无监督异常检测作为机器学习领域的重要分支,专门用于在缺乏标记数据的环境中识别异常事件。本文深入探讨异常检测技术的理论基础与实践应用,通过Isolation Forest算法进行异常检测,并结合LightGBM作为主分类器,构建完整的欺诈检测系统。文章详细阐述了从无监督异常检测到人工反馈循环的完整工作流程,为实际业务场景中的风险控制提供参考。
异常检测是一种识别与正常数据模式显著偏离的数据点的技术方法。这些异常点,也称为离群值,通常表示系统中的异常状态、潜在威胁或需要特别关注的事件。

异常检测技术在多个关键领域发挥着重要作用。在金融领域,通过识别异常交易模式和支出行为来实现欺诈检测;在制造业中,通过监控质量指标的异常波动来保障产品质量;在医疗健康领域,通过检测生理指标的异常变化来进行健康监测。这些应用的核心目标是将异常事件标记出来,供相关专业人员进行进一步审查和处理,从而有效降低潜在风险。
根据数据标记情况和应用场景的不同,异常检测方法可以分为监督学习、半监督学习和无监督学习三大类别。
监督异常检测方法基于已标记的正常和异常样本进行模型训练。这种方法在拥有可靠标记数据且异常模式相对明确的场景中表现优异。常用的算法包括贝叶斯网络、k近邻算法和决策树等传统机器学习方法。
半监督异常检测,也称为洁净异常检测,主要用于识别高质量数据中正常模式的显著偏差。这种方法适用于数据结构良好且模式相对可预测的应用场景,如欺诈检测和制造质量控制等领域。
无监督异常检测方法通过寻找显著偏离大部分数据分布的数据点来识别异常。当异常事件相对罕见或缺乏充分了解,且训练数据中不包含标记异常样本时,这种方法特别有效。典型算法包括K-means聚类和一类支持向量机等。
无监督异常检测的主要技术方法
无监督异常检测方法根据其技术原理可以分为统计方法、聚类方法、基于邻近度的方法、时间序列分析方法和机器学习算法等几个主要类别。
统计方法
统计方法通过分析数据的统计特性来识别异常观测值。Z分数方法通过计算数据点距离均值的标准差倍数来量化异常程度,将远离均值的数据点标记为异常。百分位数方法则通过设置基于分位数的阈值来识别落在正常范围之外的数据点。这类方法最适用于具有明确统计分布特征的数据,其中异常表现为对统计正态性的明显偏离。
聚类方法
聚类方法通过将相似数据点分组来识别异常,其中异常通常表现为不属于任何明确定义簇的孤立点。DBSCAN算法基于密度进行聚类,将位于低密度区域且不属于任何簇的点视为异常。K-Means聚类则通过计算数据点到簇中心的距离来识别远离所有簇中心的异常点。这类方法在正常数据形成明显聚类结构的场景中效果最佳。
基于邻近度的方法
基于邻近度的方法通过测量数据点之间的距离或相似性来识别那些异常远离其邻居或偏离数据中心趋势的点。马哈拉诺比斯距离考虑特征间的相关性来计算数据点到分布中心的距离。局部离群因子(LOF)通过计算数据点相对于其邻居的局部密度偏差来识别在密度变化区域中的离群值。这类方法特别适用于异常由其孤立性或与其他数据点的距离来定义的场景,以及处理复杂多维数据集时密度变化具有重要意义的情况。
时间序列分析方法
时间序列分析方法专门针对序列数据设计,基于时间模式来识别异常。移动平均方法通过检测数据点对特定时期内计算的移动平均的显著偏离来识别异常。季节性分解方法将时间序列分解为趋势、季节性和残差成分,异常通常在无法通过趋势或季节性解释的残差成分中被发现。这类方法最适用于观察顺序重要的序列数据,以及异常表现为对预期趋势、季节性或时间模式偏离的场景。
机器学习算法
机器学习算法通过从数据中学习复杂模式来进行异常检测。Isolation Forest作为一种集成方法,通过构建树状结构来有效隔离异常。一类支持向量机通过在正常数据周围定义边界来将数据点分类为正常或异常。K近邻算法基于到K个最近邻居的距离来分配异常分数。自编码器作为神经网络模型,通过学习数据的压缩表示来检测具有高重构误差的异常。这类方法在复杂非线性模式定义正常行为且异常相对微妙的场景中表现最佳。
异常检测与无监督聚类的区别
虽然异常检测和无监督聚类都用于分析未标记数据中的模式,但两者在目标和应用方式上存在根本差异。
以欺诈检测为例,聚类方法有助于识别潜在欺诈交易的群组或不同的行为细分,其中某些群组可能比其他群组具有更高的风险水平。小规模的聚类簇并不一定表示欺诈行为,它们可能只是代表不同的用户行为群组。
相比之下,异常检测直接针对标记异常到足以需要调查的单个交易作为潜在欺诈,无论这些交易是否形成群组。这两种方法在基本目标上存在差异,因此产生不同类型的输出结果。
在目标定位上,聚类旨在发现未标记数据中的自然分组或细分,而异常检测专注于识别显著偏离正常模式的单个数据点。在输出结果上,聚类为每个数据点分配聚类标识符,而异常检测提供异常分数或二进制标志。
无监督聚类的典型应用场景包括:识别协同作案的欺诈团伙,他们的个别交易可能不显示强异常特征,但集体模式可疑;发现多个客户共享同一联系信息的贷款申请模式;帮助安全管理员识别本质上风险较高的商户类型。
无监督异常检测的典型应用场景包括:检测新型信用卡诈骗模式;识别员工对内部系统的未授权访问;发现合法客户账户被入侵后的异常交易;检测用户在短时间内从不同地理位置的登录行为;识别使用一次性邮箱从相同IP范围创建多个新账户的行为。
这些应用场景通常涉及寻找非常微妙的个别不规律性,在缺乏标记数据或先前示例的情况下,主要模型可能忽略这些不规律模式。
Isolation Forest算法原理
Isolation Forest是一种基于二叉树结构的异常检测算法,通过利用异常的固有特征来隔离异常点,而不是对正常数据进行建模。这种直观且高效的方法使其成为异常检测任务的热门选择。
算法的核心特征包括:采用集成方法构建多个隔离树;通过异常点被隔离的难易程度来识别异常(需要更少的分割步骤来被分离的点更可能是异常);对高维数据具有相对快速和可扩展的处理能力;作为无监督方法不需要标记数据进行训练;直接针对离群值检测而不分析正常点的分布;在处理具有众多特征的高维数据集时表现优异。
算法工作机制
Isolation Forest的工作原理可以通过以下流程来理解:首先,数据点需要遍历森林中的每棵树(树1、树2、...、树T)。

图:Isolation Forest架构以及数据点处理流程
在算法执行过程中,h_i(x)表示数据点在第i棵树中的路径长度,即数据点从根节点到叶节点所经过的边数。路径长度越短,表明数据点越可能是异常。
接下来,算法计算数据点在所有T个隔离树中的平均路径长度Eh(x):

其中T表示森林中隔离树的总数,h_i(x)表示数据点x在第i棵隔离树中的路径长度。
异常分数计算
Isolation Forest模型将平均路径长度转换为标准化的异常分数s(x):
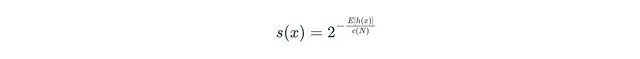
公式中各参数的含义为:Eh(x)表示x的平均路径长度;N表示用于构建单棵树的训练子集中的数据点数量(子采样大小);c(N)表示标准化因子,代表在N个点的二叉搜索树中不成功搜索的平均路径长度:

其中m表示样本大小。
异常分数的取值范围为0到1,分数越高表示成为异常的可能性越大。最终,模型将计算得到的分数与预设阈值(γ)进行比较,如果分数低于阈值,则将该数据点标记为异常。
无标记数据环境下的评估方法
在实际应用中,由于缺乏标记数据或历史记录,无法直接确认检测到的异常是否确实需要被标记。因此需要通过多种方式来评估来自Isolation Forest的异常标记结果。
人工参与循环评估
人工审查是评估异常标记的关键步骤,包括向欺诈调查专家展示标记的异常事件。调查专家对真实欺诈和误报数量的反馈为异常检测系统提供了宝贵的改进信息。关键评估问题包括:模型输出是否导致实际调查发现真实欺诈,还是主要产生噪音;模型是否能够持续一致地将相似类型的事件标记为异常。
半监督评估方法
当拥有少量保留的标记数据集时(即使由于数量太少而不用于训练),可以使用这些数据计算相关指标。Precision@k指标评估模型标记的前k个异常中真正欺诈的百分比。Recall@k指标类似于Precision@k,但专注于前k个标记中包含的实际欺诈案例数量。ROC AUC和PR AUC指标将异常分数视为连续变量并绘制相应的性能曲线。
合成异常注入测试
通过向干净数据集中注入已知数量的合成异常,观察模型成功识别的比例。这种方法有助于对不同无监督算法进行基准测试比较。
这些评估方法的价值在于:生成新的标记数据用于重新训练主要模型;创建新特征或规则来应对新兴威胁;调整Isolation Forest超参数(如contamination参数)以优化检测准确性。
实验设计与实现
本节通过信用卡交易数据集演示异常检测的完整周期,包括Isolation Forest调优、人工反馈循环评估,以及使用新标记数据训练LightGBM模型。
数据预处理
Isolation Forest与其他基于决策树的模型类似,需要进行适当的数据预处理。从Financial Transactions Dataset: Analytics数据集加载数据后,对数值特征执行列转换以进行标准化和归一化处理。
原始数据集结构:

经过列转换后的数据:
[[-1.39080197 -0.03606896 0.04983562 -1.30648276 0.37940361 -1.67063883]
[-0.192827 -0.52484299 -0.42640285 -0.52439344 1.85293745 -0.46941254]
[ 0.66316843 -0.62795398 -0.5266197 -0.03136157 -0.46709455 -0.40267775]
...
[ 0.66316843 -0.96249769 -0.85253289 -1.06913227 1.39833658 -1.53716925]
[-1.56087595 -0.67663075 -0.57406012 0.17866552 -1.97198017 0.26467019]
[-0.3129254 -0.53653239 -0.43765848 -0.20775319 -1.59575877 0.06446581]]数据形状:(1000, 6)
Isolation Forest参数调优
在没有任何欺诈线索的初始阶段,采用相对宽松的超参数设置,使模型具有较高的灵活性:
from sklearn.ensemble import IsolationForest
from sklearn.svm import OneClassSVM
isolation_forest = IsolationForest(
n_estimators=500, # 森林中树的最大数量
contamination="auto", # 初始设置为auto(后续调整)
max_samples='auto',
max_features=1, # 每次分割仅考虑一个特征
bootstrap=True, # 使用bootstrap样本确保鲁棒性
random_state=42,
n_jobs=-1
)
y_pred_iso = isolation_forest.fit_predict(X_processed)
inliers_iso = X[y_pred_iso == 1]
outliers_iso = X[y_pred_iso == -1]
print(f"Isolation Forest detected {len(outliers_iso)} outliers.")One-Class SVM对比实验
为了进行性能比较,同时调优一类支持向量机,设置相对宽松的nu值:
one_class_svm = OneClassSVM(
kernel='rbf',
gamma='scale',
tol=1e-7,
nu=0.1, # 宽松的nu值设置
shrinking=True,
max_iter=5000,
)
y_pred_ocsvm = one_class_svm.fit_predict(X_processed)
inliers_ocsvm = X[y_pred_ocsvm == 1]
outliers_ocsvm = X[y_pred_ocsvm == -1]
print(f"One-Class SVM detected {len(outliers_ocsvm)} outliers.")实验结果分析
实验结果显示:
- Isolation Forest检测到166个异常点
- One-Class SVM检测到101个异常点

图:Isolation Forest(左)和One-Class SVM(右)的无监督异常检测结果对比
Isolation Forest在寻找容易被"隔离"的点方面表现更为积极,擅长发现新颖的、真正异常的点,即使这些点与主要数据簇的距离并不是非常远。如果对"异常"的定义相对宽泛,这种特性可能导致检测到更多的异常点。
One-Class SVM在正常数据周围定义了更加结构化的边界,将边界之外的点标记为异常。这种方法相对保守,需要从"正常"流形更显著的偏差才会被标记为异常。
人工反馈循环评估
为了实际演示评估过程,将标记的记录按照以下四个类别进行逐一审查:
类别1(真正例,TP):模型标记的交易确实是欺诈性的。类别2(假正例,FP):模型标记的交易实际上是合法的,表示"虚假警报"。过多的假正例可能使分析师工作负担过重并导致效率低下。类别3(新欺诈模式):识别出被捕获的新类型欺诈,或以前错过的欺诈类型,为不断演变的威胁态势提供新的洞察。类别4(合法但异常行为):交易看似合法但对该客户或客户群体确实异常,了解模型标记原因具有重要价值。
需要注意的是,假阴性(FN)记录通常来自其他来源,如客户投诉或退单,因为这些交易未被模型标记但后来发现是欺诈性的。在这个实验中,由于重点关注模型标记的准确性,暂时排除了假阴性分析。在实际应用中,欺诈专家对记录进行准确分类至关重要。
以下是一些标记记录的示例和相应的人工审查结果:

图:标记的交易记录列表(合成数据)和人工审查示例
以记录#0为例,77美元的退款虽然不一定可疑或欺诈,但确实代表了该特定客户的异常行为模式。记录#67(底部)同样显示了大量退款行为。如果将此识别为新的欺诈方案,可以将其标记为类别3。
对于记录#23、#25等,客户年龄超过90岁。来自该年龄群体个人的如此高交易量通常是异常的,需要特别关注。
在166个潜在异常中,按类别分布情况为:类别1占94个,类别2占30个,类别3占10个,类别4占23个。
污染度参数调整
基于审查结果的分析显示:总标记数为166个;真正例(TP)为94个;假正例(FP)为72个(166-94);标记集的精确度为TP/(TP+FP) = 94/166 ≈ 56.63%。
这表明虽然模型预测了16.6%的污染率,但该数据集的实际可观察污染率为9.4%(1000个总样本中的94个异常)。同时必须考虑模型在此实验中未标记的假阴性(遗漏的异常),因此真实污染率可能大于等于9.4%。
基于这一发现,在下一次迭代中将contamination参数设置为0.1(10%):
refined_isolation_forest = IsolationForest(
n_estimators=500,
contamination=0.1, # 更新为0.1
max_samples='auto',
max_features=1,
bootstrap=True,
random_state=42,
n_jobs=-1
)训练样本标签更新
另一个重要步骤是基于更新的数据集重新训练主要模型。向原始DataFrame添加三个新列,将human_review类别1标记为is_fraud = true(1):
-
human_review:存储审查类别(0,1,2,3,4),非异常情况为零 -
is_fraud_iforest:存储来自Isolation Forest的初始异常检测结果(二进制:1,-1) -
is_fraud:存储最终欺诈判定结果(二进制:0,1),其中1表示欺诈is_fraud
列作为目标变量用于训练主要模型:
import pandas as pd
df_human_review = pd.read_csv(csv_file_path, index_col=1)
df_merged = df_new.merge(
df_human_review[['human_review']],
left_index=True,
right_index=True,
how='left'
)
df_merged['human_review'] = df_merged['human_review'].fillna(0).astype(int)
df_merged['is_fraud'] = (df_merged['human_review'] == 1).astype(int)图:更新后的数据框,右侧三列为新添加的列
主要模型重新训练
由于数据集存在类别不平衡问题,首先使用SMOTE技术对少数类进行过采样:
from sklearn.model_selection import train_test_split
from imblearn.over_sampling import SMOTE
from collections import Counter
X = df_merged.copy().drop(columns='is_fraud', axis='columns')
y = df_merged.copy()['is_fraud']
X_tv, X_test, y_tv, y_test = train_test_split(X, y, test_size=300, shuffle=True, stratify=y, random_state=12)
X_train, X_val, y_train, y_val = train_test_split(X_tv, y_tv, test_size=300, shuffle=True, stratify=y_tv, random_state=12)
print(Counter(y_train))
smote = SMOTE(sampling_strategy={1: 75}, random_state=42)
X_train, y_train = smote.fit_resample(X_train, y_train)
print(Counter(y_train))输出结果:Counter({0: 370, 1: 30}) → Counter({0: 370, 1: 75})
然后使用更新的训练样本重新训练主要模型(LightGBM)和基线模型:
from sklearn.ensemble import HistGradientBoostingClassifier
from sklearn.linear_model import LogisticRegression
# 主要模型
lgbm = HistGradientBoostingClassifier(
learning_rate=0.05,
max_iter=500,
max_leaf_nodes=20,
max_depth=5,
min_samples_leaf=32,
l2_regularization=1.0,
max_features=0.7,
max_bins=255,
early_stopping=True,
n_iter_no_change=5,
scoring="f1",
validation_fraction=0.2,
tol=1e-5,
random_state=42,
class_weight='balanced'
)
# 基线模型
lr = LogisticRegression(
penalty='l2',
dual=False,
tol=1e-5,
C=1.0,
class_weight='balanced',
random_state=42,
solver="lbfgs",
max_iter=500,
n_jobs=-1,
)性能评估结果
使用训练集、验证集和测试集对主要模型与逻辑回归基线进行评估。为了减少假阴性,将F1分数作为主要评估指标:
- 逻辑回归(L2正则化):训练性能0.9886-0.9790 → 泛化性能0.9719
- LightGBM:训练性能0.9133-0.8873 → 泛化性能0.9040
两个模型都表现出良好的泛化能力,其泛化分数接近训练分数。在这个比较中,带有L2正则化的逻辑回归是性能更优的模型,在训练数据和更重要的未见泛化数据上都达到了更高的准确性。其泛化性能(0.9719)优于LightGBM(0.9040)。
合成异常注入测试
最后,创建50个合成数据点来测试模型的适应性:
from sklearn.metrics import f1_score
num_synthetic_fraud = 50
synthetic_fraud_X = generate_synthetic_fraud(num_synthetic_fraud, X_test, df_merged)
y_pred_test_with_synthetic = pipeline.predict(X_test_with_synthetic)
f1_test_with_synthetic = f1_score(y_test_with_synthetic, y_pred_test_with_synthetic, average='weighted')测试结果表明,LightGBM在检测合成欺诈方面达到了完美的F1分数1.0000,显著优于逻辑回归(F1分数:0.8764,精确度0.90,召回率0.84)。

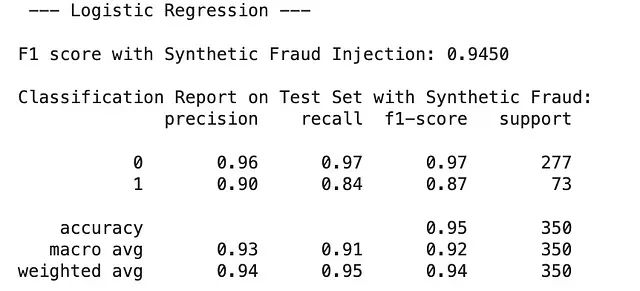
虽然LightGBM完美识别了注入的欺诈案例,但在当前阶段,带有L2正则化的逻辑回归可能为欺诈分类提供更好的整体平衡性能。
总结
本研究通过实验演示了异常标记如何逐步完善异常检测方案和主要分类模型在欺诈检测中的应用。实验结果表明,Isolation Forest作为一个强大的异常检测模型,无需显式建模正常模式即可有效工作,在处理未见风险事件方面具有显著优势。
研究发现,通过人工反馈循环可以有效提升模型性能,将无监督异常检测的结果转化为有价值的训练数据。这种方法特别适用于缺乏历史标记数据但需要快速响应新兴威胁的场景。
对于实际应用而言,自动化人工审查系统和开发创建欺诈交易规则的结构化方法将是对所提出方法的关键增强。未来的研究方向可以包括:建立更加智能化的人工反馈收集机制;开发自适应的阈值调整算法;集成多种异常检测算法以提高检测精度;构建实时异常检测系统以应对动态变化的威胁环境。
https://avoid.overfit.cn/post/dd2a70afff95402284c02d8c6237cce5
作者:Kuriko IWAI