大家好,这里是架构资源栈 !点击上方关注,添加"星标",一起学习大厂前沿架构!
关注、发送C1即可获取JetBrains全家桶激活工具和码!

随着 AI 编程助手不断演进,开发者正在寻找既强大又可本地部署的解决方案。由 Mistral AI 和 All Hands AI 联合打造的 Devstral-Small-2507 正是这样一款专为开发者设计的大模型 ------ 不仅支持 128k 上下文窗口,还可在高端 PC 或 Mac 上本地运行,并登顶 SWE-Bench 编程能力排行榜。本篇文章将手把手教你如何在本地环境中部署 Devstral Small 1.1,并打造属于自己的 AI 编程助手。
✨ Devstral Small 1.1 有何亮点?
- 🧠 强大的上下文处理能力:128k tokens
- 🛠️ 面向工程:可理解复杂代码、执行多文件编辑
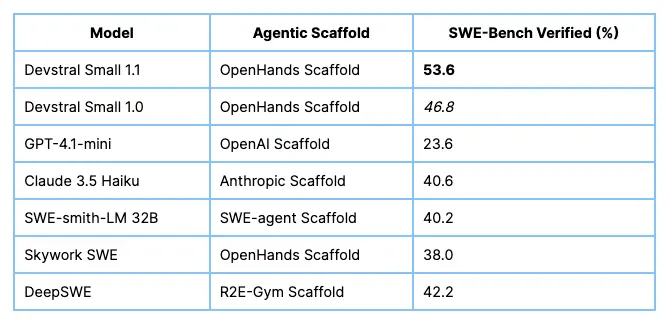
- 📈 性能卓越:SWE-Bench Verified 得分 53.6%,击败前代模型 Devstral Small 1.0 和所有公开模型
- 💡 多语言支持:识别 24 种语言
- 🖥️ 支持本地 GPU:无需依赖云平台即可运行
🚀 环境部署前准备
我们将在 GPU 环境中运行 Devstral 模型。教程基于 NodeShift 云平台,但你也可以选择任何支持 GPU 的本地或云平台。本文演示使用以下 Docker 镜像:
bash
nvidia/cuda:12.1.1-devel-ubuntu22.04该镜像预装完整 CUDA 工具链,适用于 vLLM 推理框架。
🛠️ 步骤 1:创建 GPU 虚拟机
在 NodeShift 或其他云服务商上选择支持 CUDA 的 GPU,如 H100、A100、L40 等,并启动交互式 shell 容器。推荐配置:
- GPU: H100 (或 VRAM ≥ 40GB)
- 镜像:
nvidia/cuda:12.1.1-devel-ubuntu22.04 - 认证方式: SSH 密钥
🧩 步骤 2:安装 Miniconda 与 Python 环境
bash
# 更新系统并安装 wget
sudo apt update && sudo apt install wget -y
# 下载并安装 Miniconda
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.sh安装后激活 conda 并创建 Python 环境:
bash
export PATH="/root/miniconda3/bin:$PATH"
conda init
exec "$SHELL"
# 创建 Python 3.11 环境
conda create -n devstral python=3.11 -y
conda activate devstral📦 步骤 3:安装依赖库
bash
pip install torch
pip install git+https://github.com/huggingface/transformers
pip install git+https://github.com/huggingface/accelerate
pip install huggingface_hub
pip install --upgrade vllm
pip install --upgrade mistral_common chal然后登录 Hugging Face 以获取模型访问权限:
bash
huggingface-cli login访问 huggingface.co/settings/to... 获取你的访问令牌。
🔧 步骤 4:安装指定版本 transformers 与 tokenizers
为避免兼容性问题,需使用以下固定版本:
bash
pip install transformers==4.51.1 tokenizers==0.21.1验证安装:
bash
python -c "import transformers; print(transformers.__version__)"
python -c "import tokenizers; print(tokenizers.__version__)"
python -c "import vllm; print(vllm.__version__)"
python -c "import mistral_common; print(mistral_common.__version__)"输出版本应为:
makefile
transformers: 4.51.1
tokenizers: 0.21.1
vllm: 0.9.2
mistral_common: 1.7.0🧠 步骤 5:启动 Devstral 小模型服务
bash
vllm serve mistralai/Devstral-Small-2507 \
--tokenizer_mode mistral \
--config_format mistral \
--load_format mistral \
--tool-call-parser mistral \
--enable-auto-tool-choice \
--tensor-parallel-size 1启动成功后,模型 API 可通过如下路径访问:
/v1/chat/completions/v1/completions/v1/embeddings
🌐 步骤 6:构建 Gradio Web 界面(可选)
安装 Gradio 和 requests:
bash
pip install gradio requests创建 devstral_demo.py:
python
import gradio as gr
import requests
VLLM_SERVER_URL = "http://localhost:8000/v1/completions"
def chat_with_devstral(prompt, temperature=0.2, max_tokens=1024):
headers = {"Content-Type": "application/json", "Authorization": f"Bearer token"}
payload = {
"model": "mistralai/Devstral-Small-2507",
"prompt": prompt,
"max_tokens": max_tokens,
"temperature": temperature,
}
response = requests.post(VLLM_SERVER_URL, headers=headers, json=payload)
return response.json().get("choices", [{}])[0].get("text", "⚠️ No response")
gr.Interface(
fn=chat_with_devstral,
inputs=[gr.Textbox(lines=4), gr.Slider(0, 1, value=0.2), gr.Slider(128, 4096, step=128)],
outputs="text",
title="💻 Devstral-Small-2507 AI 编程助手"
).launch(server_name="0.0.0.0", server_port=7860)运行脚本:
bash
python3 devstral_demo.py浏览器访问:http://localhost:7860
📡 步骤 7:使用 Python 脚本测试模型
创建 app.py:
python
import requests, json
url = "http://127.0.0.1:8000/v1/chat/completions"
headers = {"Content-Type": "application/json"}
messages = [
{"role": "system", "content": "You are Devstral, an expert software engineer."},
{"role": "user", "content": "Refactor this Python function:\ndef foo(x): return [i*2 for i in x if i%2==0]"},
]
data = {"model": "mistralai/Devstral-Small-2507", "messages": messages, "temperature": 0.15}
res = requests.post(url, headers=headers, data=json.dumps(data))
print(res.json()["choices"][0]["message"]["content"])执行:
bash
python3 app.py✅ 示例:快速测试 FastAPI 接口生成
Prompt:
css
Write a minimal FastAPI app with an endpoint `/greet` that returns a greeting message based on a `name` parameter.预期输出:
python
from fastapi import FastAPI
app = FastAPI()
@app.get("/greet")
def greet(name: str):
return {"message": f"Hello, {name}!"}🧠 总结:为什么值得本地部署 Devstral Small?
- 🧩 全流程控制:无需依赖云端,数据安全可控
- 🔧 可定制性强:可与 OpenHands、Gradio 等工具深度集成
- 📊 实测表现卓越:在真实开发场景中具备实用性与可靠性
- 🧙 开发者友好:理解多语言、支持自动工具调用、适配大代码上下文
现在,你已经成功将 Devstral Small 1.1 部署在本地 GPU 环境中!欢迎探索更多高级用法,将其集成到代码审查、PR 生成、Refactor 自动化等开发流程中。
如果这篇文章对你有帮助的话,别忘了【在看】【点赞】支持下哦~
原文地址:mp.weixin.qq.com/s/5JSAqOBrt...
本文由博客一文多发平台 OpenWrite 发布!