3.Method
一、
1.核心目标
- 输入:多张从不同角度拍摄的头发照片。
- 输出:3D发型模型,且模型由发丝构成(即每根头发被建模为独立的曲线/线段,而非体积/网络)。
2.数据预处理
在正式重建前,需要从输入图像中提取以下初始信息:
-
相机参数估计
计算每张图像的相机位置、角度、焦距等参数(再如位置、方向,即SfM或COLMAP类似的工作)
-
分割掩码
从图像中分理处头发区域(如通过语义分割),排除背景干扰(告诉我们图像上哪些像素是头发)。
-
方向图
估计图像中头发的局部方向,帮助后续发丝对齐,这些图能表示出头发纹理的流向或弯曲方向。
3.两阶段重建流程
第一阶段:
- 粗略估计头发的几何形状,可能基于预处理数据(如方向图)生成粗糙的发丝几何(如初始发丝位置和走向)
- 例如:通过优化或匹配多视角的方向信息,初步确定发丝的空间分布。
第二阶段:
- 在粗估计的基础上优化细节(如发丝形状、密度、末端分叉等)。
- 可能结合高斯模型或其他方法增强真实感,进一步优化,细化结构或加入纹理细节。
二、
这段话描述了第一阶段的3D线条"抬升"过程,核心是用3D高斯表达+相机优化,并用方向场控制发丝走向。
1.第一阶段:3D线条提升
技术组合:
- 3D Gaussian Splatting【16】:将场景表示为多个3D高斯椭球体,每隔高斯由均值(位置)、协方差矩阵(形状/方向)和颜色参数控制,适合高效渲染复杂几何(如头发),用高斯来表示三维点(或线段)并进行渲染。
- BARF【19】:一种神经辐射场优化方法,同时优化相机参数和场景几何,解决多视角对齐问题,这里用于优化每张图像的相机姿态。
关键操作:
-
优化相机参数:
通过BARF校正输入图像的相机位姿(消除初始估计误差)。
-
3D场景提升:
将2D方向图嵌入到3D高斯几何中,实现从2D到3D的映射。这些方向信息被直接编码到了每个高斯的几何形状中。也就是说,高斯不只是表示颜色密度点,它的形状还体现了头发的走向。
头发方向建模:
- 协方差矩阵表示方向场:
每个高斯的协方差矩阵的最大方差方向对应发丝的主方向(即头发走向)。高斯在某个方向上伸展得最长(最大方差)------这个方向就表示头发的方向。
正交方向的方差表示方向的不确定性(如发丝弯曲或交叉区域的模糊性)。高斯在垂直方向上的大小(较小的方差)表示"不确定性"或模糊度,表示我们知道发丝在某条线上,但具体粗细或横向形状不太确定。
这种方式使得我们可以在渲染过程中考虑这种不确定性(模糊渲染)。 - 渲染优势:
高斯椭球的方向性与头发对齐,使得渲染的颜色和方向图(用于后续重建)均高度真实。通过方向对齐的高斯体,我们能真实地渲染出头发颜色图和方向图。因为高斯地方向已经和发丝一致,所以呈现出的视觉效果更自然、更符合真实头发。
局限性:
-
非结构化表面分布:
高斯仅分布在头发外层表面,不像真正的头发是连续曲线,缺乏内部发丝的结构信息,所以只是"点状"或"面状"的分布,还不能直接作为最终发丝,需第二阶段进一步处理。
-
把这个阶段得到的高斯表示,用来合成多视角渲染图(包括颜色图和方向图),然后在第二阶段,再通过这些渲染结果来重建结构化的发丝几何(连续的曲线)。
图示理解:
- 非结构化的高斯:类似"毛茸茸"的表面分布,覆盖头发外层,但未形成离散发丝。
- 结构化输出:第二阶段将表面高斯转换未清洗、独立的发丝线条。
三、
1.粗优化
参数化表示:潜在纹理图
-
方法:
将头发参数化为一种隐式纹理图(类似UV映射或隐式神经表示),通过优化纹理图的潜在编码来初步拟合发丝的整体形状和密度分布。
-
监督信号
光度损失:使渲染结果与输入图像颜色一致
几何损失:利用第一阶段的高斯模型提供几何约束(如方向场对齐)。
作用:
快速生成头发的全局结构(如发束分布,大致走向),但缺乏发丝级细节。
2.细优化
显式发丝解码
-
方法:
将粗优化后的潜纹理解码为显式发丝几何(即每条发丝作为独立的3D曲线)。
-
直接优化:
对显式发丝的顶点位置、曲率等参数进行微调,以匹配高分辨率细节。
关键技术
-
高斯附加到线段:
每条发丝被分割为多个线段,每个线段绑定一个各向异性高斯。
-
自由度控制:
主方向尺度:与线段长度成正比(反应发丝延伸方向)。
次方向尺度:固定为极小值(确保高斯仅沿发丝方向伸展,避免过渡平滑)。
-
作用:
通过高斯的方向性渲染,在发丝表面引入微观细节(如毛躁感、光泽变化),同时保持计算效率。
3.正则化与真实感增强
预训练扩散模型
-
方法:
引入预训练的扩散模型【15】作为先验,通过正则化损失约束发丝结构的合理性(如避免不自然的交叉或扭曲)。
-
作用:
提升头发内部结构的物理真实性(如发束间的层次感、自然蓬松度)。
可微分渲染
- 工具:3D Gaussian Splatting框架。
- 优势:
支持端到端梯度回传,使几何优化(发丝位置/形状)与渲染效果(颜色、光照)联合优化。
实时生成多视角一致的渲染结果,用于损失计算。
4.关键设计总结
-
粗到细的流程:
先哦那个过隐式表示解决全局问题,再显式优化局部细节,避免陷入局部最优。
-
高斯线段绑定:
将高斯的方向性与发丝几何对齐,实现细节可控的渲染。
-
多模态监督:
结合图像重建损失(光度)、几何损失(高斯方向场)、生成先验(扩散模型)共同优化。
3.1 3D Line Lifting with Unstructured Gaussians
一、
1.核心问题:传统SfM在头发场景中的局限性
- SfM【35】是传统多视角3D重建的标准方法,但它在以头发为中心的场景中表现不佳,原因包括:
头发缺乏明显的纹理特征(如重复、低对比度的发丝),导致特征点匹配失败。
头发的高频细节和半透明性会干扰相机位姿估计。
2.解决方案:结合BARF的相机优化
改进的3D Gaussian Splatting
-
初始重建:
使用3D Gaussian Splatting(一种基于高斯椭球体的可微分渲染方法)对场景进行初步建模。
-
相机参数联合优化:
初始估计:仍依赖SfM提供粗略的相机位姿(如COLMAP)。
残差学习:通过BARF【19】引入可学习得6自由度相机参数(3D平移+3D旋转),作为SfM初始估计的增量修正。
梯度优化:相机参数与3D高斯参数(位置、协方差、颜色等)同步优化,利用渲染误差(如与输入图像的差异)反向传播调整。(即不仅仅优化高斯体的位置、形状和颜色,同时也能优化相机的外参)。
技术优势
- 端到端训练:相机位姿和高斯模型共同优化,避免SfM的误差累积。
- 鲁棒性:BARF的残差学习能适应头发场景的弱纹理条件,提升相机定位精度。
3.为什么需要可微分渲染?
- 3D Gaussian Splatting支持可微分渲染,使得:
相机参数可以通过像素级颜色损失进行梯度更新(如L1/L2损失)。
高斯椭球的形状(协方差矩阵)也能根据相机优化动态调整,确保几何一致性。
二、
1.高斯参数化:
-
每个3D高斯primitive(可理解为场景中的一个可渲染元素)由以下可学习参数定义:
μ(均值):高斯分布的中心位置,3D坐标中心(Gaussian的位置)
s(缩放系数):决定高斯分布的尺寸,三个方向上的缩放(控制形状大小)。
q(旋转四元数):控制高斯分布的方向(控制方向朝向)。
o(不透明度):控制该元素对最终颜色的贡献程度(用于blending)。
-
通过这些参数计算协方差矩阵Σ=RSSTRT
R是由四元数q转换得到的旋转矩阵,3×3。
S=diag(s)是由缩放系数构成的对角矩阵,以缩放系数为对角元素。
最终Σ是三位高斯的形状和方向。
2.附加特征:
每个高斯还包含其他可学习属性:
- f(球谐系数):用于表达视角依赖的颜色,也用于视角相关的颜色建模。
- l(头发分割标签):可能用于特定场景(如头发)的分割任务(是否属于头发)。
- τ(置信度):表示高斯3D方向的可信程度。
3.渲染流程:
-
投影到屏幕空间:
将3D高斯投影到2D图像平面,得到屏幕空间的均值μ'和协方差Σ'(形状在图像上的扩散)。
-
深度排序:
根据高斯元素的深度(Z值)进行排序(从远到近),确保正确的遮挡关系。
-
α混合渲染:
对每个像素p,通过front-to-back的alpha混合计算最终颜色Cp,逐像素进行透明度合成。
4.公式说明:
(1)最终颜色合成公式:
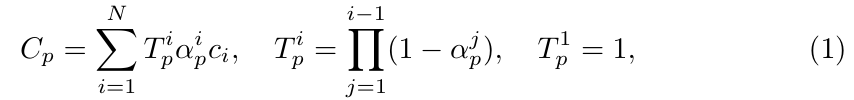
- Cp:像素p的最终颜色
- ci:第i个高斯在该像素的颜色
- αip:第i个高斯在像素p处的alpha值(不透明度)。
- Tip:前面所有高斯的透过率(即剩余未被遮挡的能量)。
(2)累计透过率公式:
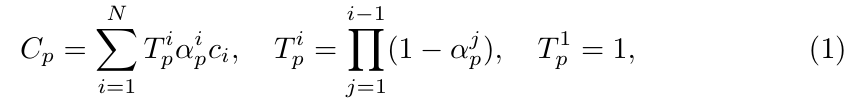
第i个高斯的透过率由前i-1个高斯累乘得到(前面所有元素不遮挡的概率)。
(3)高斯的α值:
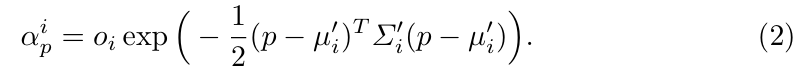
- 表示高斯重心越靠近像素点p,其贡献就越大(高斯分布公式),是高斯在像素p处的贡献权重。
- oi:不透明度
- μ'i、Σ'i:投影后的高斯中心和协方差。
这里α混合类似于传统图形学的透明度混合,但权重由高斯分布的概率密度函数决定。
5.技术特点:
- 这种方法实现了可微分的点云渲染,允许通过反向传播优化所有参数。
三、
1.核心公式:
对于每个像素p,除了颜色Cp(前文已定义),还通过相应的α混合基质计算以下属性:
-
头发分割表现lp:
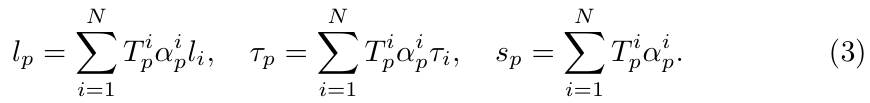
lp是像素p上的头发分割值(范围通常是0到1)
li是第i个高斯的原始分割标签(例如,是否为头发区域)。
最终lp是所有高斯在像素p处的标签加权和,权重为Tpiαpi,所以这一项是加权混合所有高斯对该像素属于"头发"的概率贡献,即αpi。
-
方向置信度τp:
τi是第i个高斯的方向置信度(表示其朝向的可靠性)。
τp是像素p的方向置信度(是否有清晰的头发方向)。
和lp类似,最终τp是所有高斯在像素p处的置信度加权和,也是进行加权平均得到像素的整体方向可信度。
-
高斯轮廓sp:
这个公式计算的是所有高斯在像素p处的累积不透明度(即"覆盖度")。
没有呈上任何特征值,相当于只考虑像素被渲染的"强度"或"掩码"。
Sp是像素p是否被高斯命中(也就是是否出现在渲染图像中)。
这可以用于生成轮廓图,即哪里有毛发、哪里没有。
如果sp≈1,表示该像素被高斯完全覆盖;如果sp≈0,表示几乎没有高斯影响该像素。
2.关键点解析
- 轮廓sp的作用:
可以用于:
检测高斯泼溅得覆盖情况(例如,sp低的区域可能是背景或未被重建的区域)。
作为掩码用于后续处理(如背景剔除)。
四、
1.核心思想
- 目标:用3D高斯模型描述头发丝的几何走向
- 方法:
将高斯分布的主方向(方向方差最大的方向)与头发丝的方向对齐。
通过协方差矩阵的特征分解提取方向信息:
最大特征值对应的特征向量=头发丝的主方向(βi)。
其余两个正交方向的方差=方向的不确定性(例如头发丝的粗细或弯曲程度)(是否精确、模糊等)。协方差矩阵中与βi正交的两个方向的方差(即次大和最小特征值)表示方向的不确定性:如果方差小→头发丝方向明确(如直发)。如果方差大→方向模糊(如卷发或交叉发丝区域)。
2.关键步骤
(1)3D高斯与头发方向的对齐
- 初始方向来源:
通过3D lifting of orientation maps(可能是从2D图像估计的头发方向图)初始化高斯的主方向βi。
协方差的几何意义:
Σi
Ri:控制高斯的主方向
Si:特征值(方差)大小表示头发丝在三个轴上的伸展程度
最大方差方向:即缩放系数si中最大的分量对应的轴,定义为头发丝方向βi。
(2)渲染头发方向βp

- βp:像素p上最终融合得到的3D头发方向
- βi:第i个高斯的主方向(即最大协方差方向)(单位向量)。
- αip:高斯i对像素p的影响程度,高斯i在像素p的权重(根据协方差和屏幕位置计算,由协方差矩阵Σ'i和距离决定,见公式(1)~(2))。
- 所以整体是一个加权平均,融合多个高斯对该像素头发的预测。对覆盖像素p的所有高斯的主方向βi进行加权平均,权重由高斯的可见性和贡献度(αipTip)决定。
五、
总体含义:在训练阶段,作者使用一种基于梯度的优化方式来优化每个高斯原语的位置、方向、颜色等属性,借助多个损失函数来引导优化,使结果在外观和几何上更接近真实头发结构。
1.优化方法:
- 使用基于梯度的优化方法训练高斯模型,引用自文献【16】。
2.光度损失:
-
Lrgb:结合了L1损失和结构相似性损失(SSIM),用于约束渲像与真实图像的颜色和结构一致性;
L1损失:预测图像与真实图像逐像素的差值。
SSIM损失:结构相似性,考虑图像亮度,对比度和结构。
-
Lseg:分割损失,通过L1损失匹配渲染的头发轮廓(sp)和分割掩码(lp)与真实掩码。
-
Ldir:方向损失,监督头发方向的一致性。引入了一个渲染置信因子τp,
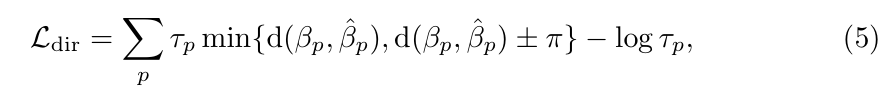
βp:预测像素p的头发方向(由高斯推导)
β^p:该像素的真是方向
d(...):表示预测方向βp与真实方向β^p之间的绝对角度差。
τp:该像素的方向置信度,来源于高斯,用于加权方向误差,并通过-logτp项防止τp过小(类似正则化),τp让高置信度的像素对方向误差影响更大。
3.总训练目标:
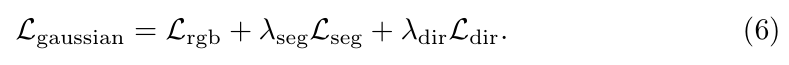
- λseg和λdir使超参数,用于平衡不同损失的贡献,用来调节各个损失的权重。
- 三个部分一起控制训练目标:
1.图像重建要准确(颜色)
2.分割要对(轮廓)
3.头发方向要准(几何结构)
3.2 3D Hair Strands Reconstruction
一、
第一阶段的结果
-
高斯模型:高斯原语(小椭球体)已经很好地拟合了发型的可见结构,高斯模型已经捕捉到发型可见部分的结构。
几何形状:头发在3D空间中的分布和轮廓,头发整体的3D体积和形状(如发束的分布、密度等)。
发丝方向:每一部分头发的生长方向和流向信息,每个局部区域的头发走向。
这些高斯模型可以理解为对头发"点云"或"体积"的初步重建,但尚未生成连续的头发丝。
-
优化的相机参数:相机的内外参数(如位姿、焦距、朝向)也被同步优化(进一步精细化),以确保渲染和投影的准确性,确保3D高斯与多视角2D观测数据(如输入图像)对齐。
第二阶段:3D头发丝重建的输入
第一阶段的输出(高斯模型+相机参数)作为第二阶段的先验信息,用于生成更精细的连续头发丝,也就是从表面点云提取出真实的头发丝结构。
二、
- 头发丝的表示:头发贴图
头发贴图H:
类似于纹理贴图,但存储的是3D发丝数据,覆盖在3D头部模型的头皮区域上。
每个纹素对应一条3D发丝,用折线表示:
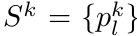
其中pkl是第k根发丝的第l个3D控制点。
头部模型对齐:
使用多视角优化(基于面部关键点【38】)将3D头部模型与场景对齐,确保头发贴图的空间准确。 - 优化挑战与正则化
自由度问题:
直接优化发丝控制点(即显式表示H)会导致参数过多(每根发丝有多个3D点),容易陷入过拟合或陷入局部最优。
潜空间表示Z:
引入潜变量头发贴图Z,通过预训练的编码器E和解码器G与显式贴图H互相转换
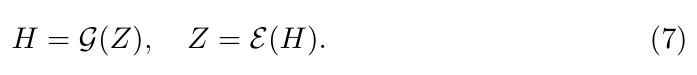
作用:
压缩发丝的高维数据到低维潜空间,减少优化变量。
利用解码器G的归纳偏置(如发型先验),约束生成的发丝结构合理。 - 两阶段优化策略
粗优化:
优化潜变量Z,解码得到显式贴图H后,直接优化H中的发丝控制点。
优势:可微调局部细节(如发梢分叉、弯曲),提升精度。
三、
-
潜变量头发贴图(Z)的解码效率问题
计算成本高:
将潜变量贴图Z解码为显式发丝贴图H是一个计算密集型操作,无法在每次优化迭代中对所有发丝执行。
粗优化阶段的策略:
仅解码部分引导发丝,记为H'。
这些引导发丝是稀疏的代表性子集,用于高效优化潜变量Z,而无需处理全部发丝。
优势:减少计算量,同时保持对整体发型结构的控制。
细优化阶段的灵活性:
一旦潜变量Z在粗优化中收敛,可解码生成任意数量的发丝(高密度),用于局部微调。
-
发型优化的约束条件
优化发丝时使用两类关键约束:
(1)光度损失
可微分光栅化
将3D发丝渲染为2D图像,与输入的多视角图像对比(通过L1、SSIM损失)。
确保渲染的发丝在颜色、阴影和几何上与真实观测一致。
(2)潜扩散正则化
引用文献【38】:
使用预训练的扩散模型约束潜变量Z,确保生成的头发符合真实发型的分布。
作用:
避免不合理的发型结构(如杂乱或穿透头皮的发丝)。
对发型内部不可见部分(如被外层头发遮挡的区域)提供先验约束,增强整体真实感。
-
高斯重建阶段提供的真值
噪声抑制:
使用第一阶段(高斯模型)生成的几何和方向场作为监督信号。
优势:
高斯模型已初步过滤了输入图像中的噪声(如遮挡、光照变化)。
为发丝优化提供更干净的初始条件,尤其是方向场,避免优化陷入局部最优。
四、
-
头发丝的高斯化表示
为了将头发丝(折线段)适配到可微分渲染框架中,每条发丝的线段
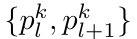
被转换为一个高斯基元,其参数定义如下:
尺度向量skl:
与线段长度成正比(即1/2*||pkl+1 - pkl||2),使高斯沿线段方向拉伸。
其他两个分量:固定为极小值e(如e=0.001),确保高斯在横截面上近似为现状(模拟细发丝)。
公式:
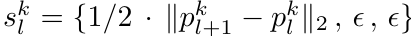
旋转四元数:
将高斯的x轴对齐到线段方向(即pkl+1 - pkl),确保高斯沿发丝方向延伸。
其他属性:
不透明度okl:设为1(完全不透明,避免透明干扰渲染)。
方向置信度τkl:设为1(完全信任预设方向)。
颜色参数fkl:通过球谐系数表示,可训练,控制光线交互后的颜色表现。
-
外观优化:两阶段训练
(a)粗优化阶段
优化参数:
隐式编码Z:表示头发的潜在特征(如形状、密度等)。
外观解码器Ga:从潜在特征Z预测球谐稀疏fkl(决定颜色)。
Ga的结构与预训练的头发丝解码器G相同,但G是固定的(基于合成数据预训练),而Ga是每场景从头训练的。
目标:通过光度损失(如渲染图像与真实图像的差异)优化Z和Ga,初步拟合头发的外观。
(b)细优化阶段
优化参数:
直接优化高斯参数H:包括位置、旋转、缩放等几何属性。
目标:进一步提升渲染细节,匹配真实外观。
-
技术动机
可微分光栅化:允许梯度回传,使几何和外观参数能通过端到端训练联合优化。
高斯建模:用拉伸的高斯分布近似头发丝的局部细节,平衡计算效率与渲染质量。
两阶段策略:粗阶段解决全局最优,细阶段优化局部细节,避免陷入局部最优。
第二遍:
(待写)
五、
- 渲染损失函数
在细优化阶段,损失函数基于高斯分布训练目标Lgaussian(来自第一阶段,公式(6)),并包含以下关键组成部分:
颜色损失Lrgb
分割损失Lseg
方向损失Ldir
传统方法可能通过高斯分布的协方差矩阵提取方向(βi),但此处直接利用线段方向向量vkl=pkl+1 - pkl(即头发丝生长方向),因为细优化阶段抑制头发丝的精确走向,无需依赖统计估计。 - 粗优化阶段的挑战与解决方案
问题:内存限制导致几何"空洞"
在粗优化阶段,受内存限制,每次训练批次只能从潜在编码Z解码少量引导头发丝H'。
直接渲染稀疏的H'会导致生成的几何体存在空洞,使得光度损失(如Lrgb)无法有效优化(因缺失区域无法计算梯度)。
解决方案:引导头发丝插值
稠密化处理:通过插值算法将稀疏的H'转换为稠密头发丝H^,再用于光栅化渲染。
插值方法基于文献【39】,但改进为直接在3D坐标空间(而非潜在空间)进行插值,保留几何一致性。
插值后,稠密的H^填补了空洞,使光度损失可正常计算。
细阶段的优化无需插值:因此时已直接优化完整的稠密头发几何H,无需稀疏------稠密转换。 - 技术动机与优势:
方向向量的直接利用:
细阶段已知头发生长方向(vkl),比协方差矩阵估计的方向更准确,减少优化噪声。
插值的必要性:
粗阶段的内存限制是瓶颈,插值是一种计算高效的妥协,确保训练稳定性。
两阶段分工:
粗阶段:通过插值解决全局结构(低分辨率)。
细阶段:直接优化高分辨率几何(无需近似)。
六、
-
核心目标
通过扩散模型的先验知识(如预训练的潜在扩散模型)对头发几何进行正则化,确保生成的头发既符合真实物理形态(如自然流线、疏密分布),又能避免人工优化的不合理结构(如交叉、杂乱)。
-
关键方法
(a)分数蒸馏采样(SDS)
作用:从预训练的扩散模型中提取"知识",作为优化过程的指导信号(即损失函数Lsds)。
实现:在潜在空间中计算损失,而非直接处理3D几何数据(如点云或网格)。
参考文献:基于文献【30】的SDS方法和文献【38】的头发生成框架。
(b)潜在扩散模型
输入输出:操作对象是潜在头发图Z,一种低维压缩表示。
预训练模型:使用现成的扩散模型(如【38】中的模型,无需重新训练)。
-
两阶段优化流程
(a)粗优化阶段
操作:直接对潜在头发图的降采样版本Z'应用SDS损失Lsds。
目的:快速优化头发的整体形状和密度分布(低分辨率约束)。
(b)细优化阶段
问题:细粒度优化(如单根发丝)无法直接应用低分辨率Z'的损失。
解决方案:
随机采样:每一步选择一部分头发丝。
编码到潜在空间:用预训练编码器E将这些发丝转换为潜在表示。
插值到统一分辨率:将潜在表示插值为与Z'相同分辨率的纹理。
扩散惩罚:对插值后的低分辨率潜在图施加SDS损失(与粗阶段一致)。
优势:在细粒度优化中保持扩散模型的全局约束,避免局部过拟合。
-
技术细节
潜在空间操作的意义:
避免高维几何数据(如千万级发丝)直接优化带来的计算负担。
利用扩散模型在压缩空间中的生成能力。
动态子采样与插值:
细阶段通过随机采样和插值,将高维发丝"投影"到低维潜在空间,实现多尺度优化。
-
总结
贡献:将扩散模型的生成先验(通过SDS损失)嵌入到头发几何优化的全流程(粗+细阶段),兼顾效率与质量。
创新点:
粗阶段:直接约束低分辨率潜在表示。
细阶段:通过动态编码------插值,将高维发丝"对齐"到低维扩散空间。
依赖条件:需预训练的编码器E和潜在扩散模型(来自【38】)。