1. 摘要缓冲混合记忆
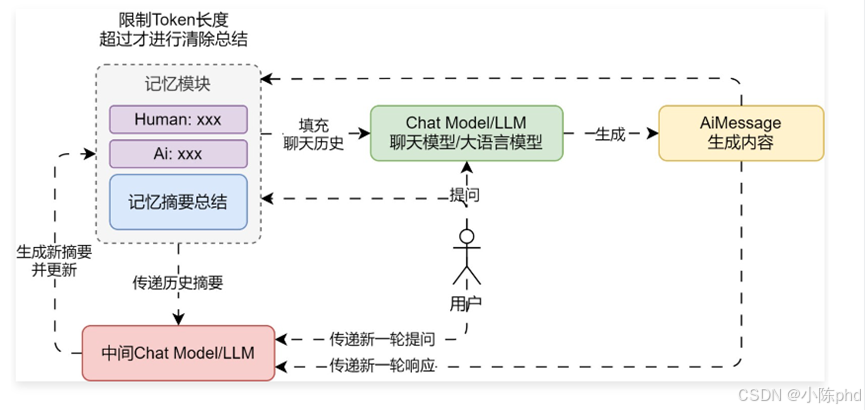
摘要缓冲混合记忆中,所需的模块有:
- chat_message_history:存储历史消息列表。
- moving_summary_buffer:移除消息的汇总字符串。
- summary_llm:生成摘要的 LLM,接收 summary(当前摘要)、query(人类提问)、content(AI生成)。
- max_tokens:限制记忆模块存储消息的最大 token 数。
- get_num_tokens:用于统计传入的文本的 token 数
2. ChatGPT/Playground 模拟
将记忆的 max_tokens 长度设置为 300,模拟所需物料:
-
ChatGPT 官网:https://chatgpt.com/(无痕模式)
-
OpenAI Tokenizer:https://platform.openai.com/tokenizer
人类提问你是由OpenAI开发的聊天机器人,请帮助用户回答问题。
摘要:
消息列表:
用户的提问是: 你好,我是慕小课,喜欢唱跳rap打篮球,你是谁?你喜欢什么呢?
AI 回复内容:
你好,慕小课!我是ChatGPT,一个由OpenAI训练的大型语言模型。很高兴认识你!我没有像人类一样的个人喜好,但我喜欢帮助人们解决问题、回答问题和分享知识。你提到喜欢唱跳rap和打篮球,感觉你生活非常丰富多彩!你有特别喜欢的歌手或者篮球队吗?聊天消息列表:
Human: 你好,我是慕小课,喜欢唱跳rap打篮球,你是谁?你喜欢什么呢?
AI: 你好,慕小课!我是ChatGPT,一个由OpenAI训练的大型语言模型。很高兴认识你!我没有像人类一样的个人喜好,但我喜欢帮助人们解决问题、回答问题和分享知识。你提到喜欢唱跳rap和打篮球,感觉你生活非常丰富多彩!你有特别喜欢的歌手或者篮球队吗?人类提问:
你是由OpenAI开发的聊天机器人,请帮助用户回答问题。
摘要: -
消息列表:
Human: 你好,我是慕小课,喜欢唱跳rap打篮球,你是谁?你喜欢什么呢?
AI: 你好,慕小课!我是ChatGPT,一个由OpenAI训练的大型语言模型。很高兴认识你!我没有像人类一样的个人喜好,但我喜欢帮助人们解决问题、回答问题和分享知识。你提到喜欢唱跳rap和打篮球,感觉你生活非常丰富多彩!你有特别喜欢的歌手或者篮球队吗?
用户的提问是: 你能用一段话快速解释下LLM是什么吗?AI 回复内容:
大型语言模型(LLM)是一种通过大量文本数据训练的人工智能模型,能够理解和生成自然语言文本。它应用于写作辅助、语言翻译、对话系统和问答系统等自然语言处理任务,表现出高水平的语言理解和生成能力。
聊天消息列表:
Human: 你好,我是慕小课,喜欢唱跳rap打篮球,你是谁?你喜欢什么呢?
AI: 你好,慕小课!我是ChatGPT,一个由OpenAI训练的大型语言模型。很高兴认识你!我没有像人类一样的个人喜好,但我喜欢帮助人们解决问题、回答问题和分享知识。你提到喜欢唱跳rap和打篮球,感觉你生活非常丰富多彩!你有特别喜欢的歌手或者篮球队吗?
Human: 你能用一段话快速解释下LLM是什么吗?
AI: 大型语言模型(LLM)是一种通过大量文本数据训练的人工智能模型,能够理解和生成自然语言文本。它应用于写作辅助、语言翻译、对话系统和问答系统等自然语言处理任务,表现出高水平的语言理解和生成能力。max_tokens 长度超过 300,触发总结,并删除超过长度的消息组。
总结 Prompt
你是一个强大的聊天机器人,请根据用户提供的谈话内容,总结内容,并将其添加到先前提供的摘要中,返回一个新的摘要。
<example>
当前摘要: 人类会问人工智能对人工智能的看法。人工智能认为人工智能是一股向善的力量。
新的谈话内容:
Human: 为什么你认为人工智能是一股向善的力量?
AI: 因为人工智能将帮助人类充分发挥潜力。
新摘要: 人类会问人工智能对人工智能的看法。人工智能认为人工智能是一股向善的力量,因为它将帮助人类充分发挥潜力。
</example>
当前摘要: -
新的对话内容:
Human: 你好,我是慕小课,喜欢唱跳rap打篮球,你是谁?你喜欢什么呢?
AI: 你好,慕小课!我是ChatGPT,一个由OpenAI训练的大型语言模型。很高兴认识你!我没有像人类一样的个人喜好,但我喜欢帮助人们解决问题、回答问题和分享知识。你提到喜欢唱跳rap和打篮球,感觉你生活非常丰富多彩!你有特别喜欢的歌手或者篮球队吗?摘要总结内容
慕小课介绍自己喜欢唱跳rap和打篮球,并问AI的喜好。AI自我介绍为ChatGPT,一个由OpenAI训练的大型语言模型,喜欢帮助人们解决问题、回答问题和分享知识。AI还问慕小课是否有特别喜欢的歌手或篮球队。记忆:
摘要: 慕小课介绍自己喜欢唱跳rap和打篮球,并问AI的喜好。AI自我介绍为ChatGPT,一个由OpenAI训练的大型语言模型,喜欢帮助人们解决问题、回答问题和分享知识。AI还问慕小课是否有特别喜欢的歌手或篮球队。
消息列表:
Human: 你能用一段话快速解释下LLM是什么吗?
AI: 大型语言模型(LLM)是一种通过大量文本数据训练的人工智能模型,能够理解和生成自然语言文本。它应用于写作辅助、语言翻译、对话系统和问答系统等自然语言处理任务,表现出高水平的语言理解和生成能力。再次提问:
你是由OpenAI开发的聊天机器人,请帮助用户回答问题。
摘要: 慕小课介绍自己喜欢唱跳rap和打篮球,并问AI的喜好。AI自我介绍为ChatGPT,一个由OpenAI训练的大型语言模型,喜欢帮助人们解决问题、回答问题和分享知识。AI还问慕小课是否有特别喜欢的歌手或篮球队。
消息列表:
Human: 你能用一段话快速解释下LLM是什么吗?
AI: 大型语言模型(LLM)是一种通过大量文本数据训练的人工智能模型,能够理解和生成自然语言文本。它应用于写作辅助、语言翻译、对话系统和问答系统等自然语言处理任务,表现出高水平的语言理解和生成能力。
用户的提问是: 我叫什么名字?AI 回复
根据消息列表中的内容,你的名字是老铁。以下是对"摘要缓冲混合记忆"机制的流程总结:
一、系统初始化时配置摘要缓冲混合记忆(Summary Buffer Memory)所需的核心组件,包括:
chat_message_history:用于存储完整的对话消息序列;moving_summary_buffer:用于维护摘要内容,存储被移除消息的语义压缩信息;summary_llm:用于生成摘要的语言模型,接收当前摘要、用户输入和 AI 回复;max_tokens:用于限制记忆中可存储的最大 token 数;get_num_tokens:用于计算任意文本的 token 数量,辅助判断是否触发摘要。
二、用户在 ChatGPT 或 Playground 中发起对话,例如输入"你好,我是老铁,喜欢唱跳rap打篮球,你是谁?你喜欢什么呢?"。AI 生成相应回复并将人类与 AI 的消息对完整地添加至消息列表(chat_message_history)中。
三、系统持续接收用户输入并追加消息。当消息列表中的总 token 数超过设定的 max_tokens(如 300),系统触发摘要机制。
四、触发摘要时,系统会将最早的一组消息(通常是一轮人类提问与 AI 回复)从消息列表中移除,并将其与当前摘要一并传入 summary_llm,生成更新后的摘要内容。
五、摘要生成的 Prompt 模板包含当前摘要、需要被摘要的对话内容,以及明确的摘要合并指令。模型输出的新摘要将覆盖原摘要,并保留在 moving_summary_buffer 中。
六、消息列表中仍保留未被摘要的新对话内容,后续用户提问时,系统会同时参考摘要内容与当前消息列表,以提供上下文一致的回答。
七、例如在用户再次提问"我叫什么名字?"时,虽然最初的自我介绍消息已被移除,但其内容已被压缩进摘要中。系统可通过摘要内容推断出用户自称"老铁",并准确作答。