前言:
上文我们讲到了Linux下的第一个程序:进度条【Linux】LInux下第一个程序:进度条-CSDN博客
本文我们来讲一讲Linux中下一个非常重要的东西:进程
1.冯诺依曼体系结构
我们所见的大部分计算机都是遵循的冯诺依曼体系结构
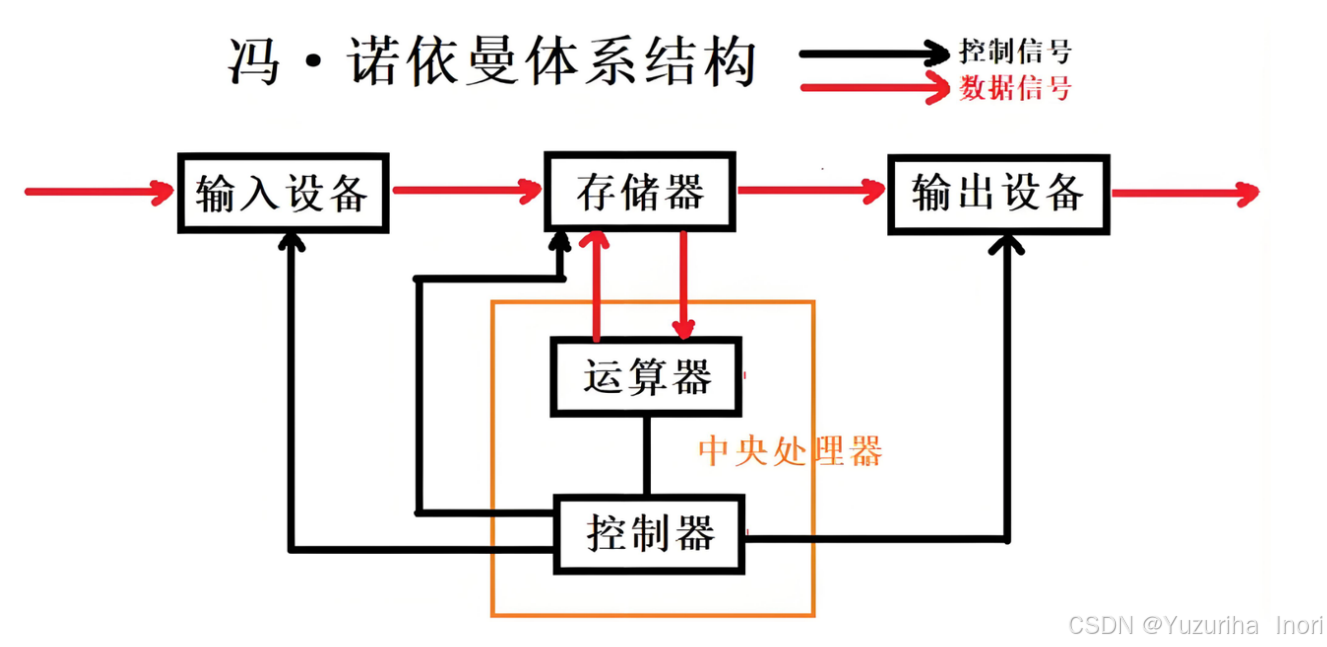
我们的计算机都是由一个个硬件所组成的
- 输出设备:显示器、音响、摄像头、网卡.......
- 输入设备:鼠标、键盘 、网卡.......
- 中央处理器(CPU):包含运算器、控制其等等等等......
对于冯诺依曼体系结构我们要注意以下几点:
- 存储器:其实就是我们所说的内存。相应的外存就是我们说所的磁盘
- 输入与输出(Input/Output,IO):输入与输出我们要站在内存的角度来看待,外设的数据流出内存叫做输入,内存将数据交给输入设备叫做输出。
- CPU与内存 :CPU在数据层面上只能直接访问内存,并不能直接访问硬件设备。所以一切软件的运行都想要先将其加载到内存才行。加载的本质其实是Input,数据从一个设备"拷贝"到另一个设备。拷贝的效率决定了体系结构的效率。
- 软件运行:软件的运行是通过CPU执行我们的代码,访问我们的数据来得以实现的。
- **理解内存:**假设没有内存,CPU直接从输入设备中拿去数据,再交由输出设备。我们知道输入设备与输出设备的速度是远远的慢与CPU的。这就导致了不论CPU有多快都没用,CPU始终要等着输入设备的数据过来才能开始处理,这个设备的效率全部取决于了外设。这显然是不合理的。
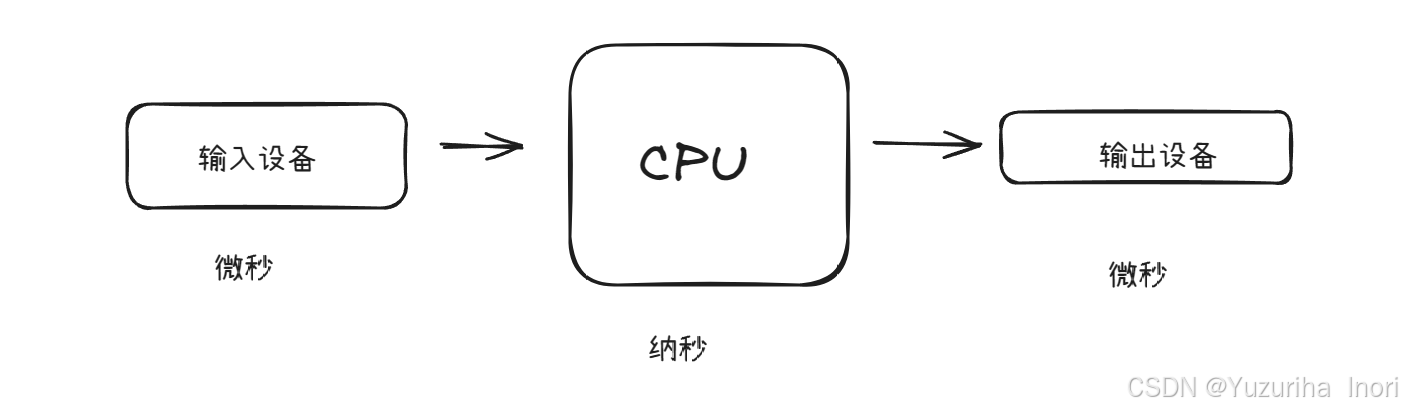
而内存的出现解决了,CPU与外设之间运算速度不匹配的弊端。内存会提前将输入设备中的数据拿过来,尽可能的减少CPU与外设之间的速度差。
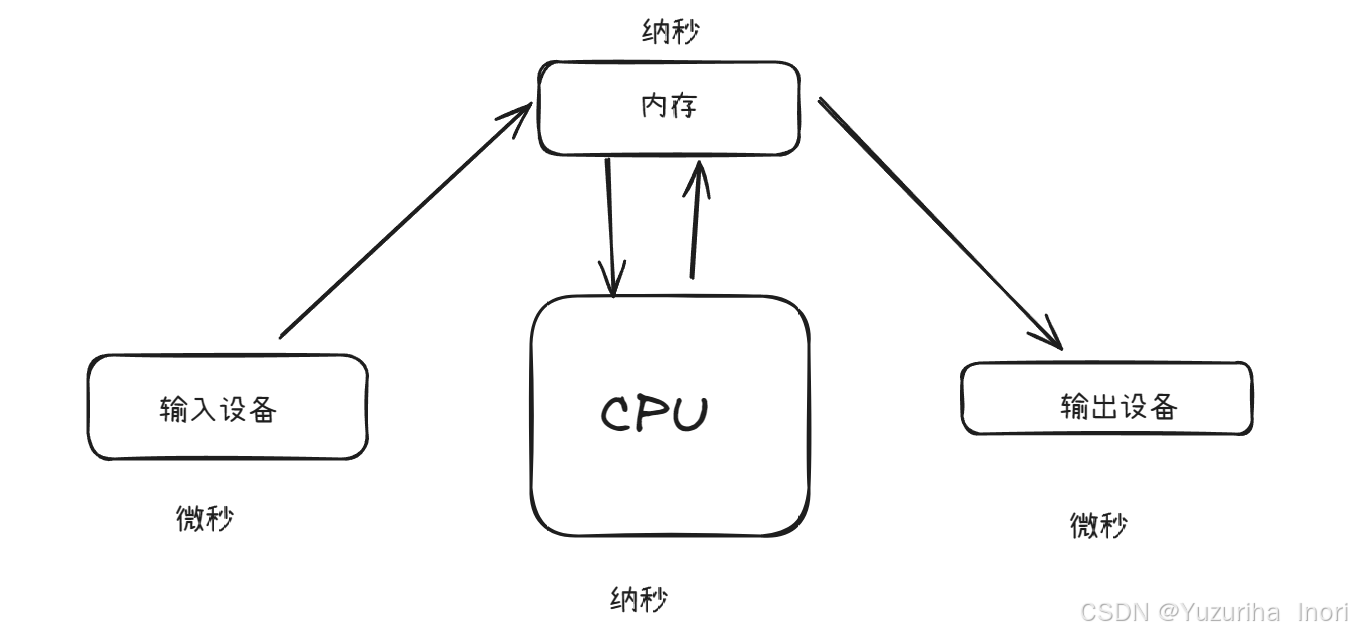
- 理解数据的流动:
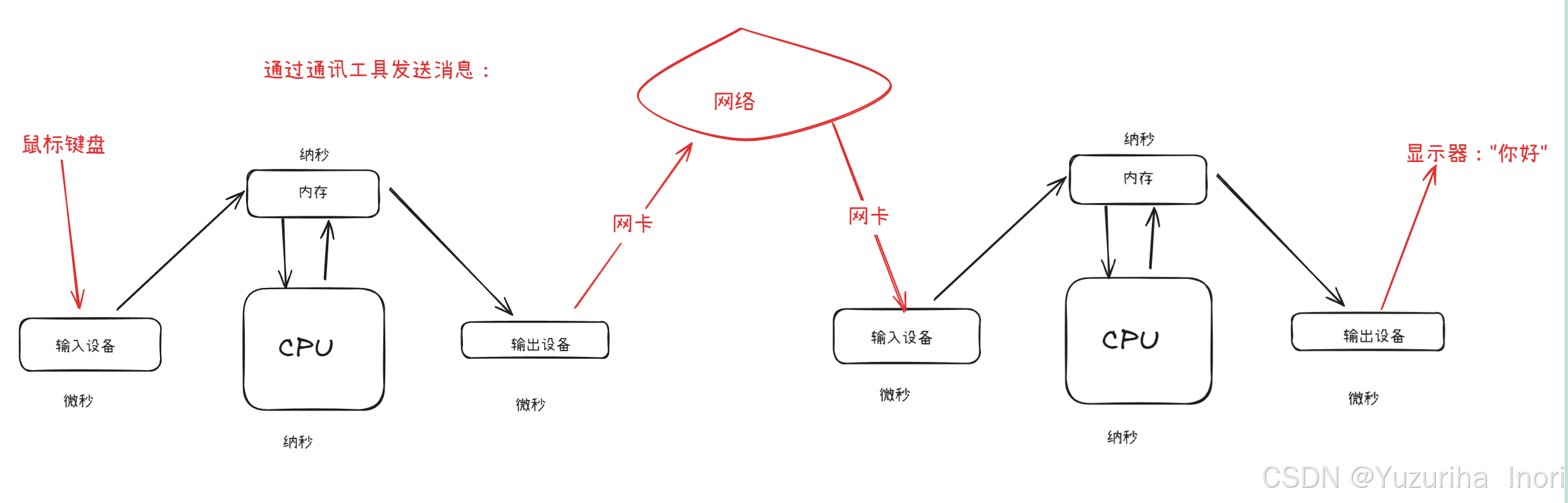
2.操作系统(Operator System)
2.1基本概念
任何一个计算机都包含一个最基本的程序:OS(操作系统)
操作系统本质是一款用于管理软硬件的软件
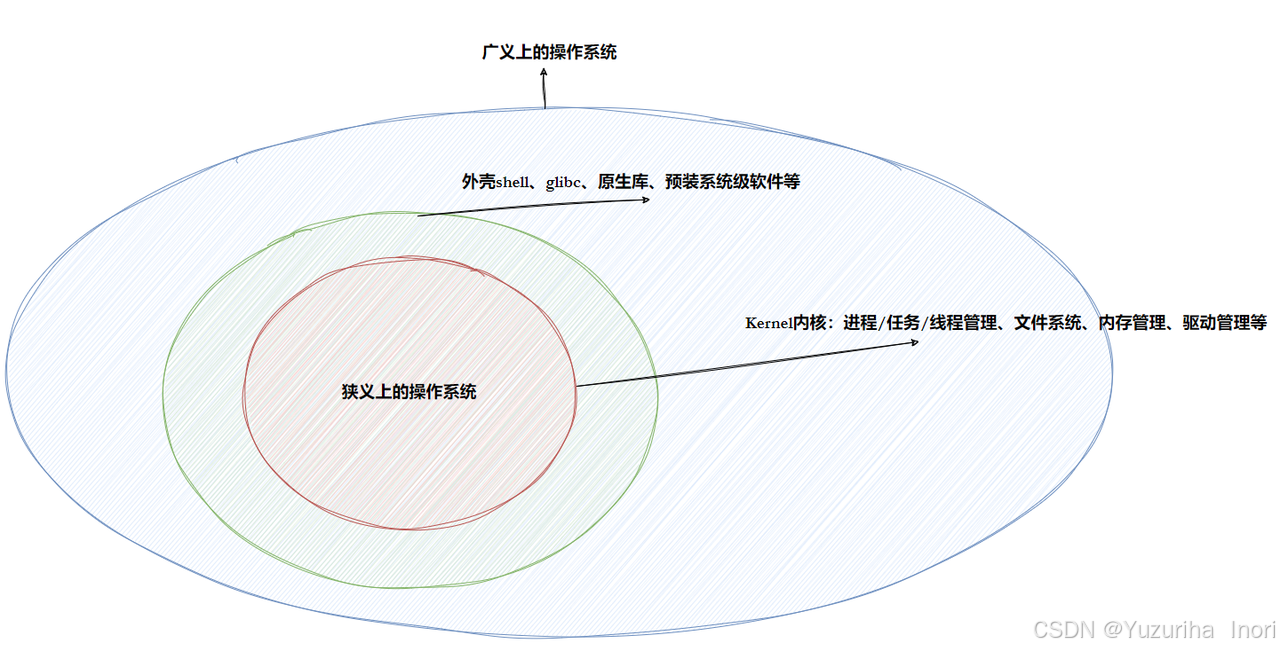
广义的操作系统包含:内核(进程管理、文件管理、内存管理、驱动管理)
其他程序(外壳shell、函数库等等等等)
狭义的操作系统包含:内核
2.2设计OS的目的是什么
对下:与硬件交互,管理软件与硬件的资源(手段)
对上:为应用程序提供一个良好的运行环境(目的)

注意:
1.操作系统是封装起来的任何人都无法访问其内部,只能通过操作系统给用户提供的接口(既系统调用)来执行功能
2.计算机上的任何操作都必须访问操作系统,且只能通过调用系统接口实现。其接口本质就是函数,只不过是系统提供的。
3.软硬件结构都为层状结构
4.我们的程序只要是访问了硬件(比如显示器,磁盘)那它就必定会贯穿整个软硬件体系结构
5.我们常用的库函数:printf,显示器上打印信息。它也访问了硬件设置,这也就意味着这个库函数底层封装了系统调用
2.3理解操作系统的"管理"
在学校的管理体系中,校长是管理层,辅导员是执行层,而学生则是被管理者。校长拥有决策权,而执行校长的决定不可能由校长亲自执行,而是辅导员来。
在计算机体系中,校长就相当于是操作系统。辅导员相当于是驱动程序。学生则相当于是底层硬件
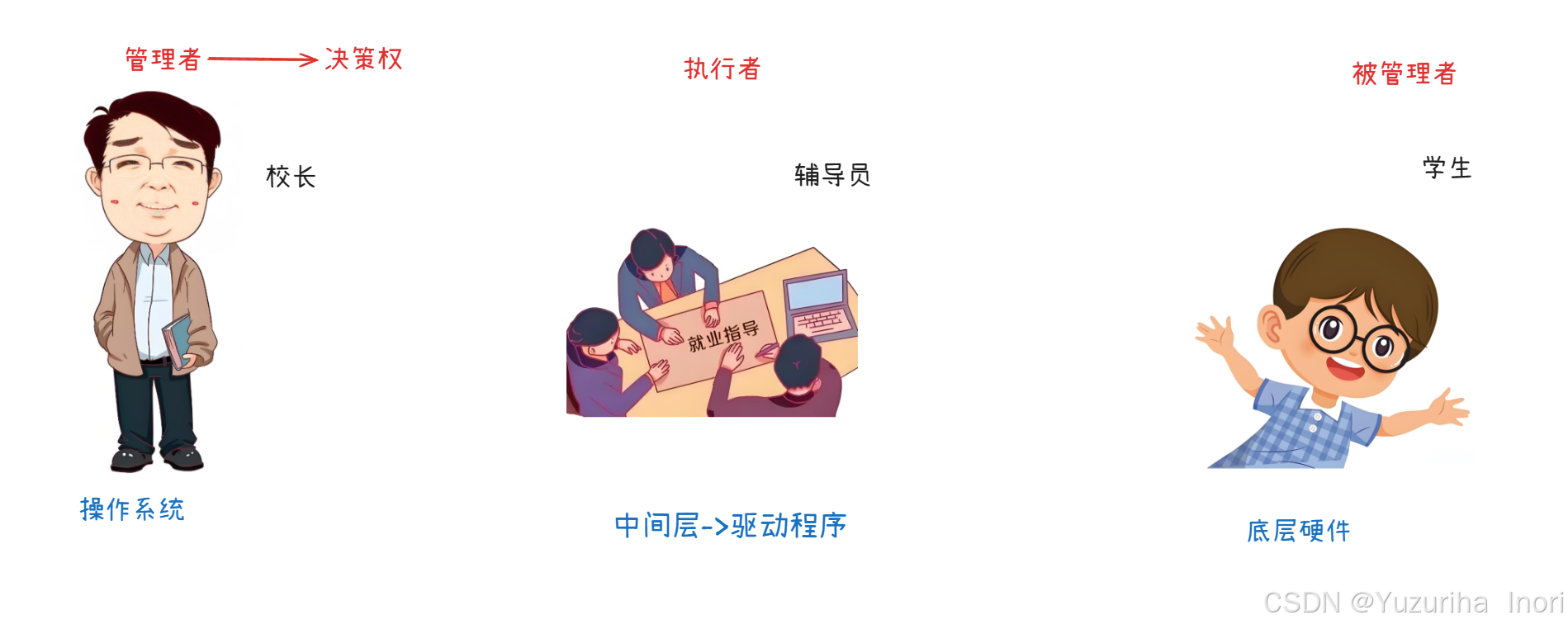
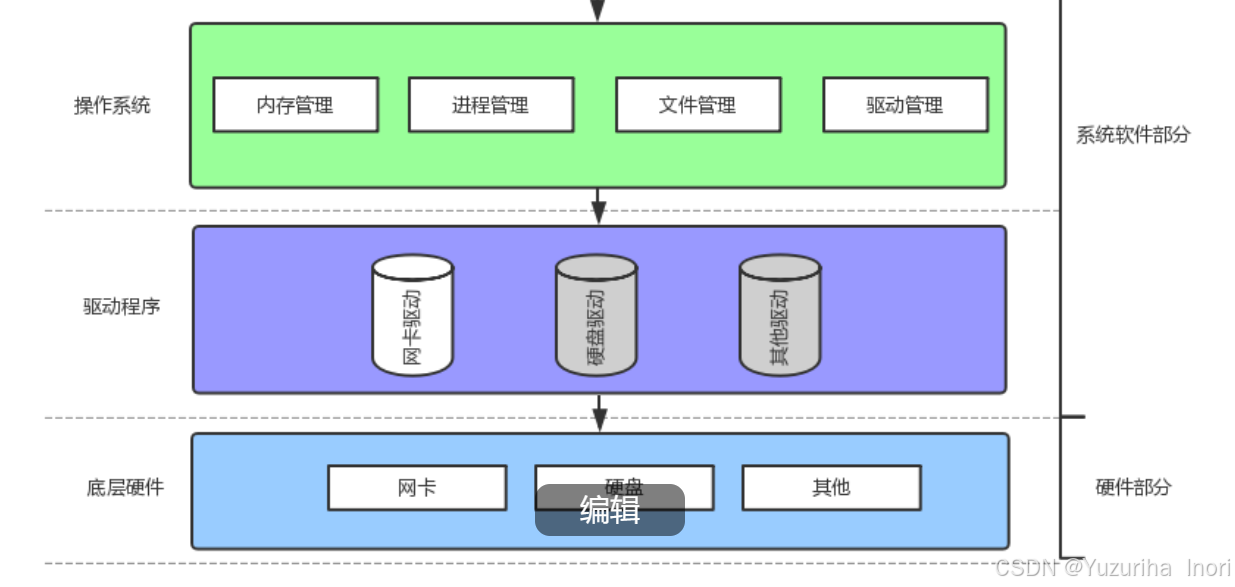
"校长"应该如何管理?
校长要管理学生,但是校长不可能将想要管理的学生一个个都喊到办公室来。校长与学生不必见面。更合理的做法是校长通过学生册里面的信息来进行管理,做出的决定交由辅导员来执行。
1.管理者与被管理者不必见面
2.管理者如何进行管理?通过数据进行管理
3.既然不见面,那数据从何而来?通过中间层"辅导员"--->驱动程序获得
"校长"管理方式进化之路
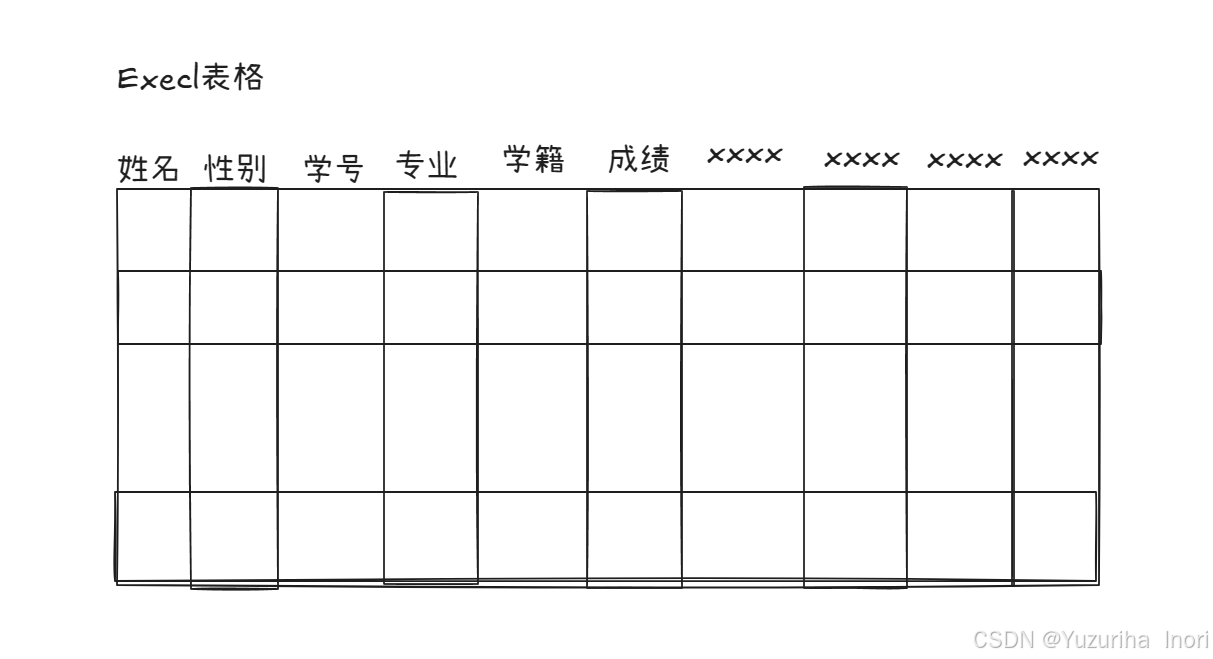
管理方式1.0:
通过表格来管理学生
管理方式2.0:
校长觉得表格管理太不方便了,于是想使用计算机来管理信息
先通过结构体来"描述"学生的信息,创建一个又一个对象来保存信息。
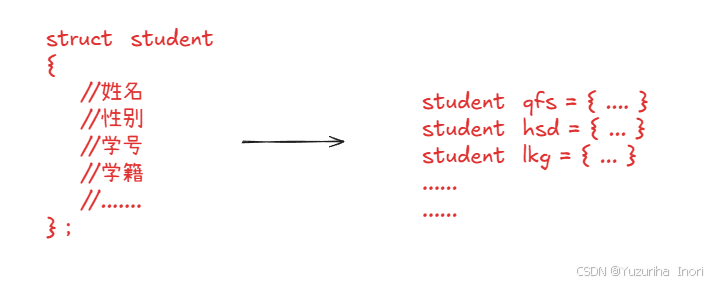
保存了众多学生数据,又如何管理这些数据呢?答案是通过数据结构来管理
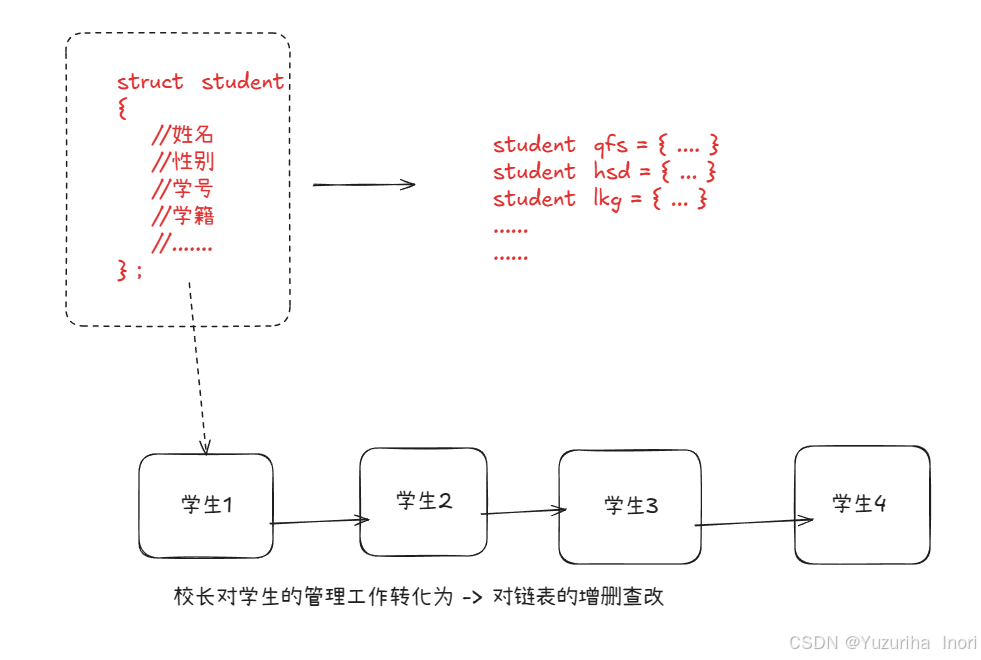
以上这种管理方式被我们称作:先描述再组织
那么操作系统是如何管理驱动程序、进程或者其他东西呢?答案也是先描述:使用类先表示属性,再组织:使用恰当的数据结构来进行管理。
2.4理解系统调用
1.操作系统要对上提供服务
2.操作系统不相信任何人
操作系统是为了我们更好的使用计算机。但操作系统是封装 起来的,任何人都不能访问其内部 ,想要使用操作系统只能通过操作系统提供 的"系统调用"。
操作系统就像银行,你要存钱或者取钱都只能在银行提供的ATM机或者窗口上办理,银行不可能让你自己进到银行金库里取钱或者存钱。
不论是Linux、windows还是macOS这些常见的操作系统都是用C语言 写的,所以"系统调用"的本质其实是C函数 ,只不过是由操作系统提供。通过调用系统提供的C函数让操作系统执行我们想要的操作。
仅仅有"系统调用" 对于不太了解操作系统的人来说上手还是太困难 了。所以为了我们普通人更好的使用操作系统,就有了我们所说的:库、shell外壳、指令等等。这些都是**在底层封装了"系统调用"**以便于我们更好的使用。这二者是上下层的关系
3.进程
3.1什么是进程?
我就不念叨书上晦涩难懂的定义了,看不懂也没啥用。直接上图!
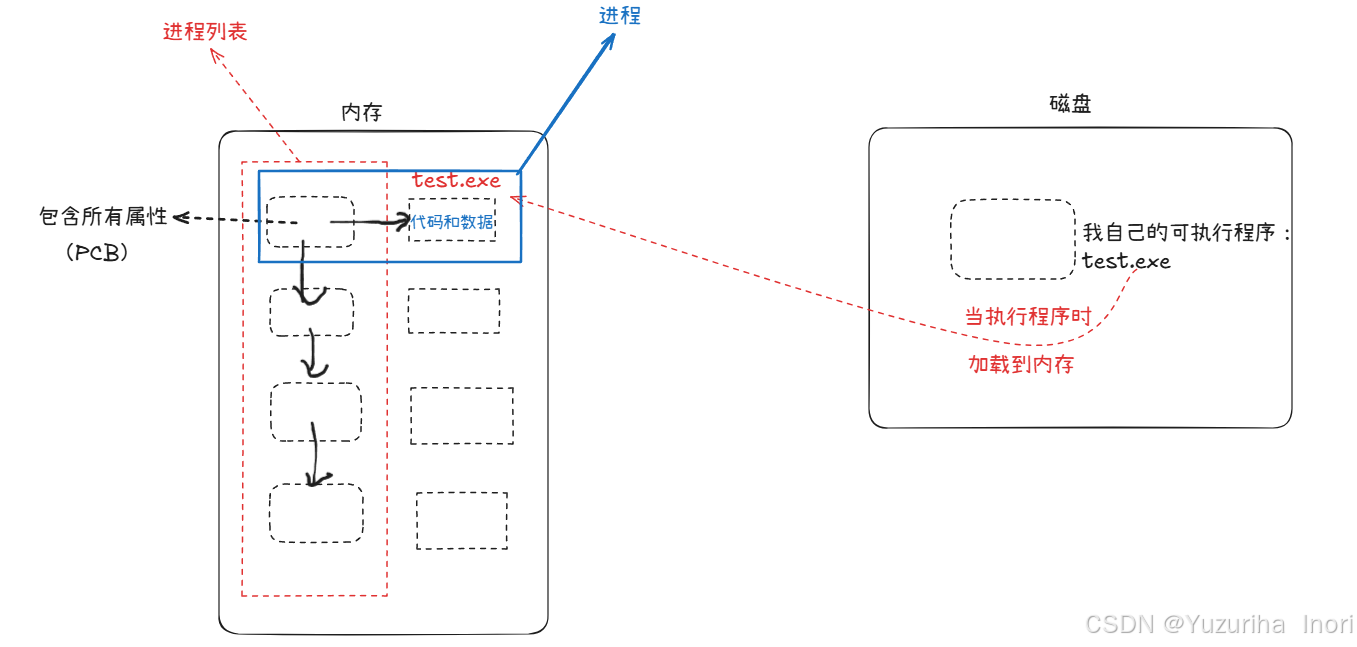
上面我们说到了操作系统的管理方式是:先描述再组织 。同样的操作系统管理进程也是先使用结构体"描述" 其中包含进程的所有属性,再使用数据结构"组织"。
当我们运行我们的可执行程序时,代码和数据会加载到内存中。此时操作系统会创建一个结构体,其中包含了test.exe的所有属性。并且会有对应的指针指向对应的代码和数据。
所谓进程 其实就是:包含对应所有属性的结构体对象+代码和数据
补充:进程的创建规则是由父进程创建子进程
PCB
操作系统创建包含所有属性的结构体有一个专业的名字叫做:进程控制块 。简称为PCB(process control block)
Linux操作系统下的PCB是:task_struct。是位于内核的一种数据结构,它会被装在到RAM(内存)中记载进程信息。
task_struct
我们知道了task_struct是一个结构体包含了进程的所有属性,那么大概有那些类型的属性呢?
- 标示符:描述本进程的唯一标志(pid)用于区别其他进程
- 状态:表示任务状态,退出代码,退出信号等等
- 优先级:相对于其他进程的优先级
- 程序计数器:程序中即将被执行的下一条指令的地址
- 内存指针:包含指向代码和数据的指针,以及和其他进程共享内存块的指针
- 上下文数据:进程执行时处理器的寄存器中的数据
- I/O状态信息:包括显示的I/O请求,分配给进程的I/O设备和被进程使用的文件列表
- 记账信息:可能包含处理器时间总和,使用的时钟总和,时间限制,记账号等等
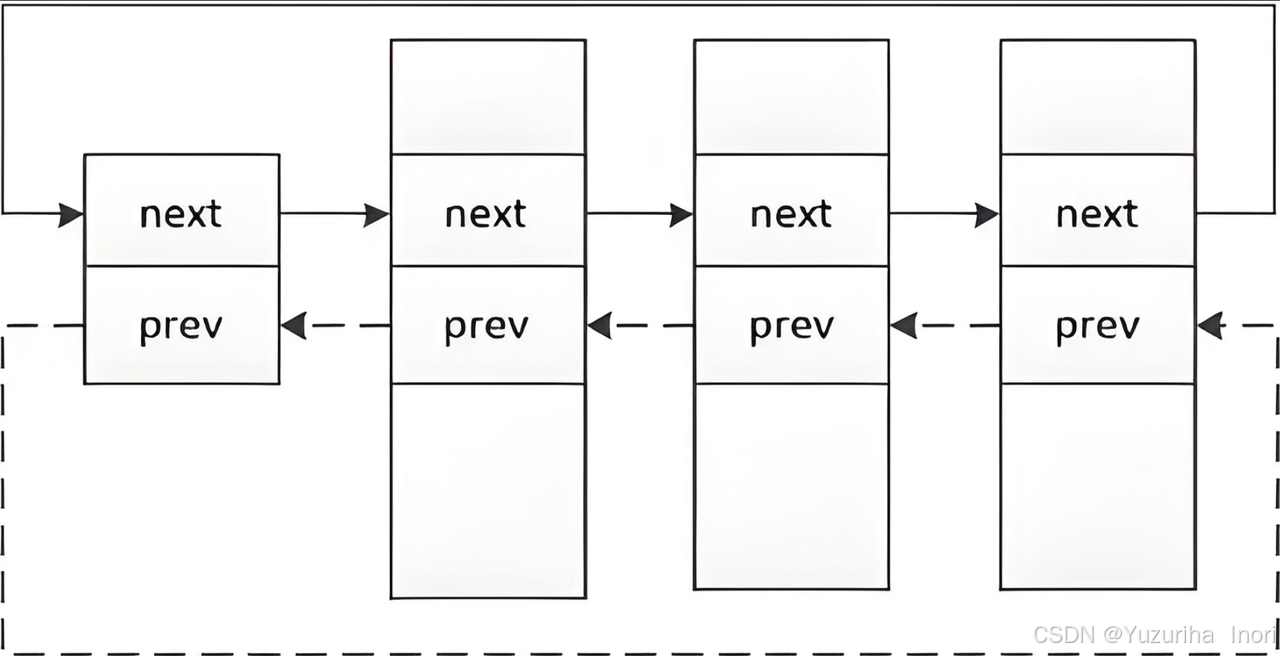
task_struct在linux系统中的组织方式是:双向链表
3.2初见进程
首先我们先介绍一下我们初见进程认识的第一个系统调用:getpid
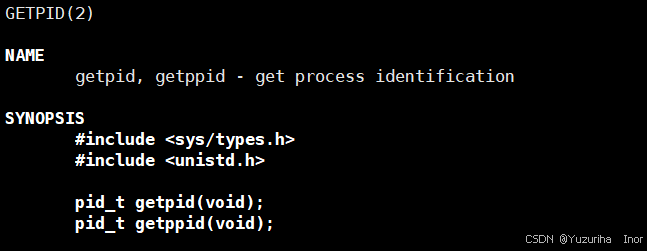
如图,getpid的功能是获得调用getpid函数的进程的标识符(简称pid) 。包含在**<unistd.h>** 库中。无需传参,返回pid_t类型的值(有同学可能比较疑惑pid_t是什么类型,其实这是由操作系统提供的类型与C语言中的int类型一致都是整型)
先编写一个简单的代码和makefile
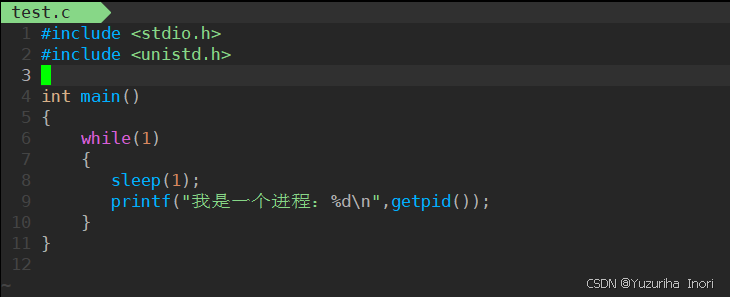
运行成功,得到具体的pid,证明当前确实是进程
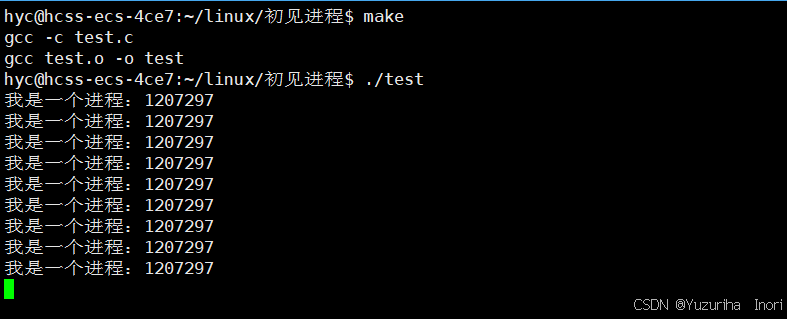
3.3查看进程
查看进程信息可以通过指令查看 ,也可以通过系统文件查看
指令查看
- 指令ps、指令top都可以查看进程信息
- ps ajx可以一键查看全部进程信息,但为了看我们想看的进程可以使用管道+grep进行过滤
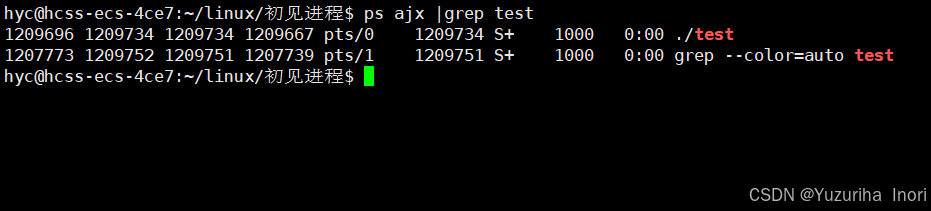
这样就看见了我们之前执行的进程信息 。这里同学可能会注意到为什么grep进程也被我们查出来了,这里简单说一下:因为grep指令也是进程,执行test关键字过滤的同时gerp进程中也有test关键字,所以被一起查出来了。
我们看见了一长串的进程信息但是我们不知道这些信息分别代表什么含义。所以我们可以使用:head -1指令,让其显示进程信息的第一行内容(&& 或者 ;同时执行左右两个指令)
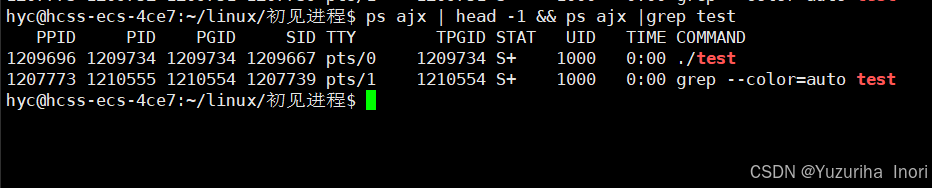
-
top指令也可以查看进程信息,不过top是实时更新的
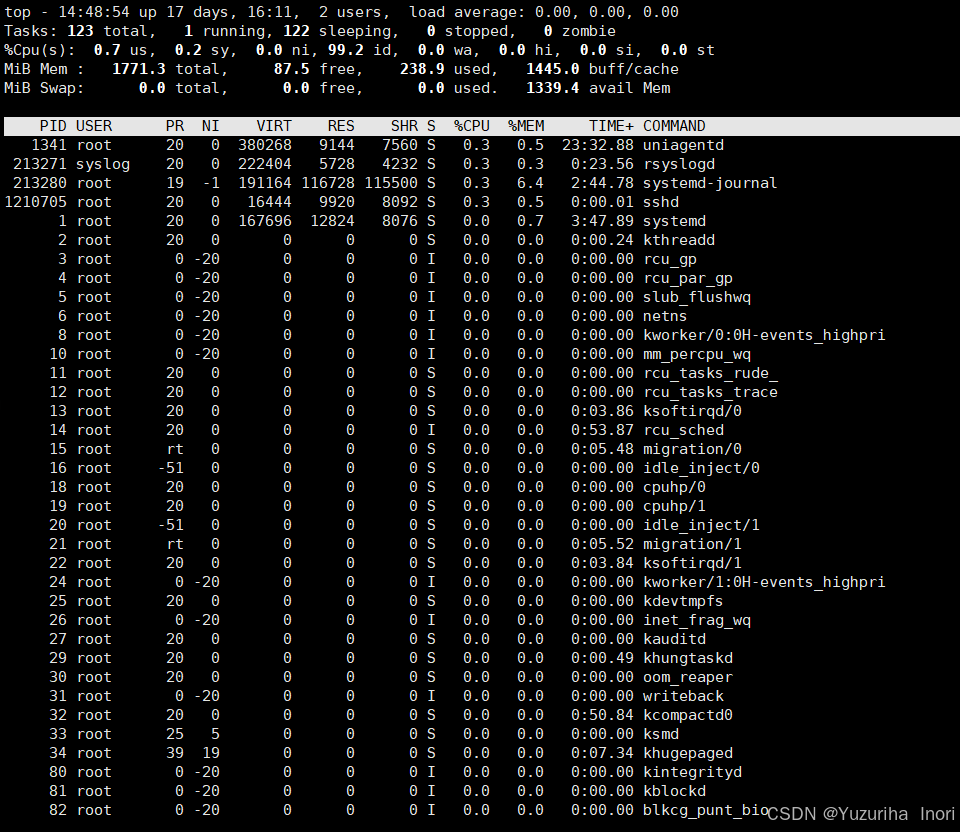
文件查看
- 进程信息可以通过 /proc的系统文件进行查看
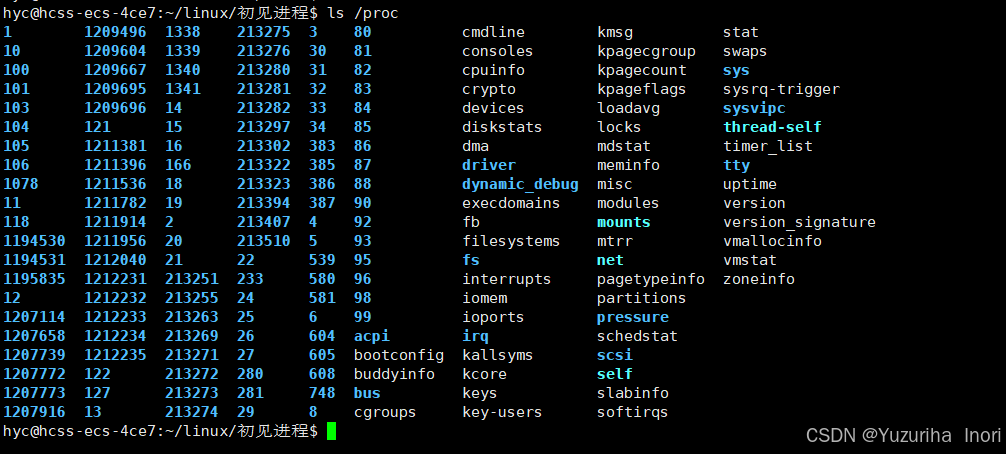
可以指定具体的进程查看其详细内容
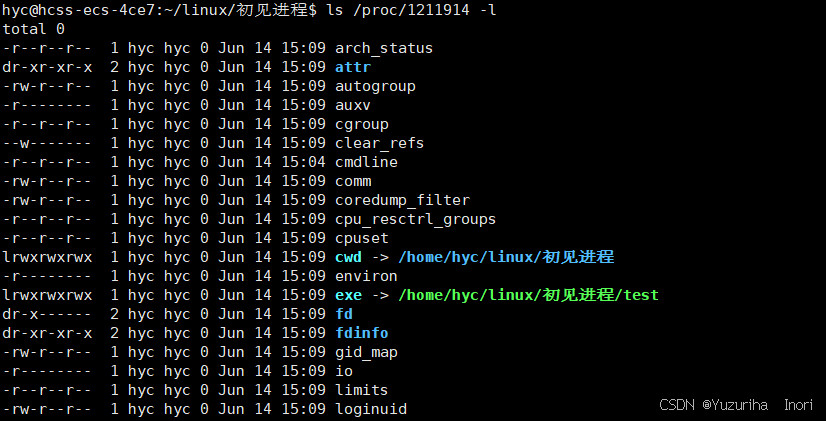
补充:
在上图我们看见就两个高亮的字符:cwd和exe,并且后面都跟了一个地址。
cwd:表示当前工作路径(current work dir)。进程在启动时会记录下自己当前所在的路径
exe:进程在启动时会记录可执行程序所在的路径
系统调用:chdir可以修改进程的cwd
杀死进程
杀死进程有两种方式
- ctrl + c:无脑杀死当前台运行的进程
- kill -9 pid:杀死指定pid的进程
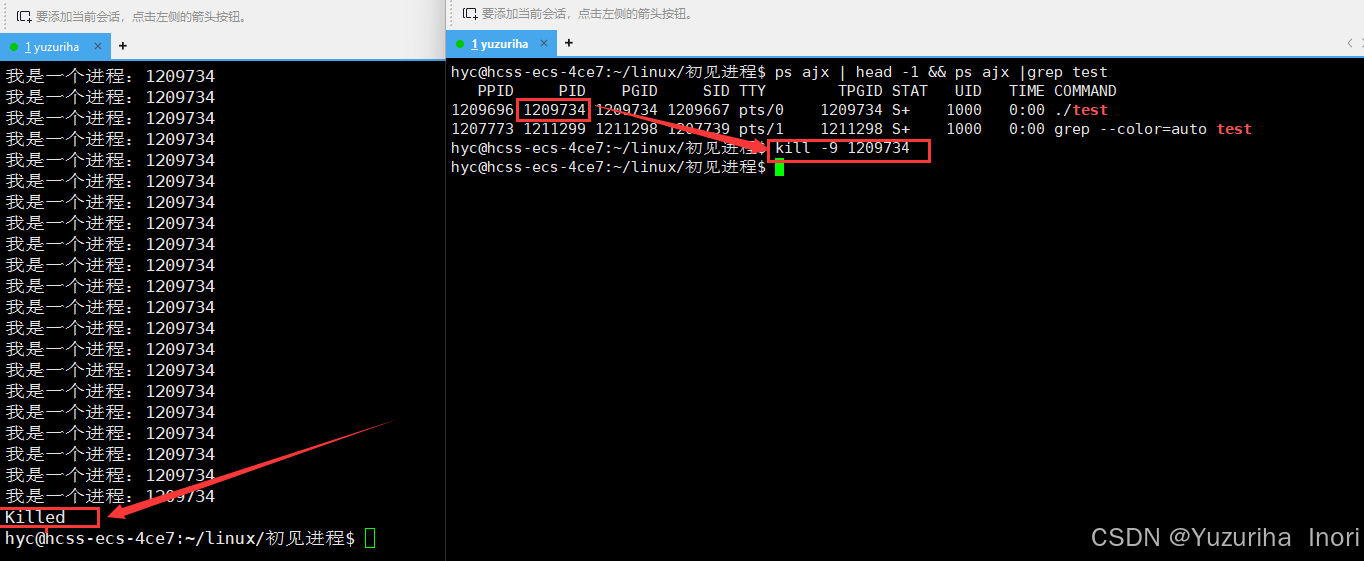
3.4父进程
上面我们讲到了getpid,不知道大家有没有注意到在这个图里面还有一个函数叫做getppid
getpid是获取当前进程的pid,而getppid这是获取当前这个进程的父进程的pid。
注:linux中进程的创建都是由父进程完成的。
我们可以通过代码来看看ppid
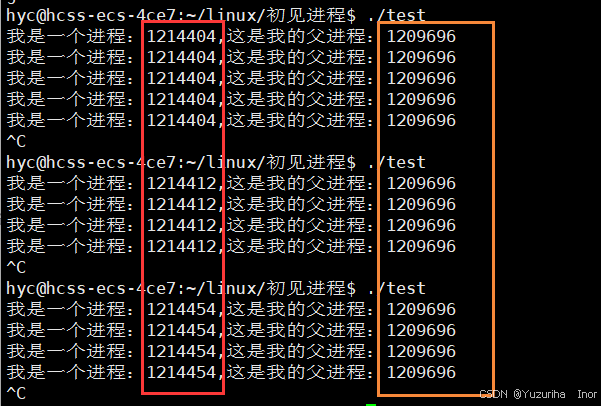
通过不断的执行杀死再次执行,我们可以发现,子进程的pid是不断变换的,而父进程的pid则是一直不变的 。我们可以通过查询父进程的pid来看看父进程到底是什么东西
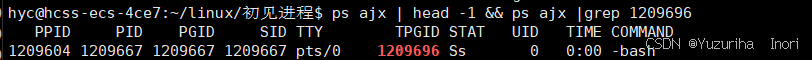
查询之后我们发现父进程是一个bash
bash其实就是我们所说的命令行解释器 (补充:os会给每一个登录用户都分配一个hash,如果同时登录3个用户就会分配3个bash)
bash是命令行解释器,那其实也是一个进程,我们执行的命令也是一个进程。从这里我们就可以知道,我们输入指令执行对应的进程,都是由bash这个父进程来创建的。
4.创建进程
在上面我们知道了,我们输入指令执行的进程,都是通过hash这个父进程来进行创建的。那么父进程是如何创建子进程的呢?
4.1如何创建进程
创建进程主要通过系统调用:fork来实现
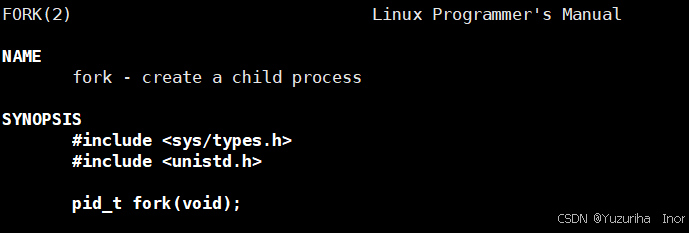
先上代码,看看具体效果
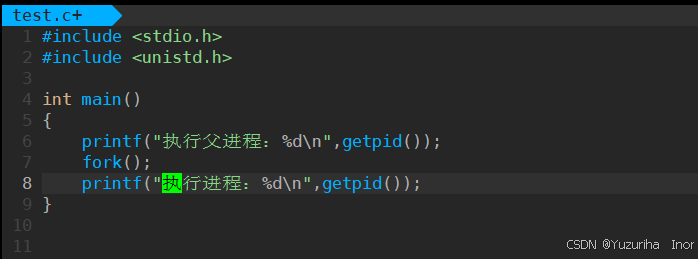
#include <stdio.h>
#include <unistd.h>
int main()
{
printf("执行父进程:%d\n",getpid());
fork();
printf("执行进程:%d\n",getpid());
}
我们可以看见出现两个不同的pid,这说明了子进程确实创建出来了。
但是为什么会有3个输出呢?我们接着往下看。
4.2fork相关问题
进程创建具体逻辑
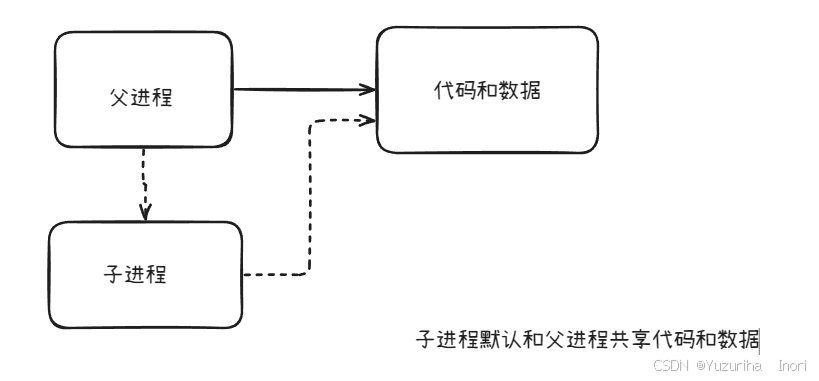
我们知道进程是由PCB+代码和数据组成 的。父进程创建子进程时,会将自己的PCB数据拷贝给子进程 ,然后子进程 在进行相应的修改 (所以父子进程的PCB数据大部分都是一样的)。在没有新代码加载进来时,子进程是默认与父进程共享代码和数据的(我们的代码就没有加载新数据)
我们的代码再第一个输出后创建了子进程,而子进程是和父进程共享代码 的。父进程继续向下执行第二个printf输出对应内容,子进程不会执行已经执行过的代码,只会执行还没有执行的代码。所以子进程执行第二个printf输出对应内容。也就是我们所看到了最后输出。
fork返回值
RETURN VALUE
On success, the PID of the child process is returned in the parent, and 0 is returned in the child. On failure, -1 is returned in the parent, no child process is created, and errno is set appropriately.
以上是关于fork返回值的文档描述。我们可以看到:如果创建成功,将会返回子进程的pid给父进程,返回0给子进程。如果创建失败则返回-1给父进程。
**看到这里我们可能会很震惊,fork居然会返回两个值吗??但事实上确实是的!**我们可以通过代码来验证一下。
#include <stdio.h>
#include <unistd.h>
int main()
{
pid_t pid = fork();
if(pid<0)
{
printf("创建失败");
}
else if(pid == 0)
{
//子进程
printf("我是一个子进程:%d,这是我的父进程:%d\n",getpid(),getppid());
}
else if(pid > 0)
{
printf("我是一个父进程:%d,这是我的父进程:%d\n",getpid(),getppid());
}
} 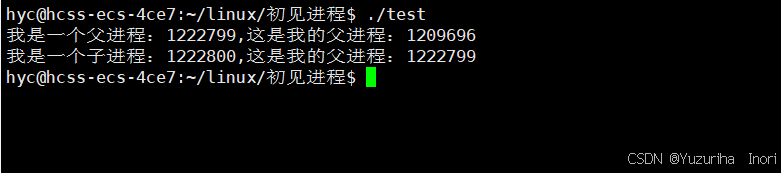
执行代码,我们可以看到同时输出了父进程和子进程,这就说明了fork确实是返回了两个值。
但与此同时,我们心中的疑问可能更多了。
为什么fork要给父子进程各自返回不同的值?
因为子进程是由父进程创建的,父进程可能同时拥有多个子进程 ,为了区分不同的子进程,父进程需要子进程的pid。
为什么fork会返回两个返回值? 
fork函数的功能是创建子进程,执行fork函数时,当子进程创建的一系列动作完成之后,才会返回pid。
也就是说返回pid之前子进程就已经创建完成了,并且已经放入调度队列中开始执行了! 上面我们讲到过子进程只会执行还没有执行过的程序 ,而恰恰return pid就是还没有执行的程序 !所以父进程执行return,子进程也会执行return。
这就是为什么fork会返回两个返回值的原因。
为什么同一个变量既满足等于0,又满足大于0?
先说结论:因为进程具有独立性,互不影响
我们可能疑惑虽然说fork返回了两个值,但是都是返回给变量pid。按我们以前的理解,pid应该会进行覆盖,最后只会满足一个条件。但是为什么两个if条件都满足呢?
首先我们知道,在我们当前这个代码中,父子进程是共享代码和数据的 。共享代码自然是好理解的,父子进程对代码只有读权限没有写权限,是不能修改代码的。
**但是数据呢?**假设父进程中有变量a为10,但是如果子进程中要对a进行修改的话,岂不是乱套了?
所以在不修改数据的情况下,操作系统默认是父子进程共享数据的 。但当要修改数据时 操作系统就进行**"写时拷贝"** 。具体是将需要修改的数据在底层拷贝一份,让目标进程修改拷贝的变量。
所以虽然我们这里的父子进程代码是共享的,但是当fork返回不同的值时,操作系统会进行**"写时拷贝"** ,形成父子进程独立的变量pid。父进程执行代码读取的数据与子进程执行代码读取的数据是不同的。
所以最后我们才会看到同时执行了两个输出
由此便解决了我们上述代码中的所有问题