Talk主页:http://qingkeai.online/
Fast-dLLM 是NVIDIA联合香港大学、MIT等机构推出的扩散大语言模型推理加速方案。

论文:Fast-dLLM: Training-free Acceleration of Diffusion LLM by Enabling KV Cache and Parallel Decoding
链接:http://arxiv.org/abs/2505.22618
代码:https://github.com/NVlabs/Fast-dLLM
项目主页:https://nvlabs.github.io/Fast-dLLM其通过分块KV缓存与置信度感知并行解码技术,在无需重新训练模型的前提下,实现了推理速度的突破性提升------在LLaDA模型1024 token长文本生成任务中,端到端推理速度狂飙27.6倍,整体耗时从266秒压缩至12秒,且主流基准测试准确率损失控制在2%以内。
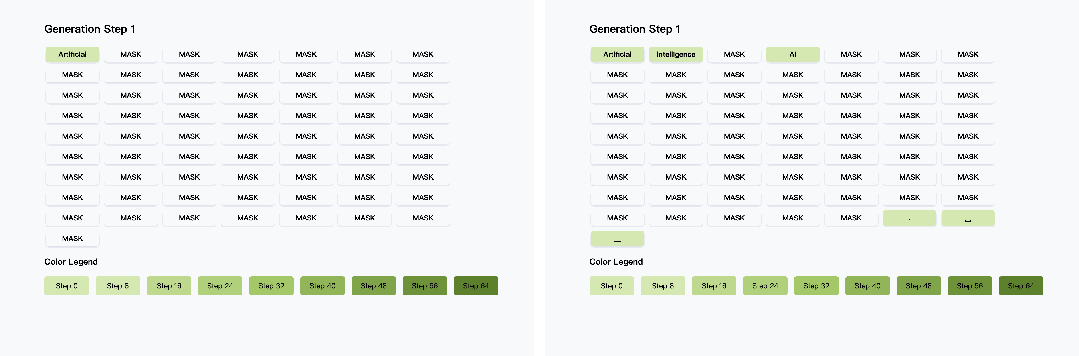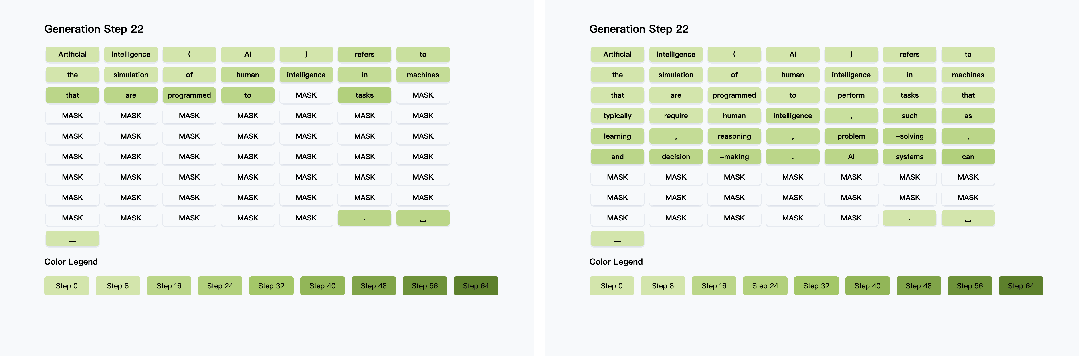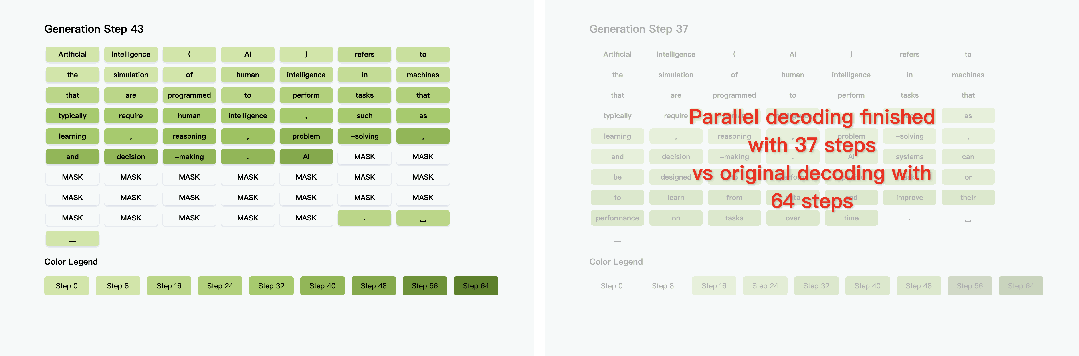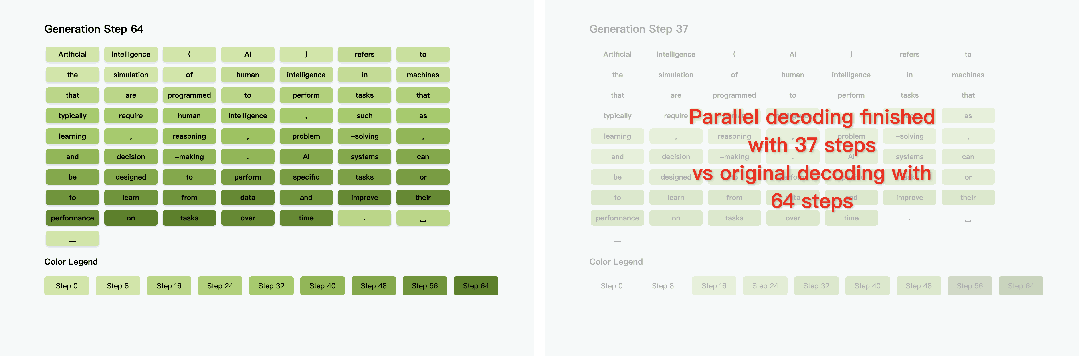
该方案兼具零训练成本与多模型兼容性,为扩散模型在长文本生成、实时交互等场景的落地提供了高效可行的优化路径。
港大&NV&MIT开源Fast-dLLM:无需重新训练模型,直接提升扩散语言模型的推理效率
6月24日晚8点 ,青稞Talk 第57期,香港大学MMLab博士生吴成岳,将直播分享《Fast-dLLM:无需重训的扩散大语言模型推理加速》。
分享嘉宾
吴成岳,香港大学MMLab博士生,导师为罗平老师和王文平老师,研究方向为多模态大模型,发表高水平学术论文十余篇,一作发表包括ICML,ACL,CVPR等业内顶级会议,2项发明专利申请中,开源项目GitHub获stars 18k+,谷歌学术引用723次,获得国家奖学金,香港政府奖学金,香港大学校长奖学金以及黑龙江省优秀毕业生,哈尔滨工业大学优秀毕业论文等荣誉,担任TPAMI,CVPR等多个顶刊顶会审稿人。
主题提纲
Fast-dLLM:无需重训的扩散大语言模型推理加速
1、扩散大语言模型推理难点
2、Fast-dLLM 核心技术解析:
-
分块 KV 缓存
-
置信度感知并行解码
3、在 LLaDA、Dream 模型上的性能验证及应用实践
直播时间
6月24日20:00 - 21:00