Spark入门到实践
一、Spark 快速入门
1.1 Spark 概述
1.2 Spark 最简安装
1.3 Spark实现WordCount
1.3.1 下载安装Scala
1.3.2 添加Spark依赖
1.3.3 Scala实现WordCount
1.3.4 通过IDEA运行WordCount
1.3.5 IDEA配置WordCount输入与输出路径
1.3.6 通过IDEA运行WordCount
1.3.7 查看运行结果
二、Spark Core 的核心功能
2.1 Spark的工作原理
2.2 弹性分布式数据集RDD
2.3 Spark 算子
2.3.1算子的作用
2.3.2 算子的分类
2.4 Pair RDD 及算子
三、Spark 分布式集群搭建
3.1 Spark 运行模式
3.2 搭建 Spark 的 Standalone 模式集群
3.2.1 下载解压 Spark
3.2.2 配置 Spark-env.sh
3.2.3 配置 slaves
3.2.4 配置文件同步其他节点
3.2.5 启动 Spark 集群
3.2.6 查看 Spark 集群状态
2.6.7 测试运行 Spark 集群
四、Spark Streaming 实时计算
4.1 Spark Streaming概述
4.1.1 Spark Streaming定义
4.1.2 Spark Streaming特点
4.2 Spark Streaming运行原理
4.2.1 Spark Streaming工作原理
4.2.2 DStream(数据集)
4.2.3 DStream vs RDD 区别
4.2.3 batch duration (批次)
4.3 Spark Streaming 编程模型
一、Spark 快速入门
1.1 Spark 概述
定义
Spark是基于内存计算的大数据并行计算框架。Spark基于内存计算的特性,提高了在大数据环境下数据处理的实时性,同时保证了高容错性和高可伸缩性,允许用户将Spark部署在大量的廉价硬件之上形成集群,提高了并行计算能力
Spark 于 2009 年诞生于加州大学伯克利分校 AMP Lab,在开发以 Spark 为核心的BDAS时,AMP Lab提出的目标是:one stack to rule them all,也就是说在一套软件栈内完成各种大数据分析任务。目前,Spark已经成为Apache软件基金会旗下的顶级开源项目。
特点
运行速度快
Spark 框架运行速度快主要有三个方面的原因:Spark基于内存计算,速度要比磁盘计算要快得多;Spark程序运行是基于线程模型,以线程的方式运行作业,要远比进程模式运行作业资源开销更小;Spark框架内部有优化器,可以优化作业的执行,提高作业执行效率。
易用性
Spark支持Java、Python和Scala的API,还支持超过80种高级算法,使用户可以快速构建不同的应用。而且Spark支持交互式的Python和Scala的Shell,可以非常方便地在这些Shell中使用Spark集群来验证解决问题的方法。
支持复杂查询
Spark支持复杂查询。在简单的"Map"及"Reduce"操作之外,Spark还支持SQL查询、流式计算、机器学习和图计算。同时,用户可以在同一个工作流中无缝搭配这些计算范式。
实时的流处理
对比MapReduce只能处理离线数据,Spark还能支持实时流计算。Spark Streaming主要用来对数据进行实时处理(Hadoop在拥有了YARN之后,也可以借助其他工具进行流式计算)。
容错性
Spark引进了弹性分布式数据集RDD(Resilient Distributed Dataset),它是分布在一组节点中的只读对象集合。这些对象集合是弹性的,如果丢失了一部分对象集合,Spark则可以根据父RDD对它们进行计算。另外在对RDD进行转换计算时,可以通过CheckPoint机制将数据持久化(比如可以持久化到HDFS),从而实现容错。
1.2 Spark 最简安装
下载
下载地址:https://archive.apache.org/dist/spark/spark-2.4.8/spark-2.4.8-bin-hadoop2.7.tgz
解压
root@hadoop1 local# tar -zxvf /usr/local/spark-2.4.8-bin-hadoop2.7.tgz
创建超链接
root@hadoop1 local# ln -s /usr/local/spark-2.4.8-bin-hadoop2.7 spark
准备测试数据集
root@hadoop1 local# vim /usr/local/words.log
hadoop hadoop hadoop
spark spark spark
flink flink flink
测试运行
统计单词词频
root@hadoop1 local# /usr/local/spark/bin/spark-shell
#读取本地文件
scala> val line=sc.textFile("/usr/local/spark/words.log")
#WordCount统计并列印
scala> line.flatMap(.split("\s+")).map((,1)).reduceByKey(+).collect().foreach(println)

1.3 Spark实现WordCount
1.3.1 下载安装Scala
下载地址:https://www.scala-lang.org/download/2.11.8.html
1.3.2 添加Spark依赖
maven依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.4.8</version>
</dependency>
.3.3 Scala实现WordCount
创建Scala目录
在bigdata项目中的Java同级目录下创建scala目录,并右击scala目录选择Mark Directory as--->Sources Root,然后在IDEA工具中选择File--->Project Structure--->Modules--->+--->Scala,在弹出的对话框中添加已经安装的Scala库,最后一路点击ok即可。
实现WordCount代码
package com.bigdata.spark
import org.apache.spark.{SparkConf, SparkContext}
object MyScalaWordCount {
def main(args: ArrayString): Unit = {
//参数检查
if(args.length < 2){
System.err.println("Usage:MyScalaWordCount <input> <output>")
System.exit(1)
}
// 获取参数
val input = args(0)
val output = args(1)
//创建scala版本的SparkContext
val conf = new SparkConf().setAppName("MyScalaWordCount") //.setMaster("local1")
val sc = new SparkContext(conf)
//读取数据
val lines = sc.textFile(input)
//进行相关计算
val resultRDD = lines.flatMap(.split("\\s")).map((,1)).reduceByKey(+)
//保存结果
resultRDD.saveAsTextFile(output)
// 停止
sc.stop()
}
}
1.3.4 通过IDEA运行WordCount
准备数据集
在本地G:\study\data目录下创建文件words.log
hadoop hadoop hadoop
spark spark spark
flink flink flink
1.3.5 IDEA配置WordCount输入与输出路径
在IDEA工具中,选择Run--->Edit Configurations打开弹窗,选择要执行的MyScalaWordCount类,在Program arguments对话框中输入MyScalaWordCount应用的输入路径(如G:\study\data\words.log)和输出路径(如G:\study\data\out)。
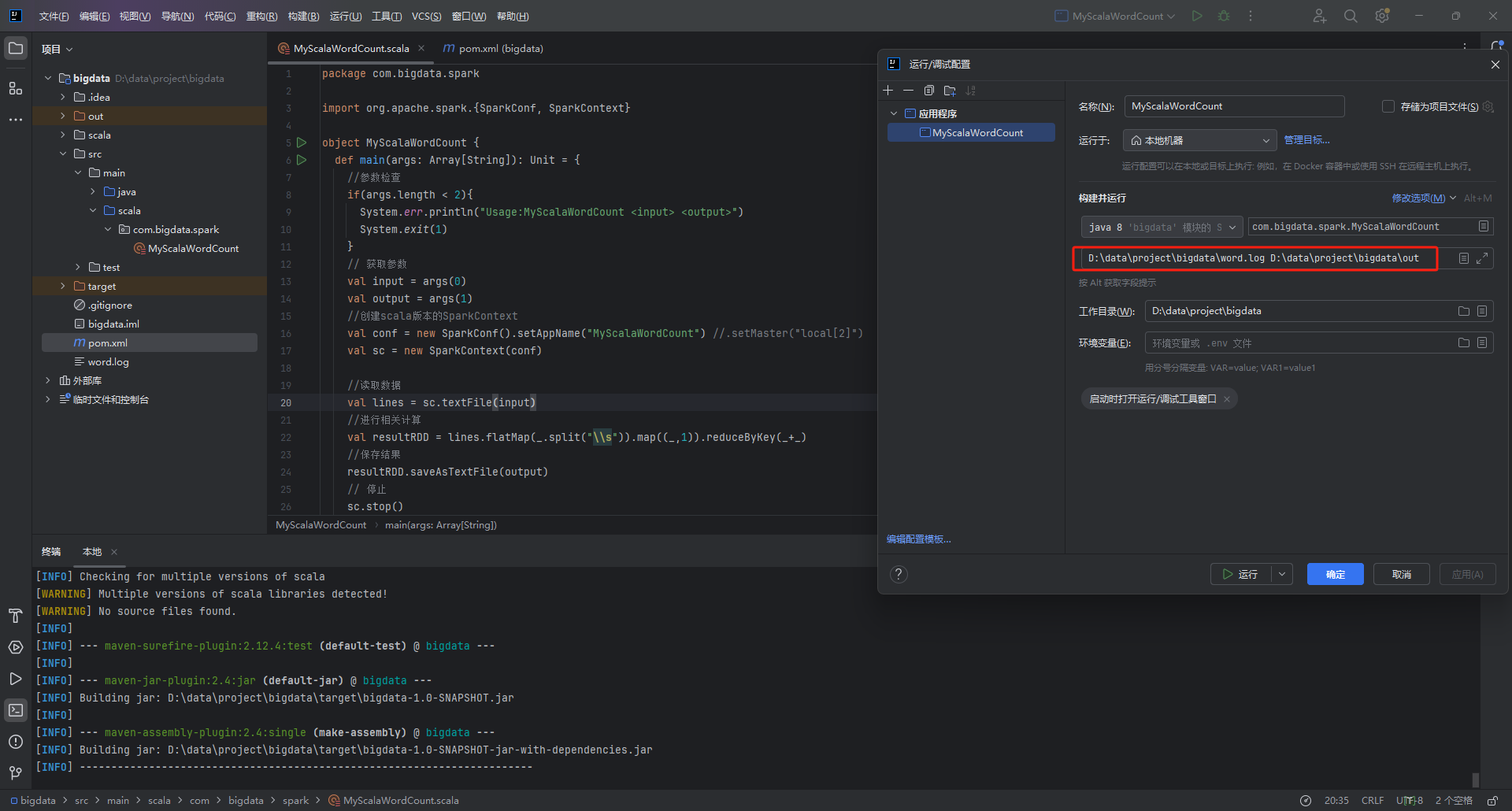
1.3.6 通过IDEA运行WordCount
IDEA运行WordCount应用
鼠标右键点击MyScalaWordCount程序,选择Run选项即可运行Scala版本的WordCount应用。
1.3.7 查看运行结果
打开运行MyScalaWordCount程序的G:\study\data\out输出目录,查看作业的运行结果如下所示。
(spark,3)
(hadoop,3)
(flink,3)

二、Spark Core 的核心功能
2.1 Spark的工作原理

2.2 弹性分布式数据集RDD
RDD简介
RDD是Spark提供的核心抽象,全名叫作弹性分布式数据集(Resillient Distributed DataSet)。Spark的核心数据模型是RDD,Spark将常用的大数据操作都转化成为RDD的子类(RDD是个抽象类,具体操作由各子类实现,如MappedRDD、Shuffled RDD)。
数据集:抽象地说,RDD就是一种元素集合。单从逻辑上的表现来看,RDD就是一个数据集合。可以简单地将RDD理解为Java里面的List集合或者数据库里面的一张表。
分布式:RDD是可以分区的,每个分区可以分布在集群中不同的节点上,从而可以对RDD中的数据进行并行操作。
弹性的:RDD默认情况下存放在内存中,但是当内存中的资源不足时,Spark会自动将RDD数据写入磁盘进行保存。对于用户来说,不必知道RDD的数据是存储在内存还是在磁盘,因为这些都是Spark底层去做,用户只需要针对RDD来进行计算和处理。RDD的这种自动在内存和磁盘之间进行权衡和切换的机制就是RDD的弹性特点所在。
RDD的两种创建方式
可从Hadoop文件系统(或者与Hadoop兼容的其他持久化存储系统,比如Hive、Cassandra、HBase)的输入来创建RDD。
可从父RDD转换得到新的RDD。
RDD的两种操作算子
Transformation算子。Transformation操作是延迟计算的,也就是说从一个RDD转换生成另一个RDD的操作不是马上执行,需要等到有Actions操作时才真正触发运算。
Action算子。Action算子会触发Spark提交作业(Job),并将数据输入到Spark系统。
RDD 数据存储模型

RDD主要支持两种操作:
转化(Transformation)操作和行动(Action)操作。RDD的转化操作是返回一个新的RDD的操作,比如map()和filter(),而行动操作则是向驱动器程序返回结果或者把结果写入外部系统的操作,会触发实际的计算,比如count()和first()。
2.3 Spark 算子
2.3.1算子的作用

说明:来源分布式存储的HDFS、Hive、Hbase文件输入到Spark生成RDD_0,通过转换算子生成RDD_1和RDD_2等,最后通过Action算子生成Scala集合
2.3.2 算子的分类
Transformation变换/转换算子
map:map对RDD中的每个元素都执行一个指定的函数来产生一个新的RDD。任何原来RDD中的元素在新RDD中都有且只有一个元素与之对应。
flatMap:flatMap与map类似,区别是原RDD中的元素经map处理后只能生产一个元素,而原RDD中的元素经flatMap处理后可生成多个元素来构建新RDD。
filter:filter的功能是对元素进行过滤,对每个元素应用传入的函数,返回值为true的元素在RDD中保留,返回为false的将过滤掉。
reduceBykey:reduceBykey就是在RDD中对元素为KV键值对的Key相同的Value值进行聚合,因此,Key相同的多个元素的值被聚合为一个值,然后与原RDD中的Key组成一个新的KV键值对。
2.4 Pair RDD 及算子
Pair RDD的定义
包含键值对类型的RDD被称作Pair RDD。Pair RDD通常用来进行聚合计算,由普通RDD做ETL转换而来。
Pair RDD算子
Pair RDD可以使用所有标准RDD上的转换操作,还提供了特有的转换操作,比如reduceByKey、groupByKey、sortByKey等。另外所有基于RDD支持的行动操作也都在PairRDD上可用。
三、Spark 分布式集群搭建
3.1 Spark 运行模式
Local模式
Local 模式是最简单的一种Spark运行模式,它采用单节点多线程方式运行。Local模式是一种开箱即用的方式,只需要在spark-env.sh中配置JAVA_HOME环境变量,无需其他任何配置即可使用,因而常用于开发和学习。
Standalone模式
Spark可以通过部署与YARN的架构类似的框架来提供自己的集群模式,该集群模式的架构设计与HDFS和YARN大相径庭,都是由一个主节点和多个从节点组成,在Spark 的Standalone模式中,master节点为主,worker节点为从。
Spark On YARN模式
简而言之,Spark On YARN 模式就是将Spark应用程序跑在YARN集群之上,通过YARN资源调度系统将executor启动在container中,从而完成driver端分发给executor的各个任务。将Spark作业跑在YARN之上,首先需要启动YARN集群,然后通过spark-shell或spark-submit的方式将作业提交到YARN上运行。
3.2 搭建 Spark 的 Standalone 模式集群
3.2.1 下载解压 Spark
见 1.2 部分
3.2.2 配置 Spark-env.sh
进入Spark根目录下的conf文件夹中,修改spark-env.sh配置文件,添加内容如下。
#复制出 Spark 环境配置文档
root@hadoop1 conf# cp /usr/local/spark/conf/spark-env.sh.template /usr/local/spark/conf/spark-env.sh
#配置 Spark 环境配置文档
root@hadoop1 conf# vim /usr/local/spark/conf/spark-env.sh
#jdk安装目录
export JAVA_HOME=/usr/local/jdk
#hadoop配置文件目录
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
#hadoop根目录
export HADOOP_HOME=/usr/local/hadoop
#Spark Web UI端口号
SPARK_MASTER_WEBUI_PORT=8888
#配置Zookeeper地址和spark在Zookeeper的节点目录
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=hadoop1:2181,hadoop2:2181,hadoop3:2181 -Dspark.deploy.zookeeper.dir=/myspark"
3.2.3 配置 slaves
进入Spark根目录下的conf文件夹中,修改slaves配置文件,添加内容如下。
root@hadoop1 conf# cp /usr/local/spark/conf/slaves.template /usr/local/spark/conf/slaves
#配置 slaves
root@hadoop1 conf# vim /usr/local/spark/conf/slaves
hadoop1
hadoop2
hadoop3
3.2.4 配置文件同步其他节点
将hadoop1节点中配置好的Spark安装目录,分发给hadoop2和hadoop3节点,因为Spark集群配置都是一样的。这里使用Linux远程命令进行分发,具体操作如下所示。
#同步到 hadoop2
root@hadoop1 conf# scp -r /usr/local/spark-2.4.8-bin-hadoop2.7 root@hadoop2:/usr/local/
#同步到 hadoop3
root@hadoop1 conf# scp -r /usr/local/spark-2.4.8-bin-hadoop2.7 root@hadoop2:/usr/local/
#hadoop2创建spark软连接
root@hadoop2 conf# ln -s /usr/local/spark-2.4.8-bin-hadoop2.7 /usr/local/spark
#hadoop3创建spark软连接
root@hadoop3 conf# ln -s /usr/local/spark-2.4.8-bin-hadoop2.7 /usr/local/spark
3.2.5 启动 Spark 集群
在启动Spark集群之前,首先确保Zookeeper集群已经启动,因为Spark集群中的master高可用选举依赖与Zookeeper集群。
1)在hadoop1节点一键启动Spark集群,操作命令如下。
root@hadoop1 conf# /usr/local/spark/sbin/start-all.sh
2)在hadoop2节点启动Spark另外一个Master进程,命令如下。
root@hadoop2 spark# /usr/local/spark/sbin/start-all.sh
3.2.6 查看 Spark 集群状态



2.6.7 测试运行 Spark 集群
- 打包
mvn clean package 
-- 打包的jar上传到 hadoop1 的 /usr/local/shell/lib/bigdata-1.0-SNAPSHOT-jar-with-dependencies.jar
-- 运行脚本
root@hadoop1 spark# bin/spark-submit --master spark://hadoop1:7077,hadoop2:7077 --class com.bigdata.spark.MyScalaWordCount /usr/local/shell/lib/bigdata-1.0-SNAPSHOT-jar-with-dependencies.jar /test/words.log /test/out16
-- 结果

四、Spark Streaming 实时计算
4.1 Spark Streaming概述
4.1.1 Spark Streaming定义
Spark Streaming是构建在Spark上的实时计算框架,且是对Spark Core API的一个扩展,它能够实现对流数据进行实时处理,并具有很好的可扩展性、高吞吐量和容错性。

4.1.2 Spark Streaming特点
易用性
Spark Streaming支持Java、Python、Scala等编程语言,可以像编写批处理程序一样编写实时计算程序。
容错性
Spark Streaming在没有额外代码和配置的情况下,可以恢复丢失的数据。对于实时计算来说,容错性至关重要。首先要明确一下Spark中RDD的容错机制,即每一个RDD都是不可变的分布式可重算的数据集,它记录着确定性的操作继承关系(lineage),所以只要输入数据是可容错的,那么任意一个RDD的分区(Partition)出错或不可用,都可以使用原始输入数据经过转换操作重新计算得到。
易整合性
Spark Streaming可以在Spark集群上运行,并且还允许重复使用相同的代码进行批处理。也就是说,实时处理可以与离线处理相结合,实现交互式的查询操作。
4.2 Spark Streaming运行原理
4.2.1 Spark Streaming工作原理
Spark Streaming支持从多种数据源获取数据,包括 Kafka、Flume、Twitter、LeroMQ、Kinesis以及TCP Sockets数据源。当Spark Streaming从数据源获取数据之后,可以使用如map、reduce、join和 window等高级函数进行复杂的计算处理,最后将处理的结果存储到分布式文件系统、数据库中,最终利用Dashboards仪表盘对数据进行可视化。
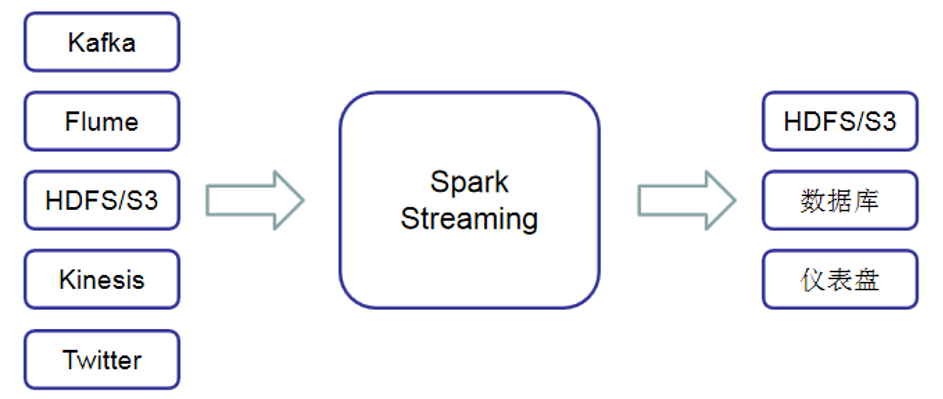
Spark Streaming先接收实时输入的数据流,并且将数据按照一定的时间间隔分成一批批的数据,每一段数据都转变成Spark中的RDD,接着交由Spark引擎进行处理,最后将数据处理结果输出到外部存储系统。

4.2.2 DStream(数据集)
DStream全称Discretized Stream(离散流),是Spark Streaming提供的一种高级抽象,代表了一个持续不断的数据流;DStream可以通过输入数据源来创建,比如Kafka、Flume,也可以通过对其他DStream应用高阶函数来创建,比如map、reduce、join、window等。
DStream的内部其实是一系列持续不断产生的RDD,RDD是Spark Core的核心抽象,即不可变的、分布式的数据集。DStream中的每个RDD都包含了一个时间段内的数据。0-1这段时间的数据累积构成了第一个RDD,1-2这段时间的数据累积构成了第二个RDD,依次类推。

4.2.3 DStream vs RDD 区别
对DStream应用的算子,其实在底层会被翻译为对DStream中每个RDD的操作。比如对一个DStream执行一个map操作,会产生一个新的DStream。其底层原理为:对输入DStream中的每个时间段的RDD,都应用一遍map操作,然后生成的RDD即作为新的DStream中的那个时间段的一个RDD;底层RDD的Transformation操作,还是由Spark Core的计算引擎来实现,Spark Streaming对Spark core进行了一层封装,隐藏了细节,然后对开发人员提供了方便易用的高层次API。

4.2.3 batch duration (批次)
Spark Streaming按照设定的batch duration(批次)来累积数据,周期结束时把周期内的数据作为一个RDD,并将任务提交给Spark 计算引擎。batch duration的大小决定了Spark Streaming提交作业的频率和处理延迟。batch duration的大小设定取决于用户的需求,一般不会太大。如下代码所示,Spark Streaming每个批次的大小为10秒,即每10秒钟提交一次作业。
val ssc = new StreamingContext(sparkConf, Seconds(10))
4.3 Spark Streaming 编程模型
输入DStream
基础数据源:StreamingContext API中直接提供了对这些数据源的支持,比如文件、socket、Akka Actor等。
高级数据源:诸如Kafka、Flume、Kinesis、Twitter等数据源,通过第三方工具类提供支持。这些数据源的使用,需要引用相关依赖。
有状态和无状态转换
无状态转换
和Spark core的语义一致,无状态转化操作就是把简单的RDD 转化操作应用到每个批次上。那么Spark Streaming的无状态转化操作,也就是对Dstream的操作会映射到每个批次的RDD上。无状态转换操作不会跨多个批次的RDD去执行,即每个批次的RDD结果不能累加。
有状态转换
a)updateStateByKey函数
有时我们需要在DStream 中跨所有批次维护状态(例如跟踪用户访问网站的会话)。针对这种情况,updateStateByKey() 为我们提供了对一个状态变量的访问,用于键值对形式的Dstream。
使用updateStateByKey需要完成两步工作:
第一步:定义状态,状态可以是任意数据类型
第二步:定义状态更新函数- update(events, oldState)
b)windows函数
windows(窗口)函数也是一种有状态操作,基于windows的操作会在一个比StreamingContext 的批次间隔更长的时间范围内,通过整合多个批次的结果,计算出整个窗口的结果。
所有基于窗口的操作都需要两个参数,分别为windowDuration以及slideDuration,两者都必须是StreamingContext 的批次间隔的整数倍。windowDuration表示窗口框住的批次个数,slideDuration表示每次窗口移动的距离(批次个数)。窗口函数具体使用方式如下所示。
val ssc = new StreamingContext(sparkConf, Seconds(10))
...
val accessLogsWindow = accessLogsDStream.window(Seconds(30), Seconds(10))
val windowCounts = accessLogsWindow.count()
DStream输出
print:在运行流程序的驱动节点上,打印 DStream 中每一批次数据的最开始 10 个元素,主要用于开发和调试。
saveAsTextFiles:以 Text 文件形式存储DStream 中的数据。
saveAsObjectFiles:以Java对象序列化的方式将DStream中的数据保存为SequenceFiles。
saveAsHadoopFiles:将 DStream 中的数据保存为 Hadoop files。
foreachRDD:这是最通用的输出操作,即将函数 func 应用于DStream 的每一个RDD。其中参数传入的函数 func 应该实现将每一个 RDD 中数据推送到外部系统,如将 RDD 存入文件或者通过网络写入数据库。