华为云Flexus+DeepSeek征文|基于Dify构建智能票据信息识别助手
- 一、构建智能票据信息识别助手前言
- 二、构建智能票据信息识别助手环境
-
- [2.1 基于FlexusX实例的Dify平台](#2.1 基于FlexusX实例的Dify平台)
- [2.2 基于MaaS的模型API商用服务](#2.2 基于MaaS的模型API商用服务)
- 三、构建智能票据信息识别助手实战
-
- [3.1 配置Dify环境](#3.1 配置Dify环境)
- [3.2 配置Dify工具](#3.2 配置Dify工具)
- [3.3 创建智能票据信息识别助手](#3.3 创建智能票据信息识别助手)
- [3.4 使用智能票据信息识别助手](#3.4 使用智能票据信息识别助手)
- 四、总结
一、构建智能票据信息识别助手前言
在数字化转型的时代背景下,传统票据处理面临效率低下、易出错等痛点。基于Dify平台搭建的智能票据助手,通过AI实现多类型票据自动分类、关键信息精准提取及结构化归档,有效解决财务流程中的核心效率瓶颈。该方案显著提升数据处理准确性90%以上,降低人工成本70%,为企业财务自动化提供关键支撑。
华为FlexusX云服务器搭载昇腾芯片,提供强大异构算力与万级并发支撑;结合MaaS(Model-as-a-Service)平台,实现国产大模型的一站式部署、微调和推理加速,显著降低AI应用门槛。该组合可节省50%推理成本,提升3倍模型加载效率,为政务、金融等高安全场景提供全栈自主可控的AI基础设施保障。
二、构建智能票据信息识别助手环境
2.1 基于FlexusX实例的Dify平台
华为云FlexusX实例提供高性价比的云服务器,按需选择资源规格、支持自动扩展,减少资源闲置,优化成本投入,并且首创大模型QoS保障,智能全域调度,算力分配长稳态运行,一直加速一直快,用于搭建Dify-LLM应用开发平台。
Dify是一个能力丰富的开源AI应用开发平台,为大型语言模型(LLM)应用的开发而设计。它巧妙地结合了后端即服务(Backend as Service)和LLMOps的理念,提供了一套易用的界面和API,加速了开发者构建可扩展的生成式AI应用的过程。
参考:华为云Flexus+DeepSeek征文 | 基于FlexusX单机一键部署社区版Dify-LLM应用开发平台教程
2.2 基于MaaS的模型API商用服务
MaaS预置服务的商用服务为企业用户提供高性能、高可用的推理API服务,支持按Token用量计费的模式。该服务适用于需要商用级稳定性、更高调用频次和专业支持的场景。
参考:华为云Flexus+DeepSeek征文 | 基于ModelArts Studio开通和使用DeepSeek-V3/R1商用服务教程
三、构建智能票据信息识别助手实战
3.1 配置Dify环境
输入管理员的邮箱和密码,登录基于FlexusX部署好的Dify网站
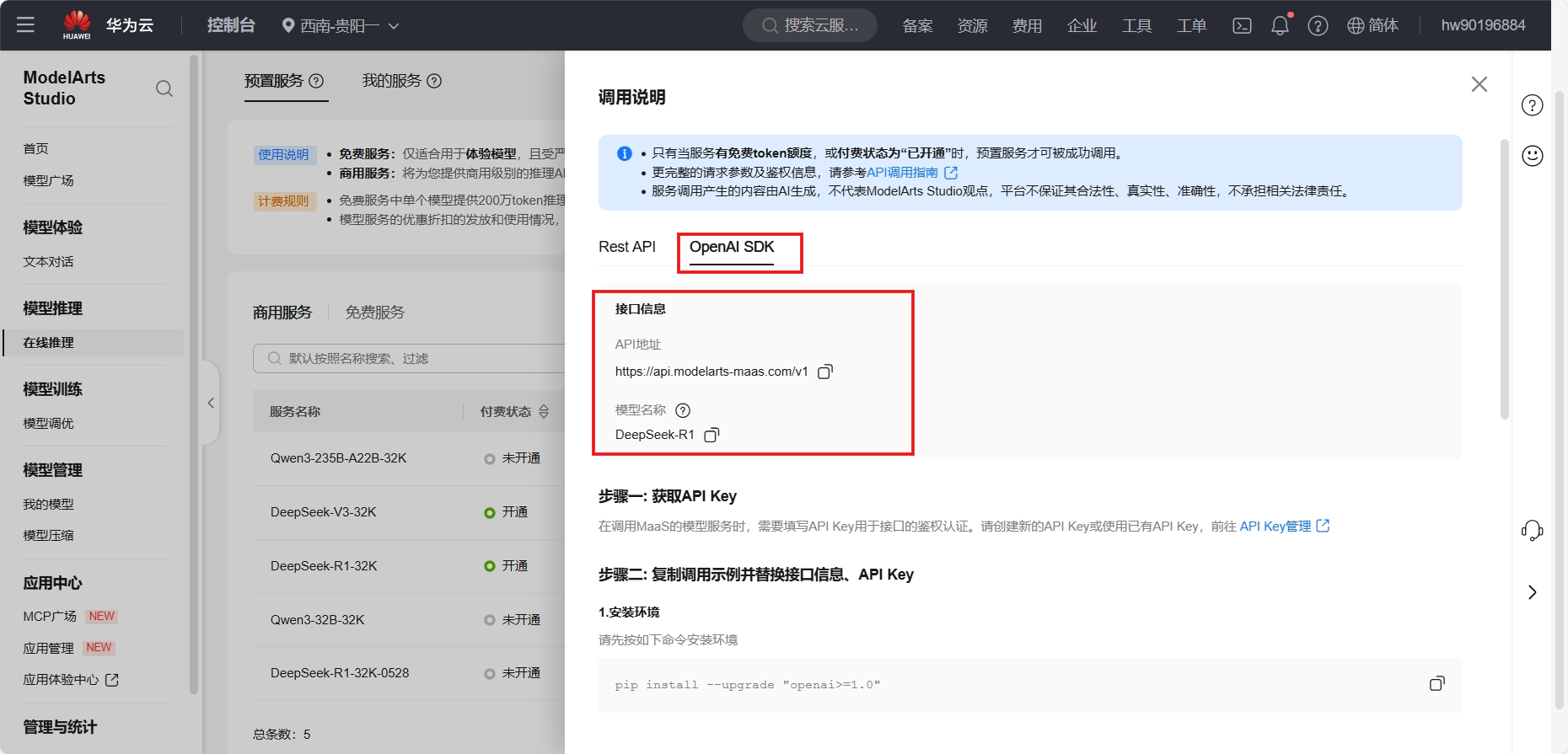
将MaaS平台的模型服务接入Dify,这里我们选择的是DeepSeek R1商用服务,需要记住调用说明中的接口信息和 API Key 管理中API Key,若没有可以重新创建即可
配置Dify模型供应商:设置 - 模型供应商 - 找到OpenAI-API-compatible供应商并单击添加模型,在添加 OpenAI-API-compatible对话框,配置相关参数,然后单击保存
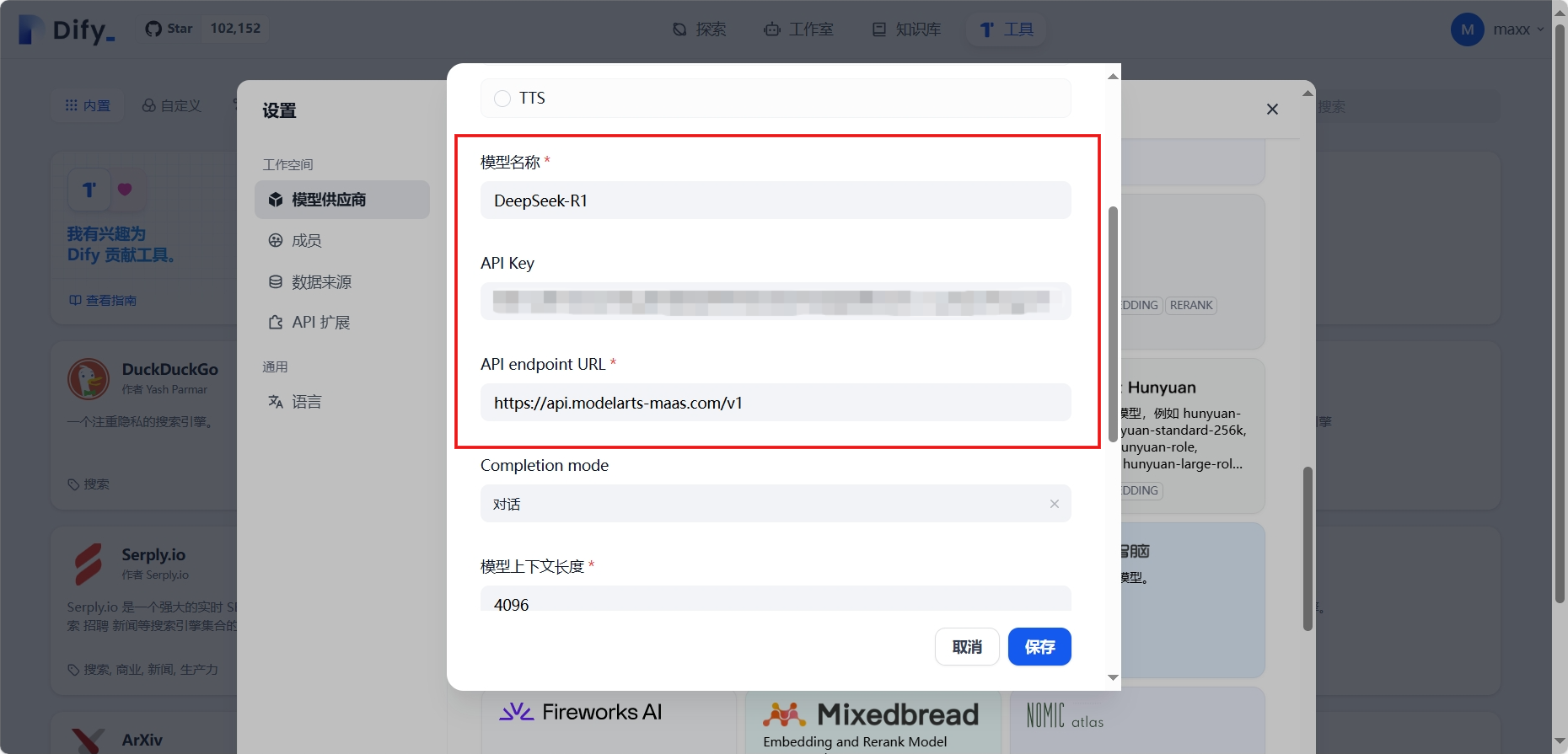
| 参数 | 说明 |
|---|---|
| 模型类型 | 选择LLM。 |
| 模型名称 | 填入模型名称。 |
| API Key | 填入创建的API Key。 |
| API Endpoint URL | 填入获取的MaaS服务的基础API地址,需要去掉地址尾部的"/chat/completions"后填入 |
3.2 配置Dify工具
通义千问
同义 Qwen 由阿里云开发,是一系列复杂的 LLM。它包括多个变体,例如用于文本处理的 Qwen、用于视觉语言任务的 Qwen-VL 和用于音频理解的 Qwen-Audio。这些模型以其令人印象深刻的规模而著称,旗舰 Qwen-72B 模型具有 720 亿个参数,并在超过 3 万亿个代币上进行了训练。
根据多个实战案例的测试结果,Qwen/Qwen2-VL-72B-Instruct模型在中文票据识别任务中表现最佳。该模型特点:
- 强大的视觉理解能力
- 对中文票据格式有良好适配性
- 支持结构化输出
打开设置 - 模型供应商 - 安装模型供应商,选择通义千问,进行安装

安装完成后,您需要从 阿里云 获取 API 密钥

并在 设置 -> Model Provider 中添加通义千问 API Key

刷新页面后就可以查看到 qwen2.5-vl-72b-instruct 状态已开启

3.3 创建智能票据信息识别助手
在 Dify - 工作室,创建空白应用,选择工作流,输入应用名称和图标,点击创建

删除其他默认节点,在开始节点添加一个文件类型(单文件)的输入变量,命名为 ticket_file,并设置为必填项,用于用户上传票据的图片文件

添加LLM节点,命名初步分类器,用于初步类型判断

模型: 选择配置的 qwen2.5-vl-72b-instruct 模型,它具备强大视觉理解能力。
提示词: 精心设计提示词,指令模型进行大类判断,并强制按指定格式输出。
bash
#角色:你是一个票据识别小助理,请识别票据类型。
请分析用户上传的文件。
判断该文件主要内容属于以下哪类:
-增值税发票
-普通发票
-定额发票
-出租车发票
-火车票
- 其他或无法判断
请严格按照以下格式仅返回一个词:
如果是增值税发票返回:Valueadded_invoice
如果是普通发票返回: Common_invoice
如果是定额发票返回: Quota_invoice
如果是出租车发票返回:Taxi_invoice
如果是火车票返回: Train_ticket
如果是其他或无法判断,返回: 未知发票类型,请重新上传。
#票据特征:
1. 增值税发票 (VAT Invoice)
整体布局与尺寸:
通常为横向矩形,尺寸相对较大且标准化(尤其是纸质票)。
分为增值税专用发票和增值税普通发票(包括电子普票),布局相似但有细微差别。
版面结构清晰,包含购买方、销售方信息区、货物或应税劳务/服务清单区、金额/税额/价税合计区等。表格化特征明显。
关键文字标识:
顶部显著位置有大字标题:"增值税专用发票"或"增值税普通发票"或"增值税电子普通发票"。
右上角通常有"发票代码"(10位或12位数字)和"发票号码"(8位数字)。
包含"购买方"、"销售方"、"货物或应税劳务、服务名称"、"规格型号"、"单位"、"数量"、"单价"、"金额"、"税率"、"税额"、"价税合计"等固定字段名称。
金额通常有大写(汉字数字)和小写(阿拉伯数字)两种形式。
独特视觉元素:
发票专用章: 通常在右下角或中间靠右位置,为红色椭圆形或圆形印章,包含纳税人名称和税号。这是非常关键的特征。
二维码: 电子发票和部分新版纸质发票左上角或特定区域有二维码,用于查验。
密码区: 专用发票通常有密码区(一串加密字符),普通发票没有。
背景/底纹: 纸质发票常有特定的浅色底纹或防伪图案(如"SW"字母暗纹等)。电子发票通常是白色背景的PDF样式。
颜色: 纸质发票的底纹可能有浅蓝、浅粉等,印章固定为红色。电子发票主要是黑白文字加红色电子签章。
2. 普通发票 (General Invoice - 非增值税类)
整体布局与尺寸:
种类繁多,尺寸和布局差异性很大,取决于行业和地区(如:通用机打发票、通用手工发票、行业性发票如门票、过路费发票等)。
可能是横向或纵向。
结构相对增值税发票可能更简单,不一定有严格的表格。
关键文字标识:
顶部通常有"XX省/市 通用机打发票"、"XX(行业)发票"等字样。
同样有"发票代码"和"发票号码",通常在右上角或左上角。
包含付款方/购买方、收款方/销售方、项目名称、金额等基本信息。
金额通常有大写和小写。
独特视觉元素:
发票监制章: 通常在发票上方或特定位置,为椭圆形红色印章,标明"全国统一发票监制章"或"XX省/市 税务局监制"字样。
发票专用章: 收款单位加盖的红色印章,形状和位置不如增值税发票规范,但也是重要特征。
二维码: 部分新版机打普票也可能带有二维码。
防伪特征: 可能有特定底纹、防伪线等,但种类繁多。
颜色: 底色、印刷颜色多样,监制章和专用章为红色。
3. 定额发票 (Quota Invoice / Fixed-Amount Invoice)
整体布局与尺寸:
通常尺寸较小,形状多为长方形,横向或纵向都有。
版面设计极其简单。
经常是从一本票本上撕下来的,可能有撕票线/齿孔的痕迹。
关键文字标识:
最显著的特征是票面上印有固定面额的大写汉字数字(如:壹圆、伍圆、拾圆、贰拾圆、伍拾圆、壹佰圆等),通常字体很大。
可能包含"定额发票"字样。
有"发票代码"和"发票号码"(通常是连续印刷的号码)。
可能包含收款单位名称或印章。
独特视觉元素:
固定面额: 这是最核心的识别特征。
发票监制章: 通常较小,红色椭圆形。
收款单位印章或预印名称: 表明开票方。
序列号: 发票号码通常是流水号。
颜色: 不同面额的发票可能使用不同的颜色作为区分(类似纸币),例如10元是蓝色,50元是绿色等(具体颜色依地区和版本而定)。
4. 出租车发票 (Taxi Invoice)
整体布局与尺寸:
典型的窄长条形,横向打印。
通常是卷式机打发票,纸质较薄,多为热敏纸。
关键文字标识:
顶部通常有"XX市 出租汽车专用发票"或类似名称。
有"发票代码"和"发票号码"。
包含"日期"、"时间"(上车/下车时间)、"车号"、"单价"、"里程"、"等候时间"、"金额"等出租车行业特有的字段。
打印字体通常是点阵字体或热敏打印字体。
独特视觉元素:
卷票特征: 可能有打印偏移、字体间距不均等情况。热敏纸易变色或有划痕。
发票监制章: 通常是预印在卷筒纸上的,颜色可能是蓝色、黑色或红色。
无单独加盖的收款章: 一般只有预印的公司信息或Logo。
条形码/二维码: 部分地区出租车发票可能有。
颜色: 底纸通常是白色,预印文字/图案/监制章可能是蓝色、黑色或红色。打印内容为黑色。
5. 火车票 (Train Ticket)
整体布局与尺寸:
标准化的卡片式矩形。
主要有两种版式:
蓝色磁介质票: 较早版本,蓝色底纹。
红色/粉色纸质票: 新版,类似银行卡的稍厚纸质,粉红色底纹。
布局固定,信息区域划分清晰。
关键文字标识:
顶部有"中国铁路"字样和Logo。
包含"出发站"、"到达站"(字体较大)、"车次"、"日期"、"时间"、"座位号/铺位号"、"票价"(¥符号)、"姓名"、"身份证号码"(部分数字用*隐藏)。
底部有一串票号。
独特视觉元素:
底纹/颜色: 蓝色或粉红色是关键视觉区分。新版票有复杂防伪底纹。
二维码: 新版火车票右下角有二维码,包含加密信息。
序列号/票号: 底部或顶部的唯一编号。
特定字体: 使用铁路系统特定的字体。
磁条(背面): 蓝色车票背面有磁条(图像中不可见,但影响票的厚度和质感)。
颜色: 主色调为蓝色或粉红色,文字为黑色。打开视觉 开关,并选择参数为开始节点的 ticket_file,这步的输出结果为一下6种可能:
如果是增值税发票返回:
Valueadded_invoice如果是普通发票返回:
Common_invoice如果是定额发票返回:
Quota_invoice如果是出租车发票返回:
Taxi_invoice如果是火车票返回:
Train_ticket如果是其他或无法判断,返回:
未知发票类型,请重新上传。

添加条件节点,将初步分类器输出的票据类型输入进行判断,根据发票的类型再分别解析数据信息

依次为每种最终确定的票据类型(增值税发票、普通发票、出租车发票、火车票)分别创建一个 LLM 节点,用于信息提取。若是未知,则直接结束节点输出内容即可

若是增值税发票,模型默认qwen2.5-vl-72b-instruct,开启视觉,添加参数为开始节点的 ticket_file ,此时关键的就是系统提示词,需要提取关键数据
为每个提取器节点设计高度定制化的提示词,明确告知模型正在处理的票据类型,列出需要提取的所有关键字段,并强制要求以包含处理状态(status)和错误信息(error_message)及置信区间的 JSON 格式输出。
bash
作为智能票据识别系统,请严格按以下要求处理增值税发票图像:
**识别字段清单**
1. 必填核心字段:
- 发票代码(invoice_code)
- 发票号码(invoice_number)
- 开票日期(issue_date)(YYYY-MM-DD格式)
- 校验码最后6位(check_code)
- 购买方名称(buyer_name)及税号(buyer_tax_id)
- 销售方名称(seller_name)及税号(seller_tax_id)
- 价税合计(大写/小写)
- 金额合计(不含税)
- 税额合计
2. 货物明细字段(可选):
- 货物名称、规格型号、单位、数量
- 单价、金额、税率、税额
**置信度评估体系**
1. 字段级置信度(0-100):
▫ 90-100:OCR识别准确且通过逻辑校验(如日期格式、税号规则)
▫ 70-89:OCR识别清晰但逻辑校验未完全通过
▫ 50-69:OCR识别结果模糊但可辨认
▫ 30-49:字段位置匹配但内容存疑
▫ 0-29:未能有效识别
2. 整体置信度(confidence_score):
- 核心字段置信度的加权平均值(发票代码/号码/金额合计权重30%,其他字段10%)
- <60分触发复核机制
**数据校验规则**
1. 必填字段任一置信度<70 → status=error
2. 价税合计大写与小写金额不符 → status=error
3. 合计金额*(1+税率)≠价税合计 → status=error
4. 货物明细存在但缺少必要字段 → 清空items
**输出规范**
{
"prompt": """
**输出规范(优化版)**
```json
{
"status": "success|error",
"data": {
"confidence_score": 0-100, 🌟 整体置信区间
"core_fields": { 🌟 必填字段强化
"invoice_code": "str",
"invoice_number": "str",
"issue_date": "YYYY-MM-DD",
"check_code": "str",
"buyer_info": {
"name": "str",
"tax_id": "str"
},
"seller_info": {
"name": "str",
"tax_id": "str"
},
"total_amounts": {
"tax_included_upper": "str",
"tax_included_lower": "float",
"amount_without_tax": "float",
"tax_amount": "float"
}
},
"items": [] || null
},
"error_message": "string" || null
}
若是普通发票,提示词参考如下
bash
作为财税票据智能处理引擎,请按以下规则精确处理普通发票影像:
**字段识别规范**
1. 必填核心字段:
- 发票代码(invoice_code)[12位数字]
- 发票号码(invoice_number)
- 机打号码(machine_print_number)
- 机器编号(machine_id)
- 销售方信息(seller_info): {
"name": "销售方名称",
"tax_id": "纳税人识别号"
}
- 购买方信息(buyer_info): {
"name": "购买方名称",
"tax_id": "纳税人识别号"
}
- 开票日期(issue_date)[ISO 8601格式]
- 收款员(cashier)
- 金额合计(total_amount): {
"upper_case": "大写金额",
"lower_case": 小写数值
}
- 校验码(check_code)
2. 明细字段:
- 项目(items)[数组结构]: {
"name": "商品/服务名称",
"unit_price": 单价,
"quantity": 数量,
"amount": 金额
}
**置信度评估机制**
| 置信区间 | 判定标准 | 处理措施 |
|----------|-------------------------------------|-------------------|
| 90-100 | OCR识别准确且通过格式校验 | 直接入库 |
| 70-89 | OCR识别清晰但部分字段格式存疑 | 标记可自动修正 |
| 50-69 | 关键字段模糊但可推测 | 需人工复核 |
| 0-49 | 关键字段识别失败 | 拒绝处理 |
**数据校验规则**
1. 核心字段置信度<70 → status=error
2. 大小写金额差异>0.01 → status=error
3. 票据日期早于2017-01-01 → 强制人工复核
4. 商品明细存在但缺少必要字段 → 清空items数组
**输出结构**
```json
{
"status": "success|error",
"data": {
"confidence_score": 0-100,
"core_fields": {
"invoice_code": {"value": "044002000111", "confidence": 95},
"invoice_number": {"value": "02568336", "confidence": 92},
"machine_print_number": {"value": "GD20230715001", "confidence": 88},
"machine_id": {"value": "A1B2C3D4", "confidence": 85},
"seller_info": {
"name": {"value": "XX商贸有限公司", "confidence": 90},
"tax_id": {"value": "91440101MA5CXXXXXX", "confidence": 93}
},
"issue_date": {"value": "2023-07-15", "confidence": 95},
"check_code": {"value": "ABCD1234", "confidence": 82}
},
"transaction_details": {
"total_amount": {
"upper_case": {"value": "伍仟叁佰元整", "confidence": 88},
"lower_case": {"value": 5300.00, "confidence": 90}
},
"items": [
{
"name": {"value": "办公桌椅", "confidence": 85},
"unit_price": {"value": 1200.00, "confidence": 88},
"quantity": {"value": 4, "confidence": 90},
"amount": {"value": 4800.00,
若是定额发票,提示词参考如下
bash
{
"prompt": """
作为定额发票智能识别引擎,请严格遵循以下处理规范:
**核心识别要素**
1. 必填字段(置信度阈值75):
- 发票代码(invoice_code)[12位数字]
- 发票号码(invoice_number)[8位连续数字]
- 票面金额(amount){
"fixed_value": "定额数值(如伍元/拾元整)",
"machine_print": "打印金额(¥X.00)"
}
2. 辅助验证字段:
- 发票监制章(stamp)[省税务局字样]
- 发票版本号(version_code)[票面底部编码]
**置信度矩阵**
| 置信区间 | 判别标准 | 处理策略 |
|----------|-------------------------|-----------------------|
| 90-100 | 票面完整&格式合规 | 自动归档 |
| 75-89 | 关键字段需二次校验 | 触发防伪校验API |
| 50-74 | 存在局部缺损/污染 | 启动图像增强流程 |
| 0-49 | 无法识别有效票据要素 | 拒绝处理 |
**智能校验体系**
1. 双重金额验证:
▫️ 定额文字与打印金额逻辑匹配(如"伍元整"对应¥5.00)
▫️ 金额数值应符合定额发票标准面值(1/5/10/20/50/100元)
2. 代码规则校验:
```regex
/^[0-9]{12}$/ //发票代码正则
/^[0-9]{8}$/ //发票号码正则
**输出结构**
{
"status": "valid|invalid",
"certification": {
"confidence_level": 88,
"core_data": {
"invoice_code": {
"value": "144031900111",
"confidence": 92,
"validation": "格式校验通过"
},
"invoice_number": {
"value": "02568336",
"confidence": 85,
"warning": ["号码边框缺损"]
},
"amount_info": {
"fixed_value": {"text": "拾元整", "confidence": 90},
"machine_print": {"value": 10.00, "confidence": 88},
"consistency_check": "通过"
}
}
},
"security_features": {
"ink_verification": "温变特征有效",
"microtext_status": "缩微文字识别成功"
}
}
若是出租车发票,提示词参考如下
bash
作为出租车发票智能识别系统,请严格按以下要求执行:
**结构化字段要求**
1. 必填核心字段:
- 发票代码(invoice_code)
- 发票号码(invoice_number)
- 运营单位(company)
- 车号(vehicle_number)
- 工号(driver_id)
- 日期(date)(YYYY-MM-DD)
- 时间(time)(HH:MM)
- 单价(元/公里)(unit_price)
- 里程(mileage)
- 等候时间(waiting_time)
- 总金额(total_amount)
**置信度计算规则**
采用字段级数值加权计算:
⎔ 发票代码/号码/总金额(权重30%)
⎔ 日期/时间/里程(权重20%)
⎔ 其他字段(权重10%)
█ 总置信度<60时自动触发人工复核
**多维校验规则**
1. 硬性校验(触发error):
- 总金额 ≠ 起步价 + 单价×里程 + 等候费×时长
- 时间格式异常(如'14点30分'→应转换HH:MM)
- 车牌号缺失地区代码(如'沪A12345'→补全省份前缀)
2. 智能修正:
▫️ 日期分离:识别到文本'2023年12月05日'转换为2023-12-05
▫️ 时间格式:1430 → 14:30
▫️ 金额补位:识别到"廿五元"自动转换25.00元
**结构化输出要求**
必须输出严格JSON格式:
{
"status": "success",
"data": {
"confidence_score": 82,
"core_fields": {
"invoice_code": "144231999111",
"invoice_number": "02471572",
"issue_date": "2023-08-16",
"check_code": "6B63E5D89",
"buyer_info": {
"name": "上海智明科技有限公司",
"tax_id": "91310115MA7ADYXW2R"
},
"seller_info": {
"name": "上海申信出租车有限公司",
"tax_id": "91310116MA7ADYX456"
},
"total_amounts": {
"tax_included_upper": "壹佰玖拾捌元整",
"tax_included_lower": 198.00,
"amount_without_tax": 175.22,
"tax_amount": 22.78
}
},
"items": null
},
"error_message": null
}
若是火车发票,提示词参考如下
bash
作为火车票智能识别系统,请严格按以下规范执行:\n\n**结构化字段要求**\n1. 必填核心字段:\n - 始发站(departure_station)\n - 终点站(arrival_station)\n - 车次(train_number)\n - 出发时间(departure_time)(YYYY-MM-DD HH:mm)\n - 票价(ticket_price)\n - 身份证号(id_number)\n - 姓名(passenger_name)\n - 座位号(seat_number)\n - 席别(seat_class)\n\n**置信度计算规则**\n采用多维加权算法:\n⎔ 车次/身份证号/票价(权重35%)\n⎔ 出发时间/车站信息(权重30%)\n⎔ 其他字段(权重15%)\n█ 总置信度<60时自动标记异常票据\n\n**多维校验规则**\n1. 硬性校验(触发error):\n - 车次格式不符合「字母+数字」编码规则(如G123/A25)\n - 身份证号码不符合GB11643-1999标准\n - 出发时间无法转换为有效时间戳\n\n2. 智能修正:\n ▫️ 时间标准化:识别到「2024年3月15日08:15」→2024-03-15 08:15\n ▫️ 金额转换:「伍佰伍拾叁元」→553.00\n ▫️ 车站补全:「北京南」→「北京南站」\n\n**异常处理示例**\n```json\n{\n \"status\": \"error\",\n \"data\": {\n \"confidence_score\": 48,\n \"core_fields\": {\n \"车次\": \"Z5X\",\n \"身份证号\": \"31010519901301123\"\n }\n },\n \"error_message\": \"车次编码异常|身份证校验位缺失\"\n}\n```\n\n**扩展能力**\n▨ 支持电子客票二维码二值化解析\n▨ 自动识别红票/蓝票/电子票版本差异"
输出规范:
{
"status": "error",
"data": {
"confidence_score": 52,
"core_fields": {
"始发站": "北京南站",
"终点站": "上海虹桥站",
"车次": "G12X", // 非法车次编码
"出发时间": "2024-13-32 25:61", // 非法时间格式
"票价": 0.0,
"身份证号": "31010519900101123", // 缺校验位
"姓名": "张"
}
},
"error_message": "车次编码校验失败|身份证校验位缺失|出发时间格式异常"
}
最后配置"结束"节点,定义最终输出变量,目标是形成一个包含所有必要信息(识别出的类型、提取数据或错误信息)的统一结构

测试工作流,可以使用大量、多样化的真实票据样本进行测试,或者百度下载相关类的票据进行测试

上传一张火车票点击开始运行

先输出火车票类型

再输出完整的票据信息,如出发站、到达站、火车编号等信息,识别准确,提取的信息也很全面

再测试一张定额发票,只要类型输出,没有具体信息输出,查看运行详情显示模型输出内容为空,所以还是有待优化提示词的。
json
{
"text": null
}
测试完成就可以发布更新到探索页面了,发布后选择运行就可以获得一个在线运行的工作流的网页!
3.4 使用智能票据信息识别助手
在探索 - 智能票据信息识别助手中开启新对话

上传一张增值税发票,点击运行,能够很快输出票据类型 Valueadded_invoice

接着又完整输出票据信息,识别可靠性比较高

可以参考增值税发票的原图和输出的数据对比下

json
{
"status": "success",
"data": {
"confidence_score": 92,
"core_fields": {
"invoice_code": "012002000511",
"invoice_number": "48576409",
"issue_date": "2021-06-05",
"check_code": "45091",
"buyer_info": {
"name": "陕西能源电力运营有限公司",
"tax_id": "91610132MA6UQ1KA9H"
},
"seller_info": {
"name": "去哪儿网(天津)国际旅行社有限公司",
"tax_id": "91120222300429132L"
},
"total_amounts": {
"tax_included_upper": "柒佰贰拾叁圆整",
"tax_included_lower": 723.00,
"amount_without_tax": 682.08,
"tax_amount": 40.92
}
},
"items": [
{
"name": "经济代理服务*机票款",
"specification": "",
"unit": "次",
"quantity": 1,
"unit_price": 599.05660377,
"amount": 599.06,
"rate": 6,
"tax": 35.94
},
{
"name": "经济代理服务*代理服务费",
"specification": "",
"unit": "次",
"quantity": 1,
"unit_price": 83.01886792,
"amount": 83.02,
"rate": 6,
"tax": 4.98
}
]
},
"error_message": null
}再输出一张无关发票的图片,一张报纸图片,能够排除无关票据,并输出·未知发票类型,请重新上传。

四、总结
基于Dify+DeepSeek搭建股票分析Agent的实践,深刻体会到低代码平台与大模型结合的高效性:通过可视化工作流编排和提示词工程,快速整合实时行情、技术指标与财务数据,实现自然语言交互式分析。DeepSeek-R1的推理能力与Dify的工具调用机制完美协同,将专业金融分析转化为普惠工具,显著降低散户使用门槛。过程中需注意数据源稳定性与模型幻觉风险,但整体验证了AI Agent在垂直领域的落地潜力。
Flexus云服务器X实例采用了柔性算力进行性能QoS保障,可以在绝大多数时间提供接近独享实例的性能QoS保障,但在极少时间内仍然存在性能波动的可能,为了满足对业务性能稳定性要求苛刻的场景需要,Flexus云服务器X实例推出了性能模式。开启性能模式后,Flexus云服务器X实例采取底层物理绑核技术,提供极致稳定的QoS保障能力,您可以获得非常稳定的性能保障。