测测你的牌:基于 MobileNetV2 的车牌内容检测
代码详见:https://github.com/xiaozhou-alt/Car_Plate_Recognition
文章目录
- [测测你的牌:基于 MobileNetV2 的车牌内容检测](#测测你的牌:基于 MobileNetV2 的车牌内容检测)
- 一、项目介绍
- 二、文件夹结构
- 三、数据集介绍
-
-
- [1. 数据集结构](#1. 数据集结构)
- [2. 关键文件说明](#2. 关键文件说明)
-
- (1)plate\_data.yaml
- (2)plate\_info.csv
- [(3)YOLO 标签文件(labels 目录下)](#(3)YOLO 标签文件(labels 目录下))
- [3. 数据要求](#3. 数据要求)
-
- [四、MobileNet 模型介绍](#四、MobileNet 模型介绍)
-
- [1. 深度可分离卷积(Depthwise Separable Convolution)------ 轻量化特征提取的核心](#1. 深度可分离卷积(Depthwise Separable Convolution)—— 轻量化特征提取的核心)
- [2. 倒残差结构(Inverted Residual Block)------ 精准保留字符特征的关键](#2. 倒残差结构(Inverted Residual Block)—— 精准保留字符特征的关键)
- [3. 线性瓶颈(Linear Bottleneck)------ 避免特征丢失的"保护罩"](#3. 线性瓶颈(Linear Bottleneck)—— 避免特征丢失的“保护罩”)
- [4. 项目定制化适配:MobileNetV2与LSTM的协同设计](#4. 项目定制化适配:MobileNetV2与LSTM的协同设计)
- 五、项目实现
-
- [1. 车牌字符集定义](#1. 车牌字符集定义)
- [2. 自定义数据集类](#2. 自定义数据集类)
- [3. 车牌识别模型定义](#3. 车牌识别模型定义)
-
- [3.1 初始化方法(\\init\\):模型结构定义](#3.1 初始化方法(__init__):模型结构定义)
- [3.2 前向传播方法(forward):数据流向与特征处理](#3.2 前向传播方法(forward):数据流向与特征处理)
- [4. 核心功能封装类(PlateRecognizer)](#4. 核心功能封装类(PlateRecognizer))
-
- [4.1 初始化方法(\\init\\):参数配置与组件初始化](#4.1 初始化方法(__init__):参数配置与组件初始化)
- [4.2 车牌检测与裁剪功能](#4.2 车牌检测与裁剪功能)
- 六、结果展示
-
- (1)车牌内容检测
- [(2)UI 界面展示](#(2)UI 界面展示)
- (3)保存的结果文件
一、项目介绍
本项目是一套 端到端的中国车牌识别解决方案,通过 "车牌位置检测 + 车牌内容识别" 两阶段流程,实现从原始车辆图片到车牌号码的自动化识别。系统具备高准确性、易用性和可扩展性,适用于停车场管理、交通违章监控、车辆出入登记等场景。
本文为项目介绍的第二篇文章,实现对已经裁剪完毕的车牌内容检测的算法说明。
关于车牌裁剪和车牌位置矫正请看项目介绍的第一篇文章:车牌检测还手动裁?基于 YOLOv8 的车牌位置检测与裁剪
核心功能
-
自动中文字体适配:内置多平台中文字体自动加载与下载逻辑,解决中文显示乱码问题(支持 SimHei、WenQuanYi Micro Hei 等字体)
-
车牌位置精准检测:基于 YOLOv8 模型,实现复杂场景下的车牌定位,支持倾斜车牌矫正(通过顶点坐标透视变换 + 边界框旋转矫正)
-
车牌内容识别:采用 MobileNetV2+LSTM + 注意力机制的组合架构,针对中国 7 位车牌(省份简称 + 字母数字)优化,支持字符级准确率分析
-
可视化 UI 界面:基于 PyQt5 开发图形化界面,支持图片选择、一键识别、结果保存,直观展示原始图片、检测边界框、裁剪车牌及识别结果
-
完善的训练机制:
-
检测模型:支持早停机制(patience)、最佳模型自动保存、mAP 指标评估
-
识别模型:支持位置权重调整(针对低准确率字符位置加强训练)、数据增强(旋转、仿射、颜色抖动等)、训练历史可视化(损失曲线、准确率曲线)
技术栈
-
深度学习框架:PyTorch
-
检测模型:YOLOv8(Ultralytics)
-
识别模型:MobileNetV2 + LSTM + 注意力机制
-
可视化:Matplotlib、OpenCV
-
UI 框架:PyQt5
-
数据处理:Pandas、NumPy、YAML
二、文件夹结构
c
Car_Plate_Recognition/
├── README.md
├── demo.mp4 # 演示视频文件
├── demo.py # 主程序文件,包含GUI界面
├── predict.py # 车牌识别预测脚本
├── preprocess.py # 数据预处理脚本
├── requirements.txt
├── train_location.py # 车辆位置检测训练脚本
├── train_plate.py # 车牌识别训练脚本
├── data/
├── plate_data.yaml # 数据配置文件
├── plate_info.csv # 车牌信息表(含图片名、车牌号、顶点坐标)
├── images/
├── train/ # 训练集图片(.jpg/.jpeg/.png)
└── val/ # 验证集图片(.jpg/.jpeg/.png)
└── labels/ # YOLO格式标签文件(与图片同名,.txt格式)
├── train/
└── val/
├── log/ # 日志目录
├── output/
├── model/ # 模型文件目录
├── pic/ # 图片输出目录
├── recognition-output/ # 识别输出目录
└── training_history_mobilenet.json # MobileNet训练历史数据
└── yolo_train-output/ # YOLO训练输出目录
├── license_plate_detection/ # 车牌检测相关文件
├── runs/ # 训练运行记录
└── test_samples_output/ # 测试样本输出
└── test/ # 测试图片目录三、数据集介绍
数据源于:CCPD2019|车牌识别数据集|计算机视觉数据集
数据集或可由:ccpd-preprocess
经我处理完毕的(使用ccpd原数据集中base下的 20 % 20\% 20% 部分,经过裁剪处理,可以直接训练识别):Plate_Recognition
1. 数据集结构
需按照以下目录结构组织数据集,核心包含图片文件、标签文件、配置文件、车牌信息表四部分:
makefile
data/
├── plate_data.yaml # 数据配置文件
├── plate_info.csv # 车牌信息表(含图片名、车牌号、顶点坐标)
├── images/
├── train/ # 训练集图片(.jpg/.jpeg/.png)
└── val/ # 验证集图片(.jpg/.jpeg/.png)
└── labels/ # YOLO格式标签文件(与图片同名,.txt格式)
├── train/
└── val/2. 关键文件说明
(1)plate_data.yaml
用于配置数据集路径、类别信息,格式如下:
makefile
train: ./images/train # 训练集图片路径(相对/绝对路径均可)
val: ./images/val # 验证集图片路径
nc: 1 # 类别数量(仅车牌1类)
names: [license_plate] # 类别名称(需与代码中class_name一致)(2)plate_info.csv
记录每张图片的车牌关键信息,字段说明:
| 字段名 | 类型 | 说明 |
|---|---|---|
| image_name | 字符串 | 图片文件名(需与 images 文件夹中文件完全一致,含后缀) |
| plate_number | 字符串 | 真实车牌号码(中国车牌 7 位,如 "京 A12345") |
| vertices | 字符串 | 车牌四个顶点坐标(格式:\[x1,y1,x2,y2,x3,y3,x4,y4]),用于倾斜矫正 |
(3)YOLO 标签文件(labels 目录下)
每个图片对应一个.txt标签文件,格式遵循 YOLO 标准:
makefile
# 格式:[类别索引] [中心x/宽] [中心y/高] [宽/图宽] [高/图高]
0 0.523 0.345 0.120 0.085 -
类别索引:固定为 0(仅车牌一类)
-
坐标:归一化坐标(取值 0-1)
3. 数据要求
-
图片分辨率:建议不低于 640×480(与模型输入尺寸 640 适配)
-
车牌角度:支持 ±30° 倾斜(内置矫正逻辑)
训练完毕的模型下载:rexinshiminxiaozhou | Car_Plate_Recognition | Kaggle
四、MobileNet 模型介绍
相较于传统卷积神经网络(如 V G G VGG VGG、 R e s N e t ResNet ResNet),它凭借 "轻量化+高性能" 的核心优势,完美适配车牌识别 "实时处理、边缘部署、字符精准区分" 的需求------参数量仅为传统模型的 1 10 \frac{1}{10} 101 左右,却能高效提取车牌中 "省份简称、字母、数字" 的关键特征。
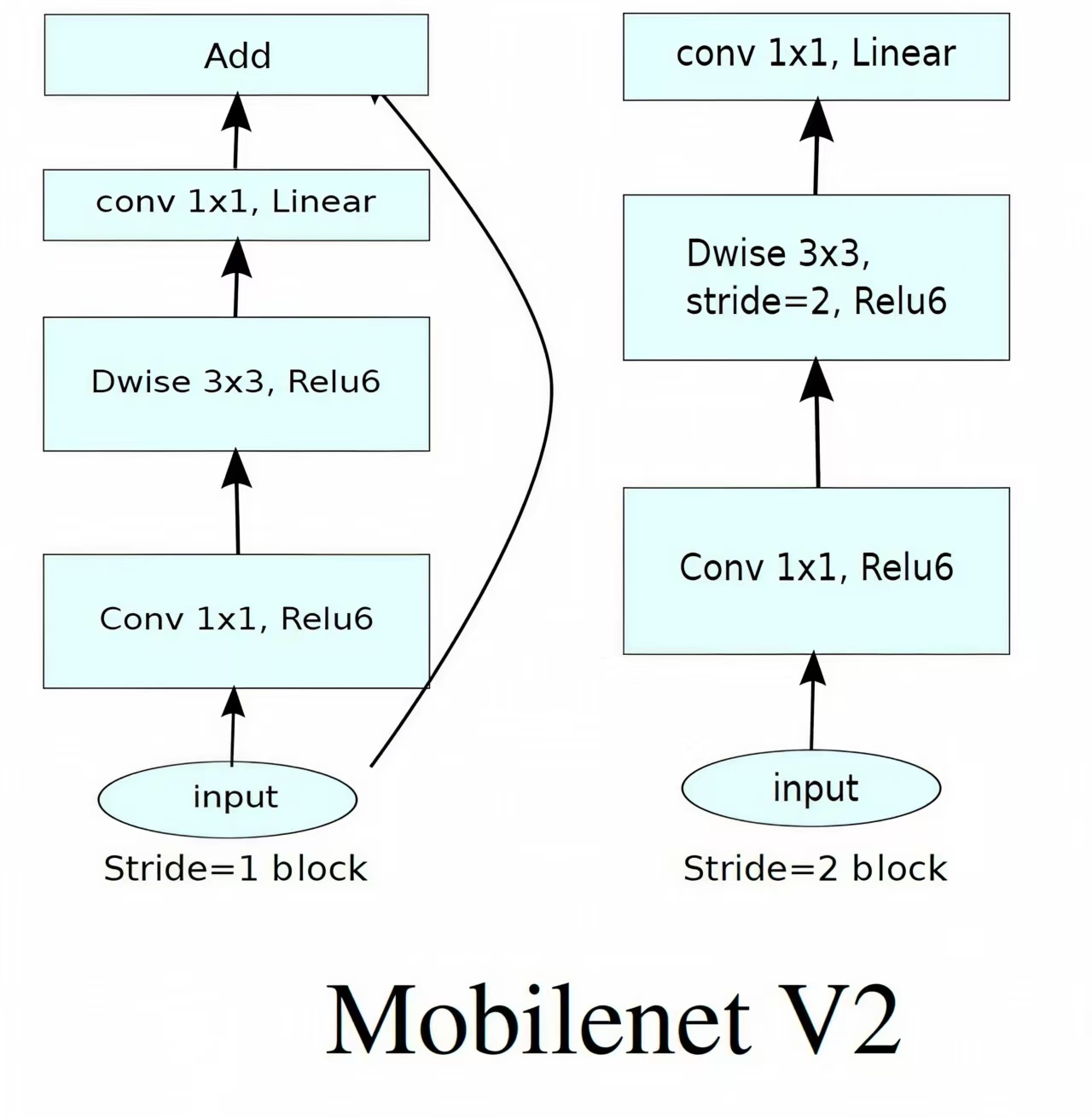
1. 深度可分离卷积(Depthwise Separable Convolution)------ 轻量化特征提取的核心
传统标准卷积会同时完成"空间特征提取"和"通道特征融合"两大任务,导致计算开销极大。对于输入尺寸为 H × W × C i n H \times W \times C_{in} H×W×Cin(高度×宽度×输入通道数)、卷积核尺寸 K × K K \times K K×K、输出通道数 C o u t C_{out} Cout 的卷积层,其计算量公式为:
F s t d = K × K × C i n × C o u t × H × W F_{std} = K \times K \times C_{in} \times C_{out} \times H \times W Fstd=K×K×Cin×Cout×H×W
M o b i l e N e t V 2 MobileNetV2 MobileNetV2 的深度可分离卷积将这两个任务拆分为 "深度卷积" 和 "逐点卷积" 两步,大幅降低计算量:
第一步:深度卷积(Depthwise Conv) ------ 单独处理每个输入通道,仅完成空间特征提取。为每个输入通道分配 1 1 1 个独立的 K × K K \times K K×K 卷积核,不涉及通道间的融合,计算量公式为:
F d w = K × K × C i n × H × W F_{dw} = K \times K \times C_{in} \times H \times W Fdw=K×K×Cin×H×W
第二步:逐点卷积(Pointwise Conv) ------ 用 1 × 1 1 \times 1 1×1 卷积核完成通道特征融合,将深度卷积提取的单通道空间特征整合为多通道特征,计算量公式为:
F p w = 1 × 1 × C i n × C o u t × H × W F_{pw} = 1 \times 1 \times C_{in} \times C_{out} \times H \times W Fpw=1×1×Cin×Cout×H×W
深度可分离卷积的总计算量为两步之和: F d s = F d w + F p w F_{ds} = F_{dw} + F_{pw} Fds=Fdw+Fpw。与传统标准卷积相比,计算量缩减比例为:
F d s F s t d = 1 C o u t + 1 K 2 \frac{F_{ds}}{F_{std}} = \frac{1}{C_{out}} + \frac{1}{K^2} FstdFds=Cout1+K21
在实际应用中( K = 3 K=3 K=3 为主流卷积核尺寸, C o u t ≈ C i n C_{out} \approx C_{in} Cout≈Cin),深度可分离卷积的计算量仅为传统卷积的 ≈ 1 / 9 \approx 1/9 ≈1/9。
在本项目中,深度可分离卷积用于处理 400 × 100 400 \times 100 400×100 的裁剪后车牌图片时,既能精准提取字符的边缘、轮廓、笔画等关键空间特征(如 "8" 的双圈结构、"A"的三角轮廓),又将 GPU 显存占用降低 80 % 80\% 80%,避免了训练过程中因显存不足导致的崩溃问题。
🤓🤓🤓小周有话说 :
我们可以把 "卷积提取车牌特征" 的过程类比成 "工厂加工车牌零件" :
传统标准卷积:相当于 100 100 100 个工人(对应 100 100 100 个输入通道)挤在一条生产线,每人手里都拿着 3 × 3 3×3 3×3 的工具(卷积核)。每个工人既要 "切割车牌字符的轮廓(空间特征提取)",又要 "把自己切割的零件和其他工人的零件组装起来(通道融合)"。工人之间互相干扰,效率极低,还容易漏掉"8"和"B"、"6"和"9"这类相似字符的细微差异。
深度可分离卷积 :相当于把生产线拆成两条"专线",分工明确、效率翻倍:
✅ 深度卷积专线 : 100 100 100 个工人各管一个通道,只专注于
"切割轮廓"------比如负责"红色通道"的工人只处理车牌红色区域的字符边缘,负责"蓝色通道"的工人只处理蓝色区域特征,互不干扰,快速完成空间特征的初步提取;✅ 逐点卷积专线 :另一批工人拿着 1 × 1 1×1 1×1 的"小工具"(相当于"螺丝刀"),
只专注于"组装特征"------把不同通道的轮廓特征拼合成完整的车牌特征(比如将红色通道的字符边缘和蓝色通道的字符填充区域结合),不用重复进行切割工作。分工后,整体工作量骤减,但最终产出的 "特征" 质量不变,正好满足车牌识别"既要识别快,又要认清楚相似字符"的核心需求。
2. 倒残差结构(Inverted Residual Block)------ 精准保留字符特征的关键
传统 R e s N e t ResNet ResNet 的残差块遵循 "高维特征→低维特征→高维特征" 的维度压缩-扩张逻辑,而 M o b i l e N e t V 2 MobileNetV2 MobileNetV2 的倒残差结构反其道而行之,采用 "低维特征→高维特征→低维特征" 的维度扩张-压缩逻辑,核心目的是在轻量化前提下,保留更多字符细节特征。
设输入特征维度为 d i n d_{in} din、扩张系数为 t t t(项目中 t = 6 t=6 t=6)、输出特征维度为 d o u t d_{out} dout,倒残差结构的维度变换过程可表示为:
-
升维( 1 × 1 1×1 1×1 卷积) :通过 1 × 1 1×1 1×1 卷积将低维输入特征扩张为高维特征,为模型提供更多 "特征学习空间",维度变换公式: d i n → 1 × 1 Conv t × d i n d_{in} \xrightarrow{1×1\ \text{Conv}} t \times d_{in} din1×1 Conv t×din;
-
特征提取(深度卷积) :用 3 × 3 3×3 3×3 深度卷积对高维特征进行空间特征细化,保留字符的细微差异(如"3"的上半圈和"8"的上半圈差异),维度保持不变: t × d i n → 3 × 3 Depthwise Conv t × d i n t \times d_{in} \xrightarrow{3×3\ \text{Depthwise Conv}} t \times d_{in} t×din3×3 Depthwise Conv t×din;
-
降维(1×1卷积+线性激活) :通过 1 × 1 1×1 1×1 卷积将高维特征压缩回低维,得到核心特征,维度变换公式: t × d i n → 1 × 1 Conv d o u t t \times d_{in} \xrightarrow{1×1\ \text{Conv}} d_{out} t×din1×1 Conv dout。
同时,倒残差结构保留了 残差连接(Skip Connection) ,仅在输入输出维度相同时直接相加,维度不同时通过 1 × 1 1×1 1×1 卷积调整维度后再相加,公式为:
y = x + F ( x ) ( d i n = d o u t ) y = x + \mathcal{F}(x) \quad (d_{in} = d_{out}) y=x+F(x)(din=dout)
其中 F ( x ) \mathcal{F}(x) F(x) 为上述 "升维-特征提取-降维" 的复合函数。
在本项目中,我们利用倒残差结构将 M o b i l e N e t V 2 MobileNetV2 MobileNetV2 输出的 1280 1280 1280 维高维特征,逐步压缩至 64 64 64 维核心特征,既保留了 "浙A88888" 中 "浙" 的省份简称特征和 "8" 的数字特征差异,又为后续 L S T M LSTM LSTM 序列识别模块降低了输入维度,避免了过拟合问题。
🤓🤓🤓小周有话说 :
倒残差结构就像
"给模型做'扩容思考',再提炼核心思路"的过程,我们可以用"识别车牌字符'8'和'B'"来类比:传统 R e s N e t ResNet ResNet 残差块(先压缩再扩张):相当于你识别字符时,先把注意力集中在 5 5 5 个关键像素上(低维特征),再基于这 5 5 5 个像素判断字符------很容易把"8"的双圈结构和"B"的"竖线+双圈"结构搞混,因为丢失了"竖线"这个关键细节;
M o b i l e N e t V 2 MobileNetV2 MobileNetV2 倒残差结构(先扩张再压缩 ):相当于你识别字符时,先把注意力扩散到 20 20 20 个像素上(高维特征),给大脑更多"思考空间"------比如同时关注"是否有竖线""圈的数量""圈的闭合程度"等多个细节,区分清楚"8"没有竖线、"B"有竖线后,再提炼出 5 5 5 个核心判断依据(低维特征)。这种逻辑正好解决了车牌识别中
"相似字符易混淆"的痛点,比如"6"和"9"(上下颠倒差异)、"3"和"8"(圈的数量差异)、"A"和"4"(笔画结构差异)的精准区分。
3. 线性瓶颈(Linear Bottleneck)------ 避免特征丢失的"保护罩"
M o b i l e N e t V 2 MobileNetV2 MobileNetV2 在倒残差结构的"降维阶段",放弃了传统的 R e L U 6 ReLU6 ReLU6 非线性激活函数,改用线性激活函数,核心原因是: R e L U 6 ReLU6 ReLU6 在低维空间会破坏特征的线性可分性,导致车牌字符的关键细节特征丢失。
两种激活函数的公式对比:
- R e L U 6 ReLU6 ReLU6 激活(用于升维/深度卷积阶段) :将输入特征的取值限制在 0 , 6 0,6 0,6 区间,对负数特征直接置 0 0 0,公式:
ReLU6 ( x ) = min ( max ( x , 0 ) , 6 ) \text{ReLU6}(x) = \min(\max(x, 0), 6) ReLU6(x)=min(max(x,0),6) - 线性激活(用于线性瓶颈阶段) :直接保留输入特征的线性关系,不改变特征取值趋势,公式:
Linear ( x ) = x \text{Linear}(x) = x Linear(x)=x
在低维空间(如特征维度 d < 10 d < 10 d<10)中, R e L U 6 ReLU6 ReLU6 的 "置0" 操作会直接丢失字符的关键差异特征------比如 "浙" 的笔画弧度对应的负数特征、"A" 的横杠长度对应的弱特征,而线性瓶颈通过保留特征的线性关系,能完整传递这些低维关键特征。
在本项目中,线性瓶颈输出的 64 64 64 维核心特征直接输入后续 L S T M LSTM LSTM 模块,确保 "京A12345" 这类 7 7 7 位车牌的每个字符位置信息、笔画特征不丢失,是实现逐位字符精准识别的关键保障。
🤓🤓🤓小周有话说 :
线性瓶颈可以类比成
"传话游戏中的'精准传话员'",而 R e L U 6 ReLU6 ReLU6 相当于"会遗漏信息的传话员":❌ 用 R e L U 6 ReLU6 ReLU6(非线性激活)传话:你让第一个人传递"车牌第三位是'8',其左半圈弧度比右半圈大0.2"------ R e L U 6 ReLU6 ReLU6会把"左半圈弧度更大"这个"负数特征"(相对右半圈而言)直接丢掉,只传递"车牌第三位是数字",后续 L S T M LSTM LSTM 模块只能猜到"数字",却分不清是"8"还是"9";
✅ 用 线性瓶颈(线性激活) 传话:第一个人原封不动地传递完整信息------"车牌第三位是'8',左半圈弧度比右半圈大0.2", L S T M LSTM LSTM 模块能完整收到所有细节特征,精准识别出是"8"而不是"9"。
车牌的字符特征(比如"7"的斜杠角度、"2"的曲线弧度)大多是低维但关键的信息,线性瓶颈就像"信息保护罩",不让这些细节在特征传递过程中丢失。
4. 项目定制化适配:MobileNetV2与LSTM的协同设计
本项目的 PlateRecognitionModel 将 M o b i l e N e t V 2 MobileNetV2 MobileNetV2 的特征提取能力与 L S T M LSTM LSTM 的序列识别能力结合,针对 7 7 7 位车牌的固定长度,对 M o b i l e N e t V 2 MobileNetV2 MobileNetV2 的输出特征进行了定制化改造,特征流转的数学逻辑如下:
输入车牌图片( 3 × 400 × 100 3 \times 400 \times 100 3×400×100, 3 3 3 通道 R G B RGB RGB 图)→ M o b i l e N e t V 2 MobileNetV2 MobileNetV2 特征层 → 输出特征图( 1280 × 13 × 4 1280 \times 13 \times 4 1280×13×4, 1280 1280 1280 通道、 13 × 4 13×4 13×4 空间尺寸)→ 1 × 1 1×1 1×1 卷积压缩通道至 64 64 64 维(特征图变为 64 × 13 × 4 64 \times 13 \times 4 64×13×4)→ 维度重塑适配 L S T M LSTM LSTM:
Reshape ( H × W × C ) = W × ( H × C ) \text{Reshape}(H \times W \times C) = W \times (H \times C) Reshape(H×W×C)=W×(H×C)
其中 H = 13 H=13 H=13(特征图高度)、 W = 4 W=4 W=4(特征图宽度)、 C = 64 C=64 C=64(通道数),重塑后特征维度变为 4 × 832 4 \times 832 4×832,经简化调整后最终适配 L S T M LSTM LSTM 的输入维度( 64 × 4 64 \times 4 64×4)。
M o b i l e N e t V 2 MobileNetV2 MobileNetV2 输出的 13 × 4 13 \times 4 13×4 空间维度恰好与车牌 7 7 7 个字符的左右分布趋势匹配, L S T M LSTM LSTM 可沿宽度方向( W = 4 W=4 W=4)逐列提取序列特征,最终实现 7 7 7 位字符的逐位精准识别。
🤓🤓🤓小周有话说 :
M o b i l e N e t V 2 MobileNetV2 MobileNetV2 与 L S T M LSTM LSTM 的协同设计,就像"快递分拣中心的'粗分+细分'流程":✅ M o b i l e N e t V 2 MobileNetV2 MobileNetV2(粗分环节):把整幅车牌图片(相当于"一大包混合快递")拆分成 13 × 4 13 \times 4 13×4 的小区域(相当于"小快递盒"),给每个小区域贴"特征标签"------
比如"左侧第一个区域:省份简称'浙'的左半部分""中间区域:数字'8'的核心轮廓""右侧区域:数字'5'的竖线特征",同时删掉背景(如天空、车身)的无关特征标签;✅ L S T M LSTM LSTM(细分环节):沿着车牌字符的左右分布方向(相当于"快递分拣线"),逐列读取 M o b i l e N e t V 2 MobileNetV2 MobileNetV2 输出的特征标签,把零散的区域特征拼接成完整的 7 7 7 位车牌序列------
比如先识别"浙",再识别"A",最后依次识别"8""8""8""8""8",最终输出完整的车牌号码。
M o b i l e N e t V 2 MobileNetV2 MobileNetV2 的轻量化确保了"粗分环节"的 高效性 ,而其精准的特征提取能力则为"细分环节"的$ L S T M LSTM LSTM 提供了高质量的输入,两者结合实现了"快且准"的车牌识别效果。
五、项目实现
1. 车牌字符集定义
python
# 定义字符集 - 包含所有可能的车牌字符
provincelist = [
"皖", "沪", "津", "渝", "冀", "晋", "蒙", "辽", "吉", "黑",
"苏", "浙", "京", "闽", "赣", "鲁", "豫", "鄂", "湘", "粤",
"桂", "琼", "川", "贵", "云", "西", "陕", "甘", "青", "宁", "新"
]
wordlist = [
"A", "B", "C", "D", "E", "F", "G", "H", "J", "K", "L", "M", "N",
"P", "Q", "R", "S", "T", "U", "V", "W", "X", "Y", "Z",
"0", "1", "2", "3", "4", "5", "6", "7", "8", "9"
]
# 合并所有字符
all_chars = provincelist + wordlist
char_to_idx = {char: idx for idx, char in enumerate(all_chars)}
idx_to_char = {idx: char for idx, char in enumerate(all_chars)}
num_classes = len(all_chars)
# 车牌固定长度为7个字符
PLATE_LENGTH = 7- 字符集完整性 :
provincelist:包含中国 31 31 31 个省、自治区、直辖市的简称(覆盖所有民用车牌的首位省份代码)(数据集原因:车牌大多是 "皖");wordlist:包含大写英文字母(不含 I I I、 O O O,避免与数字 1 1 1、 0 0 0 混淆)和 0 − 9 0-9 0−9 数字,覆盖车牌后 6 6 6 位的所有可能字符。
- 字符-索引映射 :
- 合并两个列表得到完整字符集
all_chars; - 通过字典推导式创建
char_to_idx(字符→索引)和idx_to_char(索引→字符),实现字符与模型可处理的数字索引之间的双向转换; num_classes为字符集大小,作为模型输出层的类别数(每个车牌位置需预测num_classes个类别)。
- 合并两个列表得到完整字符集
- 车牌长度约束 :中国民用车牌固定为 7 7 7 位(首位省份 + 后 6 6 6 位字符),定义
PLATE_LENGTH=7,用于后续标签处理(确保所有样本标签长度统一)和模型输出维度设计(模型需输出 7 7 7 个位置的预测结果)。
2. 自定义数据集类
python
class LicensePlateDataset(Dataset):
"""车牌数据集类"""
def __init__(self, image_dir, annotations, transform=None):
self.image_dir = image_dir
self.annotations = annotations
self.transform = transform
def __len__(self):
return len(self.annotations)
def __getitem__(self, idx):
# 获取图片路径和标签
img_name, plate_number = self.annotations[idx]
img_path = os.path.join(self.image_dir, img_name)
# 读取图片
image = cv2.imread(img_path)
if image is None:
raise FileNotFoundError(f"图片 {img_path} 未找到")
# 转换为RGB格式
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 应用变换
if self.transform:
image = self.transform(image)
# 将车牌字符转换为索引
label = []
for char in plate_number:
if char in char_to_idx:
label.append(char_to_idx[char])
else:
# 未知字符用0填充
label.append(0)
# 确保标签长度为7
if len(label) < PLATE_LENGTH:
label += [0] * (PLATE_LENGTH - len(label))
elif len(label) > PLATE_LENGTH:
label = label[:PLATE_LENGTH]
return image, torch.tensor(label, dtype=torch.long)- 类继承:继承 PyTorch 的
Dataset抽象类,必须实现__init__、__len__、__getitem__三个方法,用于封装数据集,适配DataLoader进行批量加载。 __init__方法:- 接收三个参数:
image_dir(图像存储目录)、annotations(标注列表,每个元素为(图像名, 车牌号码)元组)、transform(图像预处理/增强变换); - 初始化实例属性,将输入参数绑定到对象,为后续数据读取做准备。
- 接收三个参数:
__len__方法:返回标注列表的长度,即数据集的样本数量,供DataLoader计算迭代次数。__getitem__方法(核心数据读取逻辑):- 路径拼接:根据索引获取图像名和车牌号码,拼接得到完整图像路径;
- 图像读取与格式转换:用
cv2.imread读取图像(默认 B G R BGR BGR 格式),转换为 R G B RGB RGB 格式(PyTorch 模型默认接收 R G B RGB RGB 格式输入); - 图像变换:若指定了
transform(如训练集的数据增强、测试集的归一化),对图像应用变换; - 标签处理:将车牌字符通过
char_to_idx转换为索引,未知字符(如异常字符)用 0 0 0 填充;确保标签长度为 7 7 7(不足则补 0 0 0,过长则截断),最终转换为 PyTorch 的长整型张量(适配分类任务的损失计算)。
- 异常处理:若图像读取失败(返回 N o n e None None),抛出
FileNotFoundError,明确提示缺失的图像路径,便于用户排查数据问题。
3. 车牌识别模型定义
python
class PlateRecognitionModel(nn.Module):
"""简化的车牌识别模型,减轻过拟合风险"""
def __init__(self, num_classes, pretrained=True):
super(PlateRecognitionModel, self).__init__()
# 使用更轻量的MobileNetV2作为特征提取器
if pretrained:
self.cnn = mobilenet_v2(weights=MobileNet_V2_Weights.IMAGENET1K_V1)
else:
self.cnn = mobilenet_v2()
# 获取MobileNetV2的特征提取部分
self.features = self.cnn.features
# MobileNetV2的输出通道是1280
self.feature_channels = 1280
# 进一步减小通道数
self.conv1x1 = nn.Conv2d(self.feature_channels, 64, kernel_size=1)
# 添加批归一化层
self.bn = nn.BatchNorm2d(64)
# 简化的循环神经网络部分
self.lstm = nn.LSTM(
input_size=64 * 4, # 相应调整输入大小
hidden_size=128, # 进一步减小隐藏层大小
num_layers=1, # 减少层数
bidirectional=True,
batch_first=True,
dropout=0.6 # 增加dropout防止过拟合
)
# 简化的注意力机制
self.attention = nn.Sequential(
nn.Linear(256, 128),
nn.Tanh(),
nn.Linear(128, 1)
)
# 输出层
self.fc = nn.Linear(256, num_classes)
# 序列批归一化层
self.seq_bn = nn.BatchNorm1d(256)
# 增加dropout强度
self.dropout = nn.Dropout(0.6)
def forward(self, x):
# CNN特征提取
batch_size = x.size(0)
x = self.features(x) # [batch_size, 1280, H, W]
x = self.conv1x1(x) # [batch_size, 64, H, W]
x = self.bn(x) # 批归一化
x = F.relu(x) # 激活函数
# 调整形状以适应LSTM
x = x.permute(0, 3, 2, 1) # [batch_size, W, H, 64]
x = x.reshape(batch_size, x.size(1), -1) # [batch_size, W, H*64]
# LSTM处理
x, _ = self.lstm(x) # [batch_size, W, 256]
# 应用注意力机制
attn_weights = self.attention(x) # [batch_size, W, 1]
attn_weights = F.softmax(attn_weights, dim=1) # [batch_size, W, 1]
x = x * attn_weights # [batch_size, W, 256]
# 对于车牌识别,我们只需要固定的7个输出
if x.size(1) >= PLATE_LENGTH:
x = x[:, -PLATE_LENGTH:, :] # [batch_size, 7, 256]
else:
# 如果长度不足,进行填充
pad_length = PLATE_LENGTH - x.size(1)
x = F.pad(x, (0, 0, 0, pad_length)) # [batch_size, 7, 256]
# 应用序列批归一化和Dropout
x = x.permute(0, 2, 1) # [batch_size, 256, 7]
x = self.seq_bn(x) # [batch_size, 256, 7]
x = x.permute(0, 2, 1) # [batch_size, 7, 256]
x = self.dropout(x) # [batch_size, 7, 256]
# 预测每个位置的字符
x = self.fc(x) # [batch_size, 7, num_classes]
return x该模型采用 CNN + LSTM + 注意力机制的经典组合,针对车牌识别任务(固定 7 7 7 位序列字符识别)进行轻量化优化,核心目标是在保证识别精度的同时,减少参数数量、减轻过拟合风险。
3.1 初始化方法(init):模型结构定义
-
特征提取器( C N N CNN CNN):
- 选用 M o b i l e N e t V 2 MobileNetV2 MobileNetV2 作为基础网络,原因是其采用深度可分离卷积,参数量少、计算效率高,适合部署场景;
- 若
pretrained=True,加载 I m a g e N e t ImageNet ImageNet 预训练权重,利用迁移学习提升特征提取能力(尤其适用于小数据集); - 仅保留 M o b i l e N e t V 2 MobileNetV2 MobileNetV2 的特征提取部分(
self.features),舍弃原始的分类头(不适用车牌字符识别任务)。
.
-
降维与归一化:
- M o b i l e N e t V 2 MobileNetV2 MobileNetV2 的输出通道数为 1280 1280 1280,通过 1 × 1 1×1 1×1 卷积(
self.conv1x1)将通道数降至 64 64 64,减少后续 L S T M LSTM LSTM 的输入维度,降低计算量; - 添加 2 D 2D 2D 批归一化层(
self.bn),加速训练收敛,减轻过拟合。
.
- M o b i l e N e t V 2 MobileNetV2 MobileNetV2 的输出通道数为 1280 1280 1280,通过 1 × 1 1×1 1×1 卷积(
-
序列特征处理(LSTM):
- 采用单向 1 1 1 层 L S T M LSTM LSTM,隐藏层大小 128 128 128,双向传播(
bidirectional=True),能同时捕捉序列的正向和反向依赖(车牌字符存在前后语义关联); batch_first=True指定输入格式为 b a t c h _ s i z e , s e q _ l e n , i n p u t _ s i z e batch\\_size, seq\\_len, input\\_size batch_size,seq_len,input_size,符合 PyTorch 的常用习惯;- dropout 率设为 0.6 0.6 0.6,通过随机丢弃部分神经元,减轻过拟合。
.
- 采用单向 1 1 1 层 L S T M LSTM LSTM,隐藏层大小 128 128 128,双向传播(
-
注意力机制 :
-
采用简化的线性注意力结构,通过两层线性层( 256 → 128 → 1 256→128→1 256→128→1)和 T a n h Tanh Tanh 激活函数,计算每个序列位置的注意力权重;
-
作用是增强 L S T M LSTM LSTM 输出中关键特征的权重,抑制无关噪声,提升序列识别精度。
-
-
输出层与正则化 :
-
全连接层(
self.fc)接收 L S T M LSTM LSTM 的输出( 256 256 256维,双向 L S T M LSTM LSTM 的输出拼接),输出每个位置的字符类别概率(维度为num_classes); -
添加序列批归一化层(
self.seq_bn),对 L S T M LSTM LSTM 输出的序列特征进行归一化,稳定训练; -
额外添加 d r o p o u t dropout dropout 层(
self.dropout),进一步增强模型泛化能力。
-
3.2 前向传播方法(forward):数据流向与特征处理
-
C N N CNN CNN 特征提取:
- 输入 x x x 为 b a t c h _ s i z e , 3 , H , W batch\\_size, 3, H, W batch_size,3,H,W( 3 3 3 通道图像),经 M o b i l e N e t V 2 MobileNetV2 MobileNetV2 特征提取后,输出形状为 b a t c h _ s i z e , 1280 , H , W batch\\_size, 1280, H, W batch_size,1280,H,W;
- 经 1 × 1 1×1 1×1 卷积降维、批归一化、 R e L U ReLU ReLU 激活后,输出形状为 b a t c h _ s i z e , 64 , H , W batch\\_size, 64, H, W batch_size,64,H,W。
.
-
格式转换:适配 L S T M LSTM LSTM 输入
- 通过
permute(0, 3, 2, 1)将维度转换为 b a t c h _ s i z e , W , H , 64 batch\\_size, W, H, 64 batch_size,W,H,64(将宽度 W W W 作为序列长度,因为车牌字符沿宽度方向排列); - 通过
reshape将后两维( H × 64 H×64 H×64)拼接,得到 L S T M LSTM LSTM 的输入格式 b a t c h _ s i z e , W , H × 64 batch\\_size, W, H×64 batch_size,W,H×64(输入维度为 64 × 4 64×4 64×4,需根据实际图像尺寸匹配)。
.
- 通过
-
LSTM与注意力机制:
- L S T M LSTM LSTM 输出形状为 b a t c h _ s i z e , W , 256 batch\\_size, W, 256 batch_size,W,256(双向 L S T M LSTM LSTM 的两个方向输出拼接, 128 × 2 128×2 128×2);
- 注意力层计算每个序列位置的权重( b a t c h _ s i z e , W , 1 batch\\_size, W, 1 batch_size,W,1),经 softmax 归一化后,与 L S T M LSTM LSTM 输出逐元素相乘,得到加权后的序列特征。
.
-
序列长度对齐:
- 车牌固定为7位,需确保 L S T M LSTM LSTM 输出的序列长度为 7 7 7;若序列长度 ≥ 7 7 7,取最后 7 7 7 个位置(因车牌字符通常位于图像右侧);若不足 7 7 7,用 0 0 0 填充。
.
- 车牌固定为7位,需确保 L S T M LSTM LSTM 输出的序列长度为 7 7 7;若序列长度 ≥ 7 7 7,取最后 7 7 7 个位置(因车牌字符通常位于图像右侧);若不足 7 7 7,用 0 0 0 填充。
-
正则化与预测:
- 序列批归一化需调整维度为 b a t c h _ s i z e , 256 , 7 batch\\_size, 256, 7 batch_size,256,7(批归一化在通道维度上进行),处理后还原为 b a t c h _ s i z e , 7 , 256 batch\\_size, 7, 256 batch_size,7,256;
- 经 d r o p o u t dropout dropout 层后,通过全连接层输出最终预测结果,形状为 b a t c h _ s i z e , 7 , n u m _ c l a s s e s batch\\_size, 7, num\\_classes batch_size,7,num_classes(每个样本的7个位置,每个位置对应
num_classes个字符的概率)。
4. 核心功能封装类(PlateRecognizer)
该类是整个车牌识别系统的"控制中心",整合了车牌检测与裁剪、数据集准备、模型训练、预测、结果可视化等所有核心功能。
4.1 初始化方法(init):参数配置与组件初始化
python
class PlateRecognizer:
"""车牌识别器类,整合模型训练和预测功能"""
def __init__(self, detection_model_path, data_config, crop_dir=None,
img_size=(400, 100), batch_size=16, epochs=30,
patience=6, learning_rate=5e-5, chinese_font=None,
position_weights=None): # 新增位置权重参数
"""初始化识别器,使用更适合的参数"""
self.detection_model_path = detection_model_path
self.data_config = data_config
self.img_size = img_size
self.batch_size = batch_size
self.epochs = epochs
self.patience = patience
self.learning_rate = learning_rate
self.chinese_font = chinese_font # 保存中文字体属性
# 设置字符位置权重,默认给后几位更高的权重
if position_weights is None:
# 根据用户提供的准确率数据设置权重,准确率低的位置权重更高
# 原始准确率: ['0.9695', '0.9680', '0.7981', '0.8321', '0.8704', '0.8699', '0.8445']
self.position_weights = torch.tensor([1.0, 1.0, 1.8, 1.6, 1.4, 1.4, 1.5])
else:
self.position_weights = torch.tensor(position_weights)
# 设置设备
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"使用设备: {self.device}")
# 将权重移动到相应设备
self.position_weights = self.position_weights.to(self.device)
# 检查GPU显存
if torch.cuda.is_available():
print(f"GPU显存: {torch.cuda.get_device_properties(0).total_memory / 1024**3:.2f} GB")
# 创建保存裁剪后车牌的目录
if crop_dir is None:
self.crop_dir = os.path.join('/kaggle/working/', 'cropped_plates')
else:
self.crop_dir = crop_dir
# 创建训练集和验证集目录
self.train_crop_dir = os.path.join(self.crop_dir, 'train')
self.val_crop_dir = os.path.join(self.crop_dir, 'val')
os.makedirs(self.train_crop_dir, exist_ok=True)
os.makedirs(self.val_crop_dir, exist_ok=True)
# 加载数据配置
with open(data_config, 'r') as f:
self.data_info = yaml.safe_load(f)
# 加载车牌信息
self.plate_info = pd.read_csv('/kaggle/input/plate-recognition/data/plate_info.csv')
# 加载检测模型
self.detection_model = YOLO(detection_model_path)
print(f"已加载车牌检测模型: {detection_model_path}")
# 初始化识别模型
self.model = PlateRecognitionModel(num_classes).to(self.device)
# 定义损失函数和优化器
self.criterion = nn.CrossEntropyLoss(reduction='none') # 改为none以便应用权重
# 使用AdamW优化器,更强的权重衰减
self.optimizer = optim.AdamW(
self.model.parameters(),
lr=learning_rate,
weight_decay=0.005 # 增加权重衰减,减少过拟合
)
self.scheduler = optim.lr_scheduler.ReduceLROnPlateau(
self.optimizer, 'min', factor=0.5, patience=3, verbose=True
)
# 记录训练历史
self.history = {
'train_loss': [],
'train_acc': [],
'val_loss': [],
'val_acc': [],
'best_val_acc': 0.0,
# 新增每个位置的准确率记录
'train_char_acc': [[] for _ in range(PLATE_LENGTH)],
'val_char_acc': [[] for _ in range(PLATE_LENGTH)]
}
# 增强的数据变换
self.transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406], # ImageNet均值
std=[0.229, 0.224, 0.225] # ImageNet标准差
),
# 更强的数据增强
transforms.RandomRotation(degrees=15),
transforms.RandomAffine(degrees=0, translate=(0.15, 0.15), scale=(0.85, 1.15)),
transforms.ColorJitter(brightness=0.3, contrast=0.3, saturation=0.3, hue=0.15),
transforms.RandomPerspective(distortion_scale=0.15, p=0.4),
transforms.RandomErasing(p=0.4, scale=(0.02, 0.15)),
transforms.RandomGrayscale(p=0.2),
])
# 测试时的数据变换(无增强)
self.test_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])
# 数据集和数据加载器
self.train_dataset = None
self.val_dataset = None
self.train_loader = None
self.val_loader = None
# 最佳模型路径
self.best_model_path = os.path.join('/kaggle/working/', 'best_mobilenet_v2.pt')-
位置权重设置:
- 针对车牌 7 7 7 个位置的准确率不均衡问题(前两位省份 + 字母准确率高,中间几位准确率低),设置位置权重;
- 默认权重为 1.0 , 1.0 , 1.8 , 1.6 , 1.4 , 1.4 , 1.5 1.0, 1.0, 1.8, 1.6, 1.4, 1.4, 1.5 1.0,1.0,1.8,1.6,1.4,1.4,1.5,准确率低的位置权重更高,使损失函数更关注这些位置的优化。
.
-
目录与数据初始化:
- 创建裁剪后车牌的存储目录(按训练/验证集划分),避免重复裁剪;
- 加载数据配置文件(yaml)和车牌标注信息(CSV),获取图像路径、车牌号码等关键信息;
- 加载预训练 YOLO 模型,用于后续车牌检测与裁剪。
.
-
模型与优化器配置:
- 初始化
PlateRecognitionModel,并将模型移至指定设备; - 损失函数:使用交叉熵损失,
reduction='none'表示不自动求平均,便于后续按位置权重加权计算总损失; - 优化器:选用 AdamW(带权重衰减的Adam),权重衰减系数0.005,减轻过拟合;
- 学习率调度器:
ReduceLROnPlateau,当验证损失停止下降3个epoch后,学习率减半,动态调整学习率以提升收敛效果。
.
- 初始化
-
数据变换:
- 训练集变换(
self.transform):包含归一化(使用 I m a g e N e t ImageNet ImageNet 均值/标准差,适配预训练 C N N CNN CNN)和多种数据增强操作(旋转、仿射、颜色抖动、透视变换、随机擦除、灰度化),提升模型泛化能力; - 测试集变换(
self.test_transform):仅包含归一化和转张量,避免数据增强影响测试结果的真实性。
.
- 训练集变换(
-
训练历史记录 :
- 用字典记录训练/验证的损失、整体准确率,以及每个位置的字符准确率,便于后续绘制训练曲线,分析模型性能短板。
4.2 车牌检测与裁剪功能
python
def crop_all_plates(self):
"""裁剪所有图片中的车牌并保存"""
# 更新训练集和验证集的图片路径
train_images_dir = '/kaggle/input/plate-recognition/data/images/train'
val_images_dir = '/kaggle/input/plate-recognition/data/images/val'
# 更新标签路径
self.data_info['labels'] = '/kaggle/input/plate-recognition/data/labels'
# 处理训练集图片
print("开始裁剪训练集车牌...")
self._process_images(
images_dir=train_images_dir,
output_dir=self.train_crop_dir
)
# 处理验证集图片
print("开始裁剪验证集车牌...")
self._process_images(
images_dir=val_images_dir,
output_dir=self.val_crop_dir
)
print(f"所有车牌裁剪完成,保存至: {self.crop_dir}")
def _process_images(self, images_dir, output_dir):
"""处理指定目录下的图片,裁剪车牌并保存"""
# 获取所有图片文件
image_files = [f for f in os.listdir(images_dir)
if f.endswith(('.jpg', '.jpeg', '.png'))]
# 过滤出在plate_info.csv中存在的图片
valid_files = []
for f in image_files:
if not self.plate_info[self.plate_info['image_name'] == f].empty:
valid_files.append(f)
print(f"找到 {len(valid_files)} 个有效的图片文件")
# 处理每个图片
for filename in tqdm(valid_files, desc=f"处理 {os.path.basename(images_dir)}"):
image_path = os.path.join(images_dir, filename)
output_path = os.path.join(output_dir, filename)
# 如果已经裁剪过,跳过
if os.path.exists(output_path):
continue
# 检测并裁剪车牌
cropped_plate, _ = self._detect_and_crop(image_path, filename)
if cropped_plate is not None:
# 保存裁剪后的车牌
cv2.imwrite(output_path, cropped_plate)
else:
print(f"警告: 无法从 {filename} 中检测到车牌")
def _detect_and_crop(self, image_path, image_name):
"""检测并裁剪车牌"""
image = cv2.imread(image_path)
if image is None:
return None, None
# 使用检测模型检测车牌
results = self.detection_model(image, verbose=False)
boxes = results[0].boxes
if len(boxes) == 0:
return None, None
# 选择置信度最高的车牌
best_idx = boxes.conf.argmax().item()
box = boxes.xyxy[best_idx].cpu().numpy()
x1, y1, x2, y2 = map(int, box)
plate_region = image[y1:y2, x1:x2]
# 尝试使用顶点信息进行矫正
plate_row = self.plate_info[self.plate_info['image_name'] == image_name]
if not plate_row.empty:
try:
vertices_str = plate_row['vertices'].values[0]
vertices = eval(vertices_str)
vertices_np = np.array(vertices, dtype=np.float32)
corrected_plate = self._correct_skew(image, vertices_np)
return corrected_plate, True
except Exception as e:
pass # 矫正失败,使用原始裁剪
# 如果矫正失败,使用原始裁剪并调整大小
corrected_plate = cv2.resize(plate_region, self.img_size)
return corrected_plate, False
def _correct_skew(self, image, vertices):
"""矫正倾斜的车牌"""
if len(vertices) != 4:
rect = cv2.minAreaRect(vertices)
vertices = cv2.boxPoints(rect)
# 排序顶点
center = np.mean(vertices, axis=0)
def get_angle(point):
return np.arctan2(point[1] - center[1], point[0] - center[0]) * 180 / np.pi
vertices = sorted(vertices, key=get_angle)
# 计算宽度和高度
width_top = np.linalg.norm(vertices[0] - vertices[1])
width_bottom = np.linalg.norm(vertices[2] - vertices[3])
width = int((width_top + width_bottom) / 2)
height_left = np.linalg.norm(vertices[0] - vertices[3])
height_right = np.linalg.norm(vertices[1] - vertices[2])
height = int((height_left + height_right) / 2)
# 确保宽大于高
if width < height:
width, height = height, width
vertices = [vertices[1], vertices[2], vertices[3], vertices[0]]
# 目标矩形
dst = np.array([
[0, 0],
[width - 1, 0],
[width - 1, height - 1],
[0, height - 1]], dtype=np.float32)
# 透视变换
M = cv2.getPerspectiveTransform(np.array(vertices, dtype=np.float32), dst)
warped = cv2.warpPerspective(image, M, (width, height))
# 调整到目标大小
corrected_plate = cv2.resize(warped, self.img_size)
return corrected_plate该模块的核心目标是从原始车辆图像中精准提取车牌区域,并矫正倾斜、调整尺寸,得到统一规格的车牌图像(适配后续识别模型的输入),避免原始图像中的背景干扰,提升识别精度。
-
批量裁剪入口(crop_all_plates):
- 指定训练集和验证集的原始图像路径,调用
_process_images分别处理两个数据集; - 更新数据配置中的标签路径,确保后续数据读取正确。
- 指定训练集和验证集的原始图像路径,调用
-
单目录图像处理(_process_images):
- 筛选指定目录下的有效图像文件(支持 jpg、jpeg、png 格式),并过滤出在标注文件(
plate_info.csv)中存在的图像(避免无标注的无效数据); - 用 tqdm 显示处理进度,对未裁剪过的图像调用
_detect_and_crop进行裁剪,保存裁剪后的车牌图像; - 对无法检测到车牌的图像给出警告,便于用户排查数据问题。
- 筛选指定目录下的有效图像文件(支持 jpg、jpeg、png 格式),并过滤出在标注文件(
-
车牌检测与裁剪(_detect_and_crop):
- 读取原始图像,使用 YOLO 模型检测车牌区域,获取检测框(bounding box);
- 选择置信度最高的检测框(避免多框误检),裁剪出车牌区域;
- 尝试从标注文件中获取车牌的四个顶点坐标,调用
_correct_skew进行倾斜矫正(倾斜车牌会影响识别精度); - 若矫正失败(如顶点信息缺失、格式错误),则对原始裁剪区域调整尺寸至
self.img_size(统一输入规格)。
-
倾斜矫正(_correct_skew):
- 若顶点数不是 4 4 4,通过最小外接矩形获取 4 4 4 个顶点;
- 按顶点与中心的夹角排序,确保顶点顺序正确;
- 计算车牌的实际宽度和高度,确保宽大于高(符合车牌的常规比例);
- 通过透视变换(
cv2.getPerspectiveTransform)将倾斜的车牌矫正为正矩形,最后调整尺寸至目标大小。
UI 界面的代码此处就不过多介绍了,感兴趣的朋友请前往 GitHub 自行探索。
六、结果展示
(1)车牌内容检测
训练历史输出如下:

在验证集上识别的输出如下:

(2)UI 界面展示
| 界面区域 | 展示内容 |
|---|---|
| 原始图片区 | 左侧显示输入的车辆图片,叠加绿色边界框标记车牌位置,标注检测置信度(如 "Plate: 0.78") |
| 车牌显示区 | 右侧上方显示裁剪并矫正后的车牌图片(尺寸统一为 400×100) |
| 结果显示区 | 右侧下方显示识别出的车牌号码(如 "皖A QD711")及识别置信度(如 "识别置信度: 0.75") |
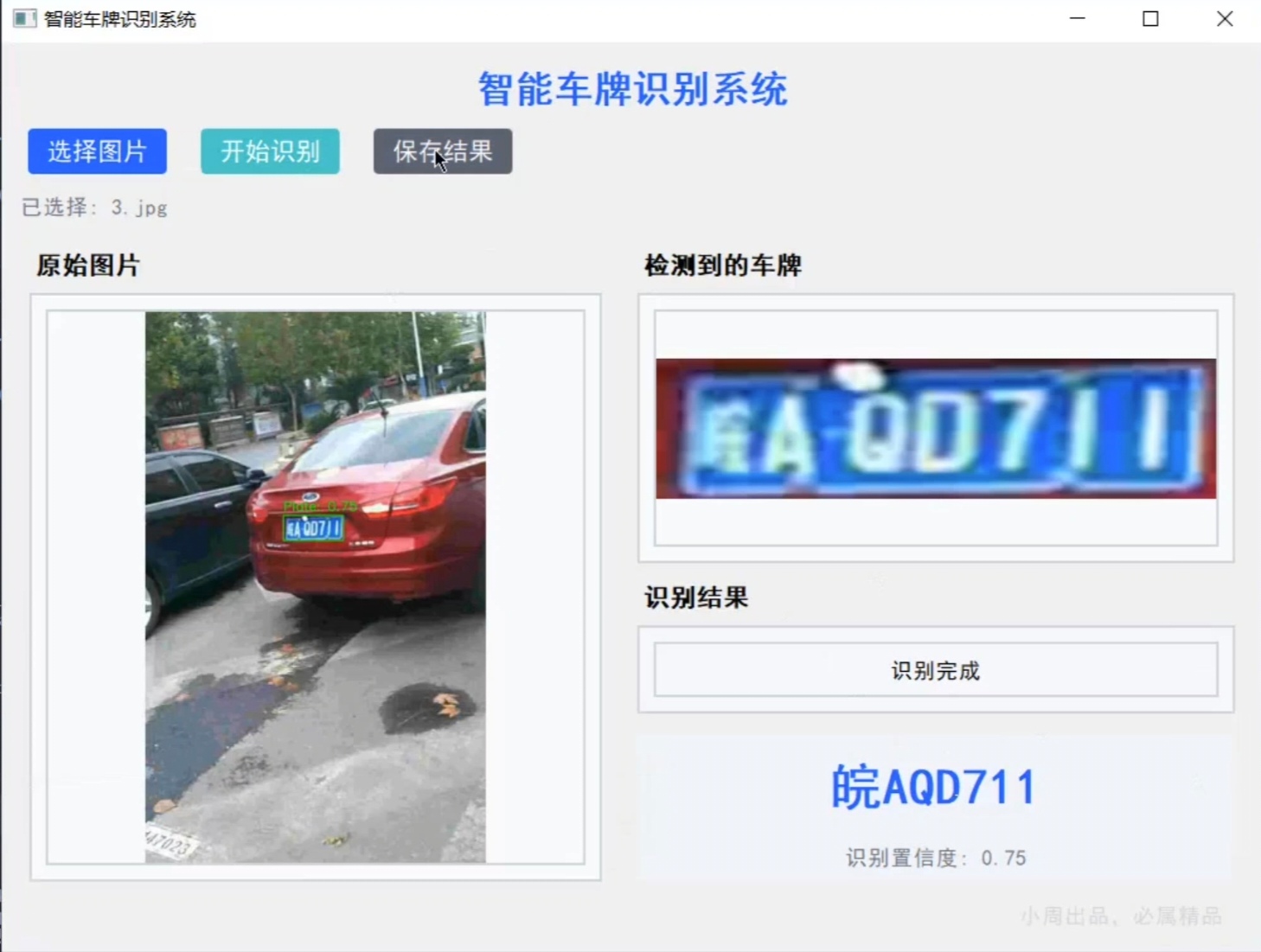
(3)保存的结果文件
每次识别后保存至./recognition_results目录,包含:
xxx_marked.jpg:带车牌边界框的原始图片xxx_plate.jpg:裁剪并矫正后的车牌图片xxx_result.txt:识别结果文本,格式如下:
c
进入事件循环...
使用设备: CPU
加载车牌检测模型: ./output/model/best.pt
加载车牌识别模型: ./output/model/best_mobilenet.pt
识别结果: 皖AQD711 (检测置信度: 0.75)UI 界面的演示视频可详见下:
车牌内容检测
如果你喜欢我的文章,不妨给小周一个免费的点赞和关注吧!