一、SM3算法介绍
SM3算法是中国国家密码管理局(OSCCA)于2010年发布的商用密码散列函数标准,属于我国自主设计的密码算法体系之一 ,标准文档下载地址为:SM3密码杂凑算法 。SM3算法输出长度为256位(32字节),与SHA-256类似,但采用了更适合国内安全需求的优化结构。SM3基于Merkle-Damgård迭代结构,通过填充、消息分组、扩展和压缩等步骤处理输入数据,确保任意长度的消息都能生成固定长度的摘要。作为我国密码行业标准(GM/T 0004-2012),SM3在政务、金融、物联网等领域广泛应用,是我国信息安全国产化的重要支撑。
SM3算法的核心流程包括消息填充、消息扩展和压缩函数三部分。首先,输入数据会被填充至512位的整数倍,并附加长度信息。随后,消息分组通过扩展算法生成132个32位字,供压缩函数使用。压缩函数采用64轮非线性迭代运算,结合与、或、异或、模加法等操作,并引入多个常量进行混淆,确保雪崩效应(微小输入变化导致输出巨大差异)。SM3的设计在安全性和效率上取得平衡,能够有效抵抗碰撞攻击、长度扩展攻击等威胁。
二、C语言实现
SM3算法的C语言实现主要由基础函数、核心处理流程和整体控制三部分组成。
1. 基础函数
在基础运算函数中,循环左移函数RL采用先左移再右移的组合方式实现32位字的循环移位,确保位移结果正确。Tj函数根据轮数返回不同的常量值,前16轮返回0x79cc4519,后续轮次返回0x7a879d8a。FF和GG这两个布尔函数通过条件判断自动切换运算逻辑,前者在后期采用(X&Y)|(X&Z)|(Y&Z),后者则使用(X&Y)|(~X&Z)。
2. 核心处理流程
核心处理函数sm3_one_block实现了算法的关键计算流程。消息扩展阶段先将输入的16个字存入数组,然后递归生成68个扩展字,每个新字由Wj0i-16、Wj0i-9和循环左移15位的Wj0i-3经过P1置换后,再与循环左移7位的Wj0i-13和Wj0i-6异或得到。
压缩阶段执行64轮迭代,每轮计算SS1和SS2两个中间值,其中SS1需要对A、E变量和Tj常量进行多重位移和模加运算。工作变量的更新采用级联方式,B、C、D依次赋值,F、G、H也类似处理,而A和E则分别接收TT1和P0(TT2)的新值。
3. 整体控制
主控函数sm3_get_hash负责处理输入数据的组织工作。对于完整的数据块直接调用sm3_one_block处理,对最后不足64字节的数据需要特殊处理。填充过程首先计算剩余数据长度,确定填充位的位置,在数据末尾添加0x80标志位,并用0x00填充剩余空间,最后64位存放原始消息长度的二进制表示。当剩余空间不足64位时,函数会先处理一个填充块,再单独处理一个包含长度信息的块。
具体代码如下:
cpp
#include<stdio.h>
#include<stdint.h>
static const uint32_t IV[8] = {
0x7380166f, 0x4914b2b9, 0x172442d7, 0xda8a0600,
0xa96f30bc, 0x163138aa, 0xe38dee4d, 0xb0fb0e4e
};
uint32_t Tj(uint8_t j) {
if (j < 16)
return 0x79cc4519;
return 0x7a879d8a;
}
uint32_t FF(uint32_t X, uint32_t Y, uint32_t Z, uint8_t j) {
if (j < 16)
return X ^ Y ^ Z;
return (X & Y) | (X & Z) | (Y & Z);
}
uint32_t GG(uint32_t X, uint32_t Y, uint32_t Z, uint8_t j) {
if (j < 16)
return X ^ Y ^ Z;
return (X & Y) | ((~X) & Z);
}
uint32_t RL(uint32_t a, uint8_t k) {
k = k % 32;
return ((a << k) & 0xFFFFFFFF) | ((a & 0xFFFFFFFF) >> (32 - k));
}
uint32_t P0(uint32_t X) {
return X ^ (RL(X, 9)) ^ (RL(X, 17));
}
uint32_t P1(uint32_t X) {
return X ^ (RL(X, 15)) ^ (RL(X, 23));
}
void sm3_one_block(uint32_t *hash, const uint32_t *block) {
uint32_t Wj0[68];
uint32_t Wj1[64];
uint32_t A = hash[0], B = hash[1], C = hash[2], D = hash[3];
uint32_t E = hash[4], F = hash[5], G = hash[6], H = hash[7];
uint32_t SS1, SS2, TT1, TT2;
uint8_t i, j;
for (i = 0; i < 16; i++) {
Wj0[i] = block[i];
}
for (i = 16; i < 68; i++) {
Wj0[i] = P1(Wj0[i - 16] ^ Wj0[i - 9] ^ RL(Wj0[i - 3], 15)) ^ RL(Wj0[i - 13], 7) ^ Wj0[i - 6];
}
for (i = 0; i < 64; i++) {
Wj1[i] = Wj0[i] ^ Wj0[i + 4];
}
for (j = 0; j < 64; j++) {
SS1 = RL((RL(A, 12) + E + RL(Tj(j), j)) & 0xFFFFFFFF, 7);
SS2 = SS1 ^ (RL(A, 12));
TT1 = (FF(A, B, C, j) + D + SS2 + Wj1[j]) & 0xFFFFFFFF;
TT2 = (GG(E, F, G, j) + H + SS1 + Wj0[j]) & 0xFFFFFFFF;
D = C;
C = RL(B, 9);
B = A;
A = TT1;
H = G;
G = RL(F, 19);
F = E;
E = P0(TT2);
}
hash[0] = (A ^ hash[0]);
hash[1] = (B ^ hash[1]);
hash[2] = (C ^ hash[2]);
hash[3] = (D ^ hash[3]);
hash[4] = (E ^ hash[4]);
hash[5] = (F ^ hash[5]);
hash[6] = (G ^ hash[6]);
hash[7] = (H ^ hash[7]);
}
void sm3_get_hash(uint32_t *src, uint32_t *hash, uint32_t len) {
uint8_t last_block[64] = {0};
uint32_t i = 0;
for (i = 0; i < 8; i++) {
hash[i] = IV[i];
}
for (i = 0; i < len; i = i + 64) {
if (len - i < 64)break;
sm3_one_block(hash, src + i);
}
uint32_t last_block_len = len - i;
uint32_t word_len = ((last_block_len + 3) >> 2) << 2;
uint32_t last_word_len = last_block_len & 3;
for (int j = 0; j < word_len; j++)
last_block[j] = *((uint8_t *) src + i + j);
switch (last_word_len) {
case 0:
last_block[word_len + 3] = 0x80;
break;
case 1:
last_block[word_len - 4] = 0;
last_block[word_len - 3] = 0;
last_block[word_len - 2] = 0x80;
break;
case 2:
last_block[word_len - 4] = 0;
last_block[word_len - 3] = 0x80;
break;
case 3:
last_block[word_len - 4] = 0x80;
break;
default:
break;
}
if (last_block_len < 56) {
uint32_t bit_len = len << 3;
last_block[63] = (bit_len >> 24) & 0xff;
last_block[62] = (bit_len >> 16) & 0xff;
last_block[61] = (bit_len >> 8) & 0xff;
last_block[60] = (bit_len) & 0xff;
sm3_one_block(hash, (uint32_t *) last_block);
} else {
sm3_one_block(hash, (uint32_t *) last_block);
unsigned char lblock[64] = {0};
uint32_t bit_len = len << 3;
lblock[63] = (bit_len >> 24) & 0xff;
lblock[62] = (bit_len >> 16) & 0xff;
lblock[61] = (bit_len >> 8) & 0xff;
lblock[60] = (bit_len) & 0xff;
sm3_one_block(hash, (uint32_t *) lblock);
}
}三、正确性测试
我们编写了下面的代码进行正确性验证,这是SM3标准文档中的两个测试向量:
cpp
void test_case1() {
uint32_t src[1] = {0x61626300};
uint32_t hash[8];
uint32_t len = 3;
sm3_get_hash(src, hash, len);
printf("hash(hex): ");
for (int i = 0; i < 8; i++) {
printf("%08x ", hash[i]);
}
printf("\n");
}
void test_case2() {
uint32_t src[16] = {0x61626364, 0x61626364, 0x61626364, 0x61626364, 0x61626364, 0x61626364, 0x61626364, 0x61626364,
0x61626364, 0x61626364, 0x61626364, 0x61626364, 0x61626364, 0x61626364, 0x61626364, 0x61626364};
uint32_t hash[8];
uint32_t len = 64;
sm3_get_hash(src, hash, len);
printf("hash(hex): ");
for (int i = 0; i < 8; i++) {
printf("%08x ", hash[i]);
}
printf("\n");
}
int main() {
test_case1();
test_case2();
return 0;
}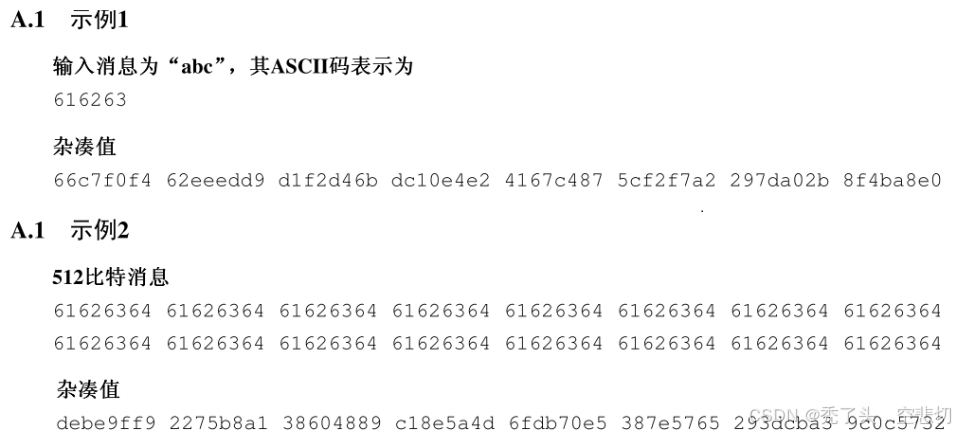
代码执行结果如下,我们的代码通过了测试。

四、总结
本次实现的SM3算法C语言版本完整呈现了该密码哈希算法的核心机制。实现过程严格遵循标准规范,通过模块化设计将算法分解为初始化、消息扩展、压缩函数等关键组件。代码采用高效的位运算和指针操作,正确处理了消息填充、分组处理等边界情况。两个标准测试用例的验证结果表明,该实现正确产生了符合预期的哈希值。整体实现既保证了算法准确性,又展现了良好的代码结构和可读性,为后续的性能优化和应用集成奠定了坚实基础。