
-
作者:Yangzhe Kong, Daeun Song, Jing Liang, Dinesh Manocha, Ziyu Yao, and Xuesu Xiao
-
单位:乔治梅森大学,马里兰大学
-
论文标题:AutoSpatial: Visual-Language Reasoning for Social Robot Navigation through Efficient Spatial Reasoning Learning
-
代码链接:https://github.com/Yanko96/AutoSpatial (coming soon)
主要贡献
-
提出了基于视觉语言模型(VLM)的方法AutoSpatial,通过结构化的空间定位和自动标注的视觉问答(VQA)对,显著提升了VLM在社会导航中的空间推理能力。
-
引入了自动数据标注策略,结合两轮VQA结构,高效解决了特定领域数据稀缺问题,同时分层增强了空间理解能力。
-
通过专家系统(如GPT-4o、Gemini 2.0 Flash、Claude 3.5 Sonnet)的交叉验证评分和人类评估者的相对排名,证明了AutoSpatial在感知与预测、推理、行动和解释等方面的显著优势。
研究背景
-
社会导航是人机交互中的一个基本挑战,要求机器人不仅能够避开障碍物,还要以符合社会规范的方式进行导航。尽管传统方法和基于学习的方法已经取得了一定进展,但在动态和社交环境中仍面临关键挑战。
-
近年来,视觉语言模型(VLM)在机器人推理方面展现出巨大潜力,但在社会导航中的应用受到限制,主要原因是缺乏空间推理能力,例如无法准确预测人类运动和人机交互,导致在动态社交环境中的决策不够理想。
-
此外,现有的自然语言注释数据集主要关注自动驾驶等结构化驾驶场景,而涉及行人交互、复杂社交规范的图像文本数据集尚未得到充分探索,这使得VLM难以在没有大量人工监督的情况下进行有效泛化。
研究方法

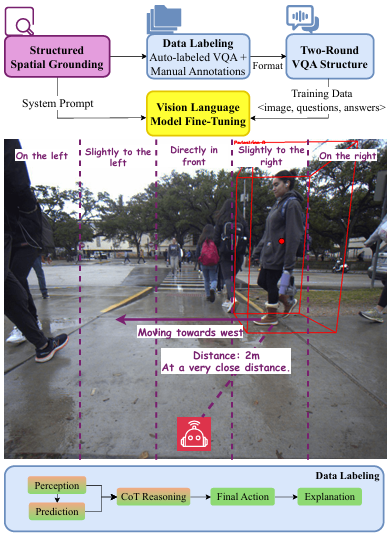
结构化空间定位
-
将空间关系分解为两个独立组件:人类的位置描述(包括角度位置和距离)以及人类运动方向的描述。
-
通过将机器人视野划分为五个区域和五级距离分类,并采用相对坐标系统描述行人运动方向,消除了相对方向描述中的模糊性,为感知和预测提供了统一的参考框架。
数据标注
-
自动标注的VQA对 :
-
基于CODA数据集,利用规则启发式方法生成VQA对,涵盖空间感知、运动预测和交互描述三个方面。
-
空间感知包括行人的位置和运动方向描述;运动预测分析短期轨迹,识别运动模式;交互描述则识别各种交互模式,如轨迹冲突、路径交叉等。
-
-
手动标注 :
-
从CODA数据集中挑选72个具有挑战性的场景进行手动标注,重点关注高行人密度环境、复杂社交分组模式以及需要从个体到群体理解的场景。
-
手动标注遵循结构化的5项任务格式:感知、预测、推理、最终行动和解释,并提供结构化空间定位指南以减少主观性。
-
两轮VQA结构
-
对于手动标注的场景,采用两轮VQA结构以实现分层学习。
-
第一轮是自动标注的VQA,关注个体行人的空间感知、预测和推理;
-
第二轮是手动标注,将个体描述整合为全面的场景描述,涵盖群体动态和高级空间推理。
实验
- 实验设置 :
-
基于LLaVA-1.6 OneVision-7B模型进行实验,使用4个A100 80GB GPU。
-
采用AdamW优化器,学习率为2e-5,批大小为8,梯度累积步数为4。
-
评估框架包括自动化指标(针对CODA数据集的基本空间推理)和人类评估(针对SNEI基准的高级场景理解)。
-
-
结果:
-
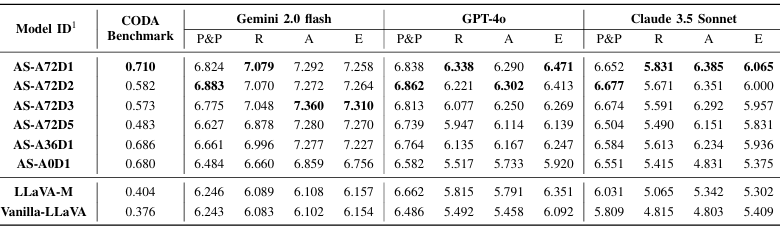
在CODA基准测试中,AutoSpatial(AS-A72D1)在空间推理方面得分为0.710,显著优于仅使用手动标注的LLaVA-M(0.404)和原始LLaVA(0.376)。
-
在专家系统评估中,AutoSpatial在感知与预测、推理、行动和解释等方面均优于基线模型,平均交叉验证分数分别提高了10.71%、16.26%、20.50%和18.73%。
-
人类评估结果也显示,AutoSpatial在所有关键方面均优于基线模型。
-
消融研究表明,仅使用感知与预测VQA任务的模型在该方面表现良好,但在其他方面提升有限;仅使用推理VQA任务的模型在推理、行动和解释方面有所改善,但在基本空间理解上表现不佳。这表明不同类型的VQA任务与手动标注相结合才能实现最佳性能。
-
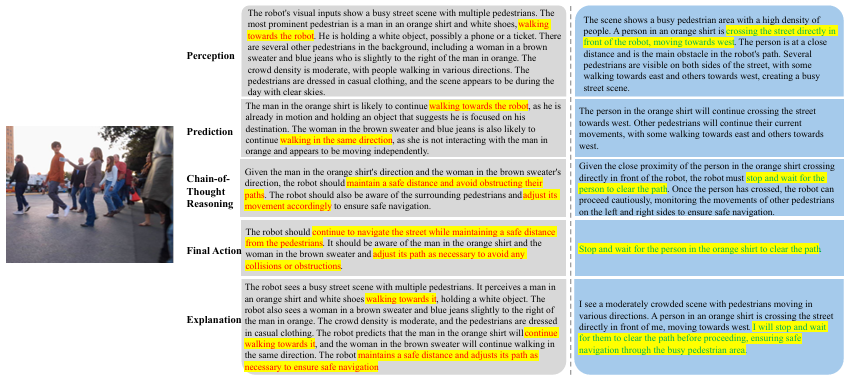
定性分析表明,AutoSpatial在识别关键参与者及其相对位置方面表现出色,能够提供更具体、符合社交规范的导航指令,但在理解人类微妙线索(如目光方向和身体姿态)方面仍存在不足。
-

结论与未来工作
-
结论 :
-
AutoSpatial通过结合自动标注数据和少量手动标注,显著提升了VLM在社会导航中的空间推理能力。
-
实验结果表明,自动标注的VQA对与手动标注相结合能够产生协同效应,即使在减少手动标注的情况下也能保持良好性能。
-
-
未来工作 :
-
进一步改进人类行为理解能力,特别是对微妙社交线索的识别,以更好地处理复杂场景中的人类交互。
-
提高空间术语的一致性,确保模型在各种环境中都能准确使用标准化的空间描述。
-
融合时间序列信息,以更好地理解人类的连续运动和意图,并在多视角下保持一致的空间推理。
-
