封面是我用大模型产生的,我觉得读源码就像是我拿着放大镜在看猫爪,Tomcat就是那只猫
前言
这篇文章是从《从阻塞IO到虚拟线程:Java并发模型演进之路(一)走向虚拟线程》中摘出来的,在探究虚拟线程的时候, 阅读Tomcat源码的过程中,自己突然想到的问题,也就是Tomcat是如何合并报文的。 客户端发送的报文可能被拆分分批次到,就像是快递一样,网购的包裹可能分批到,也可能是你再拆第第一个快递的时候,第二个快递到了。

Tomcat处理请求的
- Acceptor线程负责监听连接,连接建立之后将拿到的Socket注册到Poller线程
- Poller线程监听该Socket上面的读事件, 读事件出现之后,将对应的Socket转交给Worker线程池
- Worker线程池负责读数据,解析报文,完整的报文就执行Servlet逻辑,返回响应。

我好奇的也就是Tomcat是如何合并报文的,假设客户端发送了10KB报文,这个报文被分批到达,分批到达也有两种情况:
- Worker解析第一个4KB报文完毕,第二个6KB报文到达。
- Worker解析第一个4KB报文没解析完,第二个6KB就到达了。
针对第一种问题,我们可以给出解决方案是Worker线程在没有解析到完整报文的时候,陷入Waiting状态,Poller做一个Map,key是Socket,Value是线程ID引用。第二个报文到达的时候,根据Socket找到对应的线程ID引用,然后唤醒线程。这种方案倒是挺直接,但是Worker线程就等在这里了,不利于吞吐量的提升。尽管Tomcat的线程池被改造过,和JDK原生的线程池不同,Tomcat的线程池接到任务的时候,判断线程数是否超过最大线程数,超过了就入队,没超过就创建线程执行任务。但我们让线程等待在这里也没发挥出来NIO的优势,像是用NIO写BIO编程。
所以一个良好的方式是Worker线程解析完报文之后将报文缓存起来,然后第二个报文到来的时候,合并报文判断是否报文接收完毕,接收完毕就执行Servlet逻辑。还有报文没接收到,就接着缓存。但是Worker线程不阻塞,读完数据缓存完毕就当作任务完成,接着回线程池执行任务。事实上Tomcat采用的就是这种方案来解析数据的。
那第二种情况该怎么处理呢,大家操作缓冲区的时候该如何避免数据被覆盖呢,也就是说6KB报文覆盖了4KB报文的位置:

那该怎么办呢? 其实这里直接的方法就是上锁,在写数据的时候,由于第一个数据包先到,先持有锁,写完缓冲区,再轮到第二个线程去写缓冲区。事实上SocketChanne的read方法的时候也已经上了锁。但是我还有问题,假设第一个报文和第二个报文相错很短的时候到达Tomcat,第一个报文可能某种原因还没开始读,还没来得及上锁,第二个报文已经被扔到了Worker线程池开始读了,这样会不会也造成数据错乱问题。带着这些问题,让我们走进Tomcat的源码,
报文分批到达如何解决
有时候看源码的时候就想破案,源码里面扑朔迷离,我们需要不断的观察源码,然后大胆猜想,小心验证。同破案不同的在于,我们可以通过IDE来不断的来观测Tomcat解析报文的流程,我们可以通过程序来模拟发送两批报文的流程。不断的观察,不断的验证,这样就能得到我们想要的答案。为了模拟这种报文先后到达,我们首先写一个客户端的程序,然后观察Tomcat是如何缓存数据的。
java
String host = "localhost";
int port = 8080;
// 1. 手动拼接HTTP GET请求
// 第一部分:请求行
String requestLine = "GET /test HTTP/1.1\r\n";
// 第二部分:请求头。注意最后的 \r\n\r\n 是必需的,它标志着请求头的结束。
String requestHeaders = "Host: " + host + ":" + port + "\r\n" +
"Connection: close\r\n" +
"\r\n"; // 关键的空行,表示Header结束
byte[] part1 = requestLine.getBytes(StandardCharsets.UTF_8);
byte[] part2 = requestHeaders.getBytes(StandardCharsets.UTF_8);
try (Socket socket = new Socket(host, port)) {
System.out.println("已连接到服务器 " + host + ":" + port);
OutputStream out = socket.getOutputStream();
InputStream in = socket.getInputStream();
// 2. 发送第一部分 (请求行)
System.out.println("正在发送第一部分 (请求行)...");
out.write(part1);
out.flush(); // 强制刷新
System.out.println("第一部分已发送。"); // 语句一
// 3. 等待一段时间
System.out.println("等待1秒...");
// 4. 发送第二部分 (请求头)
System.out.println("正在发送第二部分 (请求头)...");
out.write(part2);
out.flush(); // 再次刷新
System.out.println("第二部分已发送。"); // 语句二
// 5. 读取并打印服务器响应
System.out.println("\n--- 服务器响应 ---");
byte[] buffer = new byte[1024];
int bytesRead;
while ((bytesRead = in.read(buffer)) != -1) {
System.out.print(new String(buffer, 0, bytesRead, StandardCharsets.UTF_8));
}
System.out.println("\n--- 响应结束 ---");
} catch (Exception e) {
e.printStackTrace();
}我们可以将断点打在语句一,然后观察服务端看数据被缓存到了哪里,Tomcat的源码跳来跳去的,但我们其实想想不管你怎么跳,都得调SocketChannel的read方法,如果不知道是哪个read方法,那两个方法就都打上:
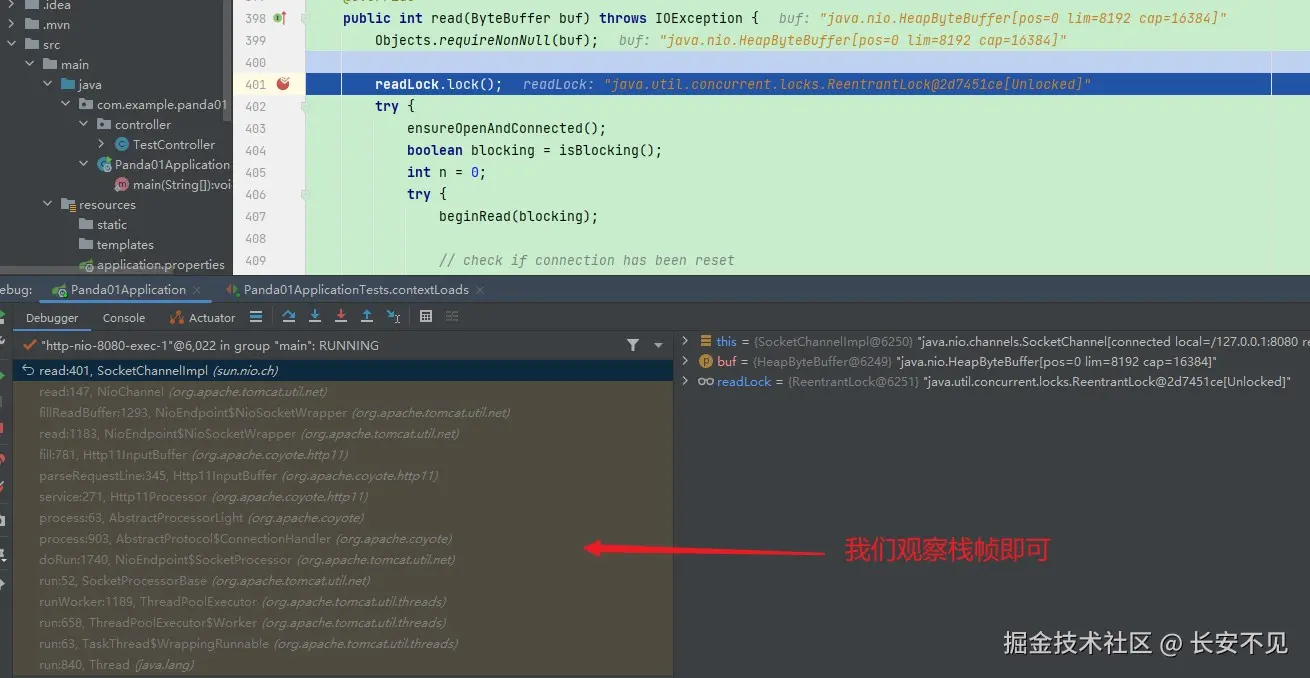
我们沿着这个栈往上追就会发现这个传入的ByteBuffer来自于Http11InputBuffer的成员变量,我们在构造函数里面看看这个Http11InputBuffer是如何被初始化的,直接在构造函数里面打断点即可:

顺着调用链可以看到Http11InputBuffer在Http11Processor的构造函数里面被初始化:

注意到上面截图中的代码:
java
Processor processor = (Processor) wrapper.takeCurrentProcessor();注意这里的takeCurrentProcessor方法在9.0的时候事实上还只是简单的set, 我观察到在10.1.39之后就改用原子变量了,我们不必关注这个问题。
这个wrapper变量事实上来自于AbstractProtocol的内部类ConnectionHandler的process方法:
java
public SocketState process(SocketWrapperBase<S> wrapper, SocketEvent status) 有take的地方,就有set的地方,我们可以看到下面将wrapper中塞入这个处理器的代码:
java
if (processor != null) {
wrapper.setCurrentProcessor(processor);
}那么现在的引用链就是SocketWrapper 引用 Processor,Processor引用Http11InputBuffer:

但这里有个问题在于,我观察到Processor,也就是Http11Processor只初始化一次,那假设A连接的报文没接收完,B连接的报文先进来处理了,这里A连接的报文被覆盖掉怎么办? 后面我的观察下,这其实是针对一个连接的Processor是相同的,但是不同的连接Processor不同。到现在我们回答了一个问题, 即TCP的报文分批到达,第一次到达解析完毕,第二次才到达。
报文分批到达但是相错时间非常短
那么如果是一次还在解析中,第二次就到达了怎么办,因为有共享的变量Processor,这里就会有安全的问题。一般来说我们解决并发问题也就是上锁和CAS,Tomcat的选择是加锁:
java
public abstract class SocketProcessorBase<S> implements Runnable {
protected SocketWrapperBase<S> socketWrapper;
protected SocketEvent event;
public SocketProcessorBase(SocketWrapperBase<S> socketWrapper, SocketEvent event) {
reset(socketWrapper, event);
}
public void reset(SocketWrapperBase<S> socketWrapper, SocketEvent event) {
Objects.requireNonNull(event);
this.socketWrapper = socketWrapper;
this.event = event;
}
@Override
public final void run() {
Lock lock = socketWrapper.getLock();
lock.lock();
try {
if (socketWrapper.isClosed()) {
return;
}
doRun();
} finally {
lock.unlock();
}
}
protected abstract void doRun();
}每个socketWrapper都关联着一把锁,解析报文线程排队执行。
总结一下
到现在我们本篇提出的问题已经得到了全面的解决,即报文分批到达,两批报文间隔相对时间长一点,对于这种情况Tomcat选择缓存这种报文。如果是第一批报文没读完,第二个报文就到达了。Tomcat选择加锁来解决这个问题。其实写本篇看源码的时候,我总是想着看源码能不能有一个范式遵循固定的步骤去拿到对应的答案。 但是想了想源码是一个繁荣的大树,有时候我们只想去观察某一处枝干,我们在看源码的时候有时候观察到一些点,尝试将其连接起来,然后验证是否是我们想观察到的枝干即可。
