文章目录
有需要本项目的代码或文档以及全部资源,或者部署调试可以私信博主
项目介绍:基于Hadoop生态与Flask的中文文本词频统计与可视化系统
随着互联网数据的爆炸式增长,如何对大规模文本数据进行高效的处理与分析,成为自然语言处理(NLP)和大数据领域的重要课题。本项目围绕中文文本数据,利用Hadoop的分布式存储和计算能力,结合Python生态中的分词、数据处理与Web开发工具,实现了一个中文文本的词频统计及可视化系统。系统的整体流程包括文本预处理、Hadoop MapReduce 分布式词频统计、结果可视化以及Web端交互展示。
项目背景与目标
在中文文本处理中,相较英文文本的空格分词,中文存在连续字符且无显式分词边界,因此分词是中文文本分析中不可或缺的一步。本项目旨在处理大规模中文文本,统计各词语出现频次,并通过可视化图表形式在网页上呈现,便于用户直观了解文本中的高频词汇及词汇分布。项目主要目标包括:
- 实现高效的中文分词及停用词过滤
- 利用Hadoop MapReduce对海量文本进行分布式词频统计
- 将词频统计结果持久化到本地
- 基于Flask框架实现词频数据的Web可视化展示
技术栈
本项目使用的主要技术与工具包括:
- Python 3:用于编写分词脚本、Mapper 和 Reducer 脚本,以及 Flask 后端
- Jieba:优秀的中文分词工具,支持自定义词典与高效分词
- Hadoop 2.7.3:用于大数据的存储 (HDFS) 和分布式计算 (MapReduce)
- Hadoop Streaming:支持使用 Python 脚本编写 Mapper 和 Reducer
- Flask:轻量级 Python Web 框架,用于构建可视化 Web 页面
- HTML/CSS/JavaScript:前端页面展示及图表渲染
- Echarts / Chart.js:用于实现交互式图表展示
系统流程与实现细节
1. 中文文本预处理
系统首先通过 Python 脚本对原始中文文本进行预处理。该脚本通过 jieba 分词,分解连续的汉字字符串为独立词语,并过滤掉停用词及常见标点符号。如下是核心分词流程:
python
words = jieba.cut(line)
filtered_words = [word for word in words if word not in stop_words and word not in ",。、;:''""【】《》?、.!...\n"]分词后,结果以制表符分隔写入文件,为后续 Hadoop 处理提供输入。
2. Hadoop MapReduce 分布式词频统计
预处理后的文本上传至 HDFS。随后,使用 Hadoop Streaming 执行 MapReduce 作业:
-
Mapper.py:读取输入文件,将每行拆分为单词,逐行输出每个单词。
输出格式:
word -
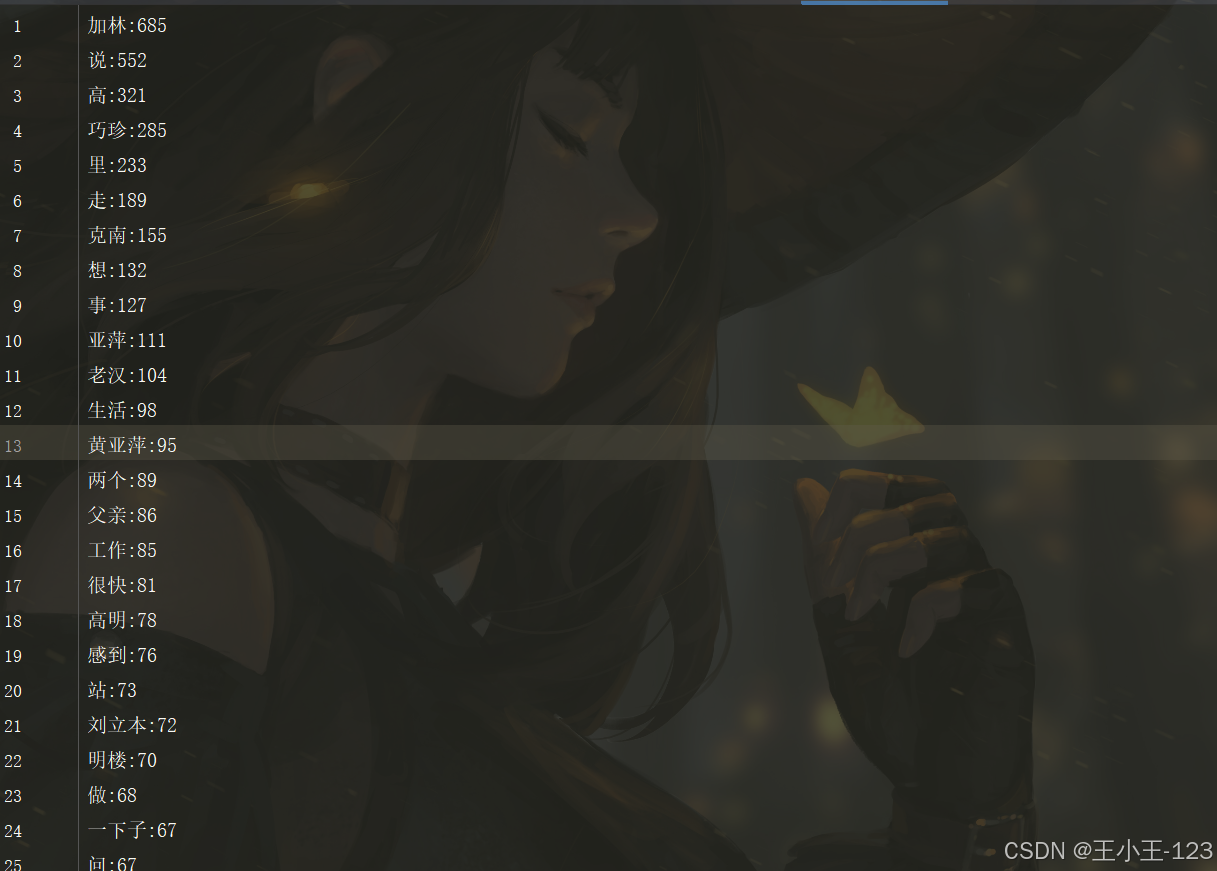
Reducer.py:接收 Mapper 输出,统计每个词语出现的次数,结果按词频降序输出。
输出格式:
word:count
为了保证灵活性,Reducer 中利用 Python 字典聚合词频,并对结果进行排序:
python
ls.sort(key=lambda x: x[1], reverse=True)作业执行完成后,通过 HDFS 命令将统计结果下载至本地,供可视化模块使用。
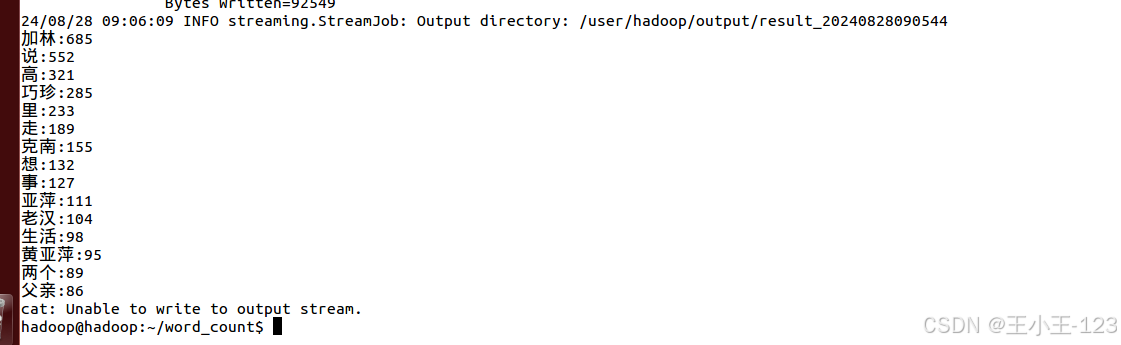
3. Web 可视化展示
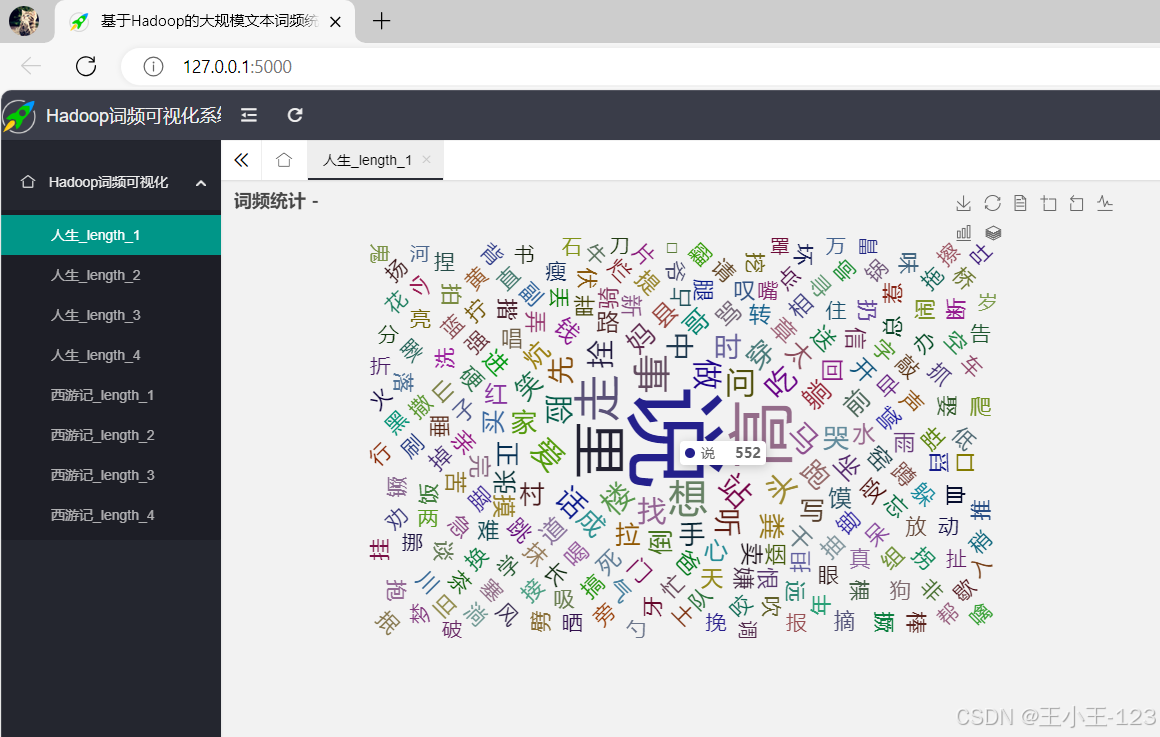
下载的词频结果被导入 Flask 后端,供 Web 应用读取。用户访问网页时,Flask 将词频数据以 JSON 格式传递给前端,前端利用 Echarts 或 Chart.js 渲染词云图、柱状图或折线图等多种图表,生动展示词频分布。
前端示例流程:
javascript
$.getJSON('/get_word_count', function(data) {
var chart = echarts.init(document.getElementById('main'));
var option = {
series: [{
type: 'wordCloud',
data: data
}]
};
chart.setOption(option);
});用户通过 Web 页面即可交互式查看文本中最常出现的词汇,分析文本主题或情感倾向。
项目亮点与价值
本项目充分结合了 NLP 与大数据技术的优势,实现以下创新与价值:
- 支持大规模中文文本处理,突破单机处理瓶颈
- 利用 Hadoop 提高处理效率,支持分布式扩展
- 提供直观、交互式的词频可视化,增强数据分析体验
- 架构简洁,易于部署及二次开发,可灵活应用于舆情分析、内容挖掘等领域
通过该系统,用户能够轻松应对中文文本的海量数据分析任务,将分散的文字信息高效提炼为可视化的、有价值的洞见。
该项目的优势是可以处理海量的文本,虽然Python也可以处理但是,当数据集剧增的时候,可能出现性能的问题,Hadoop就可以很好的解决这个痛点。


系统展示
项目总结
本项目是一个将Hadoop与文本词频统计的实战项目结合在一起的项目,通过对数据的处理之后,统计词频,然后完成可视化的渲染。
全流程打通了如何借助Hadoop完成这一项工作。
每文一语
小而不乱