修订
|--------------|-------------------------------------------------|
| 版本号 | 修订的内容 |
| v1 2026年1月7日 | 前言、介绍、归纳偏置、相关工作、NLP框架究竟如何处理CV的图像、核心框架、面试问题、参考资料 |
| | |
后续考虑加入ViT-base middle large的解释。
前言:
目前我已经写了BERT,ResNet的文章,有兴趣的可以点进我的主页去查看。后续会更新Transformer、CLIP、GNN等的文章。
Vision Transformer(ViT)的介绍
ViT是在2020年谷歌的论文<AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE>(一个图片等价于16*16的单词:Transformer用于大规模的视觉识别)中提出的,首次将Transformer这个NLP的框架引入到了CV领域,使图片按照序列的处理方式并在大规模的数据集上进行训练,并取得了不错的效果。
归纳偏置
论文中提到了CNN中最核心的卷积核的归纳偏置,也就是局部性,平移不变性,参数共享
局部性:如的卷积核关注的范围那么大
平移不变性:无论模型怎么平移,都可以识别出卷积核对应的特征
参数共享:一个卷积核对图片的进行卷积时,有共同的参数,无论卷积核扫的是图片左上角,左下角等
然而由于ViT采取了Transformer的encoder,使用了多头注意力机制来处理图像序列,比CNN原来的局部性、平移不变性、参数共享的归纳偏置弱得多,但是Transformer这样的大型框架是需要很多数据的,这样才能发挥Vision Transformer的优势。
NLP框架究竟如何处理CV的图像
文本的处理
首先要明确的是Vision Transformer使用的是Transformer中的encoder,这个encoder主要用于提取数据中的特征,在NLP中指的是不同的离散的文本符号,词语、句子之间的关系、顺序性。在CV中是图片中的特征,如猫耳朵的形状、颜色等。
Transformer中处理的是一个序列模型,做的主要任务是机器翻译,实现一个序列到另一个序列的翻译,如Hello Deep Learning!(23,56,12)->你 好 深 度 学 习12,3,1,645,67,4。一个句子就可以看作为一个序列,是一维的,这个很直观。
图像的处理
**但是图片并不是一个序列,他是一个二维矩阵。****在CV领域输入的图片是有大小的,比如,**这个是二维的,不能直接放到Transformer中。
于是我们会这样处理:把一个的图片展平为一个长为50176的一维序列
时间复杂度分析
但此时还有非常严重的问题(此时我直接把时间复杂度的结果拿出来,有感兴趣的可以专注我后面Transformer的文章):为序列长度,
为特征维度,Transformer的FFN(全连接层的)复杂度为
而Self-Attention(自注意力机制)的复杂度为
所以总的时间复杂度为
如果直接把一个的图片序列化,那么序列长度为
,但是时间复杂度
的主导项是
,直接输入50176的序列会占用非常大的GPU显存,。需要存储约 25 亿个注意力权重参数,显存消耗巨大。
但如果我们把一个图片切成大小,那么此时的序列长度为
,带入
,此时的结果远小于上面的
。所以把图片切成
此时的**权重参数为6.5万,**GPU的显存占用降低。
相关工作
ICLR2020
在VIT的论文中明确指出了有一篇论文和他们的工作最像,这篇论文在2020发表在
计算机顶会ICLR(International Conference on Learning Representations)
的论文<Stand-Alone Self-Attention in Vision Models>。他们的最先是把图片打成的图片块(patch),然后用Transformer的endoer来处理。但是这篇论文有很多局限性:
(1)他使用的数据集是非常小的cifar10,cifar10的特点是: 6万张 32×32 像素的彩色 RGB 图像,通道数为 3。Transformer具有较弱的归纳偏置和数据饥渴,他们使用的数据集难以体现出Transformer的优势。
(2)他使用的模型仍然保留了计算机视觉中的复杂框架,并不是采取的完全的Transformer架构。
(3)他使用的patch大小仅仅为,这就会导致序列过长 ,如果是简单的图像分类
,这都有
个图像块,导致序列过长(后续详细讨论)
这篇2020 ICLR的链接是:
https://arxiv.org/abs/2001.09867
ICLR2021 best(VIT)
我们探讨的VIT是发表在2021年的ICLR,并成为2021 ICLR best。虽然这篇论文不是最早把图片打成一个一个patch来处理的,但是VIT做出了很多贡献。
(1)Google团队使用很多大的数据集,包括他们自制的JFT-300M(包含3亿张图片和1.8万的分类),ImageNet-21k(包含1400万图片和2.1万的分类)等等,通过这些巨大的数据集,他们超越了当时的SOTA(state of the art-最好的)模型ResNet152(我前面有ResNet152的介绍),实现了ImageNet88.5%的效果
(2)VIT采取了尽可能简单的框架,是首次尽量只直接使用Transformer中的encoder,推动了Transformer在视觉中的应用
(3)他们采取的patch大小是,这就会使得模型处理的序列长度不太长,可以推广到图像分类和目标检测、语义分割等任务 。因为像目标检测、语义分割有的图片要求大小为
甚至更大,这就体现出patch大的优势-序列不会过长
总结:不同任务的典型尺寸对照表
| 视觉任务 | 典型输入尺寸 | 核心考量因素 |
|---|---|---|
| 图像分类 | 224×224、384×384 | 全局特征提取,算力与精度平衡 |
| 目标检测 | 416×416、640×640、800×1333 | 小目标保留,检测速度与召回率 |
| 语义分割 | 512×512、1024×1024 | 逐像素精度,边界还原能力 |
| 实例分割 | 640×640、800×1333 | 检测 + 分割双重需求,掩码精细度 |
| 关键点检测 | 256×192、384×288 | 目标长宽比匹配,关键点定位精度 |
| 图像生成 | 512×512、1024×1024 | 生成图像保真度,显存限制 |
核心框架
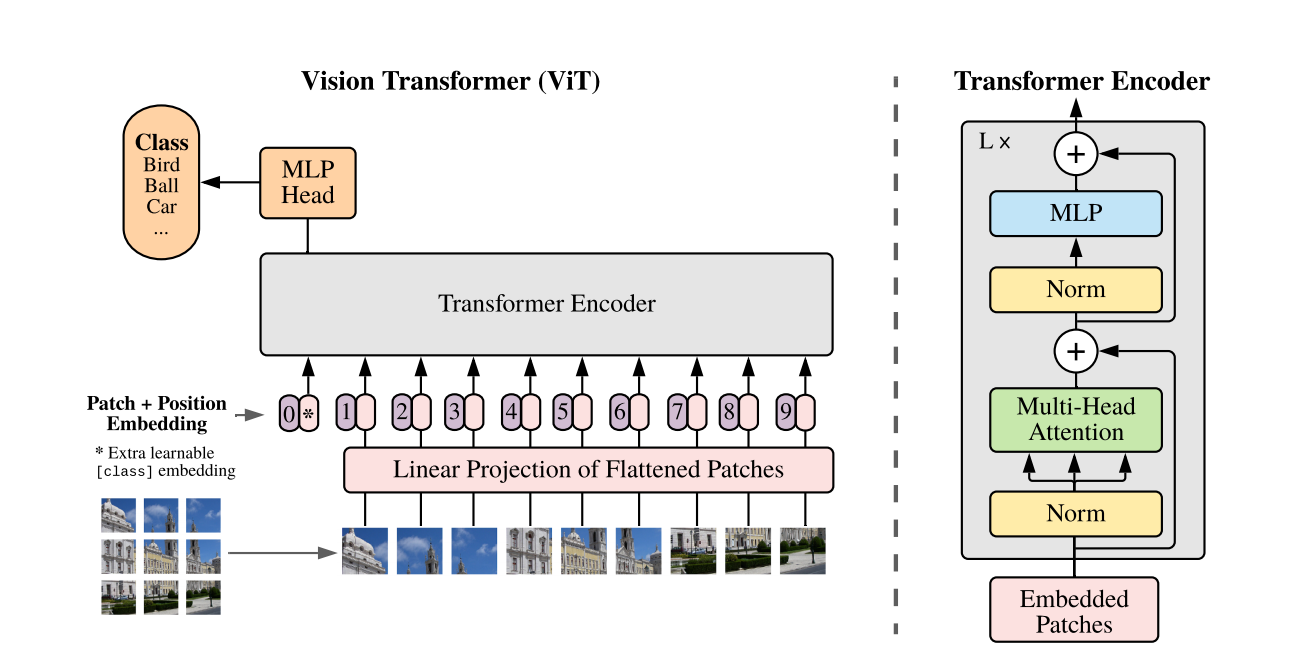
PatchEmbedding
通过我们刚才的介绍我们大概知道了VIT是如何处理图像输入的,他是先把一个很大的图片切成小小的块,如,也就是把,通过这样的处理可以使得每个序列长度变得很短,使得二维的图像能转化一维的token序列,同时降低了模型的训练成本。
有关计算:
假设输入图像是,图像块的大小是
,图像块的维度是
,那么图像块的个数为
。在图像块(Patch)展平之后,通过一个线性投影层(Linear Projectiom)投影到
,经过一系列操作,得到了
的维度。
、下面是PatchEmbedding对应代码:
python
import torch
import torch.nn as nn
class PatchEmbeddingConv(nn.Module):
"""用卷积实现的Patch Embedding(高效版)"""
def __init__(self, img_size=224, patch_size=16, in_channels=3, embed_dim=768):
super().__init__()
self.img_size = (img_size, img_size)
self.patch_size = (patch_size, patch_size)
# 计算Patch数量:(224/16)×(224/16)=196
self.num_patches = (self.img_size[0] // self.patch_size[0]) * (self.img_size[1] // self.patch_size[1])
# 卷积层等价于"Patch展平+线性投影"
self.proj = nn.Conv2d(
in_channels=in_channels,
out_channels=embed_dim,
kernel_size=patch_size, # 刚好覆盖一个Patch
stride=patch_size # 步长=Patch尺寸,实现非重叠分块
)
def forward(self, x):
# x: [batch_size, 3, 224, 224]
x = self.proj(x) # [batch_size, 768, 14, 14] → 每个位置对应一个Patch的投影
x = x.flatten(2) # [batch_size, 768, 196] → 展平成序列
x = x.transpose(1, 2) # [batch_size, 196, 768] → 调整维度为[B, 序列长度, 嵌入维度]
return xCLS头
VIT这里的CLS是借鉴了BERT中CLS,用于NSP任务是否为句子B是否为句子A的下一个句子,其中使用CLS这个特殊标记来记录所有token之间的关系,原因是Transformer的自注意力机制可以实现开头的CLS特殊标记和其他所有的token之间相互交互,经过多层注意力机制,特殊标记CLS融合了序列的所有特征。
VIT中的CLS也是类似的,他是放到**整个序列开头的特殊标记,经过了多层的注意力机制,**CLS融入了所有token的特征,在VIT中称为图像块Patch,最后可以实现视觉中的分类任务。
python
class ClassToken(nn.Module):
def __init__(self, embed_dim=768):
super().__init__()
# 初始化一个可学习的向量:[1, 1, embed_dim](1个Token,维度与Patch Embedding一致)
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
def forward(self, x):
# x: [batch_size, num_patches, embed_dim](如[B, 196, 768])
batch_size = x.shape[0]
# 将Class Token复制到整个批次:[B, 1, 768]
cls_token = self.cls_token.expand(batch_size, -1, -1)
# 拼接在Patch序列的最前面:[B, 196+1=197, 768]
x = torch.cat([cls_token, x], dim=1)
return xPositionEmbedding
虽然我们通过PatchEmbedding把一个图片切成196个
的图片块(Patch)或者称为196个Token,但此时模型并不知道这些64个图片块的顺序先后。
于是我们引入了位置编码(PositionEmbedding)来区分第一个,第二个...第六十四个图像块(Patch)
在Transformer中也用了位置编码,是正余弦的位置编码 。于是,作者也借鉴了Transformer用了位置编码,只不过这里的位置编码是可学习的位置嵌入编码,具体在代码的体现是nn.Parameter。
所以VIT的位置编码会随着反向传播而变化,但是Transformer中的位置编码就是固定的正余弦编码。
python
class PositionEmbedding(nn.Module):
def __init__(self, num_patches=196, embed_dim=768):
super().__init__()
# 可学习的位置嵌入:长度=num_patches+1(包含Class Token),维度=embed_dim
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim))
def forward(self, x):
# x: [batch_size, num_patches+1, embed_dim](如[B, 197, 768])
# 直接将位置嵌入加到输入序列上(广播机制自动匹配批次)
x = x + self.pos_embed
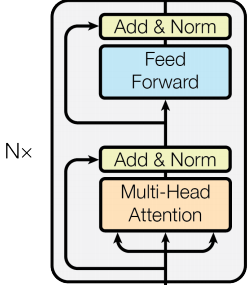
return xTransformer中的encoder
VIT中直接使用了Transformer中的encoder这个框架,而不像他的前人或多或少使用了CNN。
MLP头
GELU函数的公式,如下图,GELU 是ViT 专用激活函数,比 ReLU 更平滑:
GELU函数的图像
MLP的流程图
全局特征 z [B, D]
↓
Linear 1: z → h [B, D_hidden] (隐藏层维度 D_hidden 通常等于 D)
↓
GELU 激活函数 (引入非线性,避免线性映射的信息损失)
↓
Dropout(可选) (防止过拟合,训练阶段生效)
↓
Linear 2: h → logits [B, C] (C 是分类任务的类别数)
↓
Softmax 函数 (将 logits 转换为概率分布)
↓
分类概率 [B, C]
python
class ViTMLPHead(nn.Module):
def __init__(self, embed_dim=768, num_classes=1000, hidden_dim=None, dropout=0.1):
"""
ViT 分类头(MLP Head)
:param embed_dim: Encoder 输出的特征维度(对应 D),默认 ViT-B/16 的 768
:param num_classes: 分类类别数,默认 ImageNet 的 1000 类
:param hidden_dim: MLP 隐藏层维度,默认等于 embed_dim
:param dropout: Dropout 概率,防止过拟合
"""
super().__init__()
hidden_dim = hidden_dim or embed_dim # 隐藏层维度默认和嵌入维度一致
self.dropout = nn.Dropout(dropout)
# MLP 两层全连接
self.fc1 = nn.Linear(embed_dim, hidden_dim) # 第一层:[B, D] → [B, D_hidden]
self.fc2 = nn.Linear(hidden_dim, num_classes) # 第二层:[B, D_hidden] → [B, C]
def forward(self, encoder_output):
"""
前向传播:Encoder 输出 → MLP Head → logits/概率
:param encoder_output: Encoder 输出张量,shape [B, L, D]
B=batch_size, L=序列长度(patch数+1), D=嵌入维度
:return: logits (未归一化得分), probabilities (归一化概率)
"""
# 步骤1:提取 class token 特征(取序列维度的第0个token)
class_token = encoder_output[:, 0, :] # shape: [B, D]
# 步骤2:MLP 前向计算
x = self.fc1(class_token) # [B, D] → [B, D_hidden]
x = F.gelu(x) # GELU 激活(引入非线性)
x = self.dropout(x) # Dropout(训练阶段生效)
logits = self.fc2(x) # [B, D_hidden] → [B, C],未归一化得分
# 步骤3:计算分类概率(推理阶段用)
probabilities = F.softmax(logits, dim=-1) # 在类别维度归一化,shape [B, C]
return logits, probabilities代码实战
实现思路
- 数据预处理:CIFAR-100 图像尺寸是 32x32,ViT 通常处理 224x224 的图像,因此需要先将图像 resize 到合适尺寸,并进行标准化等数据增强。
- ViT 模型定义:实现标准的 ViT 结构,包括图像分块、位置编码、多头注意力、前馈网络和 Transformer 编码器。
- 训练配置:设置优化器、学习率调度器、损失函数等训练参数。
- 训练与验证:编写训练循环,实时监控训练和验证精度,保存最佳模型。
python
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
from torchvision.transforms import Compose, Resize, ToTensor, Normalize, RandomHorizontalFlip, RandomCrop
import numpy as np
from tqdm import tqdm
import os
# 设置随机种子,保证结果可复现
def set_seed(seed=42):
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
np.random.seed(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
set_seed()
# 检查GPU是否可用
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"使用设备: {device}")
# -------------------------- 1. 数据预处理 --------------------------
# CIFAR-100的均值和标准差
CIFAR100_MEAN = (0.5071, 0.4867, 0.4408)
CIFAR100_STD = (0.2675, 0.2565, 0.2761)
# 数据增强和预处理
train_transform = Compose([
Resize((224, 224)), # ViT默认输入尺寸224x224
RandomCrop(224, padding=4),
RandomHorizontalFlip(),
ToTensor(),
Normalize(mean=CIFAR100_MEAN, std=CIFAR100_STD)
])
val_transform = Compose([
Resize((224, 224)),
ToTensor(),
Normalize(mean=CIFAR100_MEAN, std=CIFAR100_STD)
])
# 加载CIFAR-100数据集
train_dataset = datasets.CIFAR100(
root='./data', train=True, download=True, transform=train_transform
)
val_dataset = datasets.CIFAR100(
root='./data', train=False, download=True, transform=val_transform
)
# 创建数据加载器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=4)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False, num_workers=4)
# -------------------------- 2. ViT模型定义 --------------------------
class PatchEmbedding(nn.Module):
"""将图像分割为patch并进行嵌入"""
def __init__(self, img_size=224, patch_size=16, in_channels=3, embed_dim=768):
super().__init__()
self.img_size = img_size
self.patch_size = patch_size
self.num_patches = (img_size // patch_size) ** 2
# 卷积层实现patch分割和嵌入
self.proj = nn.Conv2d(
in_channels, embed_dim, kernel_size=patch_size, stride=patch_size
)
def forward(self, x):
# x: [batch_size, 3, 224, 224]
x = self.proj(x) # [batch_size, embed_dim, num_patches**0.5, num_patches**0.5]
x = x.flatten(2) # [batch_size, embed_dim, num_patches]
x = x.transpose(1, 2) # [batch_size, num_patches, embed_dim]
return x
class MultiHeadAttention(nn.Module):
"""多头自注意力机制"""
def __init__(self, embed_dim=768, num_heads=12, dropout=0.):
super().__init__()
self.embed_dim = embed_dim
self.num_heads = num_heads
self.head_dim = embed_dim // num_heads
assert self.head_dim * num_heads == embed_dim, "embed_dim must be divisible by num_heads"
self.qkv = nn.Linear(embed_dim, embed_dim * 3)
self.dropout = nn.Dropout(dropout)
self.proj = nn.Linear(embed_dim, embed_dim)
def forward(self, x):
batch_size, num_patches, embed_dim = x.shape
# 生成Q, K, V: [batch_size, num_patches, 3*embed_dim]
qkv = self.qkv(x).reshape(batch_size, num_patches, 3, self.num_heads, self.head_dim)
qkv = qkv.permute(2, 0, 3, 1, 4) # [3, batch_size, num_heads, num_patches, head_dim]
q, k, v = qkv[0], qkv[1], qkv[2]
# 计算注意力分数
attn = (q @ k.transpose(-2, -1)) * (self.head_dim ** -0.5)
attn = attn.softmax(dim=-1)
attn = self.dropout(attn)
# 注意力加权求和
out = (attn @ v).transpose(1, 2).reshape(batch_size, num_patches, embed_dim)
out = self.proj(out)
out = self.dropout(out)
return out
class FeedForward(nn.Module):
"""前馈网络"""
def __init__(self, embed_dim=768, hidden_dim=3072, dropout=0.):
super().__init__()
self.net = nn.Sequential(
nn.Linear(embed_dim, hidden_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim, embed_dim),
nn.Dropout(dropout)
)
def forward(self, x):
return self.net(x)
class TransformerEncoderBlock(nn.Module):
"""Transformer编码器块"""
def __init__(self, embed_dim=768, num_heads=12, hidden_dim=3072, dropout=0.):
super().__init__()
self.norm1 = nn.LayerNorm(embed_dim)
self.attn = MultiHeadAttention(embed_dim, num_heads, dropout)
self.norm2 = nn.LayerNorm(embed_dim)
self.ffn = FeedForward(embed_dim, hidden_dim, dropout)
def forward(self, x):
# 注意力残差连接
x = x + self.attn(self.norm1(x))
# 前馈网络残差连接
x = x + self.ffn(self.norm2(x))
return x
class ViT(nn.Module):
"""Vision Transformer主模型"""
def __init__(
self,
img_size=224,
patch_size=16,
in_channels=3,
num_classes=100,
embed_dim=768,
depth=12,
num_heads=12,
hidden_dim=3072,
dropout=0.,
emb_dropout=0.
):
super().__init__()
# Patch嵌入
self.patch_embed = PatchEmbedding(img_size, patch_size, in_channels, embed_dim)
num_patches = self.patch_embed.num_patches
# 类别嵌入(cls token)
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
# 位置编码
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim))
self.pos_drop = nn.Dropout(emb_dropout)
# Transformer编码器
self.encoder = nn.Sequential(
*[TransformerEncoderBlock(embed_dim, num_heads, hidden_dim, dropout)
for _ in range(depth)]
)
# 分类头
self.norm = nn.LayerNorm(embed_dim)
self.head = nn.Linear(embed_dim, num_classes)
# 初始化权重
nn.init.trunc_normal_(self.pos_embed, std=0.02)
nn.init.trunc_normal_(self.cls_token, std=0.02)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
nn.init.trunc_normal_(m.weight, std=0.02)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def forward(self, x):
batch_size = x.shape[0]
# Patch嵌入
x = self.patch_embed(x)
# 添加cls token
cls_token = self.cls_token.expand(batch_size, -1, -1)
x = torch.cat((cls_token, x), dim=1)
# 添加位置编码
x = x + self.pos_embed
x = self.pos_drop(x)
# Transformer编码
x = self.encoder(x)
# 分类(仅使用cls token的输出)
x = self.norm(x)
x = x[:, 0] # 取cls token的输出
x = self.head(x)
return x
# -------------------------- 3. 训练配置 --------------------------
# 创建ViT模型(使用小型ViT配置,适配CIFAR-100)
model = ViT(
img_size=224,
patch_size=16,
num_classes=100,
embed_dim=256, # 减小嵌入维度,降低计算量
depth=6, # 减少编码器层数
num_heads=8, # 减少注意力头数
hidden_dim=1024
).to(device)
# 损失函数、优化器、学习率调度器
criterion = nn.CrossEntropyLoss()
optimizer = optim.AdamW(model.parameters(), lr=1e-3, weight_decay=0.03)
scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=100)
# 训练参数
num_epochs = 100
best_val_acc = 0.0
save_path = "./vit_cifar100_best.pth"
# -------------------------- 4. 训练和验证 --------------------------
def train_one_epoch(model, loader, criterion, optimizer, device):
model.train()
total_loss = 0.0
total_correct = 0
total_samples = 0
pbar = tqdm(loader, desc="Training")
for images, labels in pbar:
images, labels = images.to(device), labels.to(device)
# 前向传播
outputs = model(images)
loss = criterion(outputs, labels)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 统计
total_loss += loss.item() * images.size(0)
_, preds = torch.max(outputs, 1)
total_correct += (preds == labels).sum().item()
total_samples += images.size(0)
# 更新进度条
pbar.set_postfix({
'loss': total_loss / total_samples,
'acc': total_correct / total_samples
})
avg_loss = total_loss / total_samples
avg_acc = total_correct / total_samples
return avg_loss, avg_acc
def validate(model, loader, criterion, device):
model.eval()
total_loss = 0.0
total_correct = 0
total_samples = 0
with torch.no_grad():
pbar = tqdm(loader, desc="Validating")
for images, labels in pbar:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
total_loss += loss.item() * images.size(0)
_, preds = torch.max(outputs, 1)
total_correct += (preds == labels).sum().item()
total_samples += images.size(0)
pbar.set_postfix({
'loss': total_loss / total_samples,
'acc': total_correct / total_samples
})
avg_loss = total_loss / total_samples
avg_acc = total_correct / total_samples
return avg_loss, avg_acc
# 开始训练
for epoch in range(num_epochs):
print(f"\nEpoch {epoch+1}/{num_epochs}")
print("-" * 50)
# 训练
train_loss, train_acc = train_one_epoch(model, train_loader, criterion, optimizer, device)
# 验证
val_loss, val_acc = validate(model, val_loader, criterion, device)
# 更新学习率
scheduler.step()
# 打印结果
print(f"Train Loss: {train_loss:.4f}, Train Acc: {train_acc:.4f}")
print(f"Val Loss: {val_loss:.4f}, Val Acc: {val_acc:.4f}")
print(f"Current LR: {optimizer.param_groups[0]['lr']:.6f}")
# 保存最佳模型
if val_acc > best_val_acc:
best_val_acc = val_acc
torch.save({
'epoch': epoch + 1,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'best_val_acc': best_val_acc,
}, save_path)
print(f"保存最佳模型,验证精度: {best_val_acc:.4f}")
# 加载最佳模型并测试
checkpoint = torch.load(save_path)
model.load_state_dict(checkpoint['model_state_dict'])
final_val_loss, final_val_acc = validate(model, val_loader, criterion, device)
print(f"\n最终最佳验证精度: {final_val_acc:.4f}")代码关键部分解释
-
数据预处理:
- 将 CIFAR-100 的 32x32 图像 resize 到 224x224(ViT 的标准输入尺寸)
- 添加随机裁剪、水平翻转等数据增强,防止过拟合
- 使用 CIFAR-100 专用的均值和标准差进行归一化
-
ViT 核心组件:
PatchEmbedding:将图像分割为 16x16 的 patch,并通过卷积层转换为嵌入向量MultiHeadAttention:实现多头自注意力机制,捕捉图像不同区域的依赖关系TransformerEncoderBlock:包含注意力层和前馈网络,带残差连接和层归一化ViT:主模型,添加 cls token 和位置编码,最终用 cls token 的输出做分类
-
训练策略:
- 使用 AdamW 优化器(带权重衰减的 Adam),适合 Transformer 模型
- 余弦退火学习率调度器,动态调整学习率
- 保存验证精度最高的模型,防止过拟合
面试问题
1. 请简述 ViT 的核心思想和基本架构
核心思想 :将图像分割为固定大小的 patch(图像块) ,把每个 patch 展平为一维向量并添加位置编码,然后将其输入到标准的 Transformer Encoder 中进行特征学习,最后通过一个分类头(如 MLP)完成图像分类。本质是将视觉问题转化为序列建模问题,与 NLP 中的 Transformer 处理方式一致。
基本架构:
Patch Embedding
将输入二维图像 分割为
个大小为
的 patch,其中
每个 patch 展平为 P2C 维向量,再通过一个线性层映射到 维(Transformer 的输入维度),
为特征维度得到维度为
的 patch 序列。
- 类比:NLP 中的单词嵌入(Word Embedding)。
Class Token & Position Embedding
- Class Token:在 patch 序列前添加一个可学习的向量 z00,其作用是聚合整个图像的特征,最终仅用该向量进行分类(类似 BERT 中的 `` token)。
- Position Embedding :由于 Transformer 是置换不变性 的,需要添加位置编码来保留 patch 的空间位置信息。ViT 采用可学习的一维位置编码 ,维度与 patch 序列一致(
,+1 对应 class token)。
Transformer Encoder
- 由多个 ** 多头注意力(MSA)和多层感知机(MLP)** 模块堆叠而成,每个模块前都有 Layer Normalization,模块后有残差连接。
- MSA(多头注意力机制):捕捉不同 patch 之间的全局依赖关系,这是 ViT 相比 CNN 的核心优势。
- MLP(多层感知机):对每个 patch 的特征进行独立的非线性变换,包含两层全连接和一层 GELU 激活函数。
Classification Head
- 取 Transformer Encoder 输出的 class token zL0(
2. ViT 的计算复杂度是多少?为什么在小数据集上表现不如 CNN?
计算复杂度 :ViT 的计算复杂度主要由 ** 多头注意力机制(MSA)和多层感知机(MLP)** 决定:
- MSA 的复杂度:
- MLP 的复杂度:
- 总体复杂度:
小数据集上表现不如 CNN 的原因:
- 归纳偏置(Inductive Bias)的缺失
- CNN 具有局部性、平移不变性等归纳偏置,这些偏置是人类从视觉任务中总结的先验知识,能够帮助模型在小数据集上快速收敛。
- ViT 几乎没有归纳偏置(仅通过 patch 分割保留了少量空间结构),需要大量数据来学习图像的特征规律,否则容易过拟合。
- 预训练的重要性
- ViT 在小数据集上的表现依赖于大规模预训练(如在 ImageNet-21k 或 JFT-300M 上预训练),然后在小数据集上微调。
- 如果直接在小数据集上训练 ViT,其性能会远低于 CNN。
3. Swin Transformer 与 ViT 的核心区别是什么?为什么 Swin Transformer 更适合密集预测任务?
核心区别:
| 特征 | ViT | Swin Transformer |
|---|---|---|
| 注意力机制 | 全局注意力(计算所有 patch 之间的注意力) | 窗口注意力(计算局部窗口内 patch 的注意力) |
| 层级结构 | 固定 patch 大小,无下采样 | 分层结构,逐步合并 patch(下采样),生成多尺度特征图 |
| 位置编码 | 可学习嵌入位置编码 | 相对位置编码 |
| 计算复杂度 |
Swin Transformer 更适合密集预测任务的原因:
- 密集预测任务 (如目标检测、语义分割)需要多尺度特征图(不同层级的特征对应不同大小的目标)。
- ViT 采用固定的 patch 大小,输出的特征图尺度单一,无法直接满足密集预测任务的需求。
- Swin Transformer 采用分层结构,通过逐步合并 patch 实现下采样,生成类似 CNN 的多尺度特征图(如 C1、C2、C3、C4 层),可以直接接入现有的检测 / 分割框架(如 FPN、Mask R-CNN)。
- 窗口注意力机制大幅降低了计算复杂度,使得 Swin Transformer 能够处理高分辨率图像(如 1024×1024),这对于密集预测任务至关重要。
4. ViT 需要大量数据才能 work 吗?为什么?
- 回答:是的。因为 ViT 缺乏 CNN 的归纳偏置(如平移不变性、局部性),在小数据集上容易过拟合。原始论文表明:只有在使用 JFT-300M 等大型预训练数据集时,ViT 才能超越 ResNet。后续工作(如 DeiT)通过蒸馏等技术使其在 ImageNet 上也能有效训练。
5 ViT 和 ViLT 有什么关系?
- 回答 :ViT 是纯视觉模型;ViLT(Vision-and-Language Transformer)是多模态模型,直接将 ViT 提取的视觉 token 与文本 token 一起输入跨模态 Transformer,不使用目标检测器(如 Faster R-CNN),强调模态间的早期融合。ViLT 启用了更高效、端到端的多模态处理范式。
6 ViT 是什么?它与 CNN 有什么区别?
- 回答:Vision Transformer(ViT)是将 Transformer 架构直接应用于图像分类任务的模型。它将输入图像划分为固定大小的 patch(如 16×16),将每个 patch 展平并通过线性嵌入得到 token,再输入标准 Transformer 编码器。
- 与 CNN 不同,ViT 不依赖卷积操作和局部归纳偏置(inductive bias),而是通过自注意力机制建模全局依赖。它在大规模数据上表现优异,但在小数据集上通常不如 CNN(除非使用强正则化或预训练)。