目录:
一、项目准备工作和基础操作
可以参看我的上一篇文章:
二、加载分词器
python
import torch
from transformers import AutoTokenizer
#加载tokenizer
tokenizer = AutoTokenizer.from_pretrained('google-bert/bert-base-chinese')
tokenizer
二、加载数据集
python
from datasets import load_dataset
#加载数据集
dataset = load_dataset(path='lansinuote/ChnSentiCorp')
dataset, dataset['train'][0]
三、数据处理
python
#定义数据集遍历工具
def collate_fn(data):
text = [i['text'] for i in data]
label = [i['label'] for i in data]
#文字编码
data = tokenizer(text,
padding=True,
truncation=True,
max_length=500,
return_tensors='pt',
return_token_type_ids=False)
#设置label
data['label'] = torch.LongTensor(label)
return data
loader = torch.utils.data.DataLoader(dataset['train'],
batch_size=8,
shuffle=True,
drop_last=True,
collate_fn=collate_fn)
data = next(iter(loader))
for k, v in data.items():
print(k, v.shape)
len(loader)
四、使用模型测试分类
python
#定义模型
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
#加载预训练模型
from transformers import AutoModel
self.pretrained = AutoModel.from_pretrained(
'google-bert/bert-base-chinese')
self.fc = torch.nn.Linear(in_features=768, out_features=2)
def forward(self, input_ids, attention_mask, label=None):
#使用预训练模型抽取数据特征
with torch.no_grad():
last_hidden_state = self.pretrained(
input_ids=input_ids,
attention_mask=attention_mask).last_hidden_state
#只取第0个词的特征做分类,这和bert模型的训练方式有关,此处不展开
last_hidden_state = last_hidden_state[:, 0]
#对抽取的特征只取第一个字的结果做分类即可
out = self.fc(last_hidden_state).softmax(dim=1)
#计算loss
loss = None
if label is not None:
loss = torch.nn.functional.cross_entropy(out, label)
return loss, out
model = Model()
model(**data)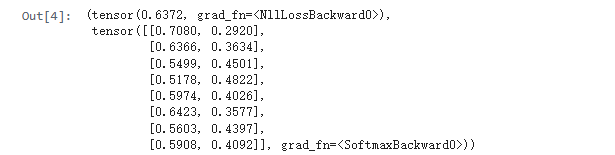
五、模型训练
python
#执行训练
def train():
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
for i, data in enumerate(loader):
loss, out = model(**data)
loss.backward()
optimizer.step()
optimizer.zero_grad()
if i % 10 == 0:
out = out.argmax(dim=1)
acc = (out == data.label).sum().item() / len(data.label)
print(i, len(loader), loss.item(), acc)
if i == 300:
break
train()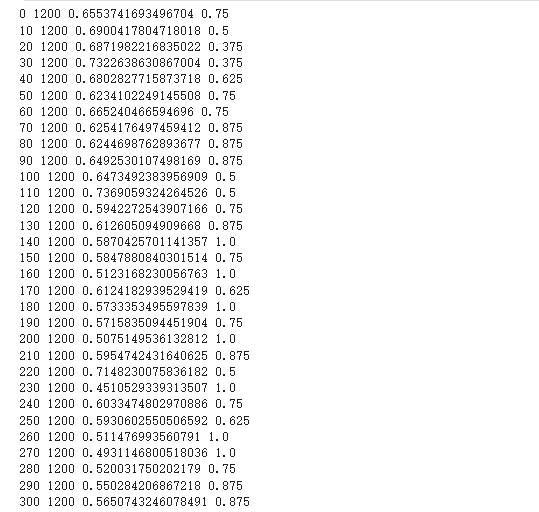
5.1、代码解读一
python
acc = (out == data.label).sum().item() / len(data.label)作用:
衡量模型 预测正确的样本比例,是分类任务中最直观的评价指标。
逐部分解析:
1、out == data.label
-
out:模型的预测结果(经过 softmax 后,通常取 argmax(dim=1) 得到类别索引,如 0, 1, 0, ...)。
-
data.label:真实标签(样本的正确类别,如 1, 1, 0, ...)。
-
比较结果:返回一个布尔张量(True/False),True 表示预测正确,False 表示预测错误。
-
例:out = 0, 1, 1,label = 0, 1, 0 → 比较结果为 True, True, False
2、.sum().item()
- .sum():将布尔张量中的 True(视为1)求和,得到 正确预测的样本数。 例:上述 True, True, False 求和后为 2(2个正确样本)。
- .item():将 PyTorch 张量转换为 Python 数值(如 tensor(2) → 2)。
3、/ len(data.label)
-
len(data.label):当前批次的总样本数(如一个 batch 有8个样本,则为8)。
-
最终结果:正确样本数 / 总样本数,即 准确率(Accuracy)。 例:2个正确 / 3个总样本 → 准确率 ≈ 66.7%。
5.2、代码解读二
python
loss = torch.nn.functional.cross_entropy(out, label):计算交叉熵损失作用:
衡量模型 预测概率与真实标签的差距,是训练过程中优化的目标(通过最小化 Loss 提升模型性能)。
逐部分解析:
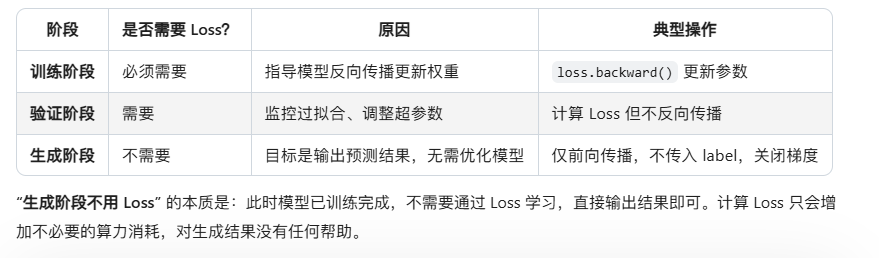
1、if label is not None
-
仅在 训练/验证阶段 计算 Loss(此时有真实标签 label)。
-
测试阶段(仅预测,无标签)可不计算 Loss,直接返回预测结果 out。
2、cross_entropy(out, label)
输入:
- out:模型的原始输出(Logits,未经过 softmax 的张量,形状为 batch_size, num_classes)。
- label:真实标签(形状为 batch_size,每个元素是类别索引,如 0 或 1)。
计算逻辑:
- 对 out 自动应用 softmax,得到每个类别的预测概率 p。
- 计算真实标签对应类别的负对数概率:-ln(p_true)(概率越低,Loss 越大)。
- 对 batch 内所有样本的 Loss 取平均值,得到最终的交叉熵损失。
例: 二分类中,样本真实标签为 1,模型预测 1 类的概率为 0.9 → Loss = -ln(0.9) ≈ 0.105;若概率为 0.1 → Loss = -ln(0.1) ≈ 2.303(差距越大,Loss 越大)。
3、return loss, out
- 返回 Loss(用于反向传播更新模型权重)和预测结果 out(用于计算准确率或后续处理)。
六、测试训练后的分类结果
python
#执行测试
def test():
loader_test = torch.utils.data.DataLoader(dataset['test'],
batch_size=8,
shuffle=True,
drop_last=True,
collate_fn=collate_fn)
correct = 0
total = 0
for i, data in enumerate(loader_test):
with torch.no_grad():
_, out = model(**data)
out = out.argmax(dim=1)
correct += (out == data.label).sum().item()
total += len(data.label)
print(i, len(loader_test), correct / total)
if i == 5:
break
return correct / total
test()
可以看到训练后的结果准确率比没有训练的准确率高出了不少。