文章目录
- [1 介绍](#1 介绍)
- [2 快速入门](#2 快速入门)
-
- 1_引入依赖
- [2 配置模型](#2 配置模型)
- [3 配置客户端](#3 配置客户端)
- [4 测试](#4 测试)
- [3 会话日志](#3 会话日志)
-
- 1_Advisor
- [2 添加日志Advisor](#2 添加日志Advisor)
- [4 会话记忆](#4 会话记忆)
-
- 1_定义会话存储方式
- [2 配置会话记忆Advisor](#2 配置会话记忆Advisor)
- [5 会话历史](#5 会话历史)
-
- 1_管理会话历史
- [2 保存会话id](#2 保存会话id)
- [3 查询会话历史](#3 查询会话历史)
- [6 后续](#6 后续)
1 介绍
SpringAI整合了全球(主要是国外)的大多数大模型,而且对于大模型开发的三种技术架构都有比较好的封装和支持,开发起来非常方便。
不同的模型能够接收的输入类型、输出类型不一定相同,SpringAI 根据模型的输入和输出类型不同对模型进行了分类:
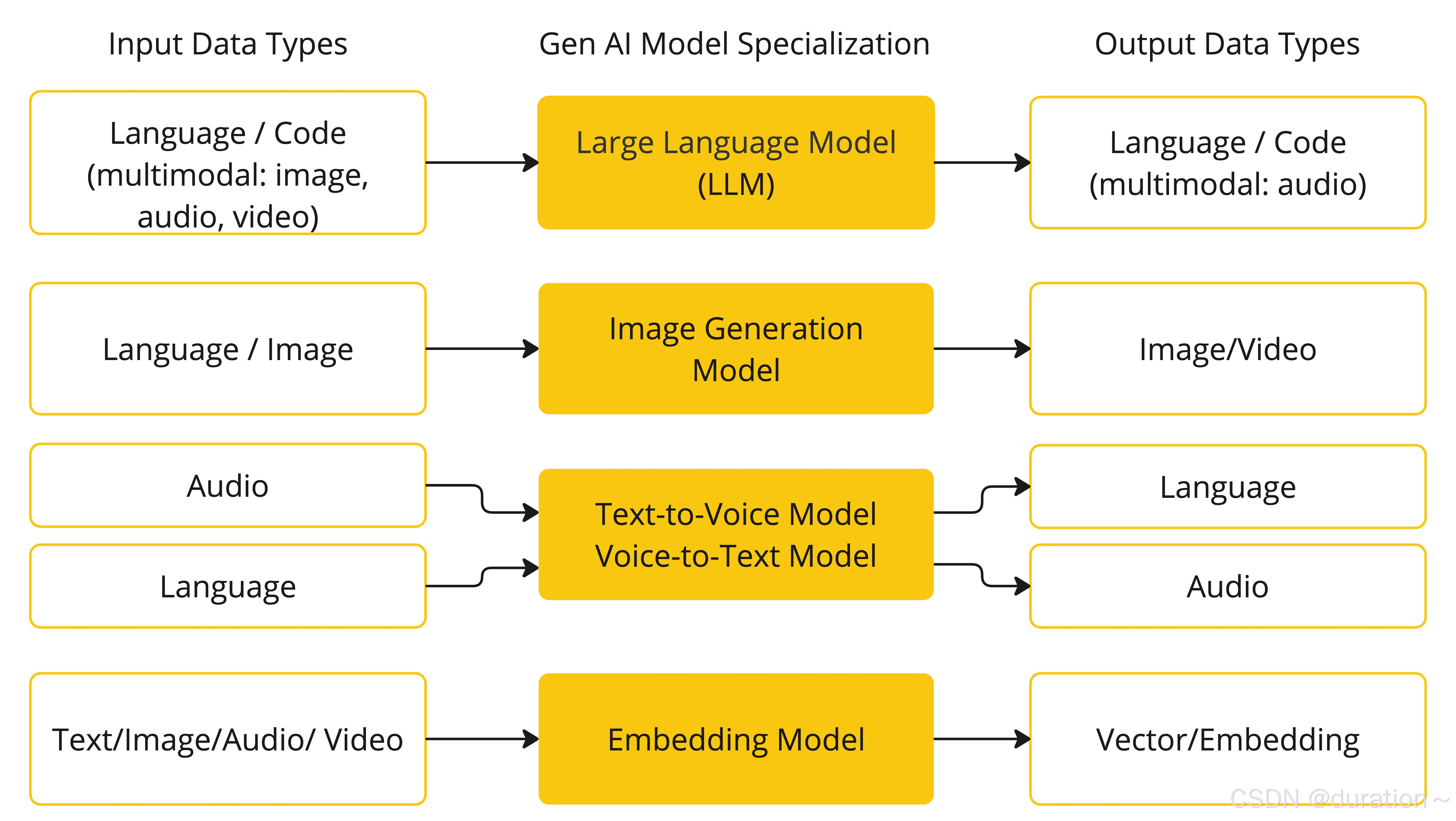
大模型应用开发大多数情况下使用的都是基于对话模型(Chat Model),也就是输出结果为自然语言或代码的模型。
官网文档:https://docs.spring.io/spring-ai/reference/
1_大模型对比
目前 SpringAI 支持的大约 19 种对话模型,以下是一些功能对比:
| Provider | Multimodality | Tools/Functions | Streaming | Retry | Built-in JSON | Local | OpenAI API Compatible |
|---|---|---|---|---|---|---|---|
| Anthropic Claude | text, pdf, image | ✔ | ✔ | ✔ | ❌ | ❌ | ❌ |
| Azure OpenAI | text, image | ✔ | ✔ | ✔ | ✔ | ❌ | ✔ |
| DeepSeek (OpenAI-proxy) | text | ❌ | ✔ | ✔ | ✔ | ✔ | ✔ |
| Google VertexAI Gemini | text, pdf, image, audio, video | ✔ | ✔ | ✔ | ✔ | ❌ | ✔ |
| Groq (OpenAI-proxy) | text, image | ✔ | ✔ | ✔ | ❌ | ❌ | ✔ |
| HuggingFace | text | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ |
| Mistral AI | text, image | ✔ | ✔ | ✔ | ✔ | ❌ | ✔ |
| MiniMax | text | ✔ | ✔ | ✔ | ❌ | ❌ | ❌ |
| Moonshot AI | text | ✔ | ✔ | ✔ | ❌ | ❌ | ❌ |
| NVIDIA (OpenAI-proxy) | text, image | ✔ | ✔ | ✔ | ❌ | ❌ | ✔ |
| OCI GenAI/Cohere | text | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ |
| Ollama | text, image | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ |
| OpenAI | In: text, image, audio Out: text, audio | ✔ | ✔ | ✔ | ✔ | ❌ | ✔ |
| Perplexity (OpenAI-proxy) | text | ❌ | ✔ | ✔ | ❌ | ❌ | ✔ |
| QianFan | text | ❌ | ✔ | ✔ | ❌ | ❌ | ❌ |
| ZhiPu AI | text | ✔ | ✔ | ✔ | ❌ | ❌ | ❌ |
| Watsonx.AI | text | ❌ | ✔ | ❌ | ❌ | ❌ | ❌ |
| Amazon Bedrock Converse | text, image, video, docs (pdf, html, md, docx ...) | ✔ | ✔ | ✔ | ❌ | ❌ | ❌ |
其中功能最完整的就是OpenAI和Ollama平台的模型了。
2_开发框架对比
Spring Ai VS LangChain4j:
| 功能项 | Spring AI | LangChain4j |
|---|---|---|
| Chat | 支持 | 支持 |
| Function | 支持 | 支持 |
| RAG | 支持 | 支持 |
| 对话模型 | 15+ | 15+ |
| 向量模型 | 10+ | 15+ |
| 向量数据库 | 15+ | 20+ |
| 多模态模型 | 5+ | 1 |
| JDK | 17 | 8 |
2 快速入门
以快速开发一个对话机器人为例。
1_引入依赖
首先,在项目中添加 spring-ai 的版本信息:
xml
<spring-ai.version>1.0.0</spring-ai.version>然后,添加 spring-ai 的依赖管理项:
xml
<!--所有spring-ai的包管理-->
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>${spring-ai.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>最后,引入 spring-ai-ollama 的依赖:
xml
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-ollama</artifactId>
</dependency>还有一些其它模型的依赖坐标:https://docs.spring.io/spring-ai/reference/api/chat/comparison.html
2 配置模型
配置属性如下,会自动向 IOC 注入一个 Ollama 的对话模型
yaml
spring:
ai:
ollama:
base-url: http://192.168.200.129:11434 # ollama服务地址, 这就是默认值
chat:
model: deepseek-r1:1.5b # 模型名称
options:
temperature: 0.8 # 模型温度,影响模型生成结果的随机性,越小越稳定3 配置客户端
客户端类型为 ChatClient,通过配置客户端可以向大模型发起请求。
ChatClient 中封装了与大模型对话的各种 API,同时支持同步式或响应式交互。
java
@Bean
public ChatClient chatClient(OllamaChatModel model){//模型也可以是 openAI
return ChatClient.builder(model)// 创建ChatClient工厂
.defaultSystem("系统提示词,支持文件的形式").build();// 构建ChatClient实例
}代码解读:
- ChatClient.builder:会得到一个
ChatClient.Builder工厂对象,利用它可以自由选择模型、添加各种自定义配置; - OllamaChatModel:如果引入了 ollama 的 starter,这里就可以自动注入 OllamaChatModel 对象。同理,OpenAI 也是一样的用法。
- defaultSystem:用于设定背景信息的系统指令,先于用户消息。
4 测试
直接编写一个 controller,在其中接收用户发送的提示词,然后把提示词发送给大模型,交给大模型处理,最后查看结果
java
private final ChatClient chatClient;
@RequestMapping("/chat")
public String chat(String prompt) {
// 阻塞式
return chatClient.prompt().user(prompt).call().content();
}
@RequestMapping(value = "/chatStream", produces = "text/html;charset=utf-8")
public Flux<String> chatStream(String prompt) {
//流式
return chatClient.prompt().user(prompt).stream().content();
}注意,基于 call() 方法的调用属于同步调用,需要所有响应结果全部返回后才能返回给前端。
stream() 方法属于流式调用实现,可以逐步拿到响应结果,需要结合 WebFlux 才能返回给前端。
访问结果:

3 会话日志
默认情况下,应用于AI的交互时不记录日志的,我们无法得知 SpringAI 组织的提示词到底长什么样,有没有问题,这不方便我们调试。
1_Advisor
SpringAI 基于 AOP 机制实现与大模型对话过程的增强、拦截、修改等功能。
所有的增强通知都需要实现 Advisor 接口。
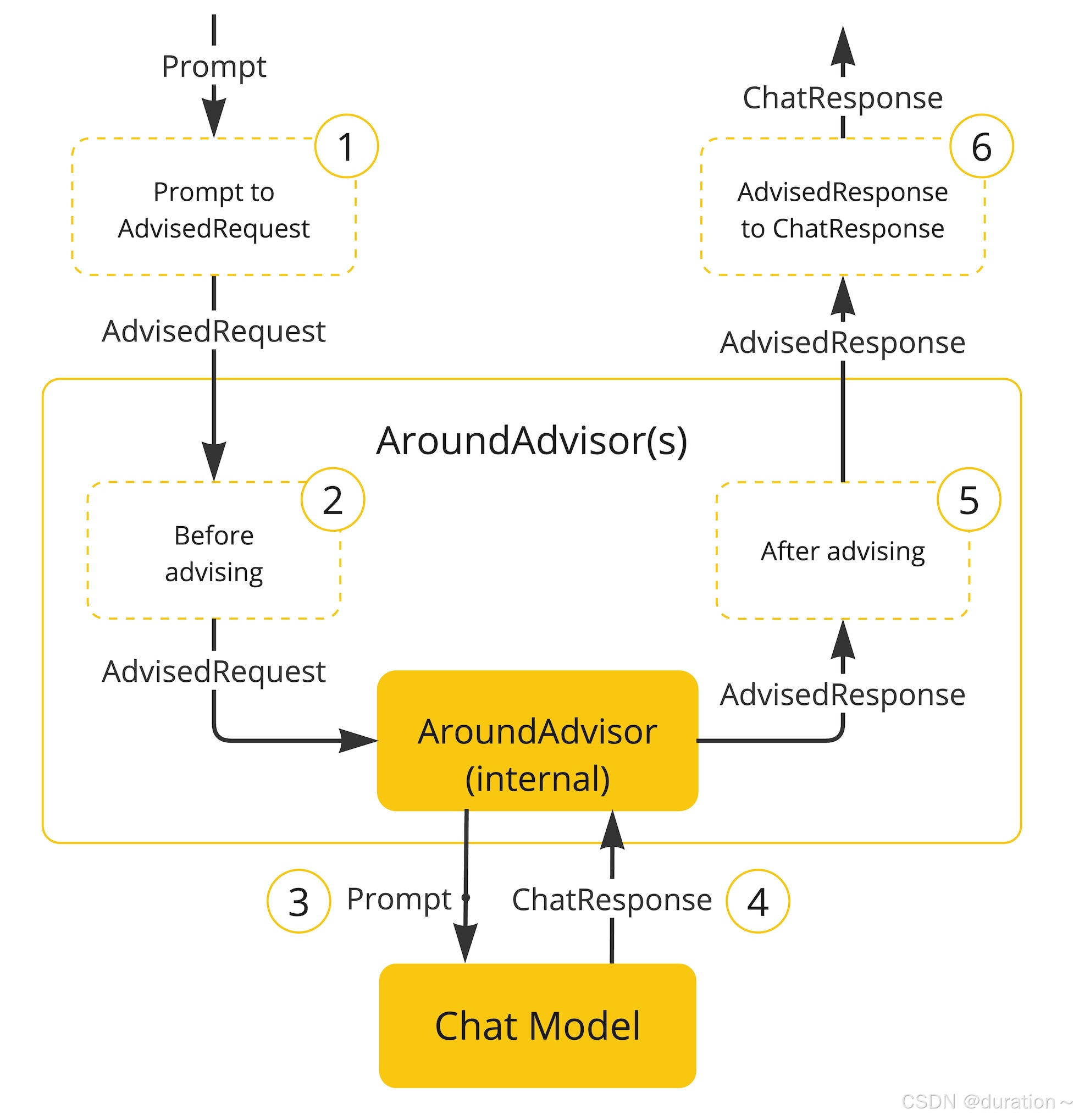
不止是日志,其他功能也可以靠这个环绕增强来实现
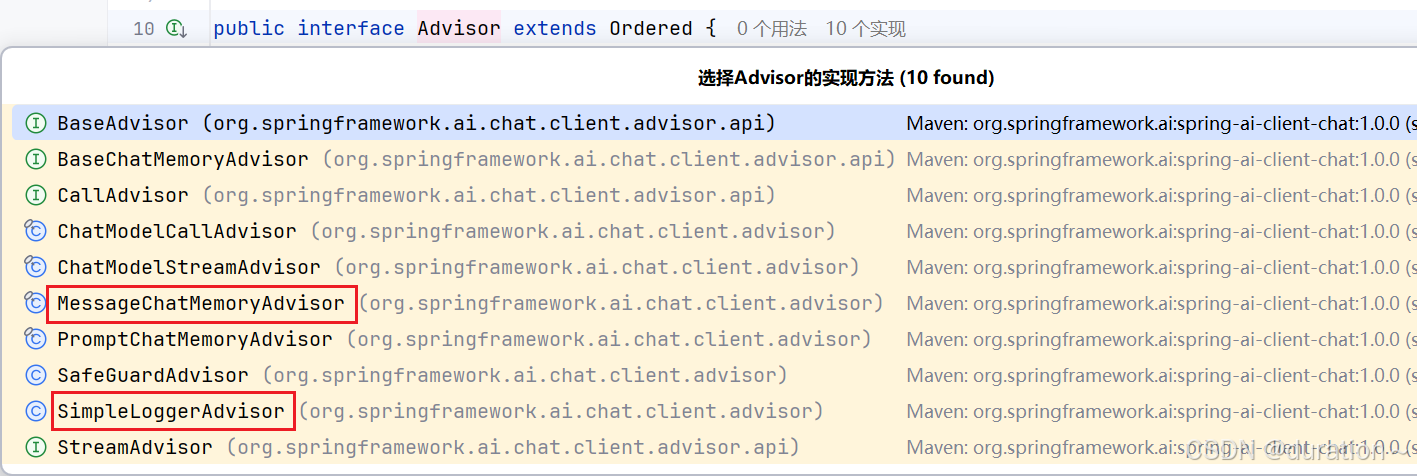
常见的有如下几种:
- CallAdvisor:非流式场景的接口。
- StreamAdvisor:流式场景的接口。
- SimpleLoggerAdvisor:日志记录的Advisor
- MessageChatMemoryAdvisor:会话记忆的Advisor
也可以自定义 Advisor,具体可以参考:
https://docs.spring.io/spring-ai/reference/api/advisors.html#_implementing_an_advisor
注意:这个链和过滤器差不多都是有顺序的,另外添加时的顺序也会有影响。
2 添加日志Advisor
配置日志 Advisor:
java
@Bean
public ChatClient chatClient(OllamaChatModel model) {
return ChatClient.builder(model)
.defaultSystem("你是我的助手,名字叫小微")
.defaultAdvisors(new SimpleLoggerAdvisor())// 配置日志Advisor
.build();
}在配置文件中设置日志级别:
yaml
logging:
level:
org.springframework.ai.chat.client.advisor: debug
com.duration.ai: debug访问测试查看日志:

4 会话记忆
大模型是不具备记忆能力的,要想让大模型记住之前的聊天内容,唯一的办法就是把之前聊天的内容与新的提示词一起发给大模型。
原理就是利用下面这三中不同的消息类型,拼接成数组一起发送给大模型:
| 角色 | 描述 |
|---|---|
| system | 设定大模型角色和任务背景的系统指令,位于用户指令之前 |
| user | 终端用户输入的指令,类似于聊天框中的输入内容 |
| assistant | 由大模型生成的消息,可能包含上一轮对话的结果 |
使用步骤如下:
1_定义会话存储方式
会话记忆功能同样基于 AOP 实现,Spring 提供了一个 MessageChatMemoryAdvisor 的通知,将其添加到 ChatClient 即可。
不过,要注意的是,MessageChatMemoryAdvisor 需要指定一个 ChatMemory 实例,也就是会话历史保存的方式。
ChatMemory 接口声明如下:
java
public interface ChatMemory {
//将指定的消息保存在指定对话的聊天内存中。
default void add(String conversationId, Message message) {
Assert.hasText(conversationId, "conversationId cannot be null or empty");
Assert.notNull(message, "message cannot be null");
this.add(conversationId, List.of(message));
}
// 添加会话信息到指定conversationId的会话历史中
void add(String conversationId, List<Message> messages);
// 根据conversationId查询历史会话
List<Message> get(String conversationId);
// 清除指定conversationId的会话历史
void clear(String conversationId);
}可以看到,所有的会话记忆都是与 conversationId 有关联的,也就是会话Id,将来不同会话id的记忆自然是分开管理的。
当前版本中,在 Spring AI 中只有一个基于内存的实现,默认也会使用它:

MessageWindowChatMemory 只能将会话历史保存在内存中(原理是一个 Map)。
2 配置会话记忆Advisor
首先,在 IOC 容器中注册 ChatMemory 对象:
java
@Bean
public ChatMemory chatMemory() {
return MessageWindowChatMemory.builder()
.maxMessages(10)//设置最大的会话消息数量 FIFO
.build();
}然后将其添加到 ChatClient 中:
java
@Bean
public ChatClient chatClient(OllamaChatModel model,ChatMemory chatMemory) {
return ChatClient.builder(model)
.defaultSystem("你是我的助手,名字叫小微")
.defaultAdvisors(new SimpleLoggerAdvisor())// 配置日志Advisor
.defaultAdvisors(MessageChatMemoryAdvisor.builder(chatMemory).build())
.build();
}补充:
MessageChatMemoryAdvisor 每次交互时,都会从内存中检索对话历史记录,并将其作为消息集合包含在提示中。
除此之外还有:
- PromptChatMemoryAdvisor:从内存中检索对话历史记录,并将其以纯文本形式附加到系统提示中。
- VectorStoreChatMemoryAdvisor:从向量存储中检索对话历史记录,并将其以纯文本形式附加到系统消息中。
虽然聊天已经有了记忆功能了,但是还存在一定的问题:不同用户间默认共用一个会话记忆对象,所以会存在互相干扰的问题(上下文跨页面影响)。
解决方式,使用如下代码,当执行对 ChatClient 的调用时,内存将由 MessageChatMemoryAdvisor 自动管理,对话历史记录将根据指定的对话 ID 从内存中检索:
java
@RequestMapping(value = "/chat", produces = "text/html;charset=utf-8")
public Flux<String> chat(String prompt, String chatId) {
return chatClient.prompt()
.user(prompt)
.advisors(a -> a.param(ChatMemory.CONVERSATION_ID, chatId))
.stream().content();
}ChatMemory.CONVERSATION_ID 是 ChatMemory 中定义的常量 key。
5 会话历史
会话历史与会话记忆是两个不同的事情:
会话记忆:是指让大模型记住每一轮对话的内容,不至于前一句刚问完,下一句就忘了。
会话历史:是指要记录总共有多少不同的对话,每个对话历史(记忆)是独立分开的,互不干扰、互不可见。
以 DeepSeek 为例,页面上的会话历史:

在 ChatMemory 中,会记录一个会话中的所有消息,记录方式是以 conversationId 为 key,以List<Message>为 value,根据这些历史消息,大模型就能继续回答问题,这就是所谓的会话记忆。
而会话历史,就是每一个会话的 conversationId,将来根据 conversationId 再去查询 List<Message>(自己的消息)。
比如上图中,有3个不同的会话历史,就会有3个 conversationId,管理会话历史,就是记住这些 conversationId,当需要的时候查询出 conversationId 的列表。
注意,在接下来业务中,我们以 chatId 来代指 conversationId,实现一个与 DeepSeek 类似的会话历史框。
1_管理会话历史
由于会话记忆是以 conversationId 来管理的,也就是会话 id(以后简称为 chatId),将来要查询会话历史,其实就是查询历史中有哪些 chatId。
因此,为了实现查询会话历史记录,需要记录所有的 chatId,必须定义一个管理会话历史的标准接口,同时根据业务类型对会话历史进行拆分。
java
public interface ChatHistoryRepository {
/**
* 保存会话历史
*
* @param type 业务类型
* @param chatId 会话id
*/
void save(String type, String chatId);
/**
* 获取会话id列表
*
* @param type 业务类型
* @return 会话id集合
*/
List<String> getChatIds(String type);
}定义实现类:
java
@Component
public class InMemoryChatHistoryRepository implements ChatHistoryRepository {
private final Map<String, List<String>> chatHistory = new HashMap<>();
@Override
public void save(String type, String chatId) {
if (!chatHistory.containsKey(type)) {
chatHistory.put(type, new ArrayList<>());
}
List<String> chatIds = chatHistory.get(type);
// 防止重复添加 chatId
if (chatIds.contains(chatId)) {
return;
}
chatIds.add(chatId);
}
@Override
public List<String> getChatIds(String type) {
return chatHistory.getOrDefault(type, List.of());
}
}注意:此实现比较简单,没有用户的概念,但是区分了不同业务,因此简单采用内存 保存type与chatId关系。
根据自身情况,可能需要持久化会话 ID,如果业务中有用户的概念,还需要记录userId和chatId的关联关系。
2 保存会话id
接下来,修改 ChatController 中的 chat 方法,做到 3 点:
- 添加一个请求参数:chatId,每次前端请求AI时都需要传递 chatId。
- 每次处理请求时,将
chatId存储到 ChatRepository。 - 每次发请求到 AI 大模型时,都传递自定义的
chatId。
java
private final ChatHistoryRepository chatHistoryRepository;
@RequestMapping(value = "/chat", produces = "text/html;charset=utf-8")
public Flux<String> chat(String prompt, String chatId) {
// 请求聊天前先保存会话id,已经做了重复添加的校验
chatHistoryRepository.save("chat", chatId);
// 请求模型
return chatClient.prompt()
.user(prompt)
.advisors(a -> a.param(ChatMemory.CONVERSATION_ID, chatId))
.stream().content();
}3 查询会话历史
定义一个新的 Controller,专门实现会话历史的查询,包含两个接口:
- 根据业务类型查询会话历史列表(不同业务需要分别记录历史,大家的业务可能是按
userId记录,根据userId查询)。 - 根据
chatId查询指定会话的历史消息。
查询会话历史消息,也就是 Message 集合。
不过 Message 可能不符合前端页面的需求,因此需要我们自定义一个 VO。
java
@NoArgsConstructor
@Data
public class MessageVO {
private String role;
private String content;
public MessageVO(Message message) {
// MessageType 有四种枚举类型:user assistant function system
this.role = switch (message.getMessageType()) {
case USER -> "user";
case ASSISTANT -> "assistant";
case SYSTEM -> "system";//系统消息前端可能不需要
default -> "";
};
this.content = message.getText();
}
}最后定义 ChatHistoryController:
java
@RequiredArgsConstructor
@RestController
@RequestMapping("/ai/history")
public class ChatHistoryController {
private final ChatHistoryRepository chatHistoryRepository;
private final ChatMemory chatMemory;
/**
* 查询会话历史列表
* @param type 业务类型,如:chat,service,pdf
* @return chatId列表
*/
@GetMapping("/{type}")
public List<String> getChatIds(@PathVariable("type") String type) {
return chatHistoryRepository.getChatIds(type);
}
/**
* 根据业务类型、chatId查询会话历史
* @param type 业务类型,如:chat,service,pdf
* @param chatId 会话id
* @return 指定会话的历史消息
*/
@GetMapping("/{type}/{chatId}")
public List<MessageVO> getChatHistory(@PathVariable("type") String type, @PathVariable("chatId") String chatId) {
List<Message> messages = chatMemory.get(chatId);
return messages.stream().map(MessageVO::new).toList();
}
}6 后续
之后会更新提示词、FunctionCalling、多模态、VectorStore、MCP