总览
主要以PPO为基础来学习VeRL的整体训练流程. 在PPO里主要有4个模型:
- Actor Model: 要训练的目标模型.
- Critic Model: 用于在RL训练中评估总收益, 在训练过程中需要进行参数更新
- Reference Model: SFT完的freeze模型, 不更新. 主要作用是作为base模型避免RL训练偏离SFT太远导致效果变差
- Reward model: 用于在RL中评估即时收益, 也是参数freeze不更新. 这个模型存在的意义是, Critic产出的总收益\(V_t = R_t + \gamma V_{t+1}\) 是这么计算的, 在某步的总收益如果全靠Critic凭空预估, 精确度肯定不如使用已知事实数据去逼近. \(R_t\) 的作用就是提供已知即时收益.
训练步骤主要分成3步:
-
Generation: Actor 在一批prompt样本上进行forward推理
-
Preparation: Critic/Reward/Reference 分别通过一次前向计算,对Actor的结果进行评分, 计算各个token的Reward和KL散度.
使用Critic/Reward的输出计算GAE, 把这部分的推理结果和评分放到经验池里, 再通过采样拿到用于下一轮训练的minibatch
-
Training: 用产出的训练样本更新 actor 和 critic 模型

VeRL和其他框架的区别:
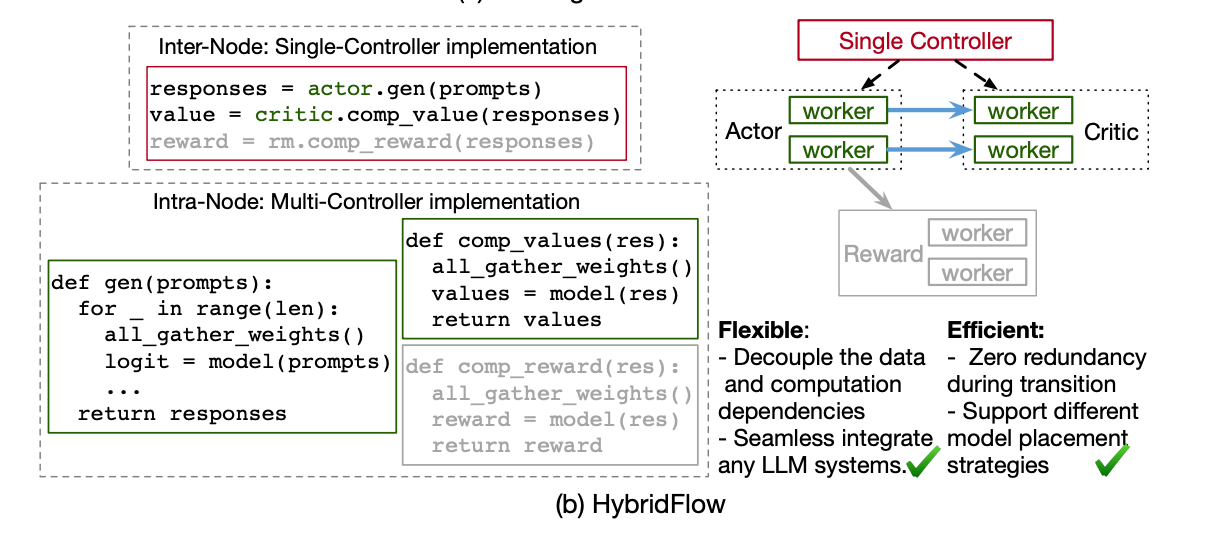
- Single Controller: 优点在于协调执行顺序灵活, 分配管理资源映射灵活. 缺点在于LLM场景下连接庞大数量的worker会有明显的调度开销.
- Multi Controller: 目前megatron/deepspeed采用的模式, 调度开销很低. 但因为没有集中控制节点各个数据流配置非常不灵活, 修改其中的一个节点需要变更其他节点的实现.
- VeRL: 采用的方案是在每个模型节点内(比如Actor的所有worker视为1个节点)采用Multi的方式, 在节点间的数据流管理采用中心节点控制的方式.
RLHF的特点
Heterogeneous model workloads: actor、critic、ref和reward四类模型有差异较大的显存占用和计算要求.比如ref和reward只需要推理, 可以只存模型参数, 但actor和critic除了推理还需要训练, 参数/梯度/optimizer都需要load进显存. 另外每个模型的规模也不一样, 比如可以用超大的critic/reward来对齐一个小的actor模型, 所以每个类型需要设置不同的并行策略和优化方案.
Unbalanced computation between actor training and generation: 这个很好理解, actor模型在training阶段是计算密集型的, 而在generation阶段是纯推理, 如果和training阶段同样的并行设置(模型并行开的很大), 其实变成了内存密集型导致资源利用率变低. 但是改成不同的并行策略会带来参数通信的额外开销, 需要综合考量.
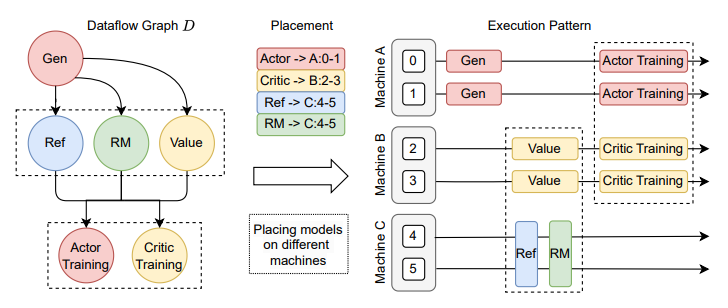
Diverse model placement requirements: 根据数据依赖和负载的关系, 把不同类型的model放到不同的device上, 从而可以并行执行. 比如下图, 把ref和reward放一块串行推理, 同时和critic推理并行执行. 如果耗时接近可以做到overlap. 但是放置策略需要配合算法设计, 尽可能的避免GPU空窗期提高利用率.
框架架构
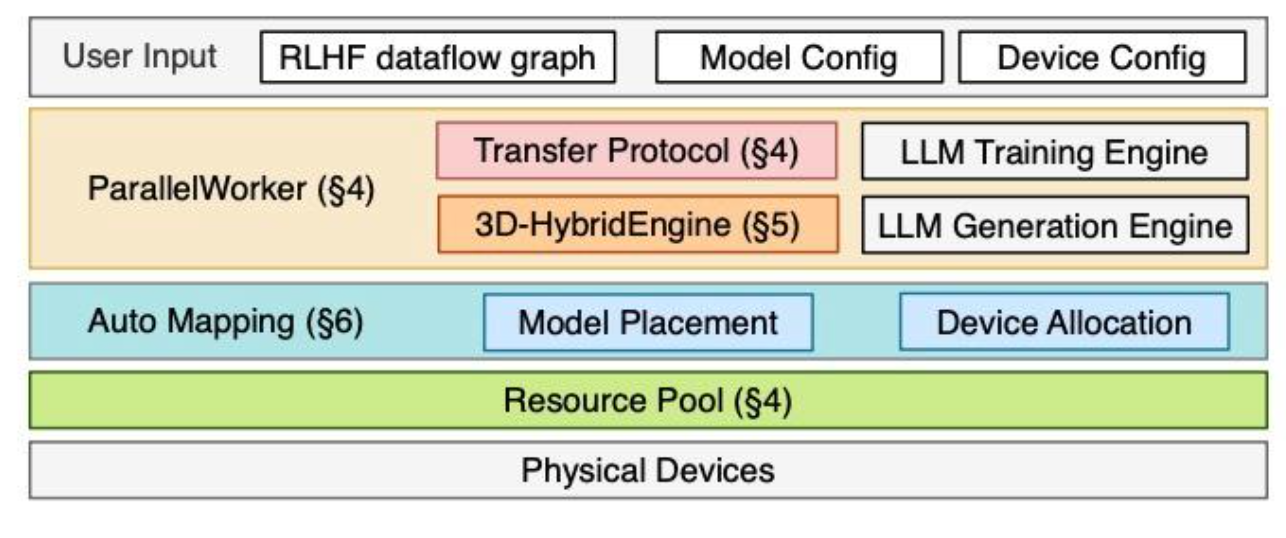
图4描述了HybridFlow的架构,它由三个主要组件组成:混合编程模型、3D-HybridEngine和自动映射算法。混合编程模型包括一组分层API,以实现RLHF数据流的灵活表达和数据流中模型的高效计算(§4)。3D-HybridEngine是专门为Actor模型的高效训练和生成而设计的,允许在两个阶段采用不同的三维并行配置,并在两个阶段之间的转换过程中实现零内存冗余和最小化通信开销(§5)。自动映射算法确定每个模型的优化设备放置,以最大限度地提高RLHF的吞吐量(§6)。
User Input
ModelConfig: Actor/Critic/Ref/Reward Model模型结构DeviceConfig: 模型在device上的放置配置, 根据这个配置再通过AutoMapping实现物理device的分配DataFlow graph: 各个model的并行策略配置. 中心节点通过这些初始化RLHF数据流, 并把这些并行operation和model分配到对应的device上.
ParallelWorker
每个model内部的MultipleController实现. 通过调用各个子model对应的训练/推理引擎来完成model的执行. 比如Ref/Reward只需要推理, 可以通过vllm/sglang等推理引擎实现高效率的推理. Actor/Critic通过Megatron等训练框架完成训练.
TransferProtocol
各个model之间的数据通信, 例如Ref/Reward infer出的结果用于经验回放样本的构建, 从而支持Actor/Critic模型训练. 通过@register装饰update函数, 每个协议包括一个collect接口和一个distribute接口, 以3D_PROTO为例:
- Collect: 收集函数的返回数据回中心节点, 例如update_actor产出的loss张量 (类似于coordinator的metrics收集)
- distribute: 派发各个DP中函数的输入数据, 例如update_actor的输入
对于包含data resharding(并行策略不一致)的场景, 流程图如下:
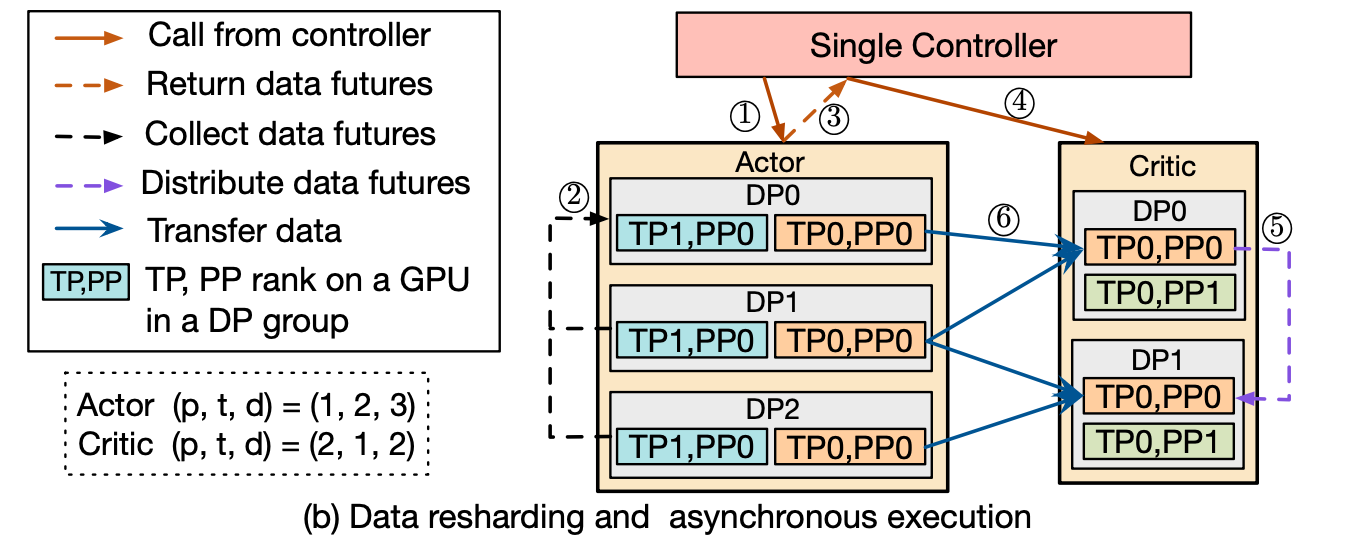
- 中心节点向actor发generate请求
- 看着像是actor通过allgather的方式把所有数据产出的future汇聚到一起? future怎么能通信得细看代码..目前想不到原理, allGather待确认
- 汇聚好的future发给中心节点
- 中心节点给critic发Prepare请求
- critic通过scatter的方式把future分配给各个DP组. scatter待确认
- 等future完成, 异步从Actor拉取推理结果. 因为DP从3个变成2个, 所以critic的每个DP相当于要推理Actor的一个半DP的结果.
3D-HybridEngine
主要解决的问题是上一节提到的, Actor在training和generation阶段, 因为推理和训练的不同特性导致需要配置不同的并行策略. 这个类的主要功能就是保证两个阶段相互切换时尽量少的通信与冗余数据的存储.
下面这张图对整个流程描述的非常清楚, 而且这个优化和zero++那个量化通信的allToall优化实现确实是有异曲同工之妙hh, 详细步骤:
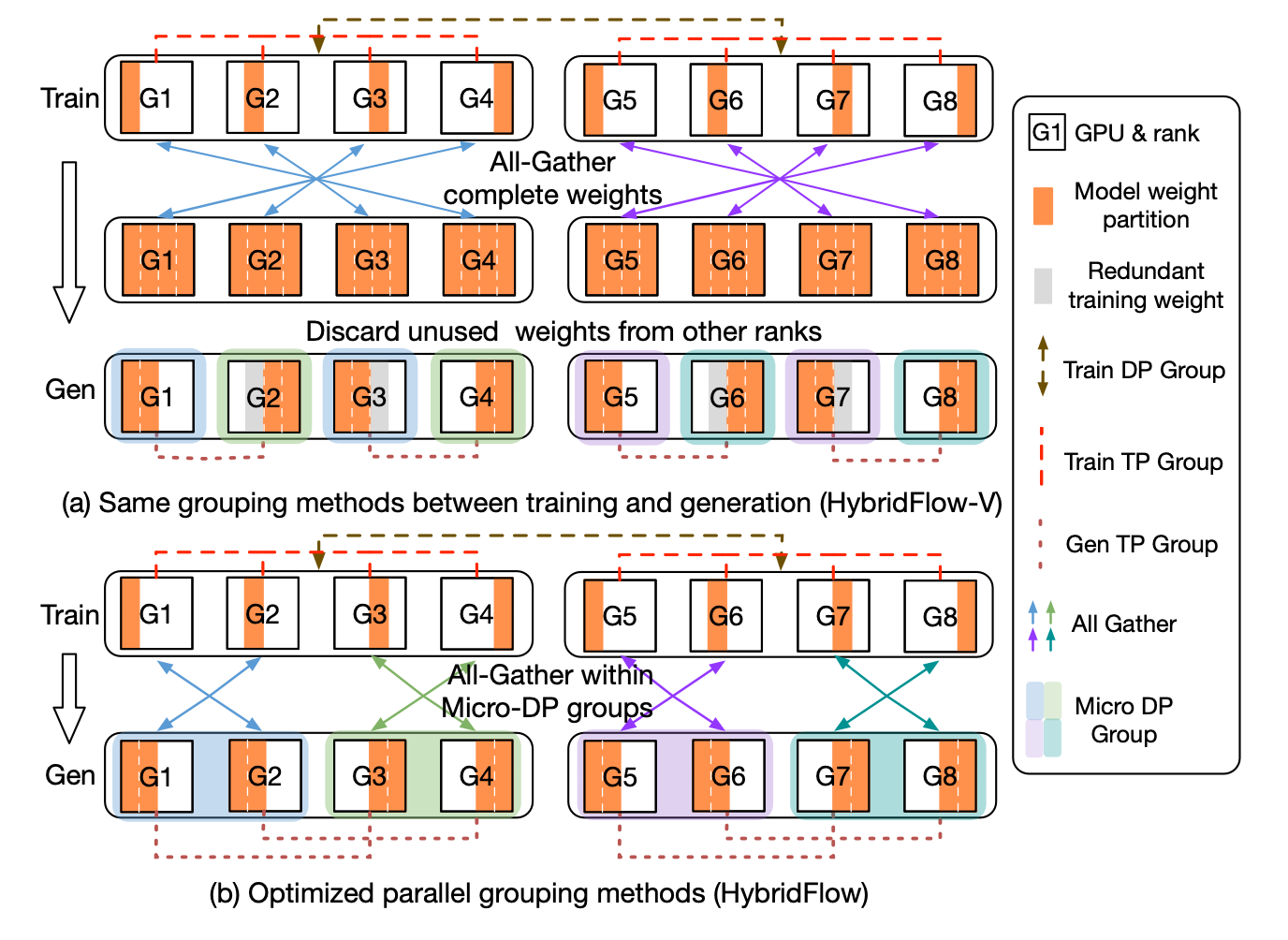
之前分析RLHF特点的时候说了, 训练阶段计算密集型模型并行大,推理阶段模型并行小. 在这张图里, 训练阶段的配置是TP4,DP2, 而推理是DP4,TP2.
Hybridflow-v: 采用的方法是在train完成后, 通过allgather的方式把TP里的全量参数完成通信, 然后在gen的时候每个device抛弃掉自己不需要的那部分. 但存在的问题是在G3上训练需要part3的参数, 但推理不需要, 如果推理的这部分参数释放掉就需要再进行一次集合通信. 为了避免这个情况通过冗余参数的方式给存储下来.
Hybridflow: 通过把DP进行进一步拆分, 把microDP内的进行allgather后, 再把不同microDP组合到一起就能在避免冗余存储的同时还进一步缩减通信. 只是过程中会动态更改每个group内的节点rank.