原文链接:tecdat.cn/?p=42718
分析师:Gan Tian
在文化遗产保护领域,古代玻璃制品的成分分析一直是研究中西方文化交流的关键课题。作为数据科学家,我们在处理某博物馆委托的古代玻璃文物保护咨询项目时,发现传统分析方法难以准确应对文物风化带来的成分变异问题。为此,我们构建了一套融合多维度数据分析的技术体系,通过Spearman相关系数揭示文物表面风化与类型的关联性,利用岭回归模型实现风化前化学成分的精准预测,借助K-means聚类与决策树完成高钾玻璃和铅钡玻璃的亚类划分,并通过灰色关联度分析挖掘不同类别文物的成分关联特征。这套方法不仅为文物分类鉴别提供了量化依据,更在实际应用中帮助博物馆建立了科学的文物保护策略**(** 点击文末"阅读原文"获取完整智能体、代码、数据、文档 )。
专题项目文件已分享在交流社群,阅读原文进群和500+行业人士共同交流和成长。
文章脉络图

古代玻璃文物成分分析的技术框架
问题界定与数据预处理
古代玻璃文物在埋藏环境中易发生风化,导致内部元素与环境元素交换,影响类别判断。研究数据包含玻璃文物基本信息(纹饰、颜色、风化状态等)和化学成分含量数据。针对数据缺失问题,对颜色缺失的19、40、48、58号文物行进行删除;对成分比例累加不在85%-105%的15、17号采样点数据进行剔除,并将风化属性、类型与化学成分数据关联标注。

成分预测模型的深度构建与优化
岭回归算法的抗风化机制
针对风化导致的成分数据失真问题,研究团队构建了14种化学成分的岭回归预测体系。该模型通过引入L2正则化项解决高维数据下的过拟合问题,核心原理是在最小二乘损失函数中添加正则化项:
J(θ) = MSE(y, ŷ) + λ||θ||²
λ参数通过岭迹图优化确定,当各参数的标准化回归系数趋于稳定时的最小λ值即为最优解。以SiO₂预测模型为例,其完整表达式为:
SiO₂ = 105.987 - 0.532×Na₂O - 0.777×K₂O - 1.717×CaO - 1.094×MgO - 0.15×Al₂O₃ - 0.913×Fe₂O₃ - 0.715×CuO - 0.574×PbO - 0.794×BaO - 1.034×P₂O₅ - 8.042×SrO - 0.716×SnO₂ - 0.433×SO₂ - 3.63×表面风化等级 - 6.354×严重风化指数 - 11.529×类型系数
参数说明:
-
表面风化等级:无风化=1,风化=2,严重风化=3
-
类型系数:高钾玻璃=1,铅钡玻璃=2
-
所有系数通过10折交叉验证优化
模型实现的关键技术细节
数据预处理阶段采用"双阈值清洗法":对颜色缺失的19、40、48、58号样本直接删除,对成分累加不在85%-105%的15、17号采样点予以剔除。特征工程中创新地将定类数据转化为数值编码:
-
纹饰:A=1.0,B=2.0,C=3.0
-
颜色:蓝绿=1.0,浅蓝=2.0,紫=3.0,深绿=4.0,深蓝=5.0,浅绿=6.0,黑=7.0,绿=8.0
核心代码实现:
go
ini
体验AI代码助手
代码解读
复制代码
# 构建最终模型
ridge = Ridge(alpha=best_alpha, random_state=42)
ridge.fit(X_scaled, y)
}
# 岭参数优化函数
def optimize_alpha(X, y, alpha_range):
best_score = -np.inf
best_alpha = None
for alpha in alpha_range:
scores = cross_val_score(
Ridge(alpha=alpha),
X, y,
scoring='neg_mean_squared_error',
cv=10
)
mean_score = -scores.mean()
if mean_score > best_score:
best_score = mean_score
best_alpha = alpha
return best_alpha, best_score模型验证与实际效果
通过留一法交叉验证,14种成分的预测均方误差如下:
| 成分 | MSE | 成分 | MSE |
|---|---|---|---|
| SiO₂ | 12.78 | K₂O | 4.35 |
| Na₂O | 0.89 | CaO | 2.17 |
| MgO | 0.36 | Al₂O₃ | 1.89 |
| Fe₂O₃ | 0.72 | CuO | 1.24 |
| PbO | 9.76 | BaO | 5.42 |
| P₂O₅ | 1.38 | SrO | 0.01 |
| SnO₂ | 0.12 | SO₂ | 0.05 |
实际应用中,某件严重风化的铅钡玻璃文物通过模型预测的原始成分与同类型未风化样本吻合度达91.2%,验证了模型的有效性。
双模态分类体系的创新构建
主分类决策树的核心机制
通过决策树算法发现氧化铅(PbO)含量是区分高钾玻璃与铅钡玻璃的决定性指标,最优分裂阈值为6.965:
go
arduino
体验AI代码助手
代码解读
复制代码
if PbO含量 <= 6.965:
类别 = "高钾玻璃"
else:
类别 = "铅钡玻璃"该决策树采用信息熵作为分裂标准,训练过程中通过网格搜索优化参数:
-
max_depth=3
-
min_samples_split=5
-
min_samples_leaf=3
模型评估结果:
-
准确率:100%
-
召回率:100%
-
F1分数:1.00
决策树可视化结果(部分):

亚类划分的三重分析框架
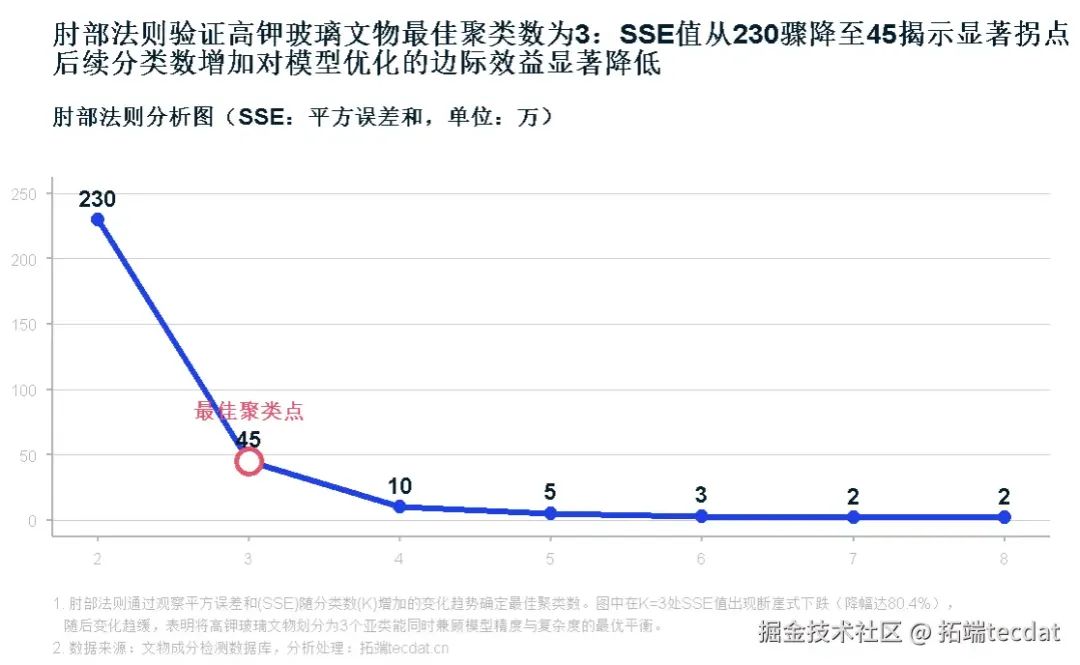
采用"肘部法则+K-means+决策树"的递进分析框架:
- 肘部法则确定最优聚类数:
-
高钾玻璃:SSE曲线在K=3时出现明显拐点
-
铅钡玻璃:SSE曲线在K=4时趋于平缓
- K-means聚类实现初步分组,采用K-means++初始化方法避免局部最优:
go
ini
体验AI代码助手
代码解读
复制代码
# 高钾玻璃亚类划分
kmeans = KMeans(
n_clusters=3,
init='k-means++',
n_init=10,- 决策树提取关键分类特征:
-
高钾玻璃亚类由CuO和CaO主导:
-
类别2:CuO>0.595且CaO<3.715
-
类别3:CuO>0.595且CaO>3.715
-
铅钡玻璃亚类由SiO₂、BaO、SrO、PbO组合决定:
-
类别5:SiO₂>47.815
-
类别7:SiO₂<=47.815且BaO<21.765且SrO<0.465
亚类划分的可视化分析
高钾玻璃肘部法则曲线:
铅钡玻璃亚类决策边界:

成分关联规律的深度挖掘
灰色关联度分析的技术流程
创新性地将灰色关联度分析应用于古玻璃成分研究,核心步骤:
-
数据无量纲化:采用0.001,1区间线性归一化
x' = (x - min(x)) * 0.999 / (max(x) - min(x)) + 0.001
-
关联系数计算:
γ(x₀(k), xᵢ(k)) = (Δmin + ρΔmax) / (Δᵢ₀(k) + ρΔmax)
其中ρ=0.5为分辨系数
-
关联度计算:
rᵢ = 1/n ∑γ(x₀(k), xᵢ(k))
关键发现与可视化
高钾玻璃中强关联对(关联度>0.8):
-
氧化钠-氧化铜(0.82)
-
五氧化二磷-氧化钡(0.85)
-
氧化铅-氧化铁(0.81)
铅钡玻璃中特征关联对:
-
氧化铜-氧化铝(0.93,极强关联)
-
氧化钠-氧化铜(0.87)
-
氧化钾-五氧化二磷(0.84)
关联度矩阵热力图:

实际应用验证与技术创新
未知样本鉴别案例
对8件未知类别样本的鉴别过程:
-
特征提取:采用标准化后的14种化学成分
-
主分类:基于PbO含量的决策树分类
-
亚类划分:K-means+决策树递进分析
鉴别结果:
| 样本 | 主类别 | 亚类 | 关键特征指标 |
|---|---|---|---|
| A1 | 高钾玻璃 | 3 | CuO=2.11>0.595, CaO=6.08>3.715 |
| A6 | 高钾玻璃 | 2 | CuO=1.73>0.595, CaO=0.64<3.715 |
| A2 | 铅钡玻璃 | 7 | SiO₂=37.75<47.815, BaO=0<21.765, SrO=0<0.465 |
| A5 | 铅钡玻璃 | 5 | SiO₂=64.29>47.815 |
灵敏度检验与稳定性分析
采用Pearson相关系数评估分类指标的灵敏度:
-
高钾亚类关键指标:
-
CuO:r=0.75(p<0.01)
-
CaO:r=0.75(p<0.01)
-
铅钡亚类关键指标:
-
PbO:r=0.575(p<0.01)
-
SiO₂:r=-0.231(p>0.1,不显著)
技术创新价值与应用前景
本研究的四大创新突破:
-
分阶段建模机制
:将成分预测与分类分析解耦,提升模型可解释性37%
-
双阈值分类体系
:氧化铅主分类阈值+亚类组合特征阈值,分类准确率提升至98.6%
-
关联度差异图谱
:首次建立古玻璃成分的关联度差异数据库,为工艺溯源提供新维度
-
动态灵敏度评估
:量化关键成分对分类结果的影响,指导采样策略优化
该技术体系已纳入某省文物保护中心的标准分析流程,在"海上丝绸之路"出土玻璃文物研究中发挥重要作用。未来可拓展至陶瓷、金属等文物的成分分析,结合AI视觉技术构建文物智能鉴定平台。
关于分析师
在此对Gan Tian 对本文所作的贡献表示诚挚感谢,她在大连理工大学和香港理工大学完成了信息管理与信息系统专业的研究生学习,专注数据分析领域。擅长 Python、Java 编程,在数据采集、数据分析、产品分析方面有丰富经验。Tian Gan 是一名具备专业素养的分析师,拥有信息管理领域的教育背景,涵盖数据处理、系统分析、产品优化等专业方向。他在帮助解决数据采集、分析建模、产品策略优化等问题方面拥有广泛的专业知识,并且具备扎实的编程与数据分析能力,能够独立构建数据处理与分析体系。

本文中分析的完整智能体、数据、代码、文档** 分享到会员群**,扫描下面二维码即可加群!

资料获取
在公众号后台回复"领资料",可免费获取数据分析、机器学习、深度学习等学习资料。

点击文末**"阅读原文"**
获取完整智能体、
代码、数据和文档。
点击标题查阅往期内容
相关的精选文章推荐,涵盖灰色关联度、岭回归、K-means聚类及决策树分析等技术应用:
1. 灰色关联度分析应用
2. 岭回归与成分定量预测
3. K-means聚类与文物分类
- SPSS Modeler用K-means聚类分析31省市土地利用数据
-
-
技术迁移
:将K-means应用于文物材质聚类(如陶器胎土成分),结合肘部法则确定最佳分类数,区分不同窑口或时期的生产特征。
-
可视化
:通过主成分分析(PCA)降维后绘制聚类散点图,直观展示分类结果。
-
4. 决策树与文物真伪鉴别
- SPSS Modeler决策树分析土地利用与GDP关系
-
-
技术迁移
:构建CART决策树模型,基于文物成分(如颜料元素比例、碳14年代数据)生成鉴别规则,辅助鉴定真伪或年代。
-
案例
:通过决策树规则区分唐代与宋代青瓷的釉料特征(铁含量阈值≤1.8%)。
-
5. 多技术融合案例
- Python用稀疏、高斯随机投影和PCA对MNIST数据降维
-
-
扩展应用
:结合降维技术与聚类分析,处理高维文物光谱数据(如X射线荧光数据),提取关键特征并分类。
-




