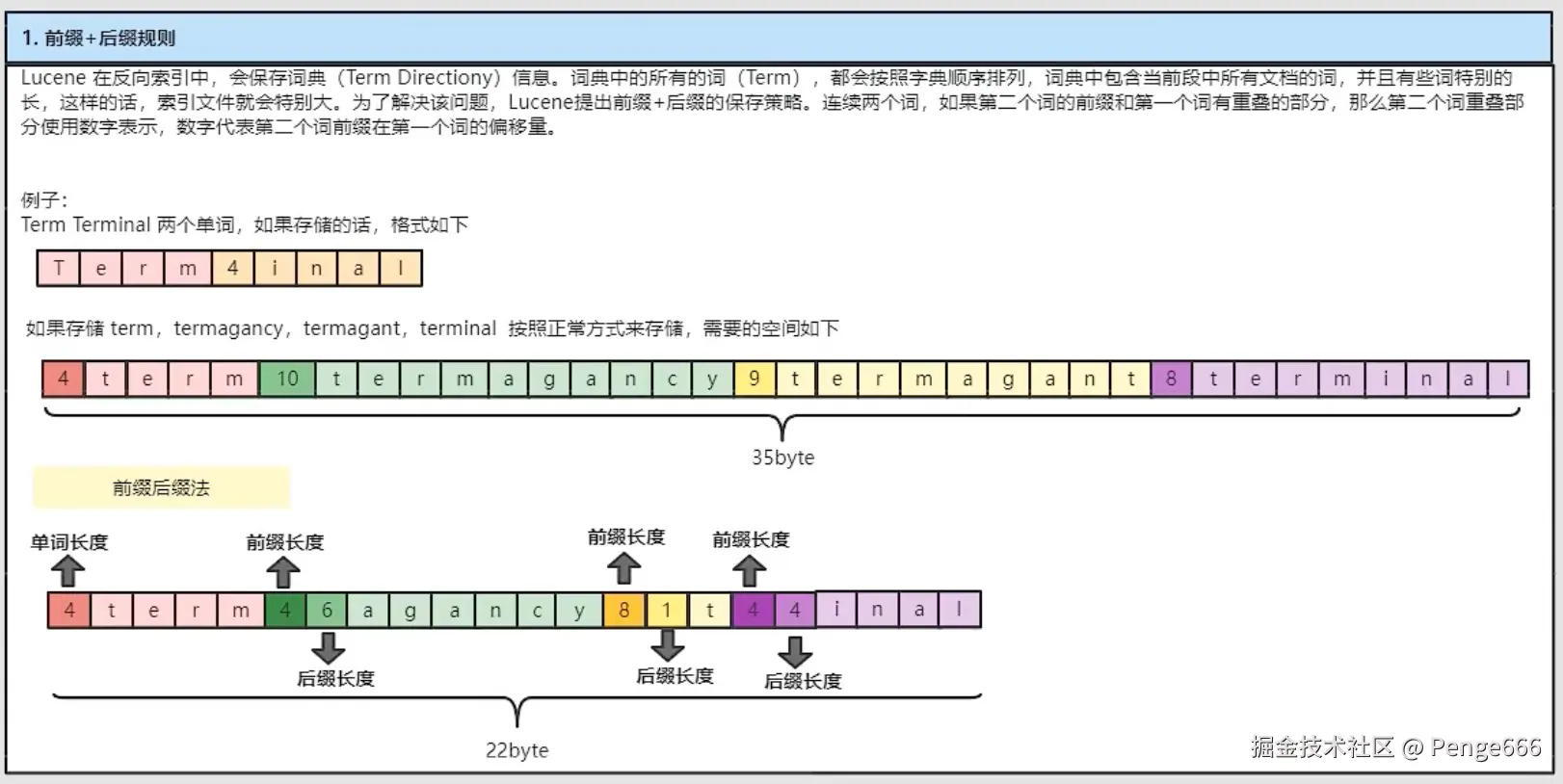
索引(Index) --> 段(segment) --> 文档(Document) --> 域(Field) --> 词(Term)
一、最外层概念:Index(索引)
- 定义 :
逻辑上的 "索引",对应磁盘上的一组文件集合,包含多个 Segment(段)和元数据文件。 - 作用 :
把分散的 Segment 组织起来,对外提供统一的 "搜索入口"。 - 类比 :
像一本书的 "目录",指引搜索引擎找到具体的 Segment(章节)。
二、核心概念:Segment(段)
-
定义 :
索引的最小物理存储单元,是一组不可变的文件(一旦生成,内容不修改)。
-
特点:
- 不可变性:写入后内容固定,保证查询时不会因数据变更而混乱;
- 并行查询:多个 Segment 可并行搜索,提升查询性能;
- 分层合并 :老 Segment 会定期合并(如
forceMerge),减少文件数量,优化查询效率。
-
类比 :
一本书的 "章节",每个章节独立存储内容,但共同组成整本书(索引)。
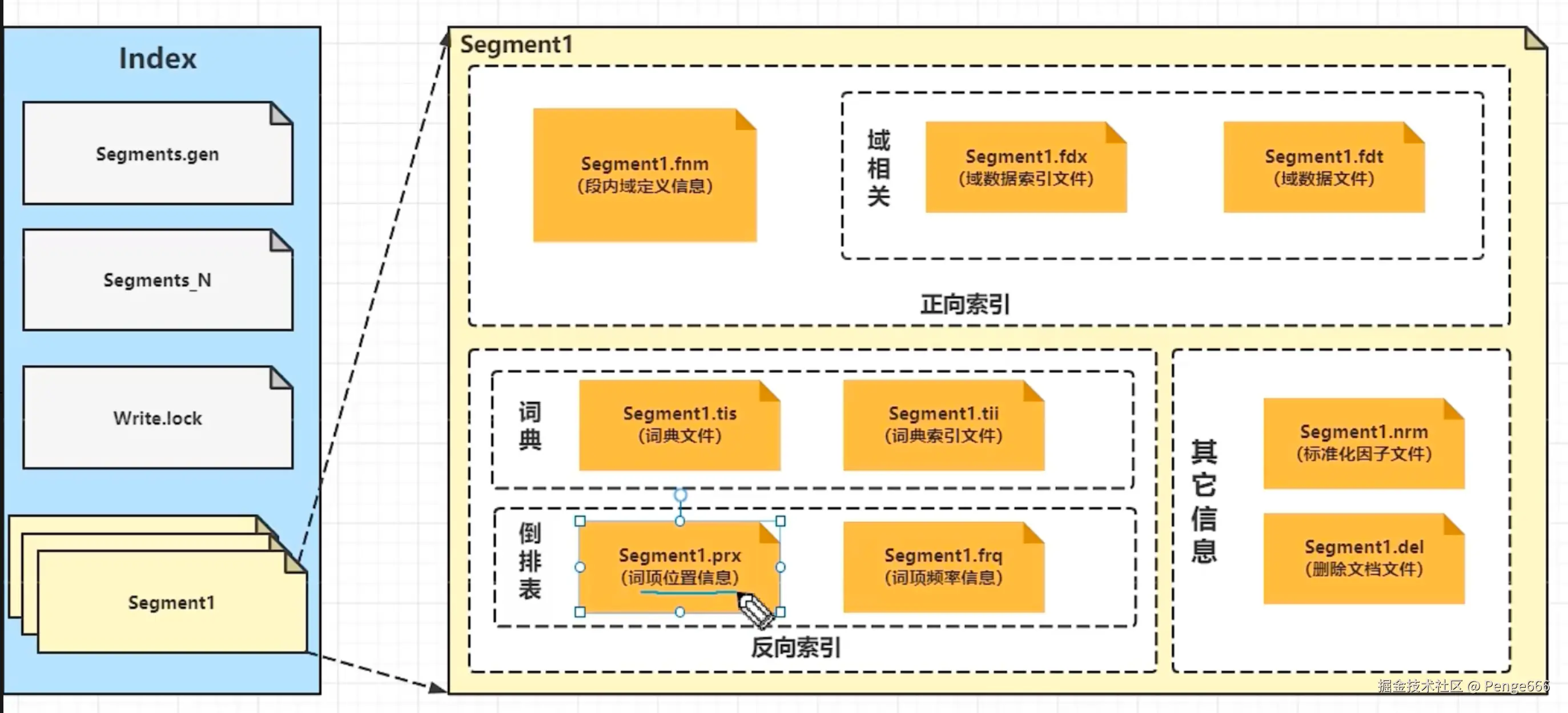
三、Segment 内的文件分类
1. 元数据文件(Index 层)
-
Segments.gen/Segments_N:记录索引中所有 Segment 的元数据(如 Segment 数量、每个 Segment 的文档数、物理文件位置 )。
- 作用:搜索引擎启动时,通过这些文件快速加载索引结构,知道有哪些 Segment 可用。
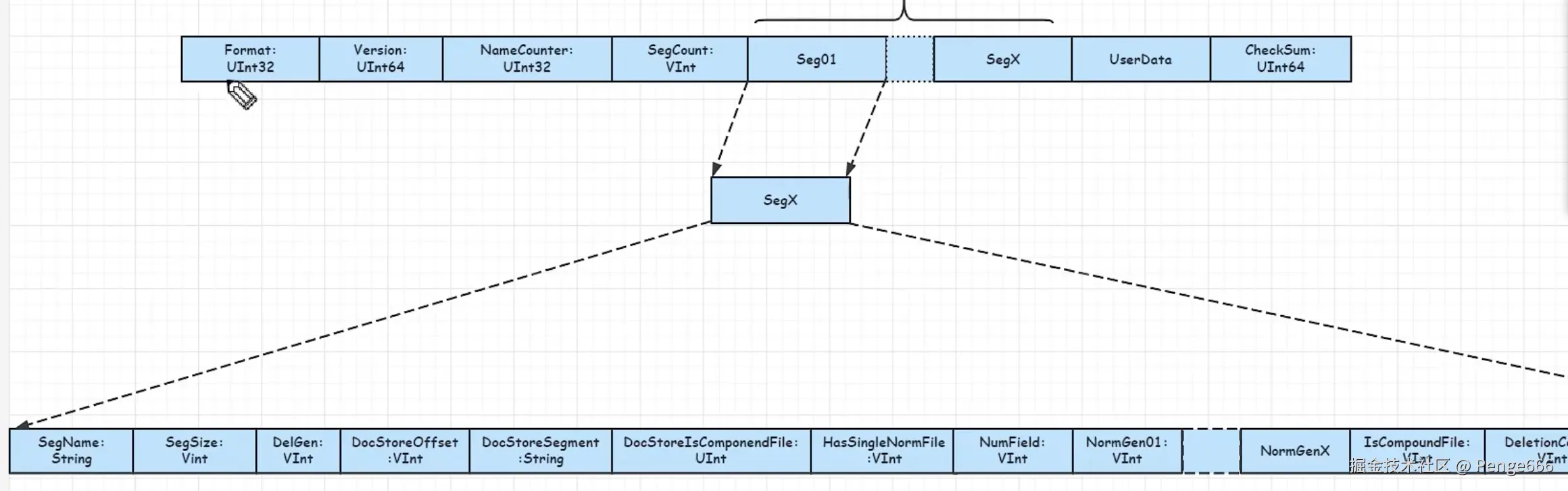
| 层级 | 字段名 | 数据类型 | 作用说明 | 关联场景 / 示例 |
|---|---|---|---|---|
| Segments_N 文件头 | Format |
UInt32 |
标记 Segments 文件格式版本,保障不同 Lucene 版本间兼容性 | 新版 Lucene 读取旧版索引时,校验格式 |
Version |
UInt64 |
记录索引创建时的 Lucene 版本,用于兼容性判断 | 高版本识别低版本索引,决定是否升级 | |
NameCounter |
UInt32 |
Segment 名称计数器,确保新 Segment 命名唯一 | 下一个 Segment 名依据此值生成(如 _5) |
|
SegCount |
VInt |
索引中 Segment 的总数量 | 快速知晓索引包含的 Segment 规模 | |
| Segment 列表 | Seg01/SegX(元数据块) |
- | 存储单个 Segment 的核心元数据,关联下方 SegX 详细结构 |
索引加载时,逐个解析 Segment 信息 |
| 扩展信息 | UserData |
String |
开发者自定义元数据,可存索引描述、创建时间等 | 附加业务信息,不影响 Lucene 核心逻辑 |
CheckSum |
UInt64 |
校验和,检测 Segments 文件是否损坏 | 加载索引时验证文件完整性 | |
| SegX 详细结构 | SegName |
String |
Segment 的唯一名称(如 _0、_1),关联磁盘文件 |
定位 Segment 对应的物理文件(_0.fdt) |
SegSize |
VInt |
Segment 包含的文档总数(含逻辑删除文档) | 查询时快速了解 Segment 数据量 | |
DelGen |
VInt |
删除版本号,>0 表示有逻辑删除文档 |
标记 Segment 是否有删除操作 | |
DocStoreOffset |
VInt |
文档存储偏移量,指向 .doc 文件中该 Segment 数据位置 |
读取文档原始内容时,快速定位数据 | |
DocStoreSegment |
String |
文档存储关联的 Segment 名称(复合文件场景用) | 复合文件模式下,关联存储位置 | |
DocStoreIsComponentFile |
UInt |
标记是否为复合文件的一部分(1 是,0 否) |
区分文件存储模式 | |
HasSingleNormFile |
VInt |
标记是否有单独的 Norm 文件(存储文档标准化因子) | 决定 Norm 数据的读取方式 | |
NumField |
VInt |
Segment 包含的字段总数 | 解析字段映射时使用 | |
NormGen01/NormGenX |
VInt |
各字段的 Norm 文件版本号,记录 Norm 数据生成版本 | 校验 Norm 数据有效性 | |
IsCompoundFile |
VInt |
标记是否为复合文件(1 是,0 否),复合文件将多个 Segment 文件合并 |
影响文件读取策略(复合 / 分散) | |
DeletionCount |
VInt |
Segment 中逻辑删除的文档数量 |
Write.lock:
写入锁文件,保证同一时间只有一个写入操作(避免 Segment 文件冲突)。
2. Segment 内的文件(重点!)
Segment 内的文件分为 "正向索引" 和 "反向索引(倒排索引)" 两部分,对应 Lucene 的核心原理。
(1)正向索引(文档→词项)
-
定义 :
以文档(Document) 为中心,记录 "文档包含哪些词项(Term)",以及词项在文档中的位置、频率等信息。
-
文件组成(域相关):
-
Segment1.fnm(段内域定义信息):记录当前 Segment 包含的字段(域,Field) 信息(如字段名称、类型、是否分词 )。 Lucene源码系列(二十九):fnm索引文件格式
- 作用:搜索时快速判断 "哪些字段需要参与查询"。
-
Segment1.fdx(域数据索引文件) +Segment1.fdt(域数据文件):存储文档的原始内容(按字段组织)。
fdx是索引,指向fdt中具体文档的位置;fdt存储文档的字段数据(如标题、正文)。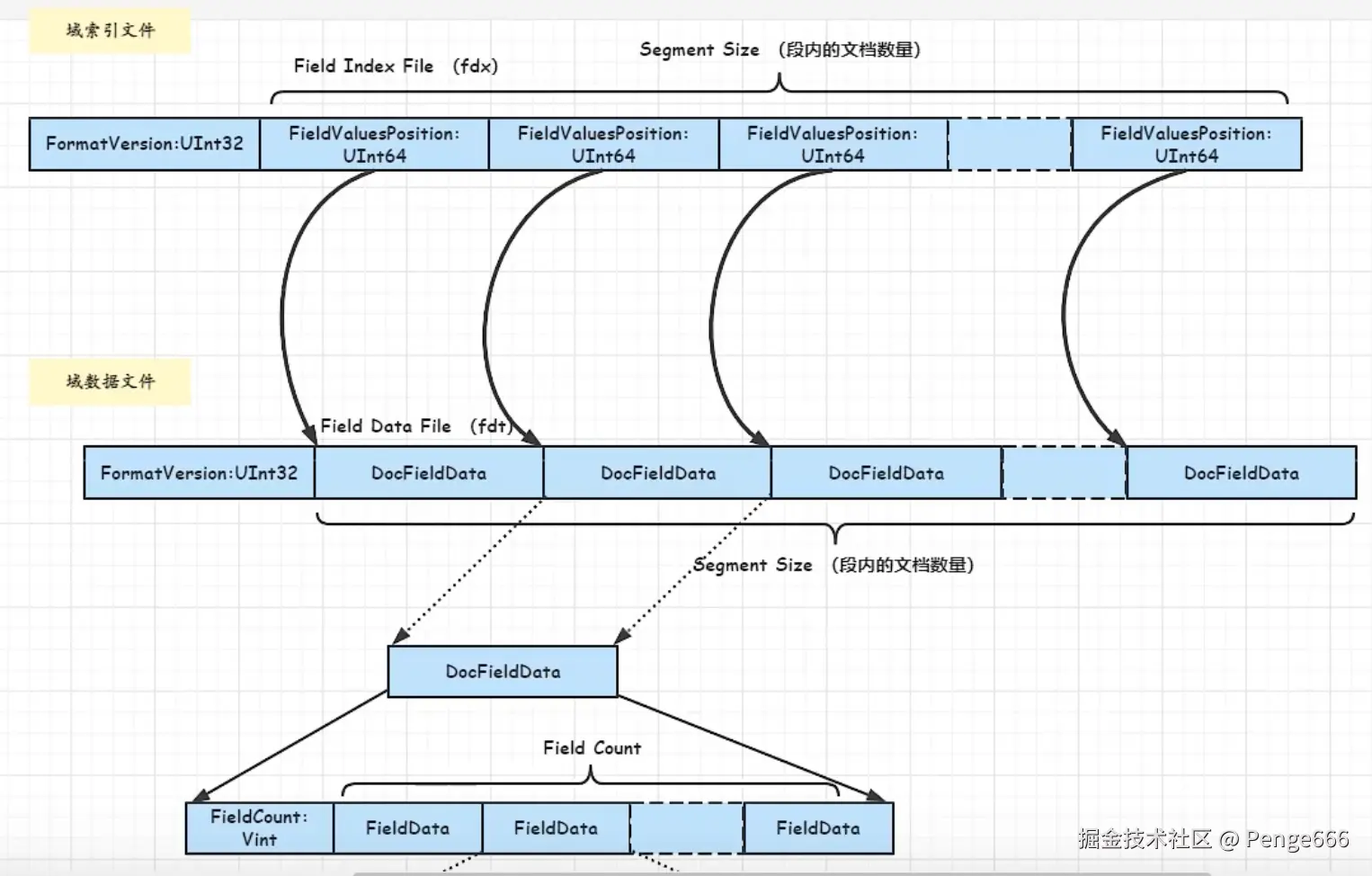
-
作用:
当需要获取 "文档原始内容"(如搜索结果展示标题、摘要 )时,通过正向索引快速读取。
-
(2)反向索引(词项→文档)
-
定义 :
以词项(Term) 为中心,记录 "哪些文档包含这个词项",以及词项在文档中的位置、频率等信息。
- 这是 Lucene 实现快速全文搜索的核心(先找词项,再关联文档)。
-
文件组成(词典 + 倒排表):
-
词典(Term Dictionary) :
-
Segment1.tis(词典文件) +Segment1.tii(词典索引文件):存储所有去重后的词项(如文档中的 "苹果""手机""好吃" ),并按字典序排序。
tii是词典的 "索引",加速词项查找(类似书的目录,快速定位词项位置);tis存储实际的词项列表。
-
作用:搜索时,先在词典中查找 "用户输入的关键词" 是否存在,存在则进入倒排表找文档。
-
-
倒排表(Postings List) :
-
Segment1.prx(词项位置信息) +Segment1.frq(词项频率信息):记录每个词项对应的文档列表 ,以及词项在文档中的位置(
prx)、出现频率(frq)。- 例:词项 "苹果" 的倒排表可能包含:
文档1(位置:标题第3个词,频率:2次)、文档2(位置:正文第5个词,频率:1次)。
- 例:词项 "苹果" 的倒排表可能包含:
-
作用:通过词项快速找到所有包含它的文档,结合位置、频率计算相关性得分(如 TF-IDF )。
-
-
(3)其他信息文件
-
Segment1.nrm(标准化因子文件) :存储文档的标准化因子(如长度归一化值),用于计算相关性得分(避免长文档因词项多而得分过高 )。
-
Segment1.del(删除文档文件) :记录当前 Segment 中被标记为删除的文档(因为 Segment 不可变,删除操作只是逻辑标记,实际文件不删除 )。
- 作用:查询时跳过这些已删除的文档,保证结果准确性。
四、搜索流程如何用到这些文件?
以 "搜索关键词 苹果手机" 为例,流程如下:
-
加载索引元数据 :
通过
Segments.gen/Segments_N找到所有可用的 Segment。 -
查询反向索引:
- 在 Segment 的
tii/tis(词典)中查找 "苹果""手机"; - 找到词项后,通过
prx/frq(倒排表)获取包含这些词项的文档列表。
- 在 Segment 的
-
计算相关性得分 :
结合
nrm(标准化因子)、frq(词频)等信息,计算每个文档与查询的相关性得分。 -
获取文档内容 :
通过
fdx/fdt(正向索引)读取文档的原始内容(如标题、正文),用于搜索结果展示。 -
跳过删除文档 :
检查
del文件,过滤已删除的文档。
五、为什么要这样设计?
-
不可变 Segment:保证查询时数据稳定,支持并行查询(多个 Segment 同时搜索),提升性能。
-
正向 + 反向索引:
- 反向索引实现 "快速查词→文档",是全文搜索的核心;
- 正向索引补充 "文档原始内容",满足结果展示需求。
-
分层文件结构:通过元数据文件、词典索引、倒排表索引,逐层缩小查询范围,避免全量扫描,实现毫秒级搜索。
补充
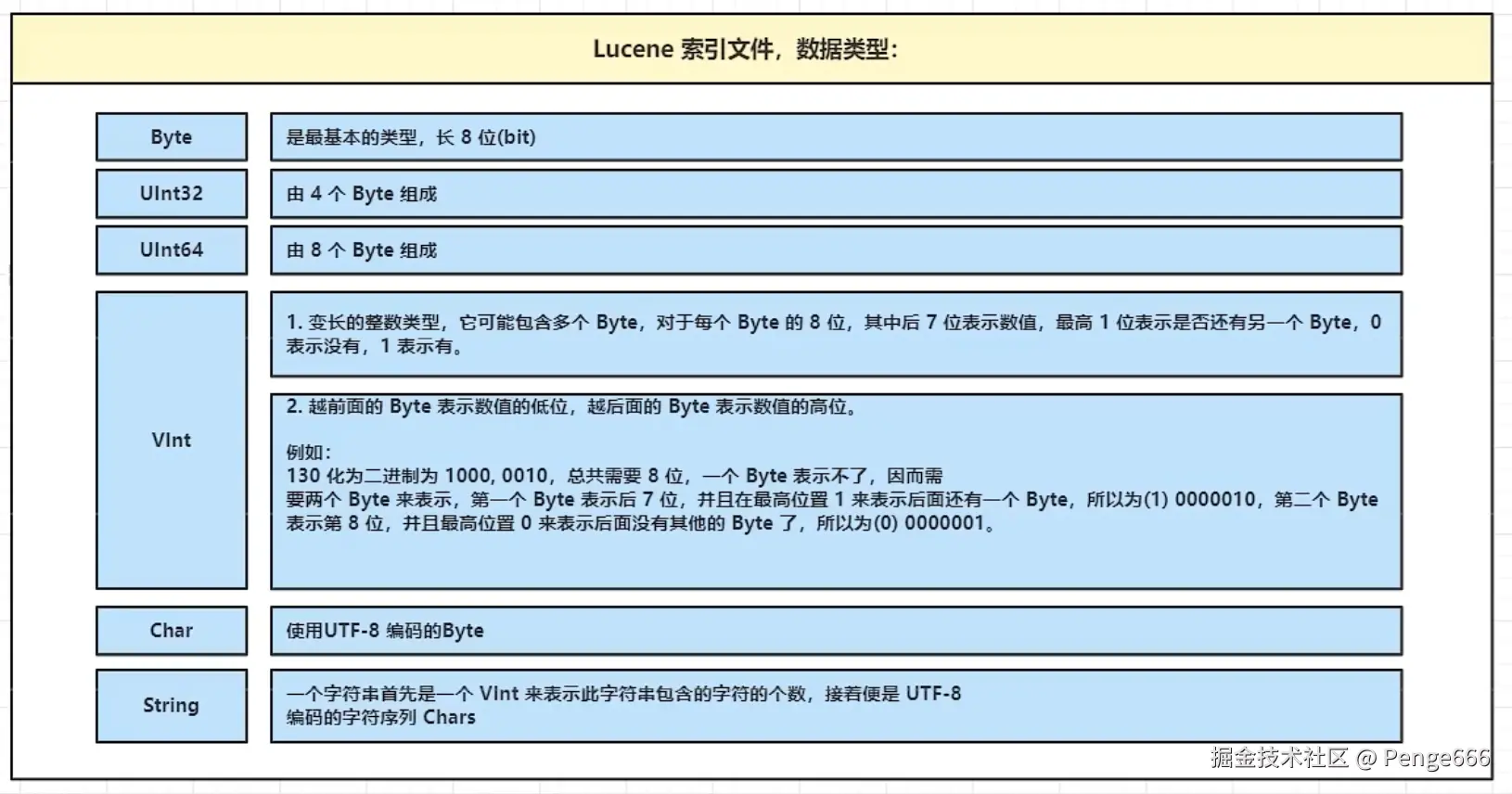
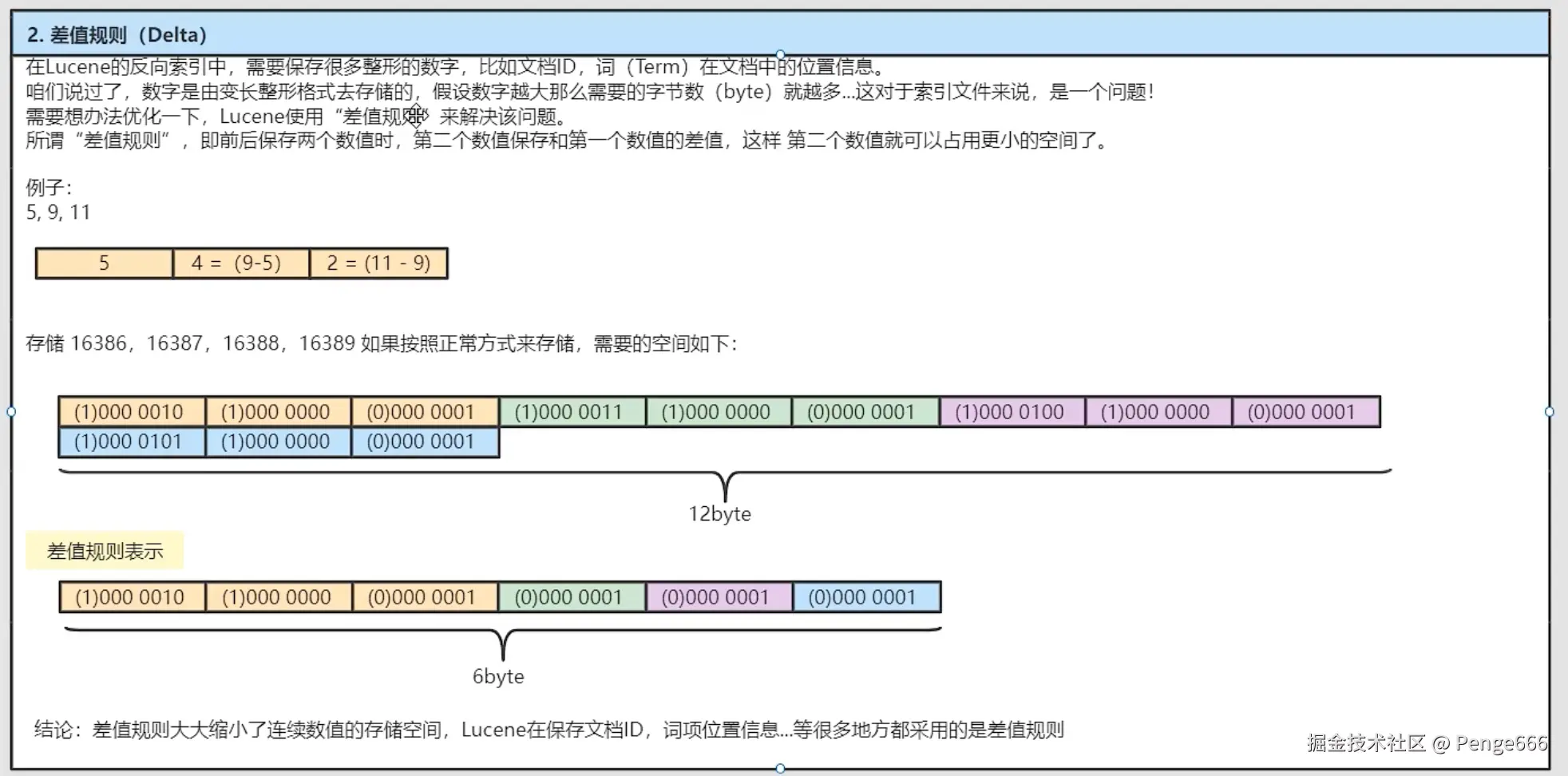
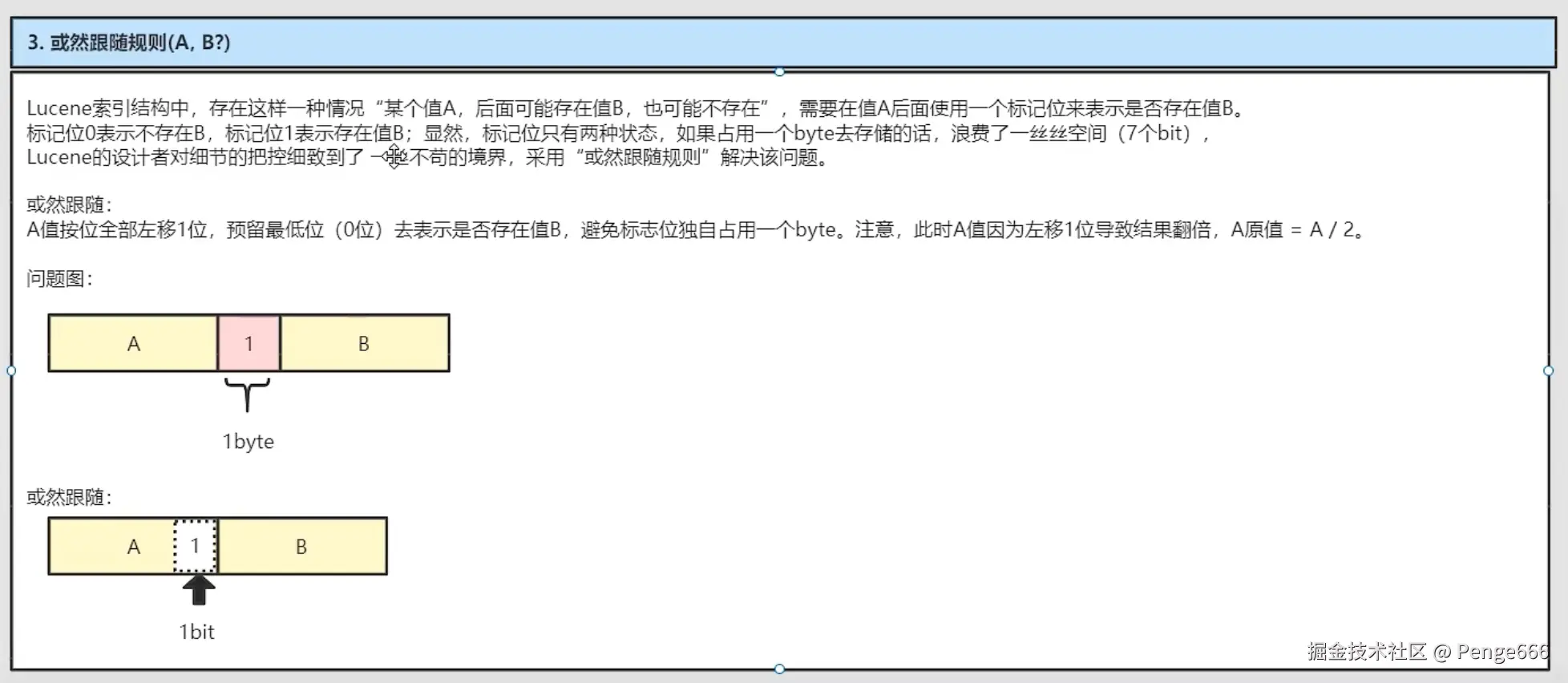
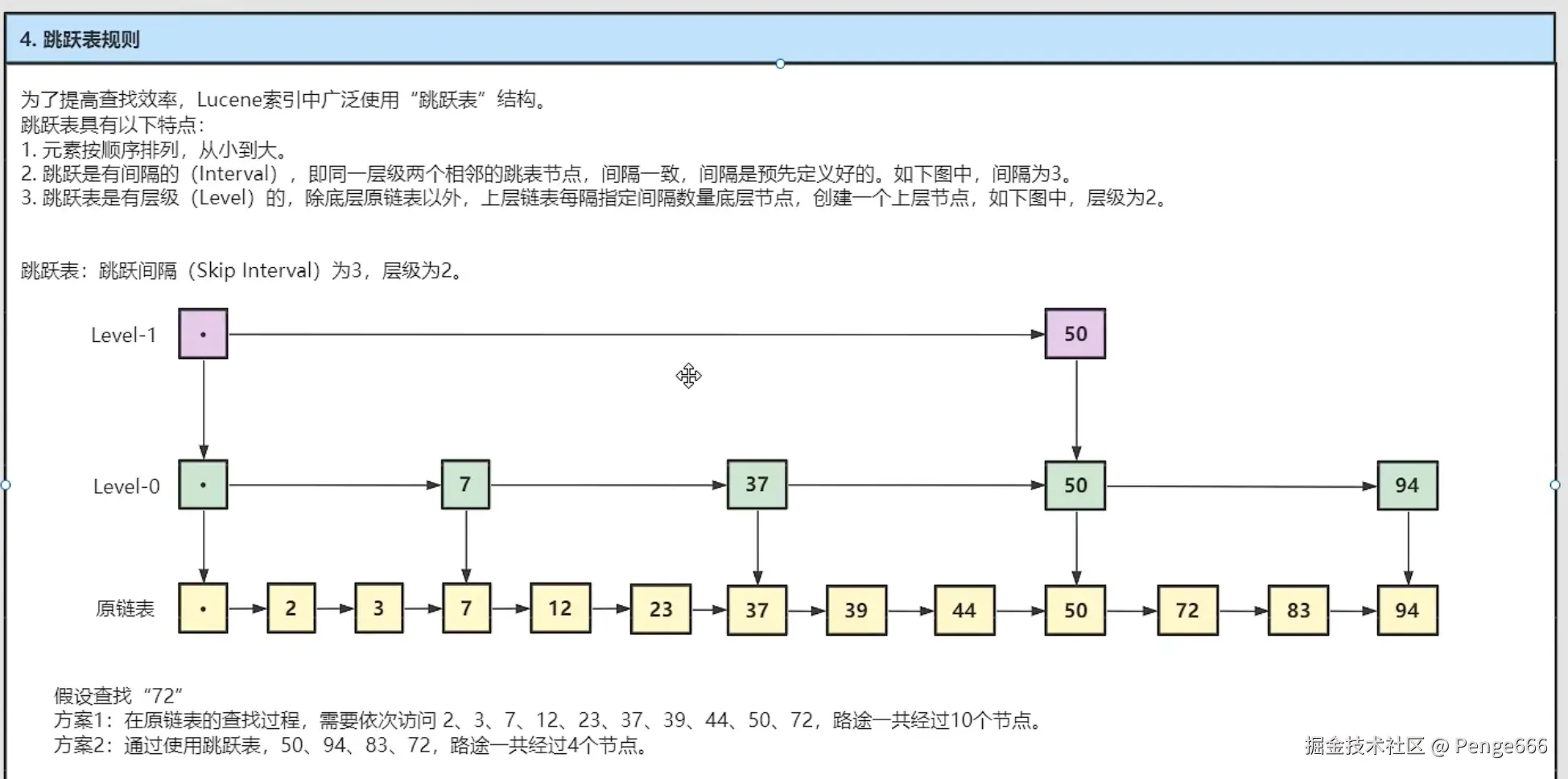
编码规则
优化索引