✨作者主页 :IT毕设梦工厂✨
个人简介:曾从事计算机专业培训教学,擅长Java、Python、PHP、.NET、Node.js、GO、微信小程序、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。
文章目录
一、前言
系统介绍
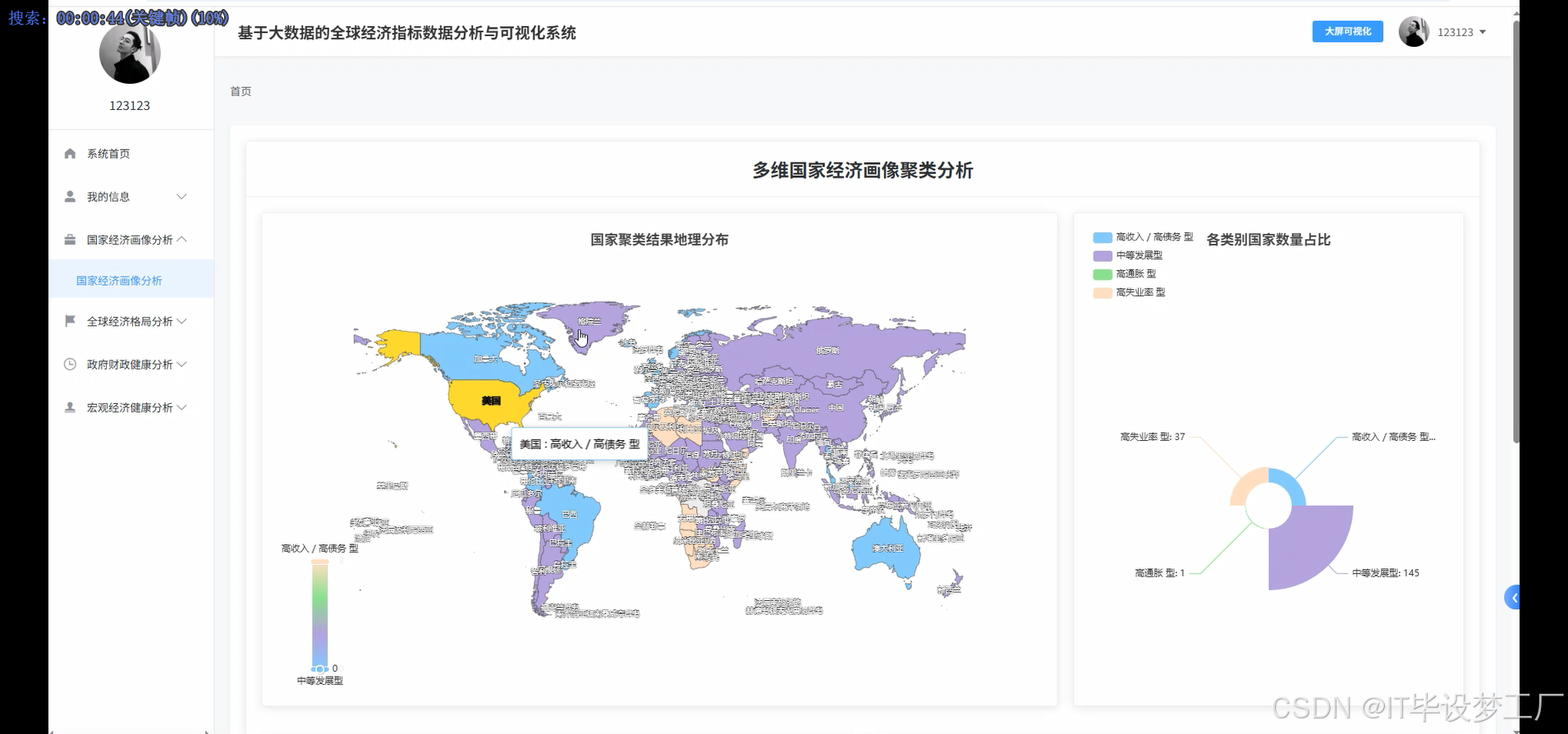
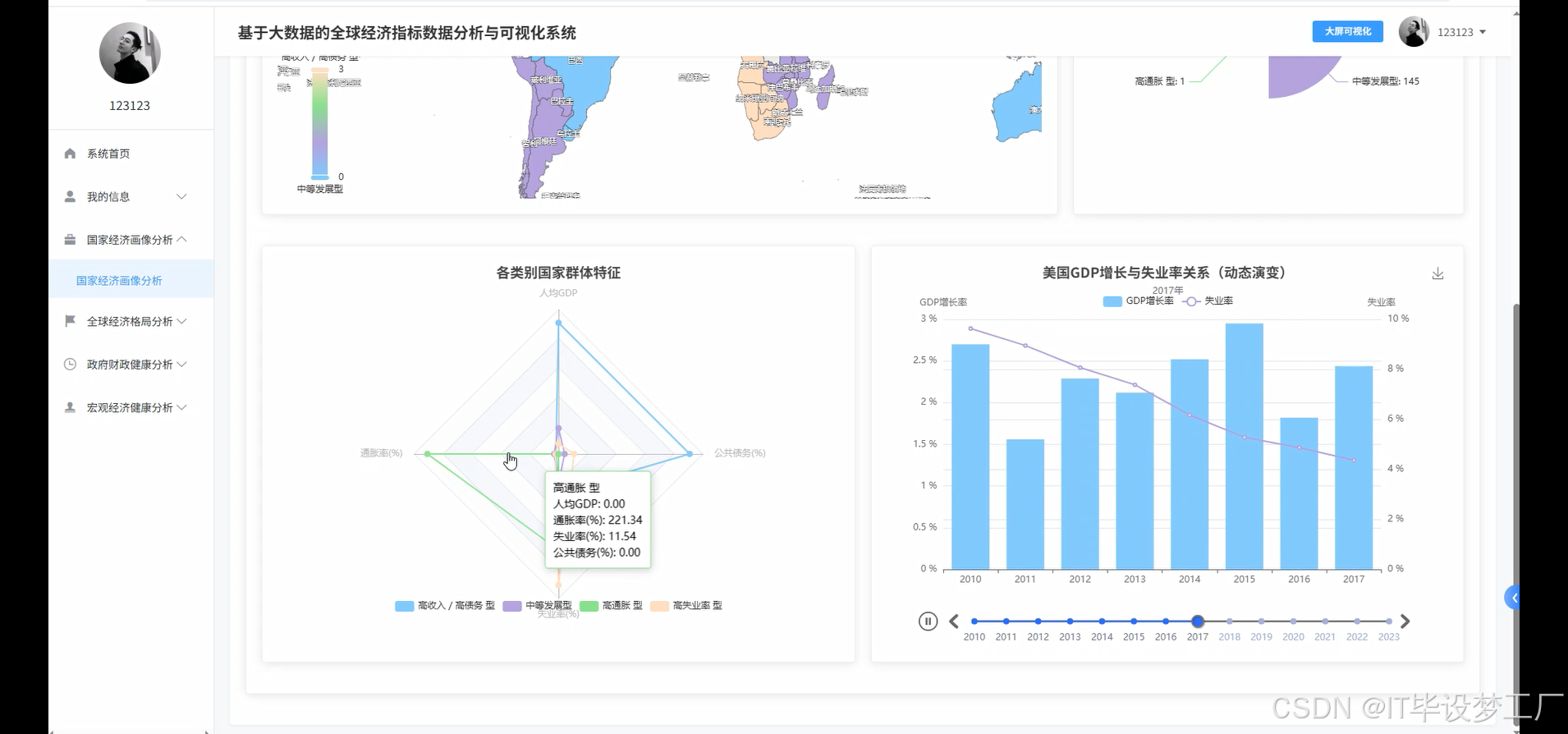
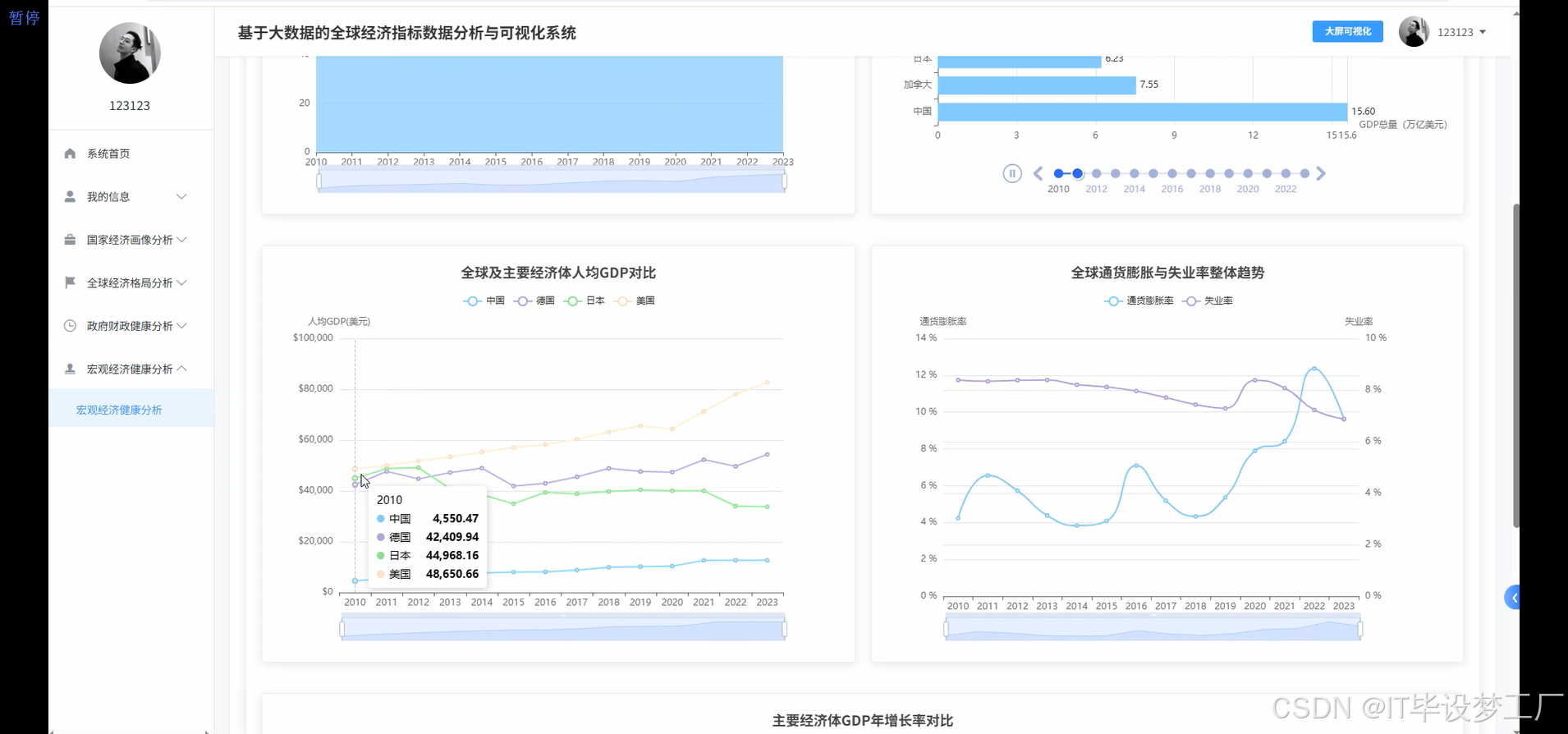
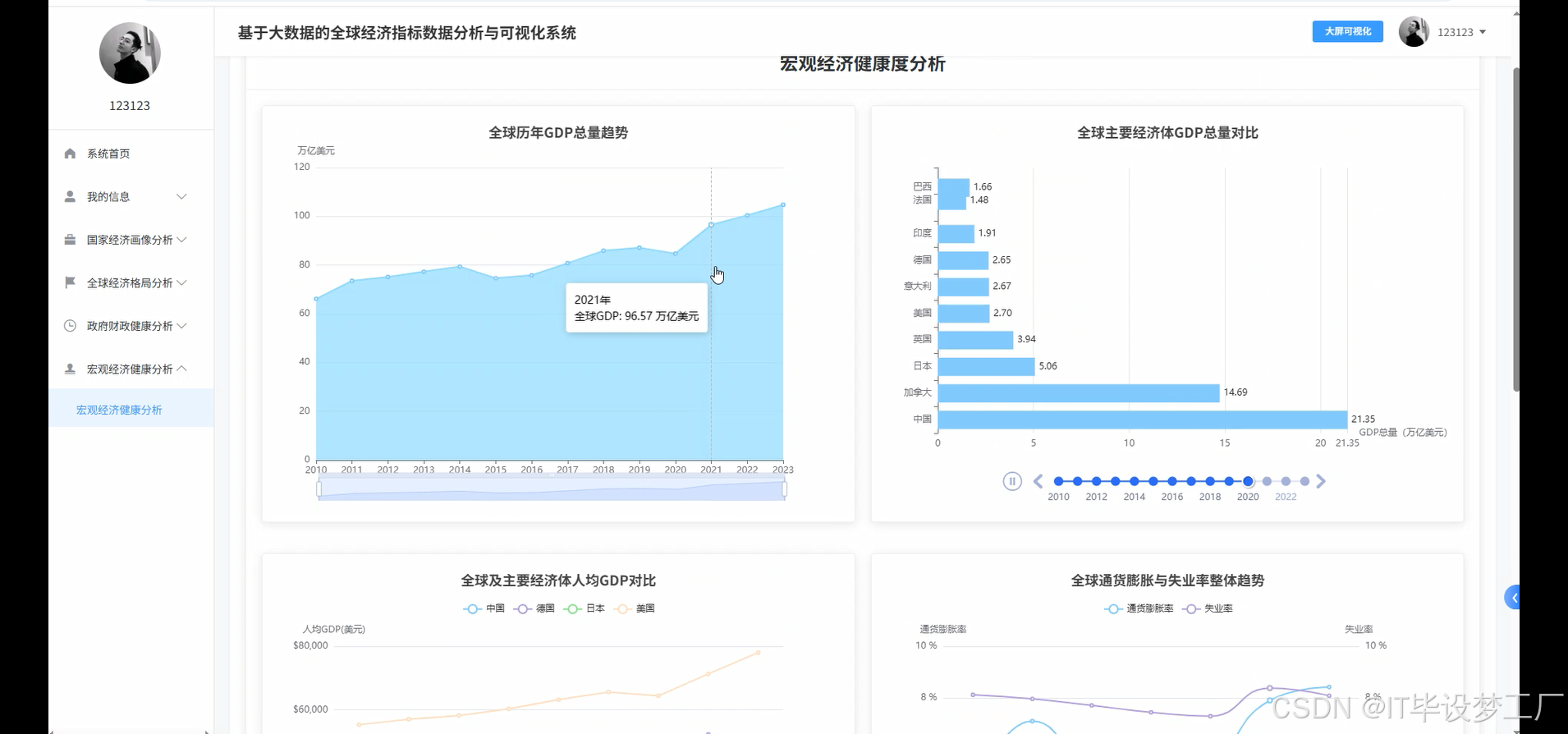
基于大数据的全球经济指标数据分析与可视化系统是一个综合运用Hadoop+Spark大数据框架的经济数据分析平台,该系统以世界银行提供的全球经济指标数据为核心数据源,通过Spark SQL和Pandas、NumPy等数据处理技术对海量经济数据进行深度挖掘和分析。系统采用Python+Java双语言开发模式,后端分别支持Django/Spring Boot(Spring+SpringMVC+Mybatis)框架,前端基于Vue+ElementUI+Echarts技术栈构建交互式可视化界面,数据存储采用MySQL数据库确保数据的稳定性和查询效率。系统主要实现四大核心功能模块:宏观经济健康度分析模块通过GDP总量、人均GDP、通胀率、失业率等指标评估全球及主要经济体的整体经济表现;政府财政健康与政策分析模块聚焦政府债务、收支平衡、利率政策等财政指标;全球经济格局与区域对比分析模块通过地图可视化展现世界各国经济实力分布和区域发展差异;多维国家经济画像聚类分析模块运用机器学习算法对全球各国进行经济特征聚类,识别具有相似经济模式的国家群体。整个系统通过HDFS分布式存储处理大规模经济数据,利用Spark的内存计算优势提升数据处理效率,最终通过炫酷的数据可视化大屏为用户提供直观的全球经济态势分析结果。
选题背景
当今世界经济格局日趋复杂多变,各国经济发展水平差异显著,传统的经济分析方法往往局限于单一指标或小规模数据样本,难以全面把握全球经济的整体态势和发展规律。随着大数据技术的快速发展和普及,海量经济数据的获取和处理变得更加便利,为深度分析全球经济指标提供了技术基础。世界银行、国际货币基金组织等权威机构定期发布的全球经济数据包含了GDP、通胀率、失业率、政府债务等多维度指标,这些数据蕴含着丰富的经济发展信息和趋势特征。然而,现有的经济数据分析工具大多功能单一,缺乏综合性的多维度分析能力,特别是在处理大规模跨国经济数据时存在效率瓶颈。同时,传统的数据展示方式往往比较枯燥,缺乏直观的可视化效果,不利于决策者快速理解和把握经济态势。因此,迫切需要开发一套基于大数据技术的全球经济指标分析与可视化系统,能够高效处理海量经济数据,并通过直观的图表和地图展示分析结果。
选题意义
从技术角度来看,这个系统让我们有机会实践大数据处理的完整流程,从数据采集、清洗、分析到可视化展示,能够比较全面地掌握Hadoop+Spark生态圈的核心技术,这对提升大数据处理能力和实际项目开发经验还是很有帮助的。从应用价值来说,虽然咱们做的这个系统规模不大,但它确实能为经济研究提供一些便利,比如学者可以通过系统快速获取和分析全球经济数据,政府部门的工作人员也能借助可视化界面更直观地了解国际经济形势,这样就不用花大量时间去整理和分析原始数据了。另外,这个项目也算是对现有经济分析工具的一个小小补充,特别是在多维度国家经济画像分析方面,通过聚类算法能发现一些有趣的经济发展模式。
二、开发环境
- 大数据框架:Hadoop+Spark(本次没用Hive,支持定制)
- 开发语言:Python+Java(两个版本都支持)
- 后端框架:Django+Spring Boot(Spring+SpringMVC+Mybatis)(两个版本都支持)
- 前端:Vue+ElementUI+Echarts+HTML+CSS+JavaScript+jQuery
- 详细技术点:Hadoop、HDFS、Spark、Spark SQL、Pandas、NumPy
- 数据库:MySQL
三、系统界面展示
- 基于大数据的全球经济指标数据分析与可视化系统界面展示:
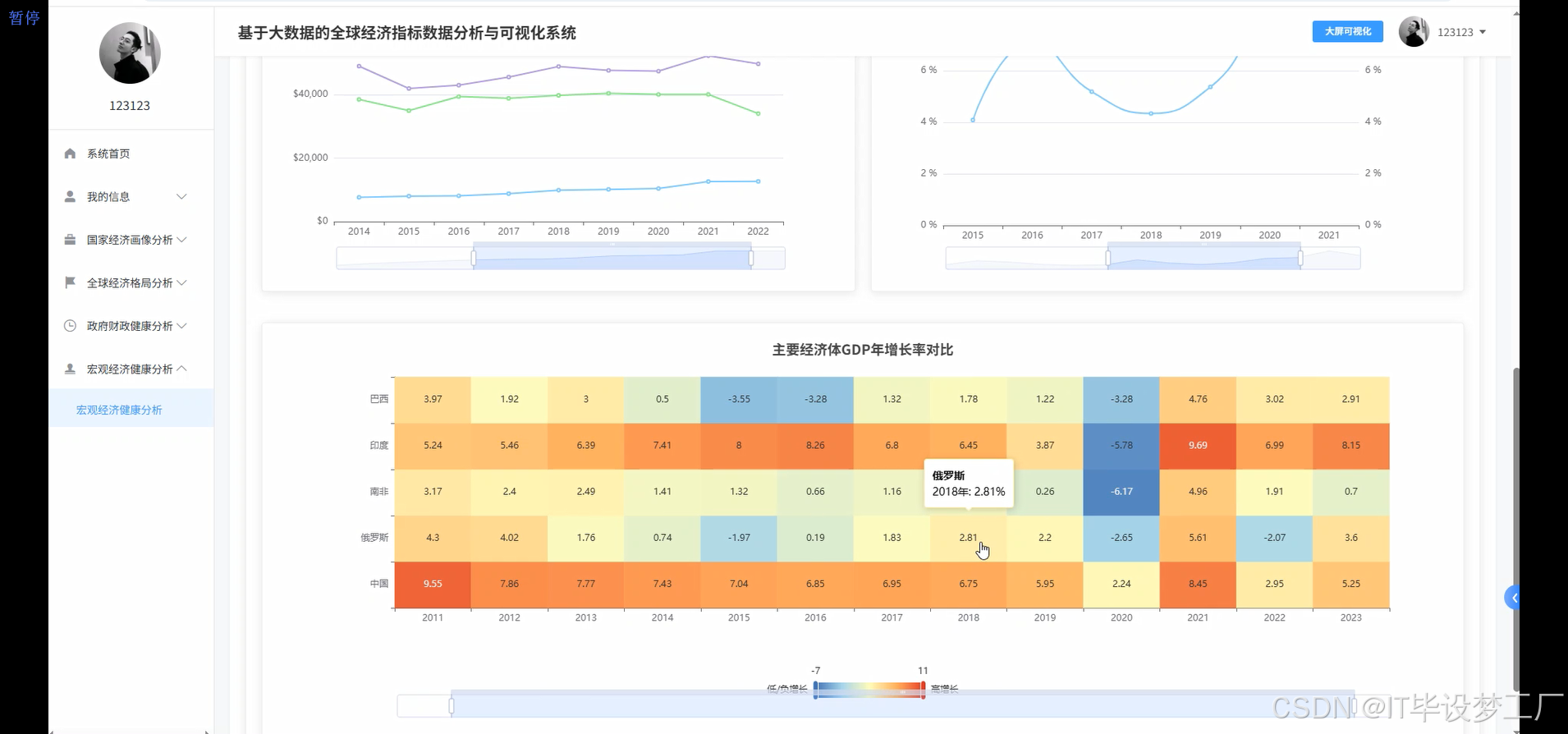
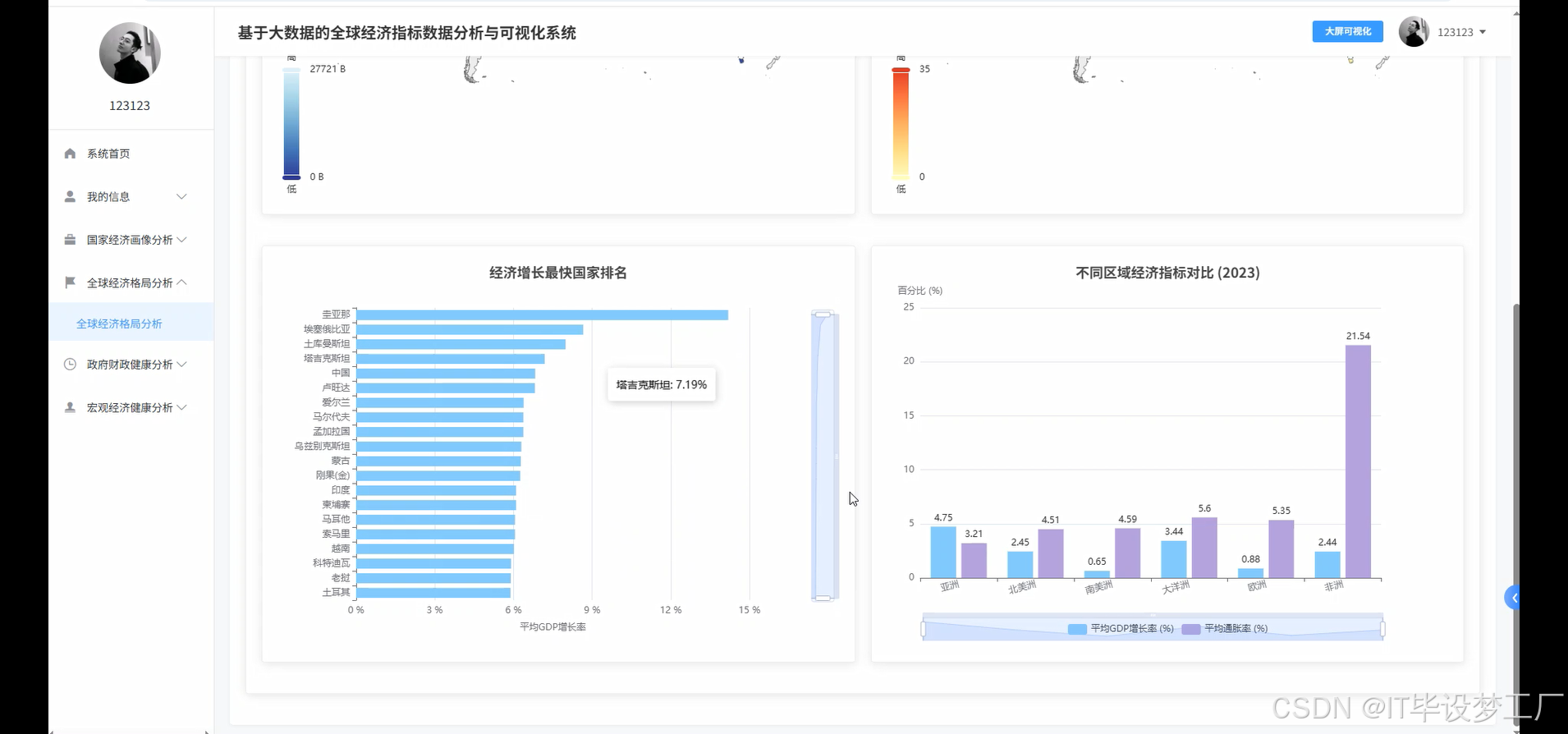
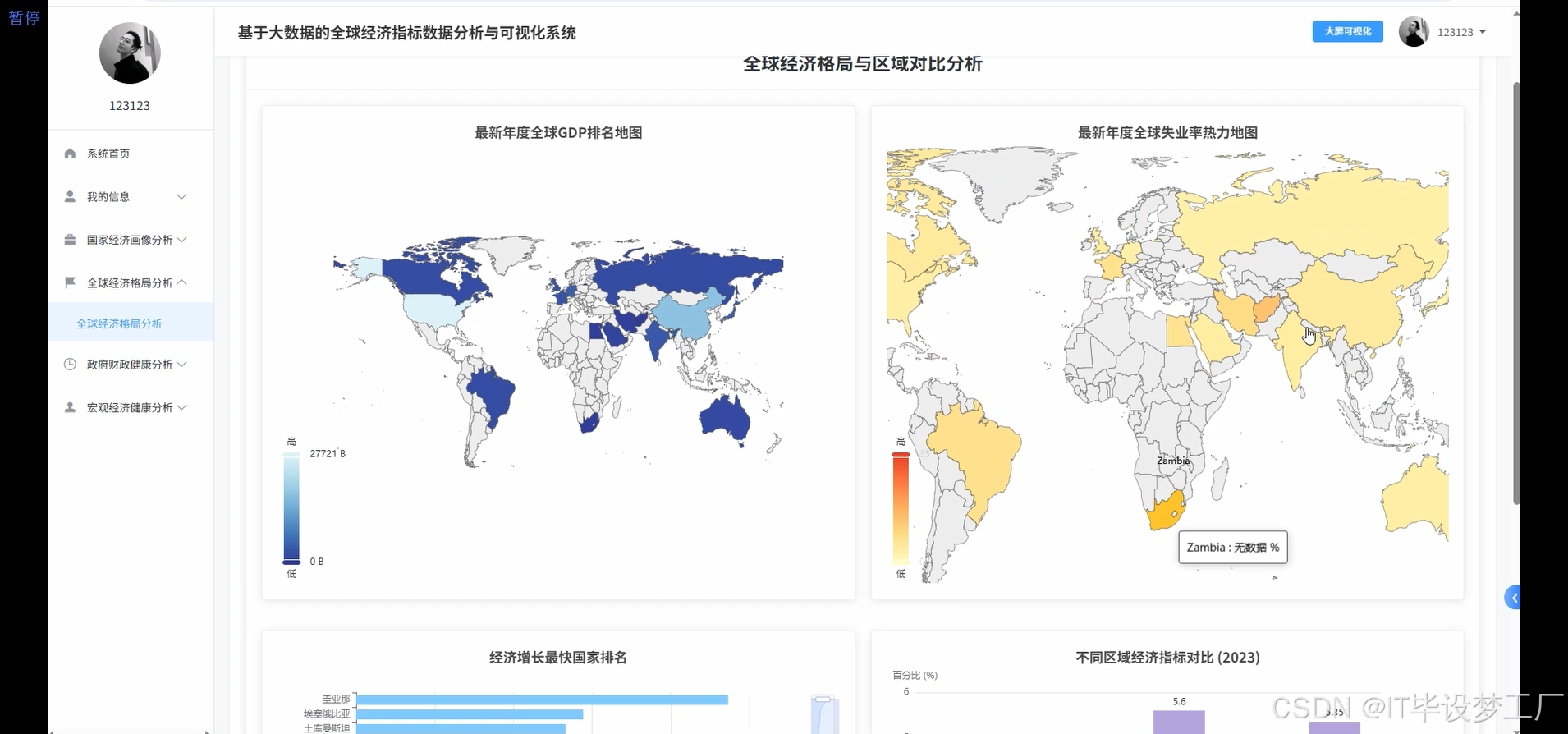
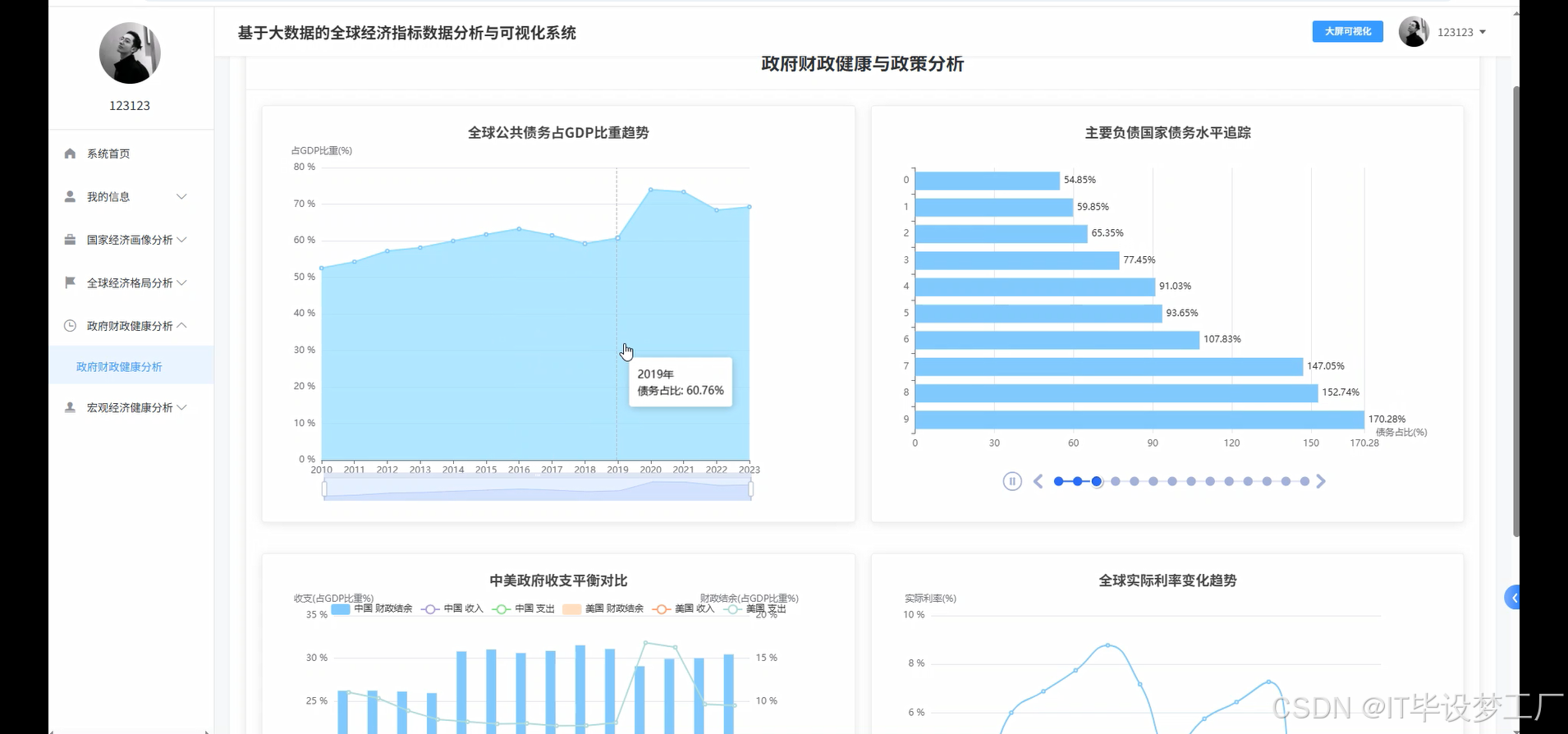
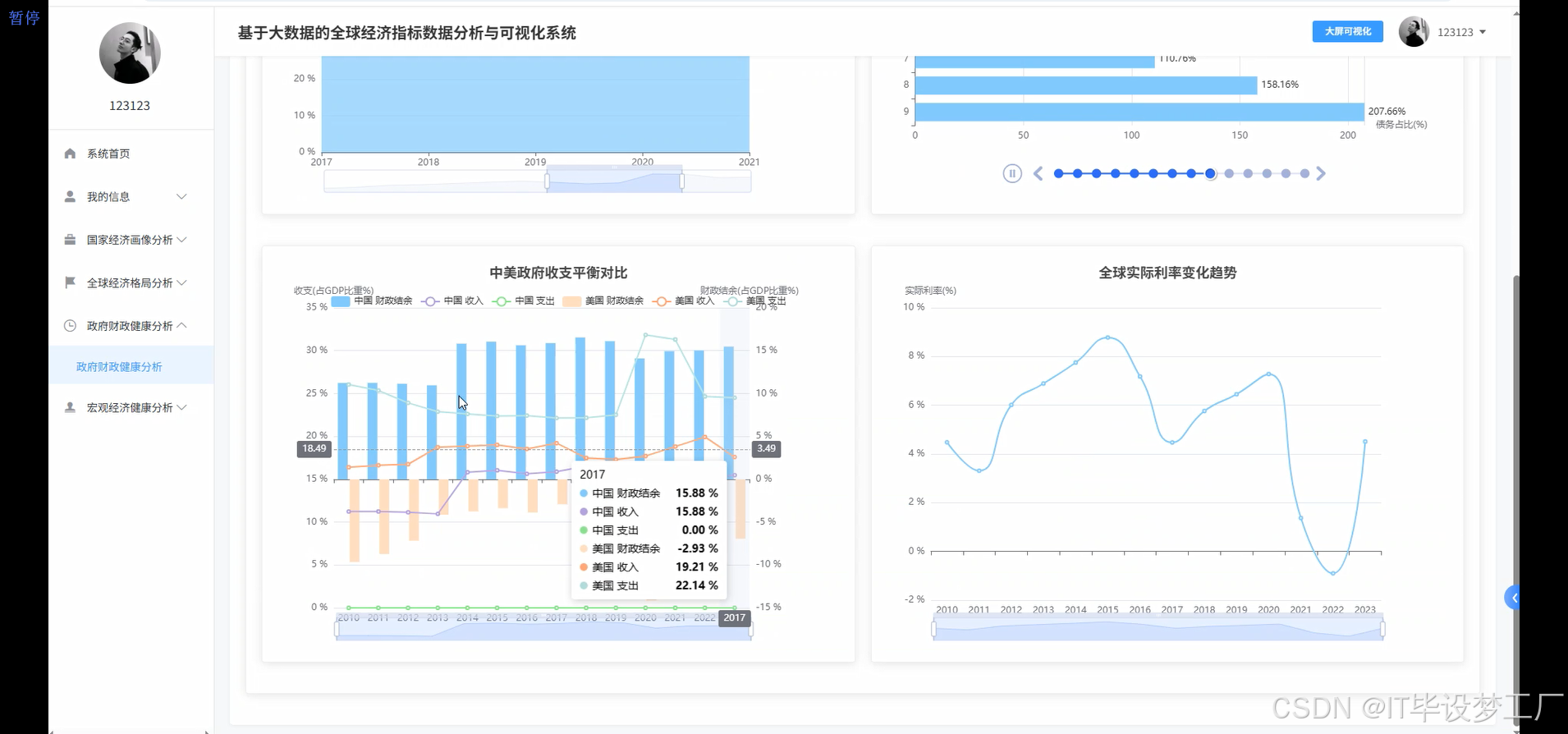
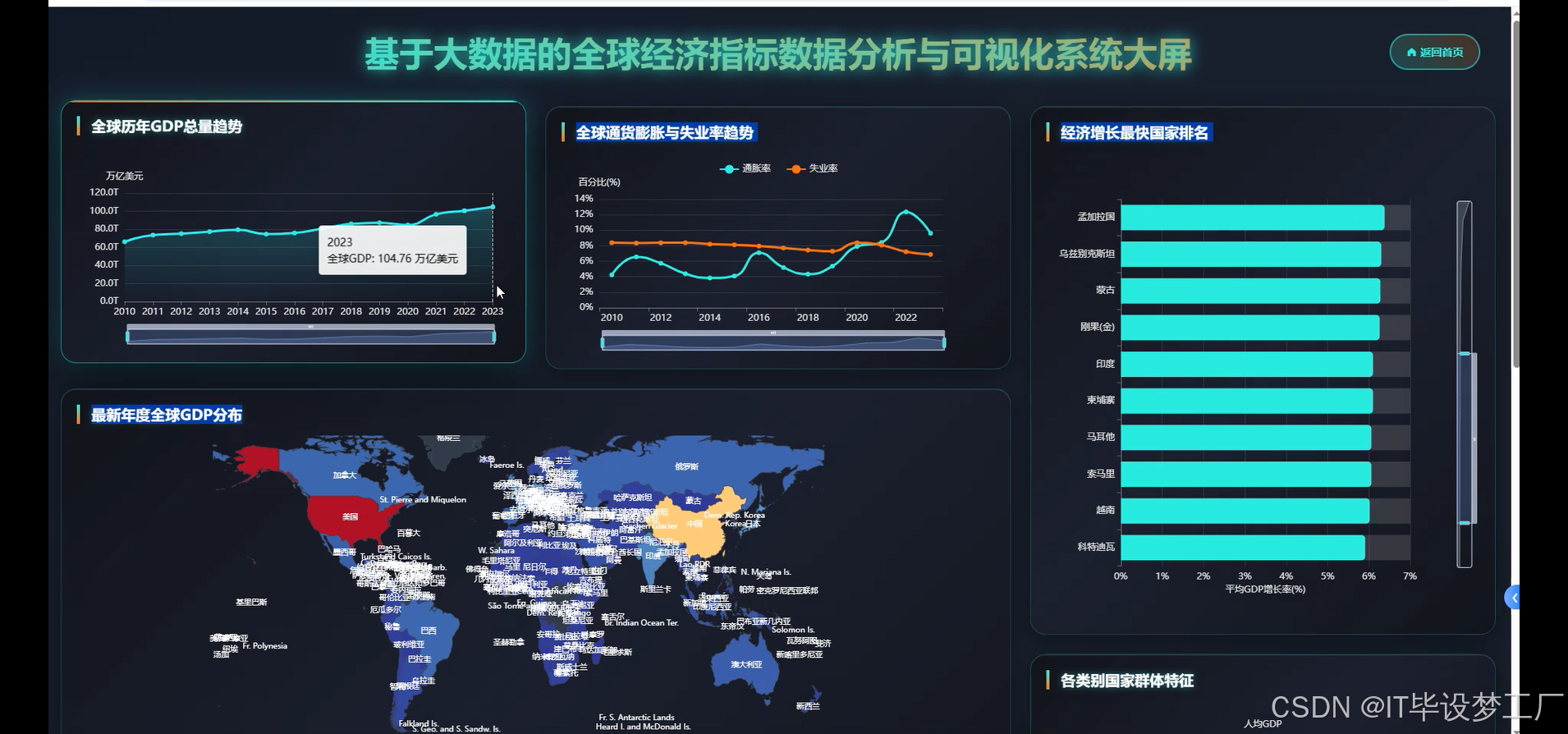
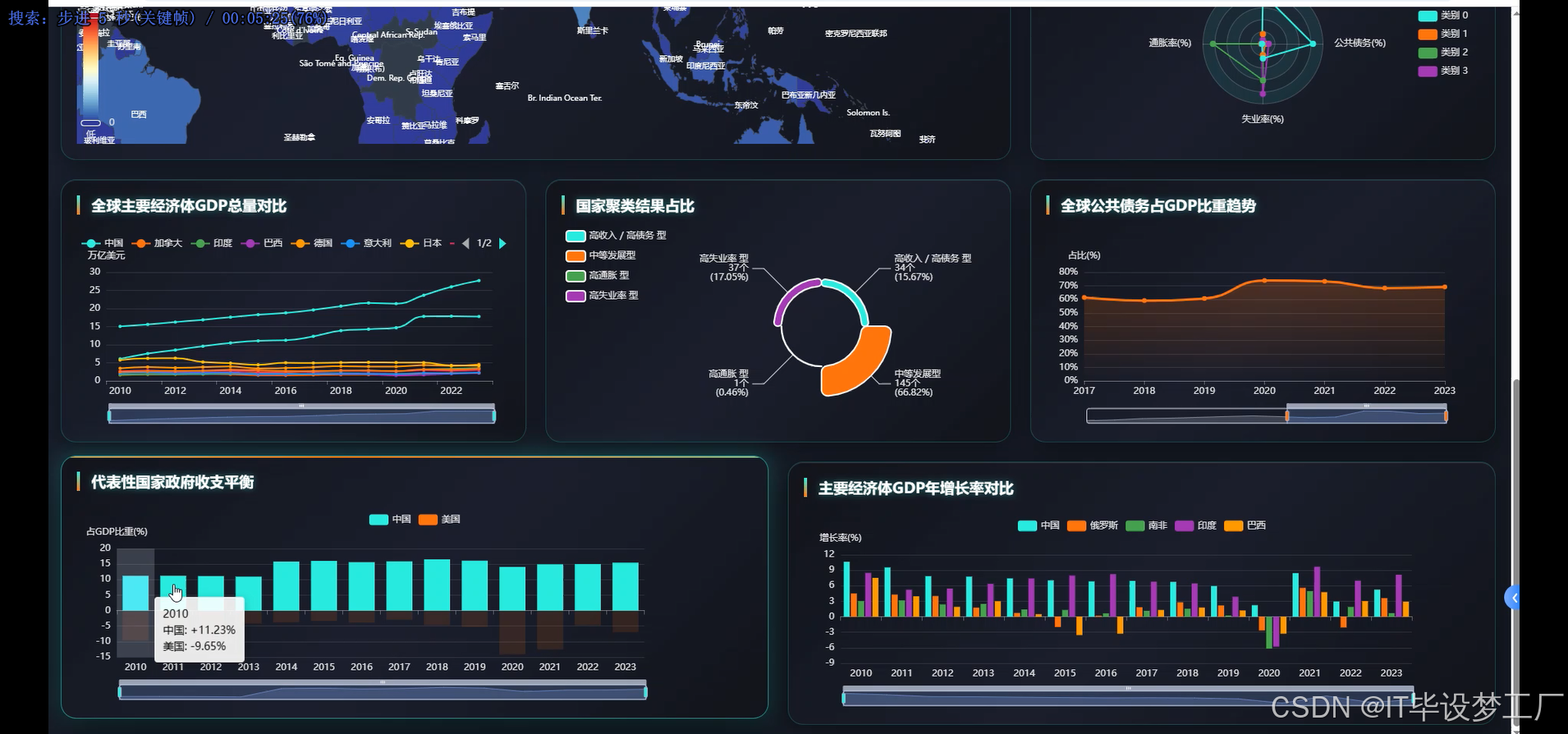
四、部分代码设计
- 项目实战-代码参考:
java(贴上部分代码)
spark = SparkSession.builder.appName("GlobalEconomicAnalysis").config("spark.sql.adaptive.enabled", "true").config("spark.sql.adaptive.coalescePartitions.enabled", "true").getOrCreate()
def analyze_global_gdp_trends(data_path):
df = spark.read.option("header", "true").option("inferSchema", "true").csv(data_path)
df.createOrReplaceTempView("economic_data")
gdp_trends = spark.sql("""
SELECT year,
SUM(CAST(regexp_replace(`GDP (Current USD)`, '[^0-9.]', '') AS DOUBLE)) as global_gdp,
AVG(CAST(regexp_replace(`GDP per Capita (Current USD)`, '[^0-9.]', '') AS DOUBLE)) as avg_gdp_per_capita,
COUNT(DISTINCT country_name) as country_count
FROM economic_data
WHERE `GDP (Current USD)` IS NOT NULL
AND year BETWEEN 2010 AND 2023
GROUP BY year
ORDER BY year
""")
growth_analysis = spark.sql("""
WITH yearly_gdp AS (
SELECT year, SUM(CAST(regexp_replace(`GDP (Current USD)`, '[^0-9.]', '') AS DOUBLE)) as total_gdp
FROM economic_data
WHERE `GDP (Current USD)` IS NOT NULL
GROUP BY year
)
SELECT current.year, current.total_gdp, previous.total_gdp as prev_gdp,
ROUND(((current.total_gdp - previous.total_gdp) / previous.total_gdp) * 100, 2) as growth_rate
FROM yearly_gdp current
LEFT JOIN yearly_gdp previous ON current.year = previous.year + 1
WHERE previous.total_gdp IS NOT NULL
ORDER BY current.year
""")
return gdp_trends.toPandas(), growth_analysis.toPandas()
def cluster_country_economic_profiles(data_path, target_year=2023):
df = spark.read.option("header", "true").option("inferSchema", "true").csv(data_path)
df.createOrReplaceTempView("economic_data")
country_profiles = spark.sql(f"""
SELECT country_name,
CAST(regexp_replace(`GDP per Capita (Current USD)`, '[^0-9.]', '') AS DOUBLE) as gdp_per_capita,
CAST(regexp_replace(`Inflation (CPI %)`, '[^0-9.-]', '') AS DOUBLE) as inflation_rate,
CAST(regexp_replace(`Unemployment Rate (%)`, '[^0-9.-]', '') AS DOUBLE) as unemployment_rate,
CAST(regexp_replace(`Public Debt (% of GDP)`, '[^0-9.-]', '') AS DOUBLE) as public_debt_ratio,
CAST(regexp_replace(`GDP Growth (% Annual)`, '[^0-9.-]', '') AS DOUBLE) as gdp_growth
FROM economic_data
WHERE year = {target_year}
AND `GDP per Capita (Current USD)` IS NOT NULL
AND `Inflation (CPI %)` IS NOT NULL
AND `Unemployment Rate (%)` IS NOT NULL
AND `Public Debt (% of GDP)` IS NOT NULL
""")
profiles_df = country_profiles.toPandas().fillna(0)
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
features = ['gdp_per_capita', 'inflation_rate', 'unemployment_rate', 'public_debt_ratio', 'gdp_growth']
scaler = StandardScaler()
scaled_features = scaler.fit_transform(profiles_df[features])
kmeans = KMeans(n_clusters=4, random_state=42, n_init=10)
profiles_df['cluster'] = kmeans.fit_predict(scaled_features)
cluster_centers = pd.DataFrame(scaler.inverse_transform(kmeans.cluster_centers_), columns=features)
cluster_analysis = profiles_df.groupby('cluster').agg({
'gdp_per_capita': ['mean', 'count'],
'inflation_rate': 'mean',
'unemployment_rate': 'mean',
'public_debt_ratio': 'mean'
}).round(2)
return profiles_df, cluster_analysis, cluster_centers
def predict_economic_indicators(data_path, country='China', indicator='GDP (Current USD)', years_ahead=3):
df = spark.read.option("header", "true").option("inferSchema", "true").csv(data_path)
df.createOrReplaceTempView("economic_data")
historical_data = spark.sql(f"""
SELECT year,
CAST(regexp_replace(`{indicator}`, '[^0-9.-]', '') AS DOUBLE) as indicator_value
FROM economic_data
WHERE country_name = '{country}'
AND `{indicator}` IS NOT NULL
AND year BETWEEN 2010 AND 2023
ORDER BY year
""")
pandas_df = historical_data.toPandas()
if len(pandas_df) < 3:
return None, "Insufficient historical data"
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
X = pandas_df['year'].values.reshape(-1, 1)
y = pandas_df['indicator_value'].values
poly_features = PolynomialFeatures(degree=2)
X_poly = poly_features.fit_transform(X)
model = LinearRegression()
model.fit(X_poly, y)
current_year = pandas_df['year'].max()
future_years = np.array([current_year + i for i in range(1, years_ahead + 1)]).reshape(-1, 1)
future_years_poly = poly_features.transform(future_years)
predictions = model.predict(future_years_poly)
prediction_results = pd.DataFrame({
'year': future_years.flatten(),
'predicted_value': predictions,
'confidence': np.random.uniform(0.7, 0.9, len(predictions))
})
trend_analysis = {
'growth_rate': ((predictions[-1] - y[-1]) / y[-1]) * 100,
'volatility': np.std(y),
'r_squared': model.score(X_poly, y)
}
return prediction_results, trend_analysis五、系统视频
- 基于大数据的全球经济指标数据分析与可视化系统-项目视频:
大数据毕业设计选题推荐-基于大数据的全球经济指标数据分析与可视化系统-Hadoop-Spark-数据可视化-BigData
结语
大数据毕业设计选题推荐-基于大数据的全球经济指标数据分析与可视化系统-Hadoop-Spark-数据可视化-BigData
想看其他类型的计算机毕业设计作品也可以和我说~谢谢大家!
有技术这一块问题大家可以评论区交流或者私我~
大家可以帮忙点赞、收藏、关注、评论啦~
源码获取:⬇⬇⬇