一、缓冲区的概念
缓冲区是内存空间的一部分。也就是说,在内存空间中预留了一定的存储空间,这些存储空间用来冲入或输出的数据,这部分预留的空间就叫做缓冲区。缓冲区根据其对应的是输入设备还是输出设备,分为输入缓冲区和输出缓冲区。
二、认识缓冲区
1.用户级缓冲区

2.文件内核级缓冲区
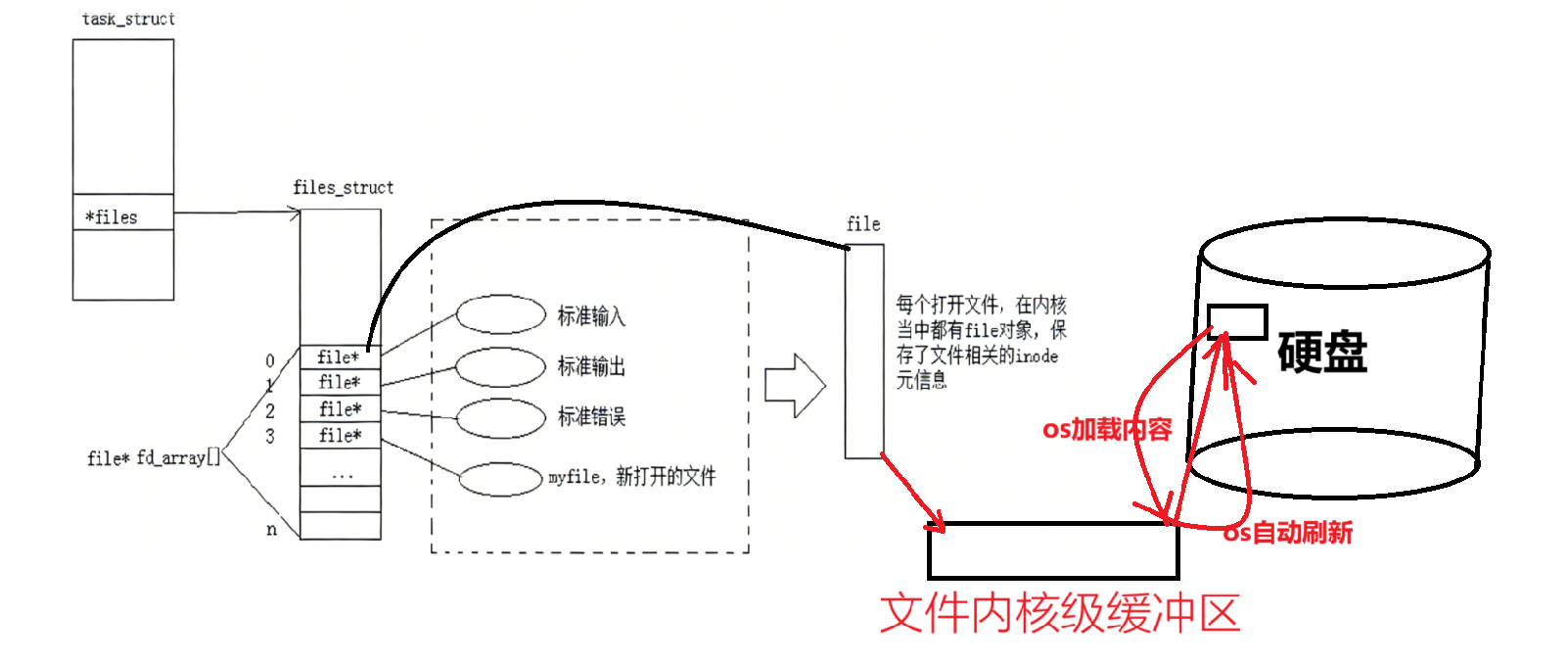
read函数和write函数本质上是系统调用级的拷贝函数
思考一下:

这个函数频繁调用,将内容拷贝到文件内核缓冲区,然后操作系统再刷新到磁盘,频繁刷新,这样的效率是不是太低了,(系统调用级函数也是有成本的,操作系统刷新数据也是有成本的)
所以我们可以把文件级缓冲区里面的内容写满了,再让操作系统刷新到磁盘里面
但是,这样用户使用的成本就太高了,所以就有了语言级缓冲区
3.语言级缓冲区
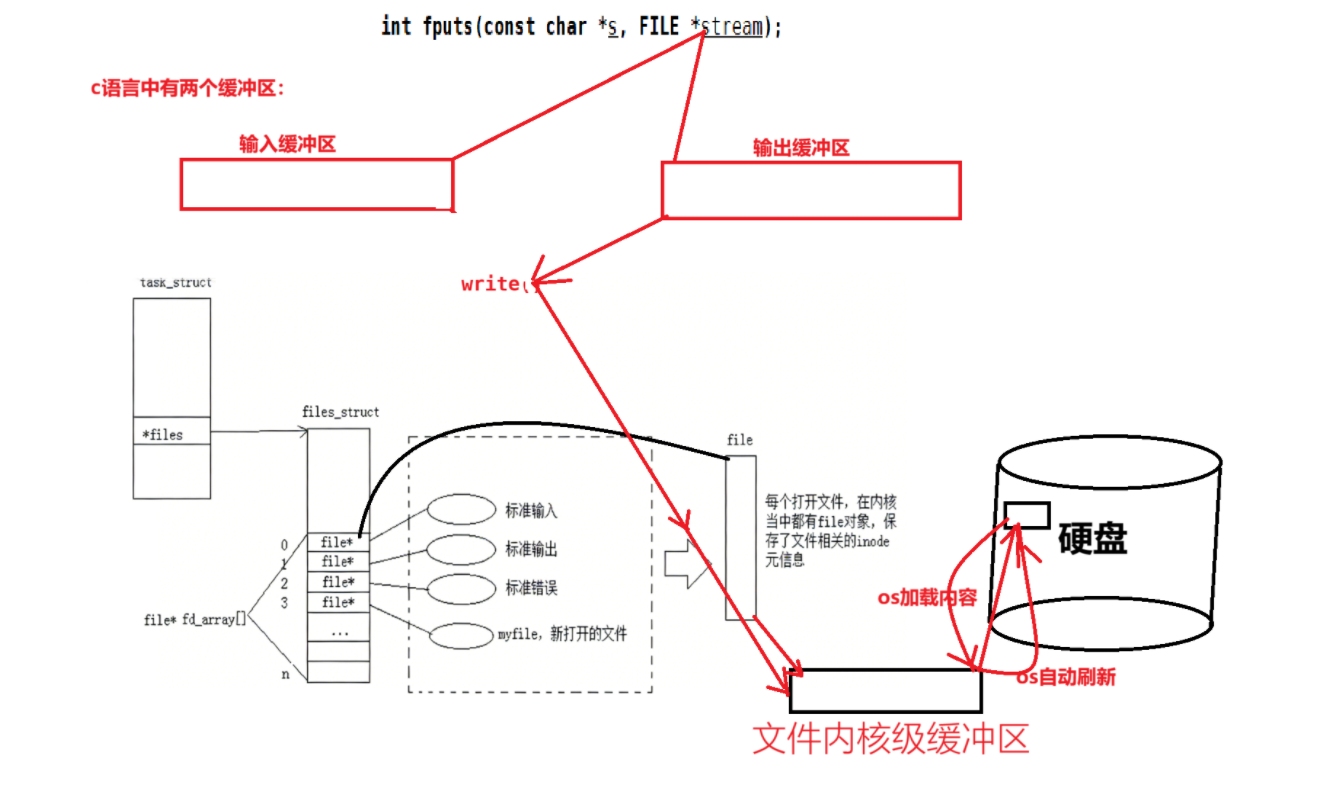
fputs函数的底层是调用了write系统调用级函数,但是**fputs函数会先将用户的数据存储在输入缓冲区中,当缓冲区满了或者满足一定的条件后,**会将输入缓冲区中的内容传给write函数,然后交操作系统来处理。
有了语言缓冲区这一层,IO的效率会大大提升
三、理解打开文件和关闭文件
**思考:**输入缓冲区和输出缓冲区在哪里呢???
答:在FILE结构体中
当调用c语言中的fopen的时候,返回的是一个FILE结构体指针,这个FILE* 指向的结构体对象是在什么时候创建的呢??
答:在调用fopen函数的时候创建的,调用fopen函数的时候会创建FILE结构体,该结构体里面有文件描述符,输入缓冲区,输出缓冲区等内容。
在调用fclose函数的时候,c语言会释放FILE结构体的内容,并刷新缓冲区。
四、缓冲区刷新机制
标准I/O提供了3种类型的缓冲区。
- 全缓冲区:这种缓冲方式要求填满整个缓冲区后才进行I/O系统调用操作。对于磁盘文件的操作通常使用全缓冲的方式访问。
- 行缓冲区:在行缓冲情况下,当在输入和输出中遇到换行符时,标准I/O库函数将会执行系统调用操作。当所操作的流涉及一个终端时(例如标准输入和标准输出),使用行缓冲方式。因为标准 I/O库每行的缓冲区长度是固定的,所以只要填满了缓冲区,即使还没有遇到换行符,也会执行 I/O系统调用操作,默认行缓冲区的大小为1024。
- 无缓冲区:无缓冲区是指标准I/O库不对字符进行缓存,直接调用系统调用。标准出错流stderr通常是不带缓冲区的,这使得出错信息能够尽快地显示出来。
1.语言级缓冲区的刷新
- 进程结束的时候,会自动刷新
- 如果目标文件是显示器,行刷新(行缓冲)
- 普通文件,一般是全缓冲,缓冲区写满了,才会刷新
2.内核级缓冲区的刷新
细节1:只要把数据从用户缓冲区拷贝到了内核文件缓冲区,就相当于交给了硬件!!!
细节2:客观上,就是写给了file对应的文件内核缓冲区->OS->自主刷新->磁盘
OS有自己的刷新策略(立即刷新或者等OS不忙了再自主刷新,OS自己定)
当然有系统调用,可以让OS立即刷新内核缓冲区:

cpp
#include <unistd.h>
int fsync(int fd);3.用3种现象来验证
1.运行下面代码,按道理来说log.txt文件中是应该有数据的,但是实际为什么没有呢?
cpp
int main()
{
close(1);
int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC);
printf("fd is:%d\n", fd);
close(fd);
return 0;
}解释:文件描述符1关闭了,fd的内容就存储在了1位置上,fd是普通文件,普通文件需要在缓冲区写满才会刷新,或者进程结束了自动刷新,又因为进程结束前close把文件给关闭了,所以缓冲区的内容没有刷新到文件中。
2.exit和_exit函数
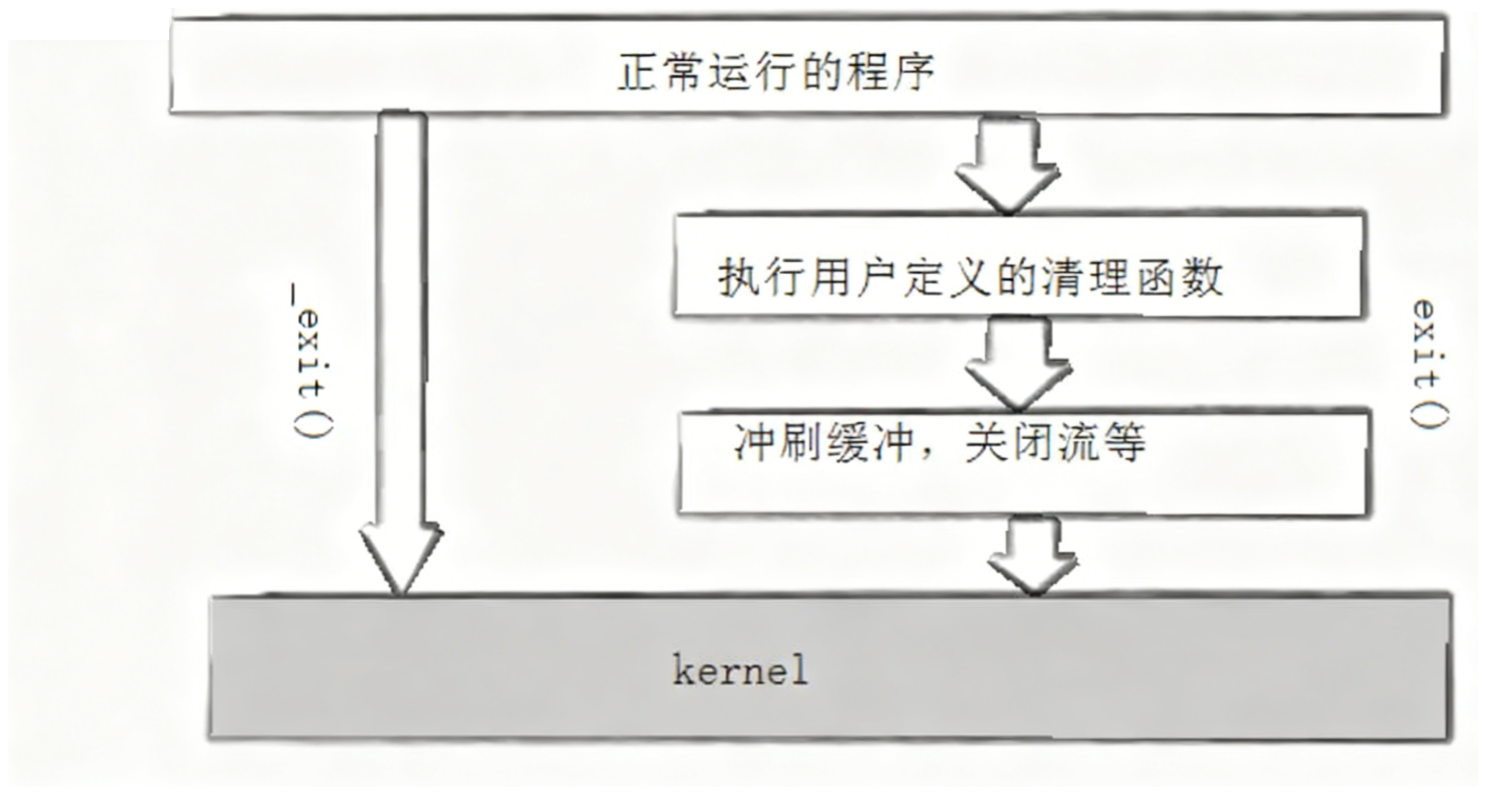
exit会刷新语言级缓冲区里面的内容,而_exit是系统级的函数,不会刷新语言级缓冲区里面的内容,这里就很清楚的理解了
3.看下面代码和运行结果:
cpp
1 #include <stdio.h>
2 #include <unistd.h>
3 #include <sys/types.h>
4 #include <sys/stat.h>
5 #include <fcntl.h>
6 #include <stdlib.h>
7 #include <string.h>
8
9 char buffer[1024];
10
11 int main()
12 {
13 read(3, buffer, sizeof(buffer));
14 write(3, buffer, sizeof(buffer));
15 // 向显示器打印字符串
16 printf("hello print\n");
17 fprintf(stdout, "hello fprintf\n");
18 const char* s = "hello fputs\n";
19 fputs(s, stdout);
20
21
22 // 系统调用
23 const char* ss = "hello write\n";
24 write(1, ss ,strlen(ss));
25
26
27 fork();
28 return 0;
29 }运行结果:
bash
[zhangsan@hcss-ecs-f571 IO]$ gcc operfile2.c -o operfile2
[zhangsan@hcss-ecs-f571 IO]$ ./operfile2
hello print
hello fprintf
hello fputs
hello write
[zhangsan@hcss-ecs-f571 IO]$ ./operfile2 > log.txt
[zhangsan@hcss-ecs-f571 IO]$ cat log.txt
hello write
hello print
hello fprintf
hello fputs
hello print
hello fprintf
hello fputs
[zhangsan@hcss-ecs-f571 IO]$ 运行结果会发现:
正常执行程序,是正常的输出打印 ,将程序输出的内容重定向到"log.txt"文件中,输出结果为什么会有重复打印的呢???
解释:父进程正常运行打印,fork函数,创建子进程后,在语言级文件缓冲区中还有内容存在(没有write函数写的内容,因为这是一个系统级的调用),重定向后,子进程是向"log.txt"文件中写入 ,这是一个普通文件,刷新规则是:进程结束的时候,自动刷新。所以子进程将语言缓冲区里面的内容又刷新了一遍,所以就会多打印一遍。
五、理解为什么有标准错误
创建一个进程,默认会打开三个文件,标准输入(0,对应键盘),标准输出(1,对应显示器),标准错误(2,对应显示器)
标准输入是作为数据的源头,标准输出可以将处理后的数据打印出来,那标准错误是干什么的呢???
看一下代码和运行结果:
代码:
cpp
1 #include <stdio.h>
2 #include <string.h>
3 #include <unistd.h>
4
5
6 int main()
7 {
8 // 标准输出:1
9 printf("这时一个正常消息\n");
10 fprintf(stdout, "这也是一个正常消息\n");
11 const char* s1 = "这时一个正常消息,write\n";
12 write(1, s1, strlen(s1));
13
14 // 标准错误:2
15 fprintf(stderr, "这是一个错误的消息\n");
16 const char* s2 = "这是一个错误的消息,write\n";
17 write(2,s2, strlen(s2));
18 perror("perror, hello");
19
20 return 0;
21 }运行结果:
bash
[zhangsan@hcss-ecs-f571 stderr]$ ./a.out
这时一个正常消息
这也是一个正常消息
这时一个正常消息,write
这是一个错误的消息
这是一个错误的消息,write
perror, hello: Success
[zhangsan@hcss-ecs-f571 stderr]$ ls
a.out error.txt normal.txt test.c
[zhangsan@hcss-ecs-f571 stderr]$ ./a.out > normal.txt
这是一个错误的消息
这是一个错误的消息,write
perror, hello: Success
[zhangsan@hcss-ecs-f571 stderr]$ cat normal.txt
这时一个正常消息,write
这时一个正常消息
这也是一个正常消息
[zhangsan@hcss-ecs-f571 stderr]$ 会发现标准输出的内容重定向到了normal.txt文件中,而标准错误中的消息没有重定向到normal.txt文件中,这个也比较好理解,因为重定向只改变的标准输出(1),把文件描述符1指向的内容从显示器改成了normal.txt文件中
那怎么把标准错误也输出到文件中呢?
cpp
[zhangsan@hcss-ecs-f571 stderr]$ ./a.out 2> error.txt
这时一个正常消息
这也是一个正常消息
这时一个正常消息,write
[zhangsan@hcss-ecs-f571 stderr]$ cat error.txt
这是一个错误的消息
这是一个错误的消息,write
perror, hello: Success
[zhangsan@hcss-ecs-f571 stderr]$ 解释一下:把error.txt文件描述符指向的内容拷贝到2号下标中,所以标准错误可以重定向到error.txt文件中。
所以就可以这样(正确信息和错误信息实现分离):
bash
[zhangsan@hcss-ecs-f571 stderr]$ ./a.out 1>normal.txt 2>error.txt
[zhangsan@hcss-ecs-f571 stderr]$ cat normal.txt
这时一个正常消息,write
这时一个正常消息
这也是一个正常消息
[zhangsan@hcss-ecs-f571 stderr]$ cat error.txt
这是一个错误的消息
这是一个错误的消息,write
perror, hello: Success
[zhangsan@hcss-ecs-f571 stderr]$ 将内容全部写入到一个文件的实现:
cpp
[zhangsan@hcss-ecs-f571 stderr]$ ./a.out > ok.txt 2>&1
[zhangsan@hcss-ecs-f571 stderr]$ cat ok.txt
这时一个正常消息,write
这是一个错误的消息
这是一个错误的消息,write
perror, hello: Success
这时一个正常消息
这也是一个正常消息这样可以实现,解释一下:
bash
[zhangsan@hcss-ecs-f571 stderr]$ ./a.out > ok.txt 2>&1前半部分是将ok.txt文件描述符的内容拷贝到1中 ,后半部分是将文件描述符1中的内容拷贝到2中,所以就实现了标准输出和标准错误的重定向。
Bash 专用简化写法(更简洁,效果同上)
bash
./a.out &> ok.txt下面这种写法也可以:
bash
./a.out >& ok.txt六、自己封装一个c语言文件级函数
分3个文件:
mystdio.h 头文件
mystdio.c 用来实现函数
main.c 用来进行测试
mystdio.h:
cpp
// mystdio.h
1 #pragma once
2
3 #include <stdio.h>
4
5 #define SIZE 1024
6 #define NON_BUFFER 1 // 0001
7 #define LINE_BUFFER 2 // 0010
8 #define FULL_BUFFER 4 // 0100
9
10
11 #define MODE 0666
12 typedef struct _myFILE
13 {
14 int fd;
15 int flags; // 标记打开模式
16 int flush_mode;
17 char outbuffer[SIZE];
18 int pos; // buffer 下标位置
19 int cap; // buffer 总容量
20
21
22 }myFILE;
23
24 myFILE* myfopen(const char* pathname, const char* mode); // r, w, a, r+, w+...
25 int myfputs(const char* str, myFILE* fp);
26 void myfflush(myFILE* fp);
27 void myfclose(myFILE* fp);
28mystdio.c:
cpp
// mystdio.c
1 #include "mystdio.h"
2 #include <string.h> // 也可以自己封装,这里不是重点
3 #include <stdlib.h>
4 #include <sys/stat.h>
5 #include <sys/types.h>
6 #include <fcntl.h>
7 #include <unistd.h>
8
9
10 #define TRY_FLUSH 1
11 #define MUST_FLUSH 2
12 myFILE* myfopen(const char* pathname, const char* mode) // r, w, a, r+, w+...
13 {
14 int fd = -1;
15 int flags = 0;
16 if(strcmp(mode, "r") == 0)
17 {
18 flags = O_RDONLY;
19 fd = open(pathname, flags);
20 }
21 else if(strcmp(mode, "w") == 0)
22 {
23 flags = O_WRONLY | O_CREAT | O_TRUNC;
24 fd = open(pathname, flags, MODE);
25
26 }
27 else if(strcmp(mode, "a") == 0)
28 {
29 flags = O_WRONLY | O_CREAT | O_APPEND;
30 fd = open(pathname, flags, MODE);
31 }
32 else
33 {
34 //TODO
35 }
36 if(fd < 0) return NULL; // 打开文件失败,返回空
37 myFILE* fp = (myFILE*)malloc(sizeof(myFILE));
38 if(fp == NULL)
39 return NULL;
40 fp->fd = fd;
41 fp->flags = flags;
42 fp->flush_mode = LINE_BUFFER;
43 fp->cap = SIZE;
44 fp->pos = 0;
45 return fp;
46 }
47 static void myfflushcore(myFILE* fp, int flag) //只在当前文件有效
48 {
49 if(fp->pos == 0) return;
50 // 这里只实现了行缓冲,其他类型的可以添加实现
51 if((fp->flush_mode & LINE_BUFFER) || (flag & MUST_FLUSH))
52 {
53 //"abcd\n"
54 if((fp->outbuffer[fp->pos-1] == '\n') || (flag & MUST_FLUSH))
55 {
56 // myfflush()
57 // 写到内核中
58 write(fp->fd, fp->outbuffer, fp->pos);
59 memset(fp->outbuffer, 0, fp->pos);
60 fp->pos = 0; // 清空缓冲区
61
62 }
63 }
64 else if(fp->flush_mode & FULL_BUFFER) // 缓存区满了刷新
65 {
66 if(fp->pos == fp->cap)
67 {
68 // ...
69 }
70 }
71 else if(fp->flush_mode & NON_BUFFER) // 无缓存模式
72 {
73 // write();
74 }
75
76 }
77 void myfflush(myFILE* fp)
78 {
79 myfflushcore(fp, MUST_FLUSH);
80 }
81
82 int myfputs(const char* str, myFILE* fp)
83 {
84 if(strlen(str) == 0)
85 return 0;
86 // step1:向文件流里面写,本质是:写到文件缓冲(拷贝)
87 memcpy(fp->outbuffer + fp->pos,str, strlen(str)); //拷贝到缓冲区中,因为可能是多次fputs所以需要有pos标记位
88 fp->pos += strlen(str);
89 // step2:如果条件运行,可以自己刷新
90 myfflushcore(fp, TRY_FLUSH);
91 return strlen(str);
92 }
93 void myfclose(myFILE* fp)
94 {
95 //1.强制刷新到内核
96 myfflush(fp);
97
98 //1.2 强制刷新到磁盘
99 fsync(fp->fd);// 不是必须的,内核会自己刷新的
100
101 //2.关闭文件
102 close(fp->fd);
103
104 //3.free
105 free(fp);
106
107 }main.c文件:
cpp
1 #include "mystdio.h"
2 #include <unistd.h>
3 int main()
4 {
5 myFILE* fp = myfopen("log.txt", "a");
6 if(fp == NULL)
7 {
8 perror("myfopen error!\n");
9 }
10
11 int cnt = 10;
12 const char* msg = "hello word\n";
13 while(cnt--)
14 {
15 myfputs(msg, fp);
16 sleep(1);
17 printf("debug:outbuffer = %s,pos = %d\n",fp->outbuffer, fp->pos);
18 }
19
20 myfclose(fp);
21 printf("write file done!\n");
22 return 0;
23 }