚至连续地获得新的数据。每次重新训练模型的成本都很高。在这样的应用需求下,一系列开放世界的识别方法被提出,这些方法旨在不断地检测和添加遇到的新类别。
- Bendale和Boult 首先提出了开放世界识别的概念,也将最近类均值分类器扩展到了开放世界识别任务中。Cao等人提出了一种渐进式直推方法,该方法选择未标记的新样本,并根据聚类结果为其提供伪标记,以更新特征原型。Wu等人回答了用于预测和利用新类别样本的图表示和学习,其中图网络用于根据特征级图推断从新数据提取的特征的嵌入,预测网络用于预测新特征的伪标签。通常,聚类和直推学习是处理开放世界识别任务的两种常用工具。最近类均值可以被认为是一种聚类策略,因为它将样本拉向其最近的邻居。图形网络也是直推式学习的常用工具。通过直推式学习,模型可以逐步利用新样本,即使它们的标签不可用。通过聚类,可以用相对较小的成本更新模型。
-
3)开集长尾识别:OSR模型在现实场景中会遇到的另一个问题是数据具有长尾分布,该模型会偏好样本数量占优势的多数类,而忽略样本明显不足的少数类。长尾问题是阶级不平衡问题的一个极端例子。有一些简单的策略来减轻模型对多数类的偏差,例如,数据重采样技术(包括从多数类的下采样和从少数类的过采样)和损失重加权(增加/减少少数/多数类样本的损失权重)。
- 近年来,开集长尾识别任务受到越来越多的关注,如何在开集环境下的少数类中挖掘有效信息成为该任务的关键问题。刘等 首先形式化定义了开集长尾识别任务,并基于动态元嵌入机制对其进行处理。元嵌入机制将多数类视觉特征与少数类视觉特征相关联,使模型对少数类具有鲁棒性,并基于记忆库中的视觉特征动态校准特征范数,以支持网格识别。蔡等人提出了一种分布敏感损失,当约束类内距离最小化时,该损失为少数类样本提供了更大的权重。此外,他们设计了一种基于距离的度量标准,根据特征到聚类的距离进行识别。
-
4)开集域适配:如第节所述。第一,分布移位既包括普遍存在于OSR任务中的语义移位,也包括协变量移位。在Open set domain adaptation中首次提出的开集域适应任务中,语义移位和协变量移位同时存在。换句话说,未知类别的样本将存在于测试集中,此外,训练集和测试集中的已知类别的样本位于不同的领域(即,分别是源领域和目标领域)。大多数现有的闭集域自适应方法旨在根据源域中已标记的已知类别样本以及目标域中未标记(或部分标记)的样本,将整个目标域与源域对齐。然而,在开集域适应任务中,目标域中的未知类样本将与源域中的已知类样本不正确地对齐,这将损害已知类和未知类之间的可区分性。
- 为了解决这个问题,Busto和Gall 在将目标域中的图像分配给源域中的一些类别时,添加了隐式离群点检测机制,因此不属于已知类别的图像可以在分配中被丢弃。为了将目标域中的未知类样本与目标域中的已知类样本分开,Saito等人在特征提取器和(C + 1)类分类器之间采用了对抗训练,其中训练分类器不仅对已知类源特征进行分类,而且根据第(C + 1)类的概率区分已知类和未知类,同时训练特征提取器来欺骗分类器。Liu等人从目标域中的已知类样本和源域中的已知类样本之间的差距比目标域中的未知类样本和源域中的已知类样本之间的差距小得多的观察中得到启发。他们设计了一种从粗到细的加权机制,该机制迭代地操作两个步骤:多二进制分类器训练步骤,该步骤测量目标图像与每个源已知类的相似性,以及二进制分类器学习步骤,该步骤基于通过与源类的高/低相似性选择的已知/未知类目标样本来训练二进制分类器。
-
5)少量开集识别:常见的OSR任务部署在大规模数据集上。然而,在一些极端现实的场景中,每个已知类别中的训练样本数量非常少,这样的任务称为fewshot开集识别任务。
- 为了完成这项任务,刘等人【Few-shot open-set recognition using meta-learning】将闭集少样本学习模型扩展到了开集环境。他们通过基于开集距离的损失项将一些伪未知样本添加到模型训练中。Jeong等人根据未知类样本与转换原型的较大差异来识别未知类样本。王等提出了一个基于能量的模型,其中偏离少数已知类别样本的类别特征或像素特征的样本被赋予更大的能量分数。
-
6)开集对抗性防御:开集对抗性防御任务结合了开集识别任务和对抗性防御任务,开集识别任务的目的是在测试过程中对已知类别进行分类并识别未知类别,对抗性防御任务的目的是使网络能够防御不易察觉的对抗性干扰图像。
- 为了处理这项任务,Shao等人提出了一个开集防御网络,它由一个带去噪层的编码器和一个用于学习无噪声特征的分类器组成。此外,他们结合了一个解码器来重建干净的图像,增加了一个自我监督损失,以提高特征的可辨性,以及一个干净-敌对的相互学习机制,其中另一个分类器(处理干净的图像)与原始分类器(处理敌对的图像)相互学习,以促进特征去噪。
-
7)带有标签噪声的OSR:在常见的OSR场景中,该模型严重依赖干净的标签。然而,向大规模数据集提供标签成本很高且容易出错,并且真实数据不可避免地包含有噪声/不正确的标签。
- Wang等人提出了一种迭代学习框架,该框架迭代地检测噪声标签,扩大干净标签和噪声标签之间的差异,并应用重新加权模块来鼓励模型从干净标签而不是噪声标签学习更多。Sachideva等人利用了主观逻辑损失,这可以在闭集噪声样本上产生较高的损失,而在开集样本上产生较低的损失。与上述方法不同,Wei等人从经验上证明了开集含噪标签甚至有助于提高模型对含噪标签的鲁棒性,并将带有动态含噪标签的开集样本作为正则项引入模型训练。
DATASETS, METRICS, AND COMPARISON
Datasets
-
本节将介绍 OSR 任务中常用的多类数据集,包括粗粒度数据集和细粒度数据集。与粗粒度数据集相比,细粒度数据集中的图像通常具有较高的类间相似性和较低的类内相似性。因此,在处理细粒度数据集时需要进行一些详细的处理操作。
-
为了模拟开放集场景,有些类被选为已知类,有些类被选为未知类。根据类的来源,数据部署可分为两类:标准数据集设置(已知类和未知类来自同一数据集)和跨数据集设置(已知类和未知类来自不同数据集)。
-
粗粒度数据集: 在标准数据集设置下使用了五个数据集:
-
MNIST: 该数据集包含 7 万张 10 级手写数字图像(28×28),其中包括 6 万张训练图像和 1 万张测试图像。随机抽取 6 个类别作为已知类别,其余 4 个类别作为未知类别。
-
SVHN:该数据集的图像来自街景门牌号码(SVHN)数据集,其中包含 99289 个 10 类街景门牌号码(32×32),包括 73257 个训练图像和 26032 个测试图像。同样,选择 6 个类别作为已知类别,其余 4 个类别作为未知类别。
-
CIFAR10:该数据集的图像来自 CIFAR10 数据集,其中包含 60000 张 10 类自然物体图像(32×32),包括 50000 张训练图像和 10000 张测试图像。同样,选择 6 个类别作为已知类别,其余 4 个类别作为未知类别。
-
CIFAR+10/+50:该数据集的图像来自 CIFAR10 和 CIFAR100 数据集。与 CIFAR10 类似,CIFAR100 包含 60000 张 100 类自然物体图像(32×32),其中包括 50000 张训练图像和 10000 张测试图像。10 个已知类固定为 CIFAR10 数据集中的 10 个类,CIFAR+10 或 CIFAR+50 从 CIFAR100 数据集中随机抽取 10 或 50 个类作为未知类。
-
TinyImageNet 该数据集是 ImageNet 数据集的一个 200 类子集,包含 120000 张自然物体图像(64×64),其中包括 100000 张训练图像、10000 张评估图像和 10000 张测试图像。其中 20 个类别为已知类别,其余 180 个类别为未知类别。
-
在跨数据集设置下,10-class CIFAR10 数据集作为已知类数据集, 收集的四个数据集分别作为四个未知类数据集: ImageNet-crop、ImageNet-resize、LSUN-crop 和 LSUN-resize,它们是从 200 类别 TingImageNet 和 10 类别 LSUN 中裁剪或调整大小的图像。
-
-
细粒度数据集: 在跨数据集设置下,使用了三个语义转换数据集,分别包含鸟类、汽车和飞机等不同子类的高分辨率图像:
-
CUB:该数据集的图像来自加州理工学院-加州大学伯克利分校鸟类(CUB)数据集(CUB-200-2011),其中包含 11788 张带标签和属性标记的 200 类鸟类图像,包括 5994 张训练图像和 5794 张测试图像,图像大小各异。其中随机抽取 100 个类别作为已知类别,其余 100 个类别则根据每个未知类别与整个已知类别的属性相似度分为三组未知类别:"易 "组包含 32 个与已知类别区别较大的类别,"难 "组包含 34 个与已知类别较为相似的类别,"中 "组包含其余 34 个类别。
-
FGVC-飞机: 在该数据集中,图像来自 FGVC-Aircraft-2013b 数据集,该数据集同样包含 10000 张带标签和属性标记的 100 级汽车图像,其中包括 6667 张训练图像和 3333 张测试图像,图像大小各不相同。随机选取 50 个类别作为已知类别,其余 50 个类别也被分为与 CUB 类似的三个难度组:20 个 "简单 "组、13 个 "困难 "组和 17 个 "中等 "组。
-
斯坦福汽车 该数据集的图像来自 Stanford-Cars 数据集,其中包含 16185 张带标签的 196 级飞机图像,包括 8144 张训练图像和 8041 张测试图像(360×240)。前 98 个类别被选为已知类别,其余 98 个类别被选为未知类别。
-
在跨数据集设置下,将 FGVC-Aircraft 中包含上述选定的 50 个已知类别的子集作为已知类别数据集,而将 200 个类别的 CUB 和 196 个类别的 Stanford-Cars 数据集分别作为两个未知类别数据集: 飞机-CUB、飞机-斯坦福-汽车。
-
Metrics
-
在此,我们介绍 OSR 任务中常用的评估指标。OSR 任务的目标不仅是准确接受多类已知类测试样本并对其进行分类,而且还需要对测试样本进行分类、同时也能正确剔除未知类别的测试样本。根据上述目标评价模型性能,ACC 和 AUROC 是标准数据集设置下最常用的两个指标,适用于粗粒度和细粒度图像。此外,在跨数据集设置下,宏-F1 分数也被用于衡量多类开放集分类性能。OSCRReducing network agnostophobia也被用于同时测量细粒度数据集上的闭集分类性能和开集剔除性能。四种评价指标的详情如下:
-
ACC: Top-1 准确率(ACC)是封闭集识别任务中常用的指标。在 OSR 任务中,该指标只考虑已知类测试样本。其计算方法是正确分类的已知类测试样本占整个已知类测试样本的比例。
-
AUROC:接收者操作特征曲线(ROC)下面积(AUROC)是一个与阈值无关的指标。在 OSR 任务中,该指标将所有已知类别视为一类,而将所有未知类别视为另一类,并测量不同阈值设置下的二元分类性能。AUROC 显示了模型能在多大程度上对两个类别进行分类。ROC 曲线以假阳性率 (FPR) 为横坐标,真阳性率 (TPR) 为纵坐标。TPR 和 FPR 的计算公式分别为
-
T P R = T P T P + F N F P R = F P F P + T N TPR=\frac{TP}{TP+FN}\\ FPR=\frac{FP}{FP+TN} TPR=TP+FNTPFPR=FP+TNFP
-
其中,TP 和 FN 表示已知类别测试样本中被正确接受为已知类别和被错误剔除为未知类别的样本数,FP 和 TN 表示未知类别测试样本中被错误接受为已知类别和被正确剔除为未知类别的样本数。
-
宏-F1: 宏-F1 分数是一个取决于阈值的指标,用于衡量多类分类性能。在 OSR 任务中,该指标将所有未知类别视为 C 个已知类别的附加类别,即第 (C + 1)- 个类别。它是根据平均精确度 Pmacro 和平均召回率 Rmacro 计算得出的,这两个指标的计算公式分别为
-
P m a c r o = 1 C + 1 ∑ i = 1 C + 1 T P i T P i + F P i ( 3 ) R m a c r o = 1 C + 1 ∑ i = 1 C + 1 T P i T P i + F N i ( 3 ) P_{macro} =\frac 1 {C + 1}\sum ^{C+1}{i=1}\frac {TP_i} {TP_i + FP_i} (3)\\ R{macro} =\frac 1 {C + 1}\sum ^{C+1}_{i=1}\frac {TP_i} {TP_i + FN_i} (3) Pmacro=C+11i=1∑C+1TPi+FPiTPi(3)Rmacro=C+11i=1∑C+1TPi+FNiTPi(3)
-
其中 TPi , TNi , FPi , 和 FNi 分别表示第 i 个类别(i∈ {1, 2, ..., C + 1})的真阳性、真阴性、假阳性和假阴性。因此,宏 F1 分数的计算公式为
-
F 1 _ m a c r o = 2 × P m a c r o × R m a c r o P m a c r o + R m a c r o ( 5 ) F_{1\macro} = 2 ×\frac {P{macro} × R_{macro}} {P_{macro} + R_{macro}} (5) F1_macro=2×Pmacro+RmacroPmacro×Rmacro(5)
-
OSCR:开放集分类率(Open-Set Classification Rate,OSCR) 也是一个与阈值无关的指标,可同时衡量已知类测试样本的 C 类分类性能,以及区分未知类和已知类的二元分类性能。与 AUROC 类似,它是另一条曲线下的面积,以正确分类率(CCR)为横坐标,新定义的 FPR 为纵坐标。这里,CCR 表示已知类别测试样本中被正确接受为已知类别以及被正确分类的比例,而新定义的 FPR 表示未知类别测试样本中被错误接受为已知类别的比例。OSCR 越大,表明不仅在接受已知类样本并将其分类方面,而且在拒绝未知类样本方面都有更好的表现。
-
Comparison
-
在本小节中,我们将提供在上述两种数据集设置下,一些具有代表性的 OSR 方法在粗粒度数据集和细粒度数据集上的比较结果。
-
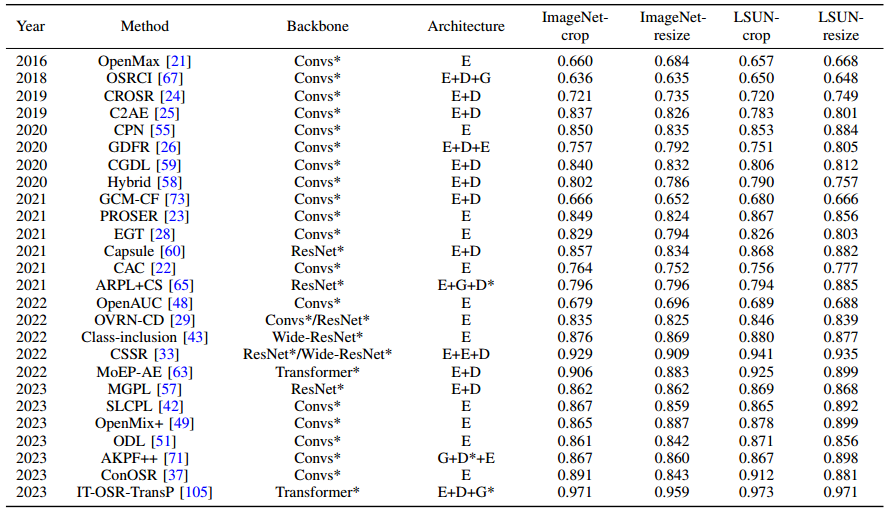
粗粒度数据集比较: 表 I 和表 II 报告了 34 种代表性 OSR 方法的 ACC 和 AUROC 结果,这些方法都是在标准数据集设置下在粗粒度数据集上进行评估的,其中比较方法的结果引用了其原始论文或引用其的论文,并按照 TinyImageNet 上的年份和 AUROC 指标进行了排序。此外,表 III 还报告了跨数据集设置下相应的宏 F1 分数,其中某些方法的结果因未在任何地方报告而缺失。为保持一致性,宏 F1 结果也按照上述策略进行排序。
-
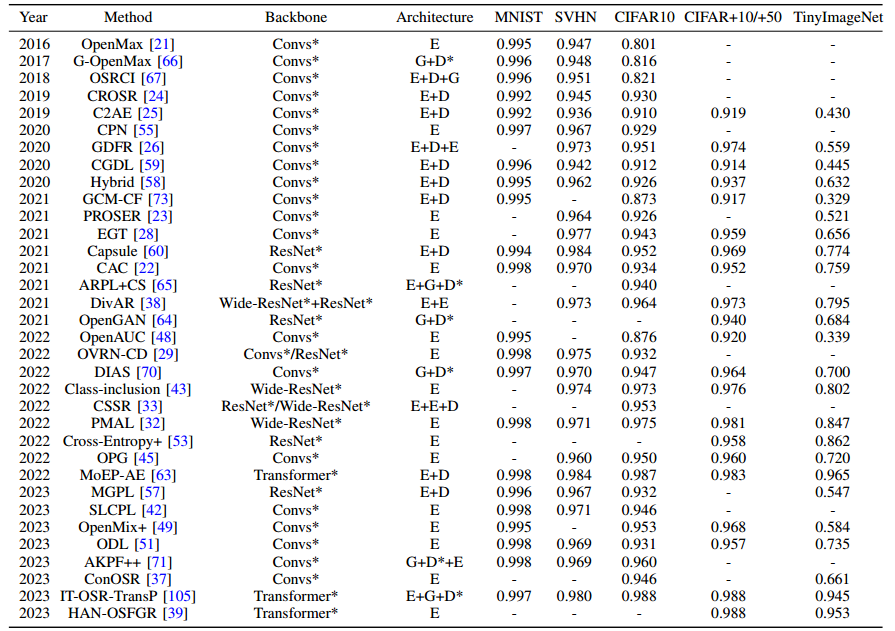
-
表 I: 标准数据集设置下粗粒度数据集的 ACC 结果。
-
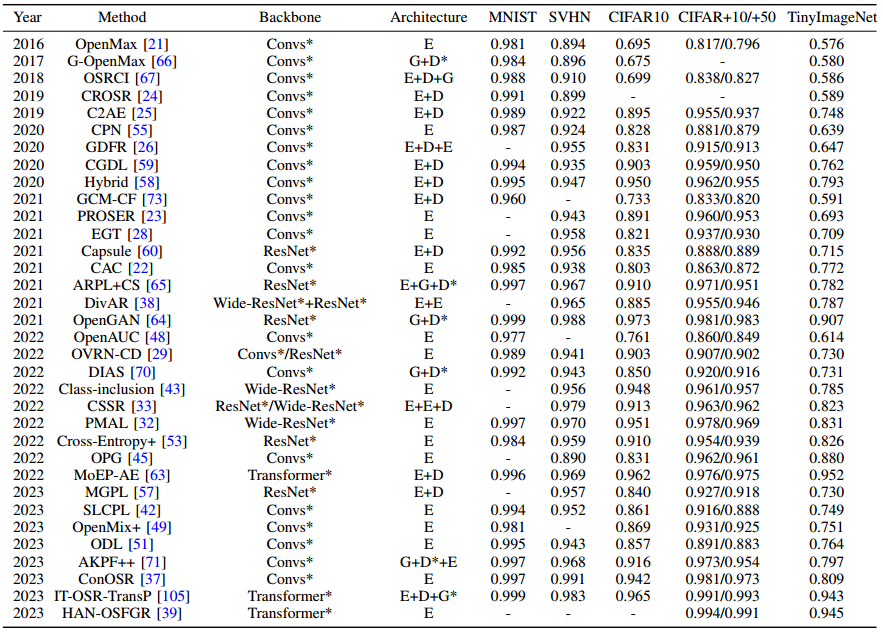
-
表 II:标准数据集设置下粗粒度数据集的 AUROC 结果。
-
-
表 III:跨数据集设置下粗粒度数据集的 Macro-F1 结果。
-
-
为了更好地进行比较,还列出了骨干和网络架构。"Convs"、'ResNet'、"Wide-ResNet "和 "Transformer "分别表示相应的方法是基于普通 CNN、ResNets、Wide-ResNets 和视觉转换器开发的。由于不同的方法通常采用不同的层配置,尽管使用的是同一组骨干,我们用 "*"表示涵盖不同的配置。此外,骨干网项中的 "+'和'/"分别表示该方法结合了两个网络作为骨干网,以及在不同数据集上采用了不同的骨干网。架构项中的 "E"、'G'、"D "和 "D*"分别表示编码器、生成器、解码器和鉴别器。
-
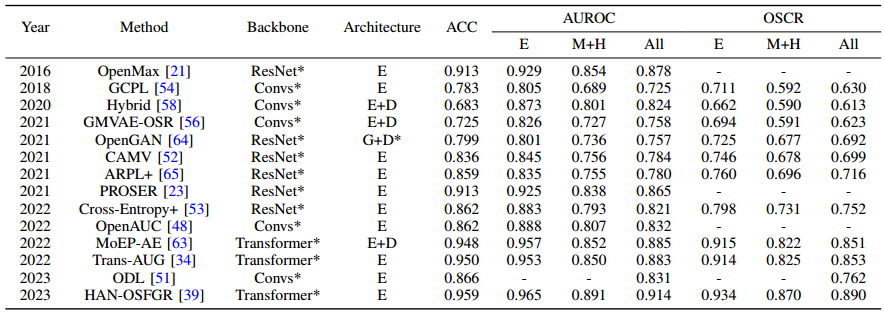
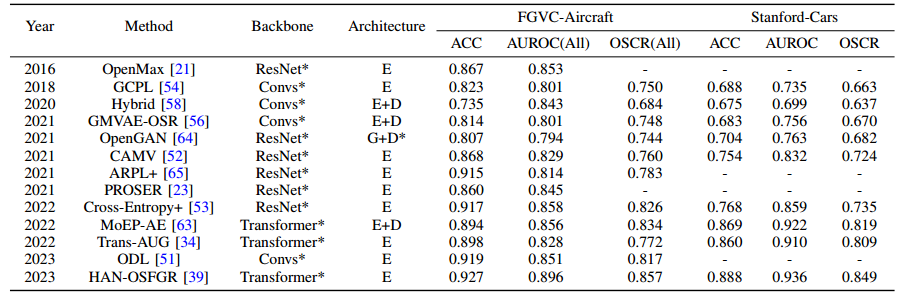
在细粒度数据集上的比较: 表 IV 和表 V 报告了一些 OSR 方法在标准数据集设置下对 CUB、FGVC-飞机和 Stanford-汽车的 ACC、AUROC 和 OSCR 结果。这些表格中的结果按年份和 CUB 的 OSCR 指标排序。E"、"M "和 "H "分别表示 '简单'、"中等 "和 "困难 "难度级别。"中等 "和 "困难 "两组合并报告,而不是在 CUB 上单独报告。
-
-
表 IV:标准数据集设置下细粒度 CUB 数据集的 ACC、AUROC 和 OSCR 结果。
-
-
表 5:标准数据集设置下细粒度 FGVC-飞机和斯坦福-汽车数据集的 ACC、AUROC 和 OSCR 结果。
-
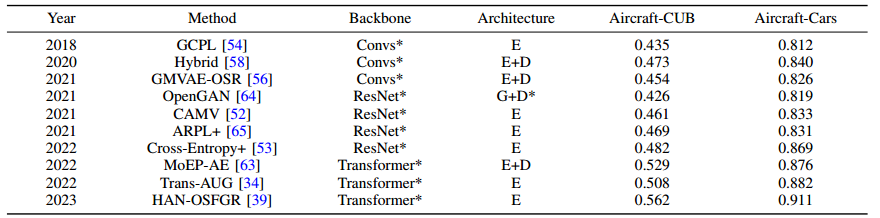
-
表 VI:在跨数据集设置下,对 Aircraft-CUB 和 Aircraft-Cars 这两个细粒度数据集的 Macro-F1 结果。
-
-
比较结果总结与分析: 总之,根据上述比较,可以从这些表格中看出 8 点:
-
从表一和表二可以看出,大多数比较方法,无论是采用更强大的骨干网还是采用更简单的架构,在大多数情况下都优于采用更轻量级骨干网的方法,这表明强大的骨干网有助于提高模型的可辨别性。虽然更强大的骨干网通常会导致更高的模型复杂度,从而限制了架构的复杂性,但它仍然可以与一些精心设计的模块相结合,如 H A N − O S F G R 中的注意机制、 C r o s s − E n t r o p y + 中的综合数据增强、 C S S R 和 M o E P A E 中的轻量级重建、 P M A L 中的原型约束、 C l a s s − i n c l u s i o n 中的离群值暴露、 O p e n G A N 和 I T − O S R − T r a n s P 中的特征生成等、以进一步提高模型性能 \textcolor{red}{虽然更强大的骨干网通常会导致更高的模型复杂度,从而限制了架构的复杂性,但它仍然可以与一些精心设计的模块相结合,如 HAN-OSFGR 中的注意机制、Cross-Entropy+ 中的综合数据增强、CSSR 和 MoEPAE 中的轻量级重建、PMAL 中的原型约束、Class-inclusion 中的离群值暴露、OpenGAN 和 IT-OSR-TransP 中的特征生成等、 以进一步提高模型性能} 虽然更强大的骨干网通常会导致更高的模型复杂度,从而限制了架构的复杂性,但它仍然可以与一些精心设计的模块相结合,如HAN−OSFGR中的注意机制、Cross−Entropy+中的综合数据增强、CSSR和MoEPAE中的轻量级重建、PMAL中的原型约束、Class−inclusion中的离群值暴露、OpenGAN和IT−OSR−TransP中的特征生成等、以进一步提高模型性能。
-
从表一和表二可以看出,如果一种方法的 ACC 值较高,则其 AUROC 值通常也较高。换句话说,在大多数比较方法中,封闭集分类性能越好,开放集检测性能也就越好。不过,在成对比较时也有很多反例,即 AUROC 明显较高对应的 ACC 相近甚至明显较低,而 ACC 较好对应的 AUROC 较差。这主要是因为一些未知类样本与一些已知类样本相似,将这些未知类样本从已知类中分离出来会损害已知类的分类准确性。因此,如何在开放集检测性能和封闭集分类性能之间取得更好的平衡是 OSR 界的一个未决问题。
-
从表一至表三可以看出,交叉数据集下的结果普遍低于标准数据集下的结果,主要原因有两个:(i) 除了语义偏移外,训练样本与未知类测试样本之间还存在协变量偏移,这可能更容易造成类混淆。(ii) 宏 F1 指标同时考虑了封闭集分类性能和开放集检测性能,模型不仅需要正确分类已知类样本,还需要根据阈值将其识别为已知类。
-
从表 I 至表 III 可以看出,最近的 OSR 方法已经实现了接近饱和的性能,即接近或高于 95%,尤其是在 Transformer 骨干网方面。因此,有必要在更大规模、更高分辨率和更困难的数据集上进行评估。
-
从表 IV 中可以看出,"中等 "和 "较难 "组的结果普遍低于 "简单 "组,这主要是因为较难组中的未知类图像通常与已知类图像具有相似的外观,只是在某些细粒度属性上有所不同。此外,最近的模型性能在 "简单 "组中也达到或接近饱和,识别更难的未知类样本主要会影响整体性能。因此,如何区分和利用较难识别的未知类样本成为提高模型在细粒度数据集上可识别性的关键。对细粒度信息进行更有效的获取和更细致的处理,或许有助于区分较难的未知类样本,然后再利用一些无监督技术进行模型训练。
-
从表四和表五可以看出,使用 ResNet* 主干网的方法通常比使用 Convs* 主干网的方法表现更好,而使用 Transformer* 主干网的方法通常比使用 ResNet* 主干网的方法表现更好。这主要是因为 ResNet 中的残差连接加深了网络,从而增强了网络学习更复杂特征的能力,而变换器中的多重自关注操作则有助于捕捉图像中语义对象的更细粒度关注。
-
从表 VI 可以看出,飞机-CUB 的结果明显低于飞机-汽车的结果。这主要是因为 FGVC-Aircraft 与 CUB 之间的分布偏移大于 FGVC-Aircraft 与 Stanford-Cars 之间的分布偏移。结合前面的观察,我们可以发现,无论是过大的分布偏移(如 CUB 上未知类样本与 FGVC-Aircraft 上已知类样本之间的分布),还是过小的分布偏移(如未知类样本中的 "中+难 "组与已知类样本之间的细微差别),都会造成类混淆。由于分布偏移问题是 OSR 界固有的问题,因此迁移学习可能有助于缓解分布偏移问题。
-
从表 I-VI 可以看出,在标准数据集设置下和粗粒度数据集上,生成式 OSR 方法的性能普遍优于判别式 OSR 方法,这主要是因为生成式模型的学习不仅基于输入和输出之间的关系,还基于数据的内部分布结构。然而,无论是在跨数据集设置下还是在细粒度数据集上,这种现象都很难被观察到,这主要是因为在跨数据集设置下,学习到的基于语义的分布无法适应协变量的变化,而在细粒度数据集上,从相似样本中学习到的分布也会相似。因此,无论是在跨数据集环境下,还是在细粒度数据集上,采用各种策略提高特征可区分性的判别方法都会更加有效。
-
OPEN ISSUES AND FUTURE RESEARCH DIRECTIONS
Open Issues
-
在这里,我们提出了OSR任务中的一些开放问题。
-
1)语义转换问题:OSR任务中的固有问题是语义转移问题,在测试集中会遇到一些新类别的图像。由于深度学习模型是数据驱动的模型,因此仅基于已知类别训练模型会使模型更倾向于已知类别,即模型会错误地将未知类别的样本预测为已知类别之一。现有的OSR方法大多是归纳方法,假设在模型训练中只有已知类的样本,虽然它们追求对已知类更具区分性的表示,希望未知类的样本可以根据它们与已知类的偏差来识别,由于不存在真实的未知类,已知类和未知类之间的决策边界的偏差仍然存在。然而,学习已经在其他任务和OSR任务中证明了它的有效性。到目前为止,只有两种转导OSR方法。此外,在现有的转导OSR方法中也存在一些开放的子问题,如第II.B节所提到的。因此,如何有效地利用未标记的测试样本仍然值得研究,特别是难以识别的测试样本。
-
2)分类已知类和识别未知类之间的一致性问题:OSR任务旨在同时分类已知类样本和识别未知类样本。一个好的OSR模型需要同时产生高的闭集分类精度和已知类和未知类之间的高差异。然而,当特征空间中的未知类样本与已知类样本混淆时,这两个目标有时可能不一致,在这种情况下,将这些未知类样本与已知类样本分离可能会损害不同已知类之间的区分度,这种现象在闭集识别任务中也可以观察到,其中一部分类别的准确性差异可能导致其他类别之间的混淆,因此,另一个开放的问题是:如何实现一致的更好的性能或实现已知类别分类和未知类别识别之间的更好的平衡?挖掘和利用难以识别的混淆样本可能是解决这一问题的一种方法。
-
3)区分已知类别和未知类别的阈值:由于在模型训练中未知类样本通常不可用,因此大多数现有的OSR方法首先训练C路分类器,并通过将基于C类的识别分数与阈值进行比较来识别未知类样本。阈值的选择对于开集识别性能至关重要,现有的OSR方法大多根据经验选择阈值进行识别,Zhou等人提出了一种基于可学习策略的类特定阈值,为阈值的进一步研究奠定了基础。
Future Research Directions
- 在这里,我们提供了一些未来的研究方向,以促进未来的工作在处理OSR任务。
- 1)人脑机制启发的开集识别:在神经科学领域,人类大脑和动物大脑被证明具有快速识别新类别的能力。一些识别机制可以启发未来的OSR方法。一些现有的OSR方法已经提供了实例。Yang等人设计了类-具体特征原型的灵感来自于人类大脑中不同类别的抽象记忆。Sun等人受大脑中时间注意机制的启发,对分层注意特征进行时间聚合,因此从大脑中的识别机制借鉴是一个很有前途的未来研究方向。
- 2)多模态大模型引导开集识别:随着数据量的快速膨胀和硬件性能的提高,深度神经网络正在进入多模态大模型时代,最近,很多在多模态大规模数据集上预训练的多模态大模型已经在辅助许多视觉任务方面展示了其泛化能力,例如少样本和零样本图像识别任务。预训练的大模型存储了关于开放世界的丰富先验信息,这是处理OSR任务的有前途的辅助工具。使用大模型的一个简单方法是调整它们的提示,其提供关于输入数据的上下文或参数信息,以帮助大型模型更好地理解和处理特定任务。
- 受预训练大型模型令人印象深刻的生成能力的鼓舞,Qu等人合作了几个大型模型(ChatGPT ,DALL-E ,CLIP 和DINO )以免训练的方式利用丰富的内隐知识,以减少对虚假判别特征的依赖。他们的方法分两个阶段操作。在一个阶段,在第二阶段,基于生成的图像和 CLIP 和 DINO 的已知类和虚拟未知类的扩展列表的两个对齐来推断测试图像。虽然该方法直观且不需要训练,它在处理OSR任务时是有效的。
- 为了进一步利用大模型,Liao等人将开放词和大模型上的快速调整结合起来处理OSR任务。开放词取自WordNet ,而不是通过询问ChatGPT生成,可学习提示提高了模型对下游任务的适应性。此外,对于较大规模数据集上的XXX,他们首先对较少类的组执行多个独立的分组提示调优,然后基于最优子提示进行预测。此外,他们提出了新的基线,以便与基于大模型的OSR方法进行公平比较,如何更好地利用OSR的开放性,基于新的提示和调优策略来处理OSR任务的世界预训练大型模型仍然值得研究。
CONCLUSION
- 本文对开集图像识别进行了全面的综述,首先对现有的基于DNN的方法进行了系统的分类,并对多数据集和两种数据集部署下的典型和最先进的OSR方法进行了比较和分析。此外,我们讨论了一些开放的问题和未来的发展方向在这个社区。
学习提示提高了模型对下游任务的适应性。此外,对于较大规模数据集上的XXX,他们首先对较少类的组执行多个独立的分组提示调优,然后基于最优子提示进行预测。此外,他们提出了新的基线,以便与基于大模型的OSR方法进行公平比较,如何更好地利用OSR的开放性,基于新的提示和调优策略来处理OSR任务的世界预训练大型模型仍然值得研究。
CONCLUSION
-
本文对开集图像识别进行了全面的综述,首先对现有的基于DNN的方法进行了系统的分类,并对多数据集和两种数据集部署下的典型和最先进的OSR方法进行了比较和分析。此外,我们讨论了一些开放的问题和未来的发展方向在这个社区。
-
小样本开放集图像识别(Few-Shot OSR)的挑战与解决方案,数据稀缺性 :每个已知类仅有少量样本,难以学习稳健的特征表示,且未知类完全未见过,导致模型泛化能力不足。双重任务冲突:需同时解决小样本分类的 "快速适应" 和开放集识别的 "未知拒绝",传统方法易在两者间失衡。