我从不幻想人生能够毫无波折,但我期望遭遇困境之际,自身能够成为它的克星。
概述
LangChain与Milvus的结合构建了一套高效的语义搜索系统。LangChain负责处理多模态数据(如文本、PDF等)的嵌入生成与任务编排,Milvus作为向量数据库提供大规模向量相似性检索能力。二者协同实现从非结构化数据到结构化检索的完整流程。在本文我们将从最常见的密集+稀疏情况开始,然后介绍各种通用的混合搜索使用方法。
一、Milvus 混合搜索检索器
混合搜索结合了不同搜索范式的优势,以提高检索的准确性和鲁棒性。它既能利用密集向量搜索和稀疏向量搜索的能力,也能利用多种密集向量搜索策略的组合,确保对各种查询进行全面而精确的检索。

上图展示了最常见的混合搜索方案,即密集+稀疏混合搜索。在这种情况下,使用语义向量相似性和精确关键词匹配两种方法检索候选内容。来自这些方法的结果会被合并、重新排序,并传递给 LLM 以生成最终答案。这种方法兼顾了精确性和语义理解,对各种查询场景都非常有效。
除了密集+稀疏混合搜索,混合策略还可以结合多个密集向量模型。例如,一种密集向量模型可能专门捕捉语义的细微差别,而另一种则侧重于上下文嵌入或特定领域的表示。通过合并这些模型的结果并重新排序,这种类型的混合搜索可确保检索过程更加细致入微、更能感知上下文。
LangChain Milvus集成提供了实现混合搜索的灵活方式,它支持任意数量的向量场,以及任意自定义的密集或稀疏嵌入模型,这使得LangChain Milvus能够灵活适应各种混合搜索使用场景,同时兼容LangChain的其他功能。
二、前提条件
1、依赖安装
bash
pip install --upgrade --quiet langchain langchain-core langchain-community langchain-text-splitters langchain-milvus langchain-openai pymilvus[model]2、OPENAI API 服务
这里需要用到嵌入模型 bge-m3,当然也可以使用其他模型,最简单的方法就是申请 OPENAI_API_KEY 或者在国内大模型服务平台申请一个,例如硅基流动、阿里云百炼、火山引擎等,如果有硬件条件可以使用 Ollama 或者 vLLM 本地部署。
python
import os
# 设置环境变量
os.environ["OPENAI_BASE_URL"] = "http://localhost:8000/v1"
os.environ["OPENAI_API_KEY"] = "EMPTY"3、Milvus 服务器
使用本地服务器或者云服务器,都可以。
python
URI = "http://localhost:19530"4、数据准备
准备一些示例文档,即按主题或流派分类的虚构故事摘要。
python
from langchain_core.documents import Document
docs = [
Document(
page_content="亚索,一位来自艾欧尼亚的剑客,擅长使用风之剑术进行快速突进和范围伤害。",
metadata={"category": "刺客/战士"},
),
Document(
page_content="拉克丝,德玛西亚的光之少女,能够使用光魔法进行远程攻击和控制。",
metadata={"category": "法师/辅助"},
),
Document(
page_content="盖伦,德玛西亚之力,无畏先锋团的领袖,以强大的防御和持续作战能力著称。",
metadata={"category": "战士/坦克"},
),
Document(
page_content="艾希,弗雷尔卓德的寒冰射手,擅长远程攻击和团队控制。",
metadata={"category": "射手"},
),
Document(
page_content="李青,盲僧,一位来自艾欧尼亚的武僧,以灵活的身手和高爆发伤害闻名。",
metadata={"category": "刺客/战士"},
),
Document(
page_content="安妮,黑暗之女,能够召唤火焰熊提伯斯进行毁灭性打击。",
metadata={"category": "法师"},
),
Document(
page_content="泰达米尔,蛮族之王,拥有极高的暴击伤害和不死之身。",
metadata={"category": "战士"},
),
Document(
page_content="索拉卡,众星之子,能够为队友提供治疗和增益效果。",
metadata={"category": "辅助"},
),
Document(
page_content="劫,影流之主,擅长使用影子分身进行高爆发刺杀。",
metadata={"category": "刺客"},
),
Document(
page_content="布里茨,蒸汽机器人,能够用机械飞爪将敌人拉到自己身边。",
metadata={"category": "坦克/辅助"},
)
]三、密集嵌入 + 稀疏嵌入
方案 1(推荐):密集嵌入 + Milvus BM25 内置功能
使用密集嵌入 + Milvus BM25 内置函数组装混合检索向量存储实例。
python
from langchain_milvus import Milvus, BM25BuiltInFunction
from langchain_openai import OpenAIEmbeddings
vectorstore = Milvus.from_documents(
documents=docs,
embedding=OpenAIEmbeddings(model="BAAI/bge-m3"),
builtin_function=BM25BuiltInFunction(), # output_field_names="sparse"),
vector_field=["dense", "sparse"],
connection_args={
"uri": URI,
"token": "root:Milvus",
"db_name": "milvus_demo"
},
consistency_level="Strong", # Supported values are (`"Strong"`, `"Session"`, `"Bounded"`, `"Eventually"`). See https://milvus.io/docs/consistency.md#Consistency-Level for more details.
drop_old=False,
)2025-06-16 11:45:53,211 [DEBUG][_create_connection]: Created new connection using: ea4510a04af24e7682d2e84b2bc00136 (async_milvus_client.py:599)在上面的代码中,我们定义了 BM25BuiltInFunction 的一个实例,并将其传递给 Milvus 对象。BM25BuiltInFunction 是一个轻量级封装类, Function 的轻量级封装类,我们可以将它与OpenAIEmbeddings 一起使用,初始化密集+稀疏混合搜索 Milvus 向量存储实例。
BM25BuiltInFunction 不需要客户端传递语料库或训练,所有这些都在 Milvus 服务器端自动处理,因此用户无需关心任何词汇表和语料库。 此外,用户还可以自定义 分析器 以在 BM25 中实现自定义文本处理。
方案 2 :密集嵌入 + 定制的 LangChain 稀疏嵌入
我们也可以从langchain_milvus.utils.sparse 继承类BaseSparseEmbedding ,并实现embed_query 和embed_documents 方法来定制稀疏嵌入过程。这样,我们就可以自定义任何基于词频统计(如BM25)或神经网络(如SPADE)的稀疏嵌入方法。
下面是一个例子:
python
from typing import Dict, List
from langchain_milvus.utils.sparse import BaseSparseEmbedding
class MyCustomEmbedding(BaseSparseEmbedding): # inherit from BaseSparseEmbedding
def __init__(self, model_path): ... # code to init or load model
def embed_query(self, query: str) -> Dict[int, float]:
... # code to embed query
return { # fake embedding result
1: 0.1,
2: 0.2,
3: 0.3,
# ...
}
def embed_documents(self, texts: List[str]) -> List[Dict[int, float]]:
... # code to embed documents
return [ # fake embedding results
{
1: 0.1,
2: 0.2,
3: 0.3,
# ...
}
] * len(texts)接下来我们着重介绍一下 BM25SparseEmbedding ,它是 LangChain-Milvus 工具包中基于 BaseSparseEmbedding 类实现的稀疏嵌入工具,其核心作用包括:
1. 生成稀疏向量表示
-
继承自 BaseSparseEmbedding,通过 BM25 算法将文本转换为高维稀疏向量(大多数维度值为 0)
-
输出格式为 Dictint, float,键为词索引(维度),值为权重(如词频统计值)
2. 支持混合检索
-
可与密集嵌入(如 OpenAIEmbeddings)结合使用,传入 Milvus.from_documents 的 embedding 参数列表
-
在 Milvus 中分别存储到密集向量字段(dense)和稀疏向量字段(sparse),实现多路召回
python
vectorstore = Milvus.from_documents(
embedding=[dense_embedding, bm25_sparse_embedding], # 组合嵌入
vector_field=["dense", "sparse"] # 对应存储字段
)3. 基于语料库的词频统计
- 需预加载语料库(文档集合)初始化统计模型
python
corpus = [doc.page_content for doc in docs]
embedding = BM25SparseEmbedding(corpus=corpus) # 传入语料库- 通过词频(TF)和逆文档频率(IDF)计算词权重,提升检索相关性
4. 服务端替代方案对比
-
局限性:需客户端管理语料库和训练词汇,增加维护成本
-
建议:Milvus 2.5+ 支持服务端内置 BM25(sparse-bm25),可直接处理原始文本,无需预生成稀疏向量
总的来说,BM25SparseEmbedding 是客户端实现的 BM25 稀疏嵌入工具,适用于:
- 灵活定制:需结合业务语料调整统计逻辑的场景;
- 混合检索:与密集嵌入配合实现多路召回(如 RAG 系统);
- 兼容旧版:Milvus <2.5 版本的全文本检索需求。但生产环境优先推荐 Milvus 服务端内置 BM25,以简化流程并提升效率。
下面是一个例子:
python
from langchain_milvus.utils.sparse import BM25SparseEmbedding
# 假设这是另一个嵌入类实例
embedding1 = OpenAIEmbeddings(model="BAAI/bge-m3")
# 语料库
corpus = [doc.page_content for doc in docs]
# 初始化BM25稀疏嵌入
embedding2 = BM25SparseEmbedding(
corpus=corpus
) # pass in corpus to initialize the statistics
vectorstore = Milvus.from_documents(
documents=docs,
embedding=[embedding1, embedding2], # 传入多个嵌入类实例
vector_field=["dense", "sparse"], # 分别对应密集和稀疏嵌入
connection_args={
"uri": URI,
...
},
consistency_level="Strong", # Supported values are (`"Strong"`, `"Session"`, `"Bounded"`, `"Eventually"`). See https://milvus.io/docs/consistency.md#Consistency-Level for more details.
drop_old=False,
)虽然可以通过 BM25SparseEmbedding 类在客户端管理语料库和进行词频统计,但建议使用 Milvus 服务器端的 BM25 内置函数。使用服务器端 BM25 内置函数可以简化流程,无需用户关心语料库管理或词汇训练问题。
四、定义多个任意向量场
在初始化 Milvus 向量存储时,我们可以传入 Embeddings 列表来实现多路检索,然后对这些候选者进行 Rerankers。
下面是一个例子:
python
from langchain_community.embeddings import DashScopeEmbeddings
embedding1 = DashScopeEmbeddings(model="text-embedding-v3")
embedding2 = OpenAIEmbeddings(model="BAAI/bge-m3")
embedding3 = OpenAIEmbeddings(model="text-embedding-3-large")
vectorstore = Milvus.from_documents(
documents=docs,
embedding=[embedding1, embedding2, embedding3],
builtin_function=BM25BuiltInFunction(output_field_names="sparse"),
# `sparse` is the output field name of BM25BuiltInFunction, and `dense1` 、`dense2` 、`dense3` are the output field names of embedding1 、 embedding2、 embedding3
vector_field=["dense1", "dense2", "dense3","sparse"],
connection_args={
"uri": URI,
...
},
consistency_level="Strong", # Supported values are (`"Strong"`, `"Session"`, `"Bounded"`, `"Eventually"`). See https://milvus.io/docs/consistency.md#Consistency-Level for more details.
drop_old=False,
)
vectorstore.vector_fields['dense1', 'dense2', 'dense3', 'sparse']在这个例子中,我们有四个向量场。其中,sparse 被用作 BM25BuiltInFunction 的输出字段,而其他三个,dense1 、dense2、dense3 ,则被自动分配为三个 OpenAIEmbeddings 模型的输出字段(根据顺序)。
1、为多向量字段指定索引参数
默认情况下,每个向量场的索引类型将由嵌入类型或内置函数自动决定。不过,我们也可以指定每个向量字段的索引类型,以优化搜索性能。
python
dense_index_param_1 = {
"metric_type": "COSINE",
"index_type": "HNSW",
}
dense_index_param_2 = {
"metric_type": "IP",
"index_type": "HNSW",
}
sparse_index_param = {
"metric_type": "BM25",
"index_type": "AUTOINDEX",
}
vectorstore = Milvus.from_documents(
documents=docs,
embedding=[embedding1, embedding2],
builtin_function=BM25BuiltInFunction(output_field_names="sparse"),
index_params=[dense_index_param_1, dense_index_param_2, sparse_index_param],
vector_field=["dense1", "dense2", "sparse"],
connection_args={
"uri": URI,
...
},
consistency_level="Strong", # Supported values are (`"Strong"`, `"Session"`, `"Bounded"`, `"Eventually"`). See https://milvus.io/docs/consistency.md#Consistency-Level for more details.
drop_old=False,
)
vectorstore.vector_fields['dense1', 'dense2', 'sparse']请将索引参数列表的顺序与vectorstore.vector_fields 的顺序保持一致,以免混淆。
2、对候选数据重新排名
根据自己的要求选择加权排名器(WeightedRanker)或重新排名器(RRFRanker)
第一阶段检索结束后,我们需要对候选数据重新排名,以获得更好的结果。以下是 加权重排 的示例:
python
vectorstore = Milvus.from_documents(
documents=docs,
embedding=OpenAIEmbeddings(model="BAAI/bge-m3"),
builtin_function=BM25BuiltInFunction(),
vector_field=["dense", "sparse"],
connection_args={
"uri": URI,
"token": "root:Milvus",
"db_name": "milvus_demo"
},
consistency_level="Strong", # Supported values are (`"Strong"`, `"Session"`, `"Bounded"`, `"Eventually"`). See https://milvus.io/docs/consistency.md#Consistency-Level for more details.
drop_old=False,
)2025-06-16 11:53:15,533 [DEBUG][_create_connection]: Created new connection using: 29d4e1f2e7434b5a94f5a7e26cc43b18 (async_milvus_client.py:599)
python
query = "远程"
vectorstore.similarity_search(
query, k=1, ranker_type="weighted", ranker_params={"weights": [0.6, 0.4]}
)[Document(metadata={'category': '法师/辅助', 'pk': 458763888137079665}, page_content='拉克丝,德玛西亚的光之少女,能够使用光魔法进行远程攻击和控制。')]下面是 RRFerankers 的示例:
python
vectorstore.similarity_search(query, k=1, ranker_type="rrf", ranker_params={"k": 100})[Document(metadata={'category': '法师/辅助', 'pk': 458763888137079665}, page_content='拉克丝,德玛西亚的光之少女,能够使用光魔法进行远程攻击和控制。')]如果不传递任何有关 Reranker 的参数,则默认使用 平均加权 Reranker 策略。
五、在 RAG 中使用混合搜索
在 RAG 的应用场景中,混合搜索最普遍的方法是密集+稀疏检索,然后是 Rerankers。
1、准备数据
我们使用 PyPDFLoader 加载 PDF 文档,并使用 RecursiveCharacterTextSplitter 将文档分割成块。
python
from langchain_community.document_loaders import PyPDFLoader
file_path = "data/0001.pdf"
loader = PyPDFLoader(file_path)
docs = loader.load()
print(f"文档页数:{len(docs)} 页")文档页数:2 页
python
# 页面的字符串内容
print(f"{docs[0].page_content[:200]}\n")
# 包含文件名和页码的元数据
print(docs[0].metadata)标题:意大利面与 42 号混凝土混合对挖掘机扭矩和环境稳定性的跨学科影响分析:剑桥大学研究
报告
摘要:
本研究报告深入研究了烹饪制品和建筑材料的融合,特别调查了将意大利面与 42 号混凝土混合对
挖掘机扭矩效率的潜在影响。 令人惊讶的是,螺丝长度、高能蛋白质、核污染、核扩散、三角函
数和地缘政治人物之间的相互作用成为一个重要的研究点。 通过利用毕达哥拉斯定理和历史类比
进行细致的检查,该研究阐明
{'producer': 'LibreOffice 24.2', 'creator': 'Writer', 'creationdate': '2025-05-29T15:22:12+08:00', 'source': 'data/0001.pdf', 'total_pages': 2, 'page': 0, 'page_label': '1'}
python
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, chunk_overlap=100, add_start_index=True
)
all_splits = text_splitter.split_documents(docs)
len(all_splits)42、将文档加载到 Milvus 向量存储中
如果数据库 milvus_demo 已经储存了其他类型的数据,测试时可以设置 drop_old=True 清掉
python
vectorstore = Milvus.from_documents(
documents=all_splits,
embedding=OpenAIEmbeddings(model="BAAI/bge-m3"),
builtin_function=BM25BuiltInFunction(),
vector_field=["dense", "sparse"],
connection_args={
"uri": URI,
"token": "root:Milvus",
"db_name": "milvus_demo"
},
consistency_level="Strong", # Supported values are (`"Strong"`, `"Session"`, `"Bounded"`, `"Eventually"`). See https://milvus.io/docs/consistency.md#Consistency-Level for more details.
drop_old=False,
)2025-06-16 14:24:36,268 [DEBUG][_create_connection]: Created new connection using: 5490932c80494891865d6e46857b5cf2 (async_milvus_client.py:599)3、构建 RAG 链
我们准备好 LLM 实例和提示,然后使用 LangChain 表达式语言将它们结合到 RAG 管道中。
python
from langchain_openai import ChatOpenAI
import os
os.environ["DASHSCOPE_API_KEY"] = "sk-xxx"
# Initialize the OpenAI language model for response generation
llm = ChatOpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
model="qwen-plus", # 此处以qwen-plus为例,您可按需更换模型名称。模型列表:https://help.aliyun.com/zh/model-studio/getting-started/models
# other params...
)
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "你是谁?"}]
response = llm.invoke(messages)
print(response.json()){"content":"我是通义千问,阿里巴巴集团旗下的超大规模语言模型。我能够回答问题、创作文字,如写故事、公文、邮件、剧本等,还能进行逻辑推理、编程等任务。如果你有任何问题或需要帮助,欢迎随时告诉我!","additional_kwargs":{"refusal":null},"response_metadata":{"token_usage":{"completion_tokens":54,"prompt_tokens":22,"total_tokens":76,"completion_tokens_details":null,"prompt_tokens_details":{"audio_tokens":null,"cached_tokens":0}},"model_name":"qwen-plus","system_fingerprint":null,"id":"chatcmpl-a5a8e18e-efbd-9c10-85bb-30dfe7242854","service_tier":null,"finish_reason":"stop","logprobs":null},"type":"ai","name":null,"id":"run--c570416c-b01f-493a-9d87-778a44f93ddf-0","example":false,"tool_calls":[],"invalid_tool_calls":[],"usage_metadata":{"input_tokens":22,"output_tokens":54,"total_tokens":76,"input_token_details":{"cache_read":0},"output_token_details":{}}}
/tmp/ipykernel_4268/4214353893.py:17: PydanticDeprecatedSince20: The `json` method is deprecated; use `model_dump_json` instead. Deprecated in Pydantic V2.0 to be removed in V3.0. See Pydantic V2 Migration Guide at https://errors.pydantic.dev/2.11/migration/
print(response.json())
python
from langchain_core.runnables import RunnablePassthrough
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
# Define the prompt template for generating AI responses
PROMPT_TEMPLATE = """
Human: You are an AI assistant, and provides answers to questions by using fact based and statistical information when possible.
Use the following pieces of information to provide a concise answer to the question enclosed in <question> tags.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
<context>
{context}
</context>
<question>
{question}
</question>
The response should be specific and use statistics or numbers when possible.
Assistant:"""
# Create a PromptTemplate instance with the defined template and input variables
prompt = PromptTemplate(
template=PROMPT_TEMPLATE, input_variables=["context", "question"]
)
# Convert the vector store to a retriever
retriever = vectorstore.as_retriever()
# Define a function to format the retrieved documents
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)使用 LCEL(LangChain 表达式语言)构建 RAG 链。
python
# Define the RAG (Retrieval-Augmented Generation) chain for AI response generation
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
python
# LangGraph 还附带内置实用程序,用于可视化您应用程序的控制流
from IPython.display import Image, display
display(Image(rag_chain.get_graph().draw_mermaid_png()))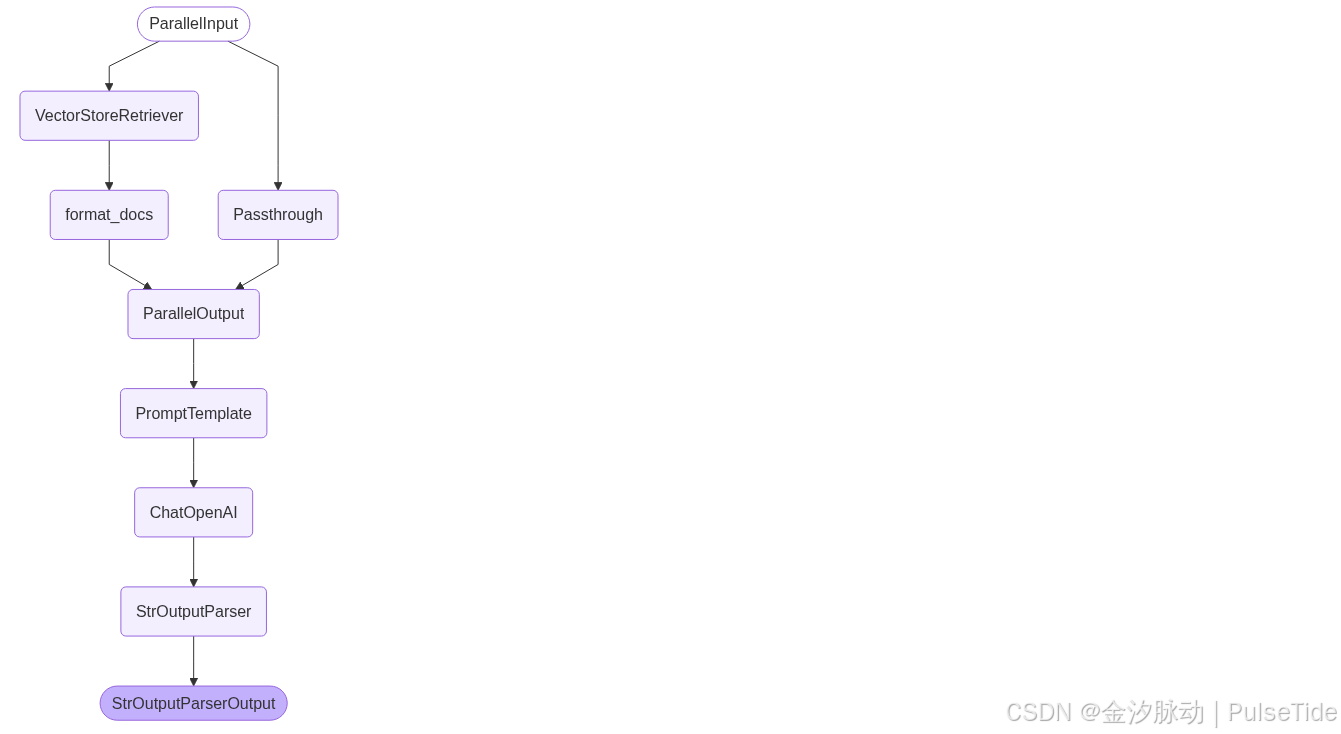
使用特定问题调用 RAG 链并获取响应:
python
query = "如何理解混凝土拌意大利面?"
res = rag_chain.invoke(query)
res'根据研究报告《Mysterious Speghetti-Concrete Mixtures: A Study in Index Dynamics》(Smith, J., 2023),混凝土拌意大利面的结合是一种跨学科研究中的非常规材料混合,旨在探索其对挖掘机扭矩效率、环境稳定性和地缘政治影响的复杂作用。\n\n### 理解混凝土拌意大利面的关键点:\n1. **物理特性与数学模型**:\n - 研究利用了基于勾股定理的数学推论,分析了螺杆长度和意大利面-混凝土成分之间的关系。研究表明,螺杆长度的变化直接影响挖掘活动期间的扭矩产生。\n - 具体而言,当意大利面与42号混凝土混合时,扭矩效率的变化可以通过以下公式近似计算: \n \\[\n T = k \\cdot L^2 + C\n \\]\n 其中,\\(T\\) 表示扭矩,\\(L\\) 是螺杆长度,\\(k\\) 和 \\(C\\) 是与材料特性相关的常数。\n\n2. **材料相互作用**:\n - 意大利面的纤维结构与混凝土的矿物化合物相结合,可能改变材料的整体强度和粘性。这种结合对挖掘机的操作产生了深远的影响。\n - 高能蛋白质(研究报告中称为"不明飞行物"或UFO)进一步增强了这种混合物的复杂性,可能导致经济发展的重大挑战。\n\n3. **环境与地缘政治影响**:\n - 报告指出,这种混合物可能引发核污染扩散的风险,特别是在太平洋地区以及沃尔玛等工业环境中。\n - 历史类比表明,类似秦始皇的地缘政治人物可能会受到这种技术变革的影响,从而改变国际关系格局。\n\n4. **跨学科视角**:\n - 这项研究整合了多个领域的知识,包括核物理、古代历史和企业外交,以全面理解这种非常规材料组合的潜在影响。\n - 例如,《The UFO Phenomenon: Implications for Economic Development and Nuclear Pollution》(Doe, A., 2022) 提供了关于高能蛋白质如何影响工业环境的具体数据。\n\n### 结论:\n混凝土拌意大利面的研究揭示了看似无关元素之间的复杂关联性,并强调了跨学科研究在应对当代工程和社会挑战中的重要性。尽管具体数值和统计结果尚未完全量化,但研究表明,这种混合物对挖掘机操作、环境稳定性和地缘政治动态具有显著影响。因此,未来需要进一步探索这些材料的协同作用及其潜在后果。'至此,我们已经构建了由 Milvus 和 LangChain 支持的混合(密集向量 + 稀疏 BM25 函数)搜索 RAG 链。
补充:使用向量存储作为检索器
向量存储检索器是一个使用向量存储来检索文档的检索器,它是一个轻量级的包装器,围绕向量存储类构建,使其符合检索器接口。 它使用向量存储实现的搜索方法,如相似性搜索和MMR,来查询向量存储中的文本。
1、创建检索器
python
retriever = vectorstore.as_retriever()使用 .as_retriever 方法从向量存储构建检索器,具体来说是一个 VectorStoreRetriever,通过调用 .invoke 方法进行检索:
python
res = retriever.invoke("what did the president say about ketanji brown jackson?")2、最大边际相关性检索
默认情况下,向量存储检索器使用相似性搜索。如果底层向量存储支持最大边际相关性搜索,我们可以将其指定为搜索类型。这有效地指定了在底层向量存储上使用的方法(例如,similarity_search、max_marginal_relevance_search 等)。
python
retriever = vectorstore.as_retriever(search_type="mmr")
python
docs = retriever.invoke("what did the president say about ketanji brown jackson?")3、传递搜索参数
我们可以使用 search_kwargs 将参数传递给底层向量存储的搜索方法。
相似性得分阈值检索
例如,我们可以设置一个相似性得分阈值,仅返回得分高于该阈值的文档。
python
retriever = vectorstore.as_retriever(
search_type="similarity_score_threshold", search_kwargs={"score_threshold": 0.5}
)指定前 k
我们还可以限制检索器返回的文档数量 k。
python
retriever = vectorstore.as_retriever(search_kwargs={"k": 1})补充:全文搜索与混合搜索对比
1、全文搜索(Full-Text Search, FTS)
核心原理
基于关键词匹配的传统检索方法,依赖 BM25 算法计算文本相关性。将文本转化为稀疏向量(高维、大部分值为零),通过统计词频、逆文档频率等指标对文档排序。
- 稀疏向量特点:维度高,仅少量非零值,适合精确匹配关键词(如产品型号、代码变量)。
- 优势:擅长处理专有名词、精确短语和完全匹配的查询(如"ERROR_CODE_404")。
Milvus 实现
- 用户直接输入文本,Milvus 自动生成稀疏向量并执行检索,无需手动处理向量转换。
- 默认使用 BM25 评分,支持模糊匹配、拼写容错等传统搜索引擎能力。
2、混合搜索(Hybrid Search)
核心原理
同时执行多路检索(如语义搜索 + 全文搜索),通过融合策略(如 RRF 算法)合并结果,返回综合排序的列表。
- 多向量支持:允许在一个 Collection 中存储多个向量字段(如密集向量、稀疏向量),并行检索不同模态的数据。
- 典型场景:
- 稀疏-密集融合:结合关键词匹配(FTS)与语义理解(密集向量)。
- 多模态搜索:同时检索图像特征向量、声纹向量等不同模态数据。
Milvus 实现
-
支持为不同向量字段创建独立索引(如 filmVector 用 IVF_FLAT,posterVector 用 HNSW)。
-
查询时指定各字段的权重(例如:weight: 0.8 给语义字段,weight: 0.2 给关键词字段),动态调整结果偏向。
| 特性 | 全文搜索 (FTS) | 混合搜索 |
|---|---|---|
| 检索目标 | 精确关键词匹配 | 综合语义 + 关键词 + 多模态数据 |
| 技术基础 | 稀疏向量 (BM25) | 多路 ANN 搜索 + RRF 融合 |
| 优势场景 | 代码搜索、产品型号查询 | RAG、多模态交叉验证(如指纹+声纹) |
| 局限 | 缺乏语义理解能力 | 需调参优化权重平衡 |