文章目录
- 前言
- 一、评分分布数据可视化
- 二、图书价格分布数据可视化
- 三、出版社图书数据可视化
- 四、每年出版的图书数据可视化
- 五、评价人数最多的前15本图书数据可视化
- 六、译者图书数据可视化
- 七、数据可视化完整代码
- 八、数据可视化大屏
- 完整项目获取看下方名片
前言
本文围绕豆瓣图书数据展开可视化分析,通过 Python 的 Pyecharts 库实现多维度数据的直观呈现。首先基于评分分布、价格区间、出版社规模等六类分析结果,分别采用条形图、饼图、词云图等可视化形式,清晰展示了图书评分分布、价格区间占比、出版社图书数量规模等数据特征。例如,通过环形玫瑰图呈现价格区间与图书数量的占比关系,利用词云图直观对比各出版社的图书出版规模。
进一步将单图表整合成可视化大屏,通过网格布局配置实现六张图表的有序排列,并添加深蓝到紫蓝的渐变背景、亮青色标题等设计,增强科技感与视觉统一性。最终形成的交互式大屏不仅实现了数据的多维度展示,还通过动态效果(如散点图的粒子动画、折线图的数据缩放)提升了用户体验,为豆瓣图书数据分析提供了可视化支撑。
前置文章:
豆瓣图书数据采集与可视化分析(一)- 豆瓣图书数据爬取
豆瓣图书数据采集与可视化分析(二)- 豆瓣图书数据清洗与处理
豆瓣图书数据采集与可视化分析(三)- 豆瓣图书数据统计分析(Pandas)
一、评分分布数据可视化
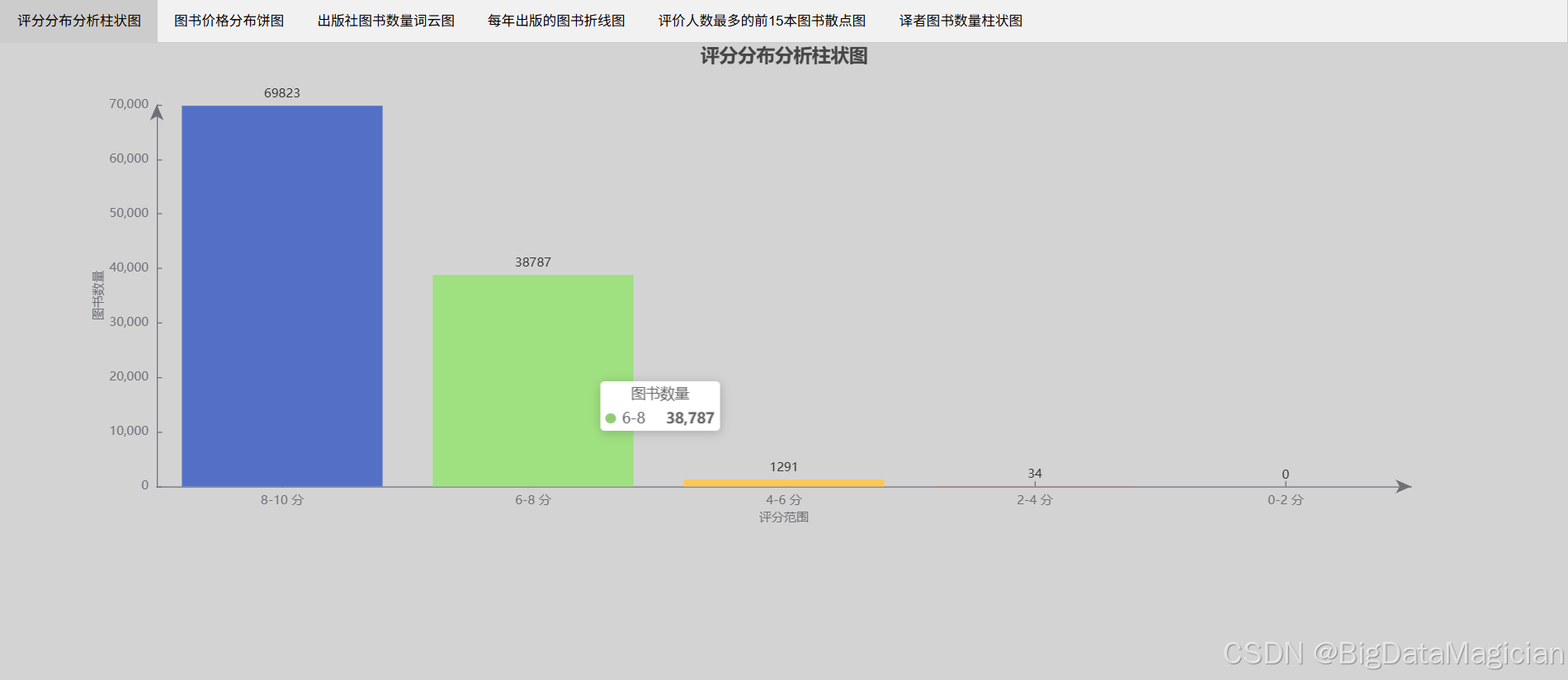
在进行评分分布分析数据可视化(条形图)时,首先确定了可视化结果的存储路径,确保路径对应的文件夹存在。接着,从指定文件中加载评分分布统计分析数据,提取出评分范围和对应的图书数量这两列数据。随后,着手构建条形图,设置图表的初始属性,如背景颜色为浅灰色,页面标题为 "评分分布分析柱状图",且保证图表在水平方向居中,背景颜色填充整个图表区域并占据页面的全部宽度。在图表内容构建上,将评分范围设置为 x 轴数据,图书数量设置为 y 轴数据,并依据数据为每个条形赋予不同颜色。对于图表的全局设置,添加了位于中心位置的标题 "评分分布分析柱状图",隐藏了图例;x 轴被定义为分类轴,代表评分范围,轴标签添加了 "分" 的标识,同时对轴线、轴刻度等样式进行了设置;y 轴被定义为数值轴,代表图书数量,也对其轴线、轴刻度等进行了样式设定。在系列设置方面,将数据标签设置在条形的顶部。最后,将构建好的条形图渲染并保存到指定路径,从而完成评分分布分析数据的可视化展示。
可视化代码如下:
python
# 评分分布分析数据可视化(条形图)
def rating_distribution_analysis():
html_file_path = "./结果输出层/数据可视化结果/评分分布分析柱状图.html"
path = Path(html_file_path)
path.parent.mkdir(parents=True, exist_ok=True)
data = load_data("./结果输出层/数据分析结果数据/评分分布统计分析.csv")
rating_range_list = data['rating_range'].tolist()
count_list = data['count'].tolist()
bar = Bar(
init_opts=opts.InitOpts(
chart_id="c1",
# bg_color="transparent",
bg_color="lightgray",
page_title="评分分布分析柱状图",
is_horizontal_center=True,
is_fill_bg_color=True,
width="100%",
)
)
bar.add_xaxis(rating_range_list)
bar.add_yaxis("图书数量", count_list, color_by="data")
bar.set_global_opts(
title_opts=opts.TitleOpts(title="评分分布分析柱状图", pos_left="center"),
legend_opts=opts.LegendOpts(is_show=False),
xaxis_opts=opts.AxisOpts(
type_="category",
name="评分范围",
name_location="center",
name_gap=25,
axisline_opts=opts.AxisLineOpts(symbol=["none", "arrow"]),
axistick_opts=opts.AxisTickOpts(
is_align_with_label=True,
is_inside=True,
),
axislabel_opts=opts.LabelOpts(formatter="{value} 分"),
splitline_opts=opts.SplitLineOpts(is_show=False)
),
yaxis_opts=opts.AxisOpts(
type_="value",
name="图书数量",
name_location="center",
name_gap=50,
axisline_opts=opts.AxisLineOpts(symbol=["none", "arrow"]),
axistick_opts=opts.AxisTickOpts(
is_align_with_label=True,
is_inside=True,
),
splitline_opts=opts.SplitLineOpts(is_show=False)
),
)
bar.set_series_opts(
label_opts=opts.LabelOpts(position="top")
)
bar.render(html_file_path)
return bar可视化结果图如下:
二、图书价格分布数据可视化
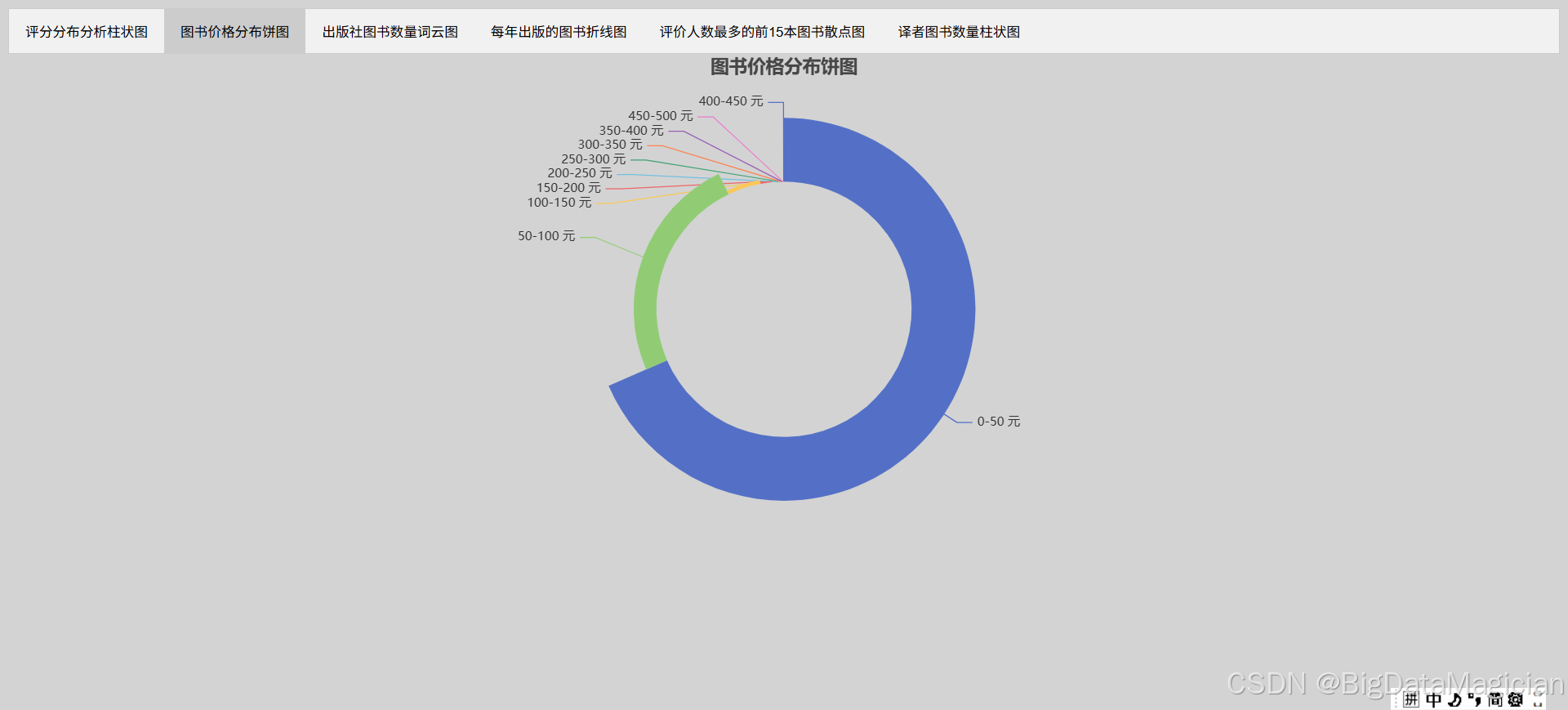
在进行图书价格分布统计分析的可视化过程中,首先确定了结果文件的存储路径并确保目录存在。随后从数据分析结果中加载了图书价格分布统计数据,包含不同价格区间及其对应的图书数量。为了直观呈现各价格区间的图书数量占比关系,选择了环形玫瑰图(环形饼图的一种变体)作为可视化图表类型。
在图表设计上,将价格区间作为分类标签,图书数量作为数值,采用 "radius" 玫瑰图模式,使扇形面积与数值大小成正比,更直观地展示不同价格区间的图书数量差异。图表采用浅灰色背景,标题居中显示为 "图书价格分布饼图",并隐藏了图例以减少视觉干扰。
为增强可读性,每个扇形添加了标签显示价格区间,并设置了鼠标悬停提示框,显示完整的分类名称、具体数量及百分比。图表的内外半径分别设置为 50% 和 75%,形成环形效果,使中心区域可用于添加额外信息。同时,为每个扇形分配了不同颜色,便于区分不同价格区间。最终,将生成的交互式饼图保存为 HTML 文件,完成了图书价格分布的可视化分析。
可视化代码如下:
python
# 图书价格分布统计分析数据可视化(饼图)
def book_price_distribution_analysis():
html_file_path = "./结果输出层/数据可视化结果/图书价格分布饼图.html"
path = Path(html_file_path)
path.parent.mkdir(parents=True, exist_ok=True)
data = load_data("./结果输出层/数据分析结果数据/图书价格分布统计分析.csv")
pie = Pie(
init_opts=opts.InitOpts(
chart_id="c2",
# bg_color="transparent",
bg_color="lightgray",
page_title="图书价格分布饼图",
is_horizontal_center=True,
is_fill_bg_color=True,
width="100%",
)
)
pie.add(
series_name="图书数量",
data_pair=list(zip(data['price_range'], data['count'])),
color_by="data",
radius=["50%", "75%"],
rosetype="radius",
)
pie.set_global_opts(
title_opts=opts.TitleOpts(title="图书价格分布饼图", pos_left="center"),
legend_opts=opts.LegendOpts(is_show=False),
tooltip_opts=opts.TooltipOpts(formatter="{a} <br/>{b} : {c} ({d}%)"),
)
pie.set_series_opts(label_opts=opts.LabelOpts(formatter="{b} 元"), )
pie.render(html_file_path)
return pie可视化结果图如下:
三、出版社图书数据可视化
在进行出版社图书数量统计分析的可视化过程中,首先确定了结果文件的存储路径并确保目录存在。随后从数据分析结果中加载了出版社图书数量统计数据,包含各出版社名称及其对应的图书出版数量。为了直观呈现不同出版社的规模差异,选择了词云图作为可视化图表类型,词云图的特点是词的大小与对应数值成正比,能快速让读者感知各出版社的相对规模。
在图表设计上,将出版社名称作为文本标签,图书数量作为数值依据,使词云图中每个出版社名称的字体大小与该出版社的图书数量成正比。图表采用浅灰色背景,标题居中显示为 "出版社图书数量词云图",并隐藏了图例以减少视觉干扰。
为增强可读性,设置了鼠标悬停提示框,当用户将鼠标移至某个出版社名称上时,会显示完整的出版社名称和对应的具体图书数量。最终,将生成的交互式词云图保存为 HTML 文件,完成了出版社图书数量的可视化分析,使读者能够一目了然地看出各出版社在规模上的差异。
可视化代码如下:
python
# 出版社图书数量统计分析数据可视化(词云图)
def publisher_book_count_analysis():
html_file_path = "./结果输出层/数据可视化结果/出版社图书数量词云图.html"
path = Path(html_file_path)
path.parent.mkdir(parents=True, exist_ok=True)
data = load_data("./结果输出层/数据分析结果数据/出版社图书数量统计分析.csv")
data_list = [tuple(row) for row in data.itertuples(index=False)]
word_count = WordCloud(
init_opts=opts.InitOpts(
chart_id="c3",
# bg_color="transparent",
bg_color="lightgray",
page_title="出版社图书数量词云图",
is_horizontal_center=True,
is_fill_bg_color=True,
width="100%",
)
)
word_count.add(
series_name="出版社图书数量词云图",
data_pair=data_list,
)
word_count.set_global_opts(
title_opts=opts.TitleOpts(title="出版社图书数量词云图", pos_left="center"),
legend_opts=opts.LegendOpts(is_show=False),
tooltip_opts=opts.TooltipOpts(formatter="{a} <br/>{b} : {c}"),
)
word_count.render(html_file_path)
return word_count可视化结果图如下:

四、每年出版的图书数据可视化
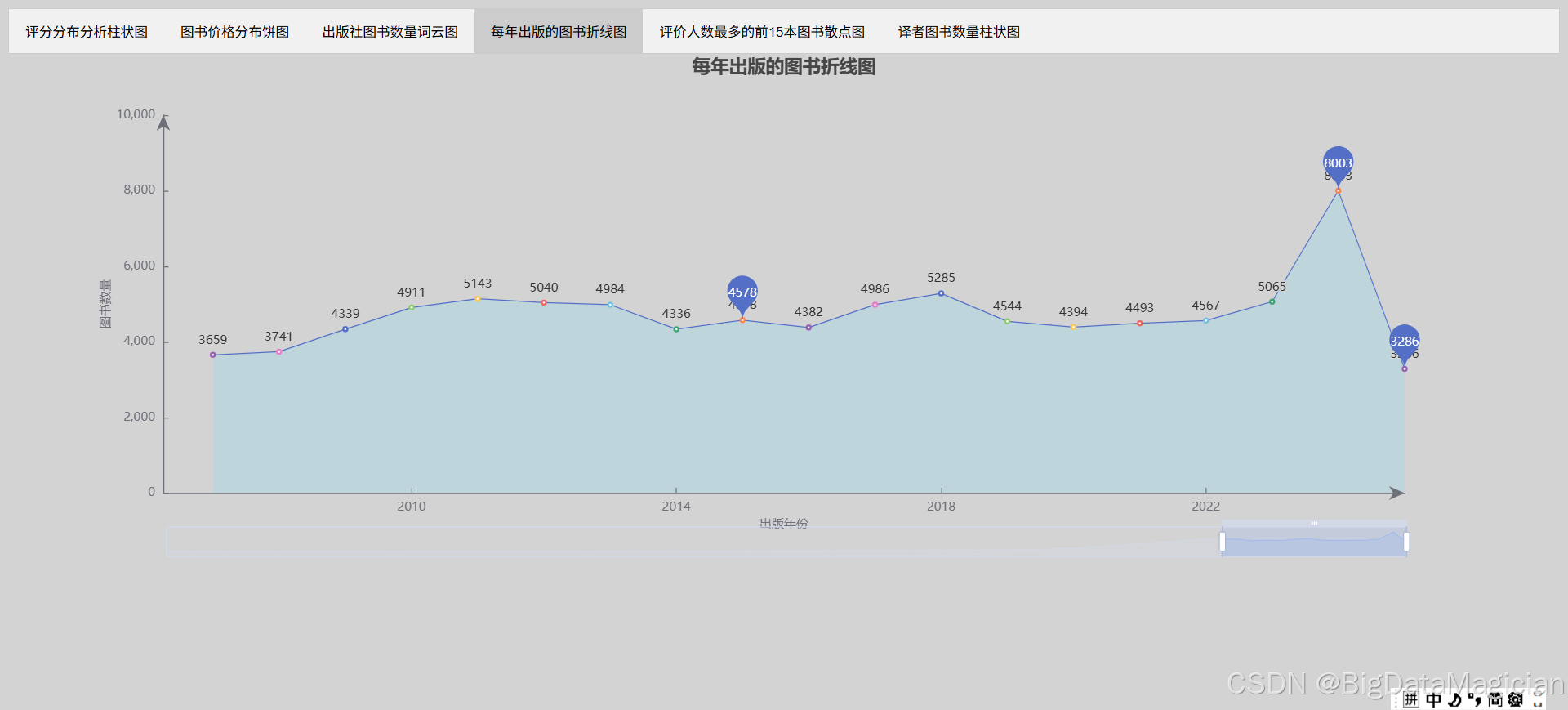
在进行每年出版的图书数量统计分析可视化时,首先确定结果文件存储路径并确保目录存在,随后加载年度出版数量统计数据。为呈现图书数量随时间的变化趋势,选择折线图作为可视化形式,将出版年份处理为时间格式数据,以确保 x 轴能按时间序列正确展示。图表采用浅灰色背景,标题居中设置为 "每年出版的图书折线图",并隐藏图例以聚焦数据趋势。
x 轴设为时间轴,仅显示年份数字,搭配轴线箭头和内部刻度增强可读性;y 轴为数值轴,标注 "图书数量" 并优化轴线样式。为提升交互性,添加滑块与内置两种数据缩放功能,便于查看长时间段数据细节。系列配置中,将数据标签置于折线顶部,同时标记最大值、最小值与平均值,直观展示数据特征;折线下方区域填充浅蓝色半透明背景,增强趋势视觉感知。最终生成的交互式折线图可清晰呈现年度出版数量的波动与整体趋势,保存为 HTML 文件完成可视化分析。
可视化代码如下:
python
# 每年出版的图书数量统计分析数据可视化(折线图)
def yearly_book_count_analysis():
html_file_path = "./结果输出层/数据可视化结果/每年出版的图书折线图.html"
path = Path(html_file_path)
path.parent.mkdir(parents=True, exist_ok=True)
data = load_data("./结果输出层/数据分析结果数据/每年出版的图书数量统计分析.csv")
publish_year_list = data['publish_year'].tolist()
publish_year_list = [f"{int(year)}-01-01" for year in publish_year_list]
count_list = data['count'].tolist()
line = Line(
init_opts=opts.InitOpts(
chart_id="c4",
# bg_color="transparent",
bg_color="lightgray",
page_title="每年出版的图书折线图",
is_horizontal_center=True,
is_fill_bg_color=True,
width="100%"
)
)
line.add_xaxis(publish_year_list)
line.add_yaxis("图书数量", count_list, color_by='data')
line.set_global_opts(
title_opts=opts.TitleOpts(title="每年出版的图书折线图", pos_left="center"),
legend_opts=opts.LegendOpts(is_show=False),
xaxis_opts=opts.AxisOpts(
type_="time",
name="出版年份",
name_location='center',
name_gap=25,
axisline_opts=opts.AxisLineOpts(symbol=["none", "arrow"]),
axistick_opts=opts.AxisTickOpts(
is_align_with_label=True,
is_inside=True,
),
axislabel_opts=opts.LabelOpts(formatter="{yyyy}"),
splitline_opts=opts.SplitLineOpts(is_show=False),
),
yaxis_opts=opts.AxisOpts(
type_="value",
name="图书数量",
name_location="center",
name_gap=50,
axisline_opts=opts.AxisLineOpts(symbol=["none", "arrow"]),
axistick_opts=opts.AxisTickOpts(
is_align_with_label=True,
is_inside=True,
),
splitline_opts=opts.SplitLineOpts(is_show=False),
),
datazoom_opts=[
opts.DataZoomOpts(range_start=85, range_end=100, type_="slider"),
opts.DataZoomOpts(range_start=85, range_end=100, type_="inside"),
]
)
line.set_series_opts(
label_opts=opts.LabelOpts(position="top"),
markpoint_opts=opts.MarkPointOpts(
data=[
opts.MarkPointItem(type_="max", name="最大值"),
opts.MarkPointItem(type_="min", name="最小值"),
opts.MarkPointItem(type_="average", name="平均值"),
]
),
areastyle_opts=opts.AreaStyleOpts(opacity=0.5, color="lightblue", )
)
line.render(html_file_path)
return line可视化结果图如下:
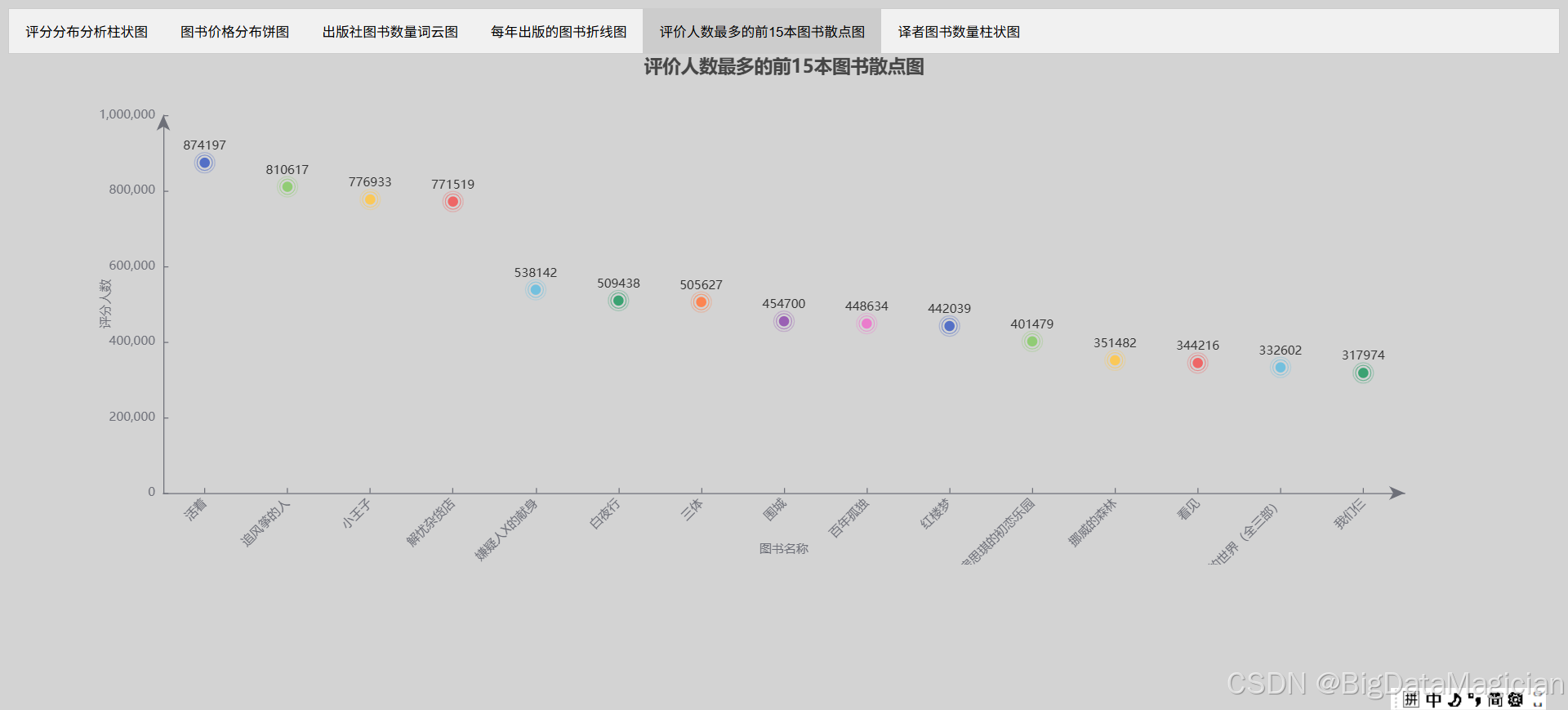
五、评价人数最多的前15本图书数据可视化
在开展评价人数最多的前 15 本图书数据可视化工作时,首先明确可视化结果的存储路径,并创建对应的文件夹。随后,从指定文件中加载评价人数多的图书分析数据,提取出图书名称与评分人数两列数据。为直观展现各图书评价人数的差异,选用具有动态效果的散点图(EffectScatter)进行可视化呈现。
在图表设计方面,将图表背景色设为浅灰色,标题 "评价人数最多的前 15 本图书散点图" 居中放置,并隐藏图例以减少视觉干扰。X 轴为分类轴,代表图书名称,为避免标签拥挤,将标签文字旋转 45 度;Y 轴为数值轴,代表评分人数,同时对两轴的轴线、刻度线等样式进行设置优化。图表中,以图书名称为横坐标,评分人数为纵坐标绘制散点,每个散点大小与对应图书的评分人数相关,同时赋予动态特效,增强视觉表现力。此外,将数据标签置于散点上方,便于读者快速获取具体数值。最后,将制作完成的散点图渲染并保存至指定路径,实现对评价人数最多的前 15 本图书数据的有效可视化展示 。
可视化代码如下:
python
# 评价人数最多的前15本图书数据可视化(散点图)
def rating_count_analysis():
html_file_path = "./结果输出层/数据可视化结果/评价人数最多的前15本图书散点图.html"
path = Path(html_file_path)
path.parent.mkdir(parents=True, exist_ok=True)
data = load_data("./结果输出层/数据分析结果数据/评价人数多的图书分析.csv")
name_list = data['name'].tolist()
rating_count_list = data['rating_count'].tolist()
scatter = EffectScatter(
init_opts=opts.InitOpts(
chart_id="c5",
# bg_color="transparent",
bg_color="lightgray",
page_title="评价人数最多的前15本图书散点图",
is_horizontal_center=True,
is_fill_bg_color=True,
width="100%"
)
)
scatter.add_xaxis(name_list)
scatter.add_yaxis("评分人数", rating_count_list, color_by='data')
scatter.set_global_opts(
title_opts=opts.TitleOpts(title="评价人数最多的前15本图书散点图", pos_left="center"),
legend_opts=opts.LegendOpts(is_show=False),
xaxis_opts=opts.AxisOpts(
type_="category",
name="图书名称",
name_location='center',
name_gap=50,
axisline_opts=opts.AxisLineOpts(symbol=["none", "arrow"]),
axistick_opts=opts.AxisTickOpts(
is_align_with_label=True,
is_inside=True,
),
axislabel_opts=opts.LabelOpts(formatter="{value}", rotate=45),
splitline_opts=opts.SplitLineOpts(is_show=False),
),
yaxis_opts=opts.AxisOpts(
type_="value",
name="评分人数",
name_location="center",
name_gap=50,
axisline_opts=opts.AxisLineOpts(symbol=["none", "arrow"]),
axistick_opts=opts.AxisTickOpts(
is_align_with_label=True,
is_inside=True,
),
splitline_opts=opts.SplitLineOpts(is_show=False),
)
)
scatter.set_series_opts(label_opts=opts.LabelOpts(position="top"))
scatter.render(html_file_path)
return scatter可视化结果图如下:
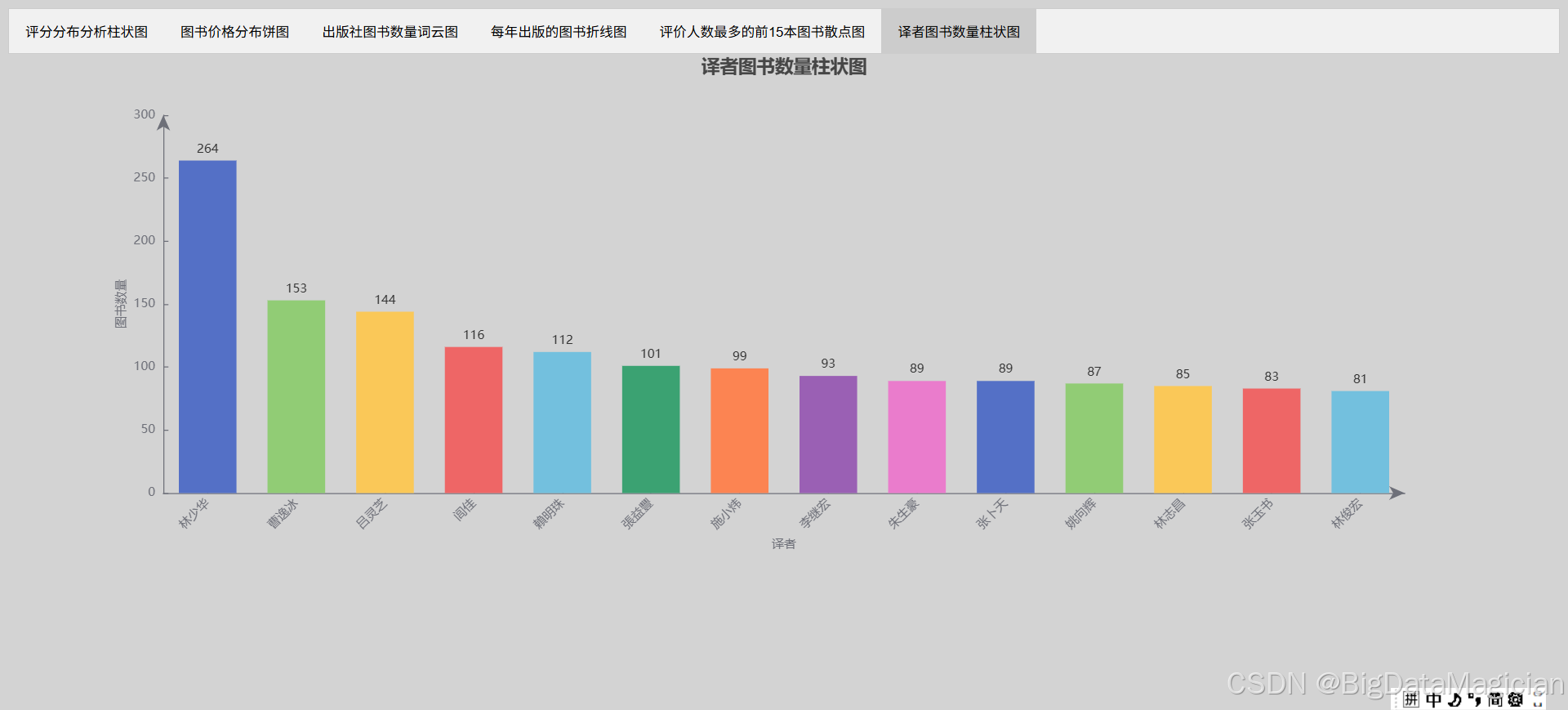
六、译者图书数据可视化
在进行译者图书数量统计分析的可视化时,首先确定结果文件的存储路径并确保目录存在,随后加载译者图书数量统计数据,同时过滤掉 "无译者" 的记录。为直观展示不同译者的图书翻译数量差异,选择横向条形图作为可视化形式,将译者名称与对应图书数量分别作为分类轴与数值轴数据。
图表采用浅灰色背景,标题 "译者图书数量柱状图" 居中显示,并隐藏图例以聚焦数据对比。x 轴(译者分类)标签旋转 45 度避免重叠,搭配轴线箭头与内部刻度增强可读性;y 轴(图书数量)优化轴线样式并标注单位。为突出各译者间的数量对比,设置条形间间隔为 35%,并根据数据值赋予不同颜色。系列配置中将数据标签置于条形顶部,便于直接读取具体数值。最终生成的交互式条形图可清晰呈现译者翻译图书的数量分布,保存为 HTML 文件完成可视化分析。
可视化代码如下:
python
# 译者图书数量统计分析数据可视化(条形图)
def translator_book_count_analysis():
html_file_path = "./结果输出层/数据可视化结果/译者图书数量柱状图.html"
path = Path(html_file_path)
path.parent.mkdir(parents=True, exist_ok=True)
data = load_data("./结果输出层/数据分析结果数据/译者图书数量统计分析.csv")
data = data[data['translator'] != '无译者']
translator_list = data['translator'].tolist()
count_list = data['count'].tolist()
bar = Bar(
init_opts=opts.InitOpts(
chart_id="c6",
# bg_color="transparent",
bg_color="lightgray",
page_title="译者图书数量柱状图",
is_horizontal_center=True,
is_fill_bg_color=True,
width="100%",
)
)
bar.add_xaxis(translator_list)
bar.add_yaxis("图书数量", count_list, color_by="data", category_gap='35%')
bar.set_global_opts(
title_opts=opts.TitleOpts(title="译者图书数量柱状图", pos_left="center"),
legend_opts=opts.LegendOpts(is_show=False),
xaxis_opts=opts.AxisOpts(
type_="category",
name="译者",
name_location="center",
name_gap=45,
axisline_opts=opts.AxisLineOpts(symbol=["none", "arrow"]),
axistick_opts=opts.AxisTickOpts(
is_align_with_label=True,
is_inside=True,
),
axislabel_opts=opts.LabelOpts(rotate=45),
splitline_opts=opts.SplitLineOpts(is_show=False)
),
yaxis_opts=opts.AxisOpts(
type_="value",
name="图书数量",
name_location="center",
name_gap=35,
axisline_opts=opts.AxisLineOpts(symbol=["none", "arrow"]),
axistick_opts=opts.AxisTickOpts(
is_align_with_label=True,
is_inside=True,
),
splitline_opts=opts.SplitLineOpts(is_show=False)
),
)
bar.set_series_opts(label_opts=opts.LabelOpts(position="top"))
bar.render(html_file_path)
return bar可视化结果图如下:
七、数据可视化完整代码
数据可视化完整代码如下:
python
import logging
from pathlib import Path
import pandas as pd
from pyecharts import options as opts
from pyecharts.charts import Bar, EffectScatter, Line, Pie, Tab
from pyecharts.charts import WordCloud
# 配置日志记录
logging.basicConfig(level=logging.ERROR, format='%(asctime)s - %(levelname)s - %(message)s')
def load_data(csv_file_path):
try:
data = pd.read_csv(csv_file_path)
return data
except FileNotFoundError:
print("未找到指定的 CSV 文件,请检查文件路径和文件名。")
except Exception as e:
print(f"加载数据时出现错误: {e}")
# 评分分布分析数据可视化(条形图)
def rating_distribution_analysis():
html_file_path = "./结果输出层/数据可视化结果/评分分布分析柱状图.html"
path = Path(html_file_path)
path.parent.mkdir(parents=True, exist_ok=True)
data = load_data("./结果输出层/数据分析结果数据/评分分布统计分析.csv")
rating_range_list = data['rating_range'].tolist()
count_list = data['count'].tolist()
bar = Bar(
init_opts=opts.InitOpts(
chart_id="c1",
# bg_color="transparent",
bg_color="lightgray",
page_title="评分分布分析柱状图",
is_horizontal_center=True,
is_fill_bg_color=True,
width="100%",
)
)
bar.add_xaxis(rating_range_list)
bar.add_yaxis("图书数量", count_list, color_by="data")
bar.set_global_opts(
title_opts=opts.TitleOpts(title="评分分布分析柱状图", pos_left="center"),
legend_opts=opts.LegendOpts(is_show=False),
xaxis_opts=opts.AxisOpts(
type_="category",
name="评分范围",
name_location="center",
name_gap=25,
axisline_opts=opts.AxisLineOpts(symbol=["none", "arrow"]),
axistick_opts=opts.AxisTickOpts(
is_align_with_label=True,
is_inside=True,
),
axislabel_opts=opts.LabelOpts(formatter="{value} 分"),
splitline_opts=opts.SplitLineOpts(is_show=False)
),
yaxis_opts=opts.AxisOpts(
type_="value",
name="图书数量",
name_location="center",
name_gap=50,
axisline_opts=opts.AxisLineOpts(symbol=["none", "arrow"]),
axistick_opts=opts.AxisTickOpts(
is_align_with_label=True,
is_inside=True,
),
splitline_opts=opts.SplitLineOpts(is_show=False)
),
)
bar.set_series_opts(
label_opts=opts.LabelOpts(position="top")
)
bar.render(html_file_path)
return bar
# 图书价格分布统计分析数据可视化(饼图)
def book_price_distribution_analysis():
html_file_path = "./结果输出层/数据可视化结果/图书价格分布饼图.html"
path = Path(html_file_path)
path.parent.mkdir(parents=True, exist_ok=True)
data = load_data("./结果输出层/数据分析结果数据/图书价格分布统计分析.csv")
pie = Pie(
init_opts=opts.InitOpts(
chart_id="c2",
# bg_color="transparent",
bg_color="lightgray",
page_title="图书价格分布饼图",
is_horizontal_center=True,
is_fill_bg_color=True,
width="100%",
)
)
pie.add(
series_name="图书数量",
data_pair=list(zip(data['price_range'], data['count'])),
color_by="data",
radius=["50%", "75%"],
rosetype="radius",
)
pie.set_global_opts(
title_opts=opts.TitleOpts(title="图书价格分布饼图", pos_left="center"),
legend_opts=opts.LegendOpts(is_show=False),
tooltip_opts=opts.TooltipOpts(formatter="{a} <br/>{b} : {c} ({d}%)"),
)
pie.set_series_opts(label_opts=opts.LabelOpts(formatter="{b} 元"), )
pie.render(html_file_path)
return pie
# 出版社图书数量统计分析数据可视化(词云图)
def publisher_book_count_analysis():
html_file_path = "./结果输出层/数据可视化结果/出版社图书数量词云图.html"
path = Path(html_file_path)
path.parent.mkdir(parents=True, exist_ok=True)
data = load_data("./结果输出层/数据分析结果数据/出版社图书数量统计分析.csv")
data_list = [tuple(row) for row in data.itertuples(index=False)]
word_count = WordCloud(
init_opts=opts.InitOpts(
chart_id="c3",
# bg_color="transparent",
bg_color="lightgray",
page_title="出版社图书数量词云图",
is_horizontal_center=True,
is_fill_bg_color=True,
width="100%",
)
)
word_count.add(
series_name="出版社图书数量词云图",
data_pair=data_list,
)
word_count.set_global_opts(
title_opts=opts.TitleOpts(title="出版社图书数量词云图", pos_left="center"),
legend_opts=opts.LegendOpts(is_show=False),
tooltip_opts=opts.TooltipOpts(formatter="{a} <br/>{b} : {c}"),
)
word_count.render(html_file_path)
return word_count
# 每年出版的图书数量统计分析数据可视化(折线图)
def yearly_book_count_analysis():
html_file_path = "./结果输出层/数据可视化结果/每年出版的图书折线图.html"
path = Path(html_file_path)
path.parent.mkdir(parents=True, exist_ok=True)
data = load_data("./结果输出层/数据分析结果数据/每年出版的图书数量统计分析.csv")
publish_year_list = data['publish_year'].tolist()
publish_year_list = [f"{int(year)}-01-01" for year in publish_year_list]
count_list = data['count'].tolist()
line = Line(
init_opts=opts.InitOpts(
chart_id="c4",
# bg_color="transparent",
bg_color="lightgray",
page_title="每年出版的图书折线图",
is_horizontal_center=True,
is_fill_bg_color=True,
width="100%"
)
)
line.add_xaxis(publish_year_list)
line.add_yaxis("图书数量", count_list, color_by='data')
line.set_global_opts(
title_opts=opts.TitleOpts(title="每年出版的图书折线图", pos_left="center"),
legend_opts=opts.LegendOpts(is_show=False),
xaxis_opts=opts.AxisOpts(
type_="time",
name="出版年份",
name_location='center',
name_gap=25,
axisline_opts=opts.AxisLineOpts(symbol=["none", "arrow"]),
axistick_opts=opts.AxisTickOpts(
is_align_with_label=True,
is_inside=True,
),
axislabel_opts=opts.LabelOpts(formatter="{yyyy}"),
splitline_opts=opts.SplitLineOpts(is_show=False),
),
yaxis_opts=opts.AxisOpts(
type_="value",
name="图书数量",
name_location="center",
name_gap=50,
axisline_opts=opts.AxisLineOpts(symbol=["none", "arrow"]),
axistick_opts=opts.AxisTickOpts(
is_align_with_label=True,
is_inside=True,
),
splitline_opts=opts.SplitLineOpts(is_show=False),
),
datazoom_opts=[
opts.DataZoomOpts(range_start=85, range_end=100, type_="slider"),
opts.DataZoomOpts(range_start=85, range_end=100, type_="inside"),
]
)
line.set_series_opts(
label_opts=opts.LabelOpts(position="top"),
markpoint_opts=opts.MarkPointOpts(
data=[
opts.MarkPointItem(type_="max", name="最大值"),
opts.MarkPointItem(type_="min", name="最小值"),
opts.MarkPointItem(type_="average", name="平均值"),
]
),
areastyle_opts=opts.AreaStyleOpts(opacity=0.5, color="lightblue", )
)
line.render(html_file_path)
return line
# 评价人数最多的前15本图书数据可视化(散点图)
def rating_count_analysis():
html_file_path = "./结果输出层/数据可视化结果/评价人数最多的前15本图书散点图.html"
path = Path(html_file_path)
path.parent.mkdir(parents=True, exist_ok=True)
data = load_data("./结果输出层/数据分析结果数据/评价人数多的图书分析.csv")
name_list = data['name'].tolist()
rating_count_list = data['rating_count'].tolist()
scatter = EffectScatter(
init_opts=opts.InitOpts(
chart_id="c5",
# bg_color="transparent",
bg_color="lightgray",
page_title="评价人数最多的前15本图书散点图",
is_horizontal_center=True,
is_fill_bg_color=True,
width="100%"
)
)
scatter.add_xaxis(name_list)
scatter.add_yaxis("评分人数", rating_count_list, color_by='data')
scatter.set_global_opts(
title_opts=opts.TitleOpts(title="评价人数最多的前15本图书散点图", pos_left="center"),
legend_opts=opts.LegendOpts(is_show=False),
xaxis_opts=opts.AxisOpts(
type_="category",
name="图书名称",
name_location='center',
name_gap=50,
axisline_opts=opts.AxisLineOpts(symbol=["none", "arrow"]),
axistick_opts=opts.AxisTickOpts(
is_align_with_label=True,
is_inside=True,
),
axislabel_opts=opts.LabelOpts(formatter="{value}", rotate=45),
splitline_opts=opts.SplitLineOpts(is_show=False),
),
yaxis_opts=opts.AxisOpts(
type_="value",
name="评分人数",
name_location="center",
name_gap=50,
axisline_opts=opts.AxisLineOpts(symbol=["none", "arrow"]),
axistick_opts=opts.AxisTickOpts(
is_align_with_label=True,
is_inside=True,
),
splitline_opts=opts.SplitLineOpts(is_show=False),
)
)
scatter.set_series_opts(label_opts=opts.LabelOpts(position="top"))
scatter.render(html_file_path)
return scatter
# 译者图书数量统计分析数据可视化(条形图)
def translator_book_count_analysis():
html_file_path = "./结果输出层/数据可视化结果/译者图书数量柱状图.html"
path = Path(html_file_path)
path.parent.mkdir(parents=True, exist_ok=True)
data = load_data("./结果输出层/数据分析结果数据/译者图书数量统计分析.csv")
data = data[data['translator'] != '无译者']
translator_list = data['translator'].tolist()
count_list = data['count'].tolist()
bar = Bar(
init_opts=opts.InitOpts(
chart_id="c6",
# bg_color="transparent",
bg_color="lightgray",
page_title="译者图书数量柱状图",
is_horizontal_center=True,
is_fill_bg_color=True,
width="100%",
)
)
bar.add_xaxis(translator_list)
bar.add_yaxis("图书数量", count_list, color_by="data", category_gap='35%')
bar.set_global_opts(
title_opts=opts.TitleOpts(title="译者图书数量柱状图", pos_left="center"),
legend_opts=opts.LegendOpts(is_show=False),
xaxis_opts=opts.AxisOpts(
type_="category",
name="译者",
name_location="center",
name_gap=45,
axisline_opts=opts.AxisLineOpts(symbol=["none", "arrow"]),
axistick_opts=opts.AxisTickOpts(
is_align_with_label=True,
is_inside=True,
),
axislabel_opts=opts.LabelOpts(rotate=45),
splitline_opts=opts.SplitLineOpts(is_show=False)
),
yaxis_opts=opts.AxisOpts(
type_="value",
name="图书数量",
name_location="center",
name_gap=35,
axisline_opts=opts.AxisLineOpts(symbol=["none", "arrow"]),
axistick_opts=opts.AxisTickOpts(
is_align_with_label=True,
is_inside=True,
),
splitline_opts=opts.SplitLineOpts(is_show=False)
),
)
bar.set_series_opts(label_opts=opts.LabelOpts(position="top"))
bar.render(html_file_path)
return bar
if __name__ == '__main__':
rating_distribution_analysis()
book_price_distribution_analysis()
publisher_book_count_analysis()
yearly_book_count_analysis()
rating_count_analysis()
translator_book_count_analysis()
tab = Tab(page_title='豆瓣图书数据可视化', bg_color="lightgray")
tab.add(rating_distribution_analysis(), "评分分布分析柱状图")
tab.add(book_price_distribution_analysis(), "图书价格分布饼图")
tab.add(publisher_book_count_analysis(), "出版社图书数量词云图")
tab.add(yearly_book_count_analysis(), "每年出版的图书折线图")
tab.add(rating_count_analysis(), "评价人数最多的前15本图书散点图")
tab.add(translator_book_count_analysis(), "译者图书数量柱状图")
tab.render("./结果输出层/数据可视化结果/豆瓣图书数据可视化.html")八、数据可视化大屏
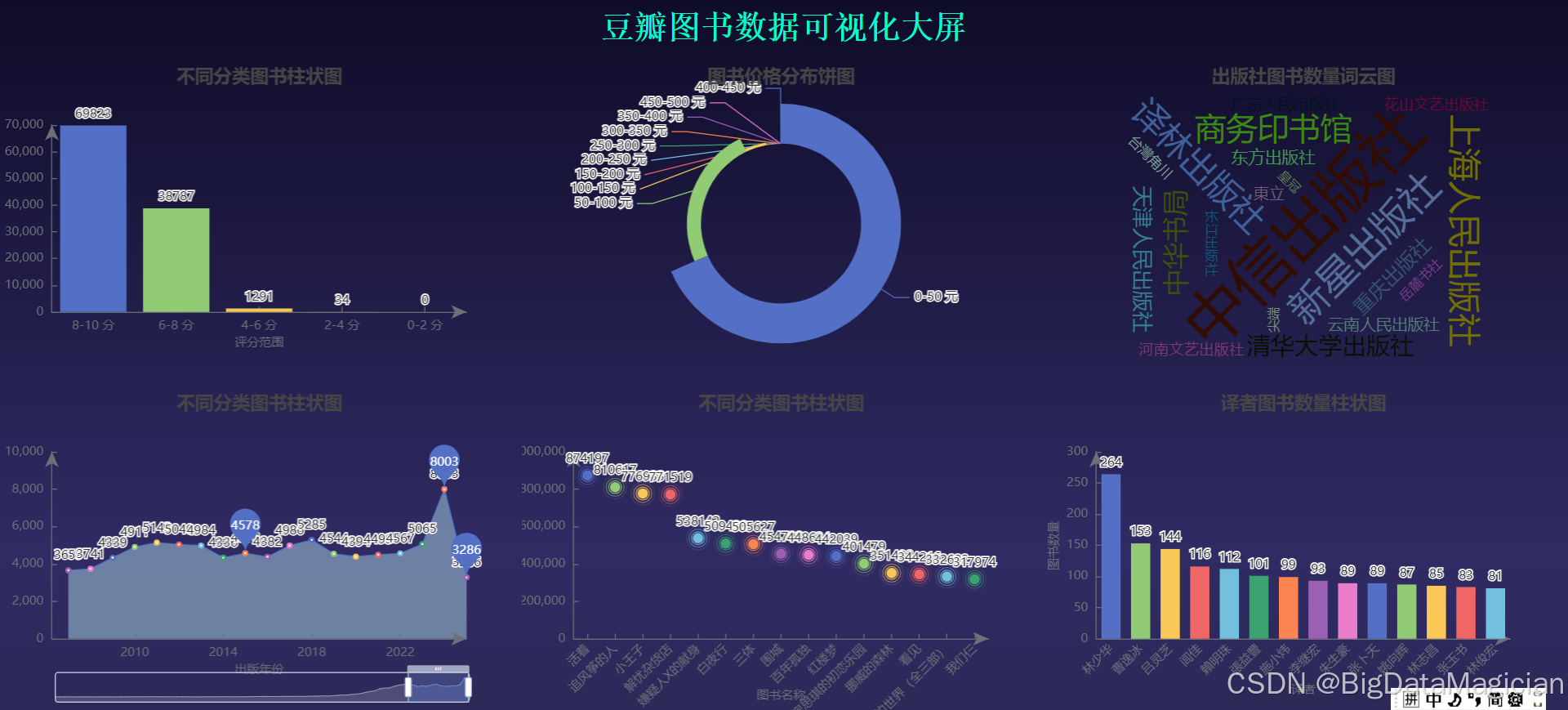
在构建豆瓣图书数据可视化大屏时,首先创建了一个标题为 "豆瓣图书数据可视化大屏" 且带有浅蓝色边框的页面容器,将评分分布分析、图书价格分布分析等六类可视化图表按默认布局添加至页面并渲染保存。为实现更规整的布局,通过配置字典定义各图表的尺寸与位置,使六张图表以两行三列的网格形式分布,每张图表宽度占比 33%、高度占比 45%,分别排列于页面上下区域。布局调整完成后,进一步优化页面视觉效果:为页面添加渐变背景,从深蓝到紫蓝的色彩过渡营造科技感;在页面顶部居中位置添加醒目的标题 "豆瓣图书数据可视化大屏",采用等宽字体并设置为亮青色以突出显示;同时统一调整页面背景样式,确保整体视觉风格协调一致,最终生成兼具数据展示与视觉美感的交互式可视化大屏。
豆瓣图书数据可视化大屏代码如下:
python
import logging
from pathlib import Path
import pandas as pd
from bs4 import BeautifulSoup
from pyecharts import options as opts
from pyecharts.charts import Bar, EffectScatter, Line, Pie, Page
from pyecharts.charts import WordCloud
# 配置日志记录
logging.basicConfig(level=logging.ERROR, format='%(asctime)s - %(levelname)s - %(message)s')
def load_data(csv_file_path):
try:
data = pd.read_csv(csv_file_path)
return data
except FileNotFoundError:
print("未找到指定的 CSV 文件,请检查文件路径和文件名。")
except Exception as e:
print(f"加载数据时出现错误: {e}")
# 评分分布分析数据可视化(条形图)
def rating_distribution_analysis():
html_file_path = "./结果输出层/数据可视化结果/评分分布分析柱状图.html"
path = Path(html_file_path)
path.parent.mkdir(parents=True, exist_ok=True)
data = load_data("./结果输出层/数据分析结果数据/评分分布统计分析.csv")
rating_range_list = data['rating_range'].tolist()
count_list = data['count'].tolist()
bar = Bar(
init_opts=opts.InitOpts(
chart_id="c1",
bg_color="transparent",
# bg_color="lightgray",
page_title="评分分布分析柱状图",
is_horizontal_center=True,
is_fill_bg_color=True,
width="100%",
)
)
bar.add_xaxis(rating_range_list)
bar.add_yaxis("图书数量", count_list, color_by="data")
bar.set_global_opts(
title_opts=opts.TitleOpts(title="不同分类图书柱状图", pos_left="center"),
legend_opts=opts.LegendOpts(is_show=False),
xaxis_opts=opts.AxisOpts(
type_="category",
name="评分范围",
name_location="center",
name_gap=25,
axisline_opts=opts.AxisLineOpts(symbol=["none", "arrow"]),
axistick_opts=opts.AxisTickOpts(
is_align_with_label=True,
is_inside=True,
),
axislabel_opts=opts.LabelOpts(formatter="{value} 分"),
splitline_opts=opts.SplitLineOpts(is_show=False)
),
yaxis_opts=opts.AxisOpts(
type_="value",
name="图书数量",
name_location="center",
name_gap=50,
axisline_opts=opts.AxisLineOpts(symbol=["none", "arrow"]),
axistick_opts=opts.AxisTickOpts(
is_align_with_label=True,
is_inside=True,
),
splitline_opts=opts.SplitLineOpts(is_show=False)
),
)
bar.set_series_opts(
label_opts=opts.LabelOpts(position="top")
)
bar.render(html_file_path)
return bar
# 图书价格分布统计分析数据可视化(饼图)
def book_price_distribution_analysis():
html_file_path = "./结果输出层/数据可视化结果/图书价格分布饼图.html"
path = Path(html_file_path)
path.parent.mkdir(parents=True, exist_ok=True)
data = load_data("./结果输出层/数据分析结果数据/图书价格分布统计分析.csv")
pie = Pie(
init_opts=opts.InitOpts(
chart_id="c2",
bg_color="transparent",
# bg_color="lightgray",
page_title="图书价格分布饼图",
is_horizontal_center=True,
is_fill_bg_color=True,
width="100%",
)
)
pie.add(
series_name="图书数量",
data_pair=list(zip(data['price_range'], data['count'])),
color_by="data",
radius=["50%", "75%"],
rosetype="radius",
)
pie.set_global_opts(
title_opts=opts.TitleOpts(title="图书价格分布饼图", pos_left="center"),
legend_opts=opts.LegendOpts(is_show=False),
tooltip_opts=opts.TooltipOpts(formatter="{a} <br/>{b} : {c} ({d}%)"),
)
pie.set_series_opts(label_opts=opts.LabelOpts(formatter="{b} 元"), )
pie.render(html_file_path)
return pie
# 出版社图书数量统计分析数据可视化(词云图)
def publisher_book_count_analysis():
html_file_path = "./结果输出层/数据可视化结果/出版社图书数量词云图.html"
path = Path(html_file_path)
path.parent.mkdir(parents=True, exist_ok=True)
data = load_data("./结果输出层/数据分析结果数据/出版社图书数量统计分析.csv")
data_list = [tuple(row) for row in data.itertuples(index=False)]
word_count = WordCloud(
init_opts=opts.InitOpts(
chart_id="c3",
bg_color="transparent",
# bg_color="lightgray",
page_title="出版社图书数量词云图",
is_horizontal_center=True,
is_fill_bg_color=True,
width="100%",
)
)
word_count.add(
series_name="出版社图书数量词云图",
data_pair=data_list,
)
word_count.set_global_opts(
title_opts=opts.TitleOpts(title="出版社图书数量词云图", pos_left="center"),
legend_opts=opts.LegendOpts(is_show=False),
tooltip_opts=opts.TooltipOpts(formatter="{a} <br/>{b} : {c}"),
)
word_count.render(html_file_path)
return word_count
# 每年出版的图书数量统计分析数据可视化(折线图)
def yearly_book_count_analysis():
html_file_path = "./结果输出层/数据可视化结果/每年出版的图书折线图.html"
path = Path(html_file_path)
path.parent.mkdir(parents=True, exist_ok=True)
data = load_data("./结果输出层/数据分析结果数据/每年出版的图书数量统计分析.csv")
publish_year_list = data['publish_year'].tolist()
publish_year_list = [f"{int(year)}-01-01" for year in publish_year_list]
count_list = data['count'].tolist()
line = Line(
init_opts=opts.InitOpts(
chart_id="c4",
bg_color="transparent",
# bg_color="lightgray",
page_title="每年出版的图书折线图",
is_horizontal_center=True,
is_fill_bg_color=True,
width="100%"
)
)
line.add_xaxis(publish_year_list)
line.add_yaxis("图书数量", count_list, color_by='data')
line.set_global_opts(
title_opts=opts.TitleOpts(title="不同分类图书柱状图", pos_left="center"),
legend_opts=opts.LegendOpts(is_show=False),
xaxis_opts=opts.AxisOpts(
type_="time",
name="出版年份",
name_location='center',
name_gap=25,
axisline_opts=opts.AxisLineOpts(symbol=["none", "arrow"]),
axistick_opts=opts.AxisTickOpts(
is_align_with_label=True,
is_inside=True,
),
axislabel_opts=opts.LabelOpts(formatter="{yyyy}"),
splitline_opts=opts.SplitLineOpts(is_show=False),
),
yaxis_opts=opts.AxisOpts(
type_="value",
name="图书数量",
name_location="center",
name_gap=50,
axisline_opts=opts.AxisLineOpts(symbol=["none", "arrow"]),
axistick_opts=opts.AxisTickOpts(
is_align_with_label=True,
is_inside=True,
),
splitline_opts=opts.SplitLineOpts(is_show=False),
),
datazoom_opts=[
opts.DataZoomOpts(range_start=85, range_end=100, type_="slider"),
opts.DataZoomOpts(range_start=85, range_end=100, type_="inside"),
]
)
line.set_series_opts(
label_opts=opts.LabelOpts(position="top"),
markpoint_opts=opts.MarkPointOpts(
data=[
opts.MarkPointItem(type_="max", name="最大值"),
opts.MarkPointItem(type_="min", name="最小值"),
opts.MarkPointItem(type_="average", name="平均值"),
]
),
areastyle_opts=opts.AreaStyleOpts(opacity=0.5, color="lightblue", )
)
line.render(html_file_path)
return line
# 评价人数最多的前15本图书数据可视化(散点图)
def rating_count_analysis():
html_file_path = "./结果输出层/数据可视化结果/评价人数最多的前15本图书散点图.html"
path = Path(html_file_path)
path.parent.mkdir(parents=True, exist_ok=True)
data = load_data("./结果输出层/数据分析结果数据/评价人数多的图书分析.csv")
name_list = data['name'].tolist()
rating_count_list = data['rating_count'].tolist()
scatter = EffectScatter(
init_opts=opts.InitOpts(
chart_id="c5",
bg_color="transparent",
# bg_color="lightgray",
page_title="评价人数最多的前15本图书散点图",
is_horizontal_center=True,
is_fill_bg_color=True,
width="100%"
)
)
scatter.add_xaxis(name_list)
scatter.add_yaxis("评分人数", rating_count_list, color_by='data')
scatter.set_global_opts(
title_opts=opts.TitleOpts(title="不同分类图书柱状图", pos_left="center"),
legend_opts=opts.LegendOpts(is_show=False),
xaxis_opts=opts.AxisOpts(
type_="category",
name="图书名称",
name_location='center',
name_gap=50,
axisline_opts=opts.AxisLineOpts(symbol=["none", "arrow"]),
axistick_opts=opts.AxisTickOpts(
is_align_with_label=True,
is_inside=True,
),
axislabel_opts=opts.LabelOpts(formatter="{value}", rotate=45),
splitline_opts=opts.SplitLineOpts(is_show=False),
),
yaxis_opts=opts.AxisOpts(
type_="value",
name="评分人数",
name_location="center",
name_gap=50,
axisline_opts=opts.AxisLineOpts(symbol=["none", "arrow"]),
axistick_opts=opts.AxisTickOpts(
is_align_with_label=True,
is_inside=True,
),
splitline_opts=opts.SplitLineOpts(is_show=False),
)
)
scatter.set_series_opts(label_opts=opts.LabelOpts(position="top"))
scatter.render(html_file_path)
return scatter
# 译者图书数量统计分析数据可视化(条形图)
def translator_book_count_analysis():
html_file_path = "./结果输出层/数据可视化结果/译者图书数量柱状图.html"
path = Path(html_file_path)
path.parent.mkdir(parents=True, exist_ok=True)
data = load_data("./结果输出层/数据分析结果数据/译者图书数量统计分析.csv")
data = data[data['translator'] != '无译者']
translator_list = data['translator'].tolist()
count_list = data['count'].tolist()
bar = Bar(
init_opts=opts.InitOpts(
chart_id="c6",
bg_color="transparent",
# bg_color="lightgray",
page_title="译者图书数量柱状图",
is_horizontal_center=True,
is_fill_bg_color=True,
width="100%",
)
)
bar.add_xaxis(translator_list)
bar.add_yaxis("图书数量", count_list, color_by="data", category_gap='35%')
bar.set_global_opts(
title_opts=opts.TitleOpts(title="译者图书数量柱状图", pos_left="center"),
legend_opts=opts.LegendOpts(is_show=False),
xaxis_opts=opts.AxisOpts(
type_="category",
name="译者",
name_location="center",
name_gap=45,
axisline_opts=opts.AxisLineOpts(symbol=["none", "arrow"]),
axistick_opts=opts.AxisTickOpts(
is_align_with_label=True,
is_inside=True,
),
axislabel_opts=opts.LabelOpts(rotate=45),
splitline_opts=opts.SplitLineOpts(is_show=False)
),
yaxis_opts=opts.AxisOpts(
type_="value",
name="图书数量",
name_location="center",
name_gap=35,
axisline_opts=opts.AxisLineOpts(symbol=["none", "arrow"]),
axistick_opts=opts.AxisTickOpts(
is_align_with_label=True,
is_inside=True,
),
splitline_opts=opts.SplitLineOpts(is_show=False)
),
)
bar.set_series_opts(label_opts=opts.LabelOpts(position="top"))
bar.render(html_file_path)
return bar
def page_default_layout():
page = Page(page_title="豆瓣图书数据可视化大屏", page_border_color='lightblue')
page.add(
rating_distribution_analysis(),
book_price_distribution_analysis(),
publisher_book_count_analysis(),
yearly_book_count_analysis(),
rating_count_analysis(),
translator_book_count_analysis()
)
page.render("./结果输出层/数据可视化结果/豆瓣图书数据可视化大屏.html")
# 定义布局配置字典
layout_config = [
{
"cid": "c1",
"width": "33%",
"height": "45%",
"top": "9%",
"left": "0"
},
{
"cid": "c2",
"width": "33%",
"height": "45%",
"top": "9%",
"left": "33.3%"
},
{
"cid": "c3",
"width": "33%",
"height": "45%",
"top": "9%",
"left": "66.6%"
},
{
"cid": "c4",
"width": "33%",
"height": "45%",
"top": "55%",
"left": "0px"
},
{
"cid": "c5",
"width": "33%",
"height": "45%",
"top": "55%",
"left": "33.3%"
},
{
"cid": "c6",
"width": "33%",
"height": "45%",
"top": "55%",
"left": "66.6%"
},
]
page.save_resize_html(
source="./结果输出层/数据可视化结果/豆瓣图书数据可视化大屏.html",
cfg_dict=layout_config,
dest="./结果输出层/数据可视化结果/豆瓣图书数据可视化大屏(新).html"
)
# 可视化大屏
def visual_large_screen():
# 读取生成的 HTML 文件
html_file_path = "./结果输出层/数据可视化结果/豆瓣图书数据可视化大屏(新).html"
with open(html_file_path, 'r', encoding='utf-8') as file:
html_content = file.read()
# 使用 BeautifulSoup 解析 HTML 内容
soup = BeautifulSoup(html_content, 'lxml')
# 在 <body> 标签内添加标题和样式
body = soup.body
title = soup.new_tag('h1',
style='text-align: center; color: #00ffcc; font-family: "Courier New", Courier, monospace; margin-top: 5px;')
title.string = "豆瓣图书数据可视化大屏"
body.insert(0, title)
# 添加科技感背景样式
style = soup.new_tag('style')
style.string = """
body {
background: linear-gradient(#0f0c29, #302b63, #24243e) no-repeat;
background-size: 100% 1080px;
color: white;
}
"""
soup.head.append(style)
# 保存修改后的 HTML 文件
new_html_file_path = "./结果输出层/数据可视化结果/豆瓣图书数据可视化大屏(新).html"
with open(new_html_file_path, 'w', encoding='utf-8') as file:
file.write(str(soup))
if __name__ == '__main__':
page_default_layout()
visual_large_screen()豆瓣图书数据可视化大屏如下图所示: