一、Pytest配置框架
Pytest的配置旨在改变其默认行为,以适应不同的测试需求和项目结构。理解其配置层级和常用参数,是高效使用Pytest的基础。
1. 配置的意义与层级
配置的本质在于提供一种机制,允许用户根据项目特点、团队规范或特定测试场景,调整Pytest的运行方式。Pytest的配置具有多层级性,优先级从低到高依次为:
•默认配置:Pytest内置的默认行为。
•环境变量:以PYTEST_开头的大写环境变量,例如PYTEST_ADDOPTS。
•配置文件:pytest.ini、pyproject.toml或setup.cfg等配置文件。
•命令行参数:通过命令行传递的参数,优先级最高。
这种层级结构确保了配置的灵活性和可覆盖性,允许用户在不同粒度上进行定制。
2. 获取所有配置信息
要全面了解Pytest支持的所有配置选项,可以通过运行pytest -h命令来获取帮助信息。该命令会列出所有可用的命令行参数、INI配置选项以及相关的环境变量。
命令:
pytest -h 结果为:
- 输出解析:
•-开头的选项:通常是命令行参数,用于在执行时直接影响Pytest行为。
•小写字母开头的选项:通常是可以在pytest.ini等配置文件中设置的INI配置项。
•大写字母开头的选项:通常是环境变量,可以在系统层面或脚本中设置。
3. 常用的命令行参数
命令行参数是临时调整Pytest行为最直接的方式,它们在当前测试运行中具有最高优先级。
|-----------------|----------------------------------------------------------|-------------|------------------------------|
| 参数 | 描述 | 示例用法 | 备注 |
| -v | 增加输出的详细程度,显示每个测试用例的名称和结果。 | pytest -v | 适用于需要查看每个测试执行状态的场景。 |
| -s | 停止捕获标准输出(stdout)和标准错误(stderr),允许测试用例中的print()函数直接输出到控制台。 | pytest -s | 在调试测试用例时非常有用,可以直接看到print的输出。 |
| -x | 遇到第一个失败的测试用例时立即停止测试执行。 | pytest -x | 适用于快速定位问题,避免不必要的后续测试。 |
| -m <MARKEXPR> | 根据标记表达式筛选要执行的测试用例。 | `pytest -m | |
api|<MARKEXPR>可以是标记名(如api),也可以是逻辑表达式(如'api and web'或'not slow')。 | | -k <EXPR>| 根据表达式筛选测试用例的名称。 |pytest -k "test_add and not test_list"| 匹配测试函数、方法或类的名称。 | |--collect-only| 只收集测试用例,不执行。 |pytest --collect-only| 适用于检查测试发现是否符合预期。 | |--lf/--last-failed| 只运行上次失败的测试用例。 |pytest --lf| 快速重跑失败用例,提高调试效率。 | |--ff/--failed-first| 先运行上次失败的测试用例,然后运行其他测试。 |pytest --ff` | 优先验证修复效果,同时不遗漏其他测试。 |
示例代码(结合-s参数):
Python
python
import pytest
def add(a, b):
return a + b
# 示例:测试失败和print输出
def test_print_and_fail():
print("Hello from test_print_and_fail!")
assert 1 == 2 # 预期失败
# 示例:测试输入
def test_input_example():
# 当使用 `pytest -s` 时,input() 可以正常工作
user_input = input("请输入您的姓名:")
print(f"您输入的是:{user_input}")
assert len(user_input) > 0
class TestCalculator:
def test_int_addition(self):
assert add(1, 2) == 3
def test_string_concatenation(self):
assert add("hello", "world") == "helloworld"
def test_list_concatenation(self):
# 列表的加法是拼接操作
assert add([1], [2, 3, 4]) == [1, 2, 3, 4]4. pytest.ini配置文件
pytest.ini是Pytest最常用的配置文件,它允许我们持久化配置选项,例如注册自定义标记、设置默认命令行参数、配置测试发现规则等。它通常放置在项目的根目录下。
pytest.ini 示例结构:
python
[pytest]
# Pytest的最低版本要求
minversion = 6.0
# 默认添加到命令行参数的选项
# -s: 允许捕获print输出
# -v: 增加输出详细程度
# --strict-markers: 强制要求所有使用的标记都必须在markers中注册
addopts = -s -v --strict-markers
# 注册自定义标记及其描述
markers =
api: 标记接口测试用例
web: 标记UI(Web)测试用例
ut: 标记单元测试用例
login: 标记登录相关测试用例
pay: 标记支付相关测试用例
ddt: 标记数据驱动测试用例
smoke: 标记冒烟测试用例,用于快速验证核心功能
# 配置测试发现规则 (可选)
python_files = test_*.py *_test.py
python_classes = Test*
python_functions = test_
# 配置测试路径 (可选)
# testpaths = tests/
# 配置报告输出 (可选)
# log_cli = true
# log_cli_level = INFO
# log_cli_format = %(asctime)s [%(levelname)s] %(message)s (%(filename)s:%(lineno)s)说明:
•pytest:配置文件的主体部分。
•minversion:指定Pytest的最低版本要求,如果当前Pytest版本低于此值,则会发出警告。
•addopts:用于设置每次运行Pytest时默认添加的命令行选项。这对于团队协作和CI/CD环境非常有用,可以确保测试运行的一致性。
•markers:这是非常重要的部分,用于注册自定义标记。在pytest.ini中注册标记可以避免PytestUnknownMarkWarning警告,并为标记提供清晰的描述,方便团队成员理解和使用。
二、标记mark
标记 可以让用例与众不同,进而可以让用例被区别对待
(一)、用户自动义标记
标记是Pytest中一种强大的元数据机制,它允许我们为测试函数、测试方法或测试类附加额外的信息。通过标记,我们可以对测试用例进行分类、筛选,甚至改变它们的执行行为。
1. 用户自定义标记
用户自定义标记主要用于对测试用例进行分类和筛选。它们需要在使用前在pytest.ini文件中进行注册。
步骤:
1、先注册
python
[pytest]
markers =
api:接口测试
web:UI测试
ut:单元测试
login:登录相关
pay:支付相关2、再标记
实例:
python
import pytest
def add(a, b):
return a + b
class TestAdd:
@pytest.mark.api
def test_int(self):
assert add(1, 2) == 3
@pytest.mark.web
def test_str(self):
assert add("1", "2") == "12"
@pytest.mark.pay
def test_list(self):
assert add([1] ,[2,3,4,5]) == [1,2,3,4,5]3、后筛选
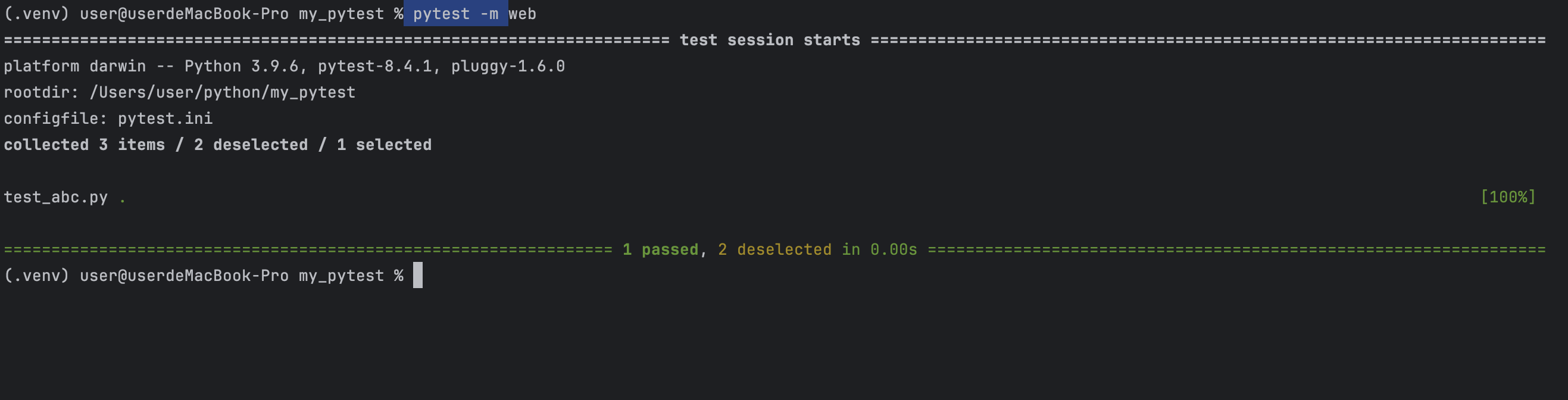
利用命令: pytest -m 参数
实例:
pytest -m web
结果:
(二)、框架内置标记
Pytest提供了一些内置标记,它们无需在pytest.ini中注册即可直接使用,并且除了筛选功能外,还具有特殊的执行效果。这些标记通常用于控制测试的跳过、预期失败以及参数化等高级行为。
和用户自定义的区别
|----|------------------|---------------------------|
| 特性 | 用户自定义标记 | 框架内置标记 |
| 注册 | 必须在pytest.ini中注册 | 无需注册,直接使用 |
| 功能 | 主要用于筛选测试用例 | 除了筛选,还具有特殊的执行效果(如跳过、预期失败) |
| 效果 | 仅影响测试的执行范围 | 影响测试的执行结果和报告状态 |
1、无需注册、可以直接使用
2、不仅可以筛选,还可以增加特殊效果
3、不同的标记、增加不同的特殊效果
- skip:无条件跳过
@pytest.mark.skip装饰器用于无条件地跳过某个测试函数或测试类。这通常用于标记那些暂时不相关、尚未完成或由于特定原因不应执行的测试。
语法:
@pytest.mark.skip(reason="跳过原因")
示例:
python
import pytest
def add(a, b):
return a + b
class TestSkip:
@pytest.mark.skip(reason="此功能正在重构,暂时跳过测试")
@pytest.mark.api
def test_old_api_endpoint(self):
assert add(1, 2) == 3- skipif:有条件跳过
@pytest.mark.skipif装饰器允许我们根据特定条件来决定是否跳过测试。如果条件为真,则测试被跳过;否则,测试正常执行。这在跨平台测试、依赖特定环境或版本时非常有用。
语法:
@pytest.mark.skipif(condition, reason="跳过原因")
示例:
python
import pytest
import sys
def add(a, b):
return a + b
class TestSkipIf:
@pytest.mark.skipif(sys.version_info < (3, 9), reason="此测试需要Python 3.9或更高版本")
@pytest.mark.web
def test_new_python_feature(self):
assert add("Python", "3.9+") == "Python3.9+"
@pytest.mark.skipif(True, reason="这是一个永远跳过的示例")
@pytest.mark.web
def test_always_skip(self):
assert add("a", "b") == "ab"- xfail:预期失败
@pytest.mark.xfail装饰器用于标记那些我们预期会失败的测试用例。当一个被标记为xfail的测试实际失败时,它不会被报告为错误,而是显示为"预期失败"(xfailed)。如果一个xfail测试意外地通过了,它会被报告为"预期通过"(xpassed)。这对于跟踪已知bug、尚未修复的功能或正在开发中的特性非常有用。
语法:
@pytest.mark.xfail(condition=None, reason="预期失败原因", raises=None, run=True, strict=False)
常用参数:
•reason:说明预期失败的原因。
•raises:指定预期失败时抛出的异常类型。如果测试失败但未抛出指定异常,则会被报告为意外通过。
•strict:如果设置为True,当xfail测试意外通过时,Pytest会将其报告为失败。默认为False。
示例:
python
import pytest
def divide(a, b):
return a / b
class TestXfail:
@pytest.mark.xfail(reason="除数为零,预期会抛出ZeroDivisionError")
@pytest.mark.pay
def test_divide_by_zero_xfail(self):
# 预期此操作会引发ZeroDivisionError
assert divide(10, 0) == 0 # 这个断言会失败,但因为xfail而被标记为预期失败
@pytest.mark.xfail(raises=TypeError, reason="预期类型错误,例如字符串和数字相加")
@pytest.mark.pay
def test_type_error_xfail(self):
# 预期此操作会引发TypeError
assert 1 + "a" # 这会引发TypeError
@pytest.mark.xfail(strict=True, reason="此功能正在开发中,如果意外通过则视为错误")
def test_feature_in_progress_xfail(self):
# 模拟一个正在开发中且目前预期会失败的功能
assert False # 模拟失败- parametrize:参数化
@pytest.mark.parametrize是Pytest中用于数据驱动测试的核心标记。它允许我们使用不同的数据集重复执行同一个测试函数,从而提高测试的覆盖率和效率。
语法:
@pytest.mark.parametrize(argnames, argvalues, ids=None, scope=None)
常用参数:
•argnames:一个字符串,包含用逗号分隔的参数名称。
•argvalues:一个列表,包含参数值的元组或列表。每个元组/列表对应一次测试执行的参数组合。
•ids:一个字符串列表,用于为每个参数组合生成更具可读性的测试ID。
示例:
python
import pytest
def multiply(a, b):
return a * b
@pytest.mark.parametrize("num1, num2, expected_result", [
(1, 2, 2),
(3, 4, 12),
(5, 0, 0),
(-1, 2, -2),
], ids=["positive_multiplication", "another_positive", "multiply_by_zero", "negative_multiplication"])
def test_multiply_operation(num1, num2, expected_result):
assert multiply(num1, num2) == expected_result一个实例:
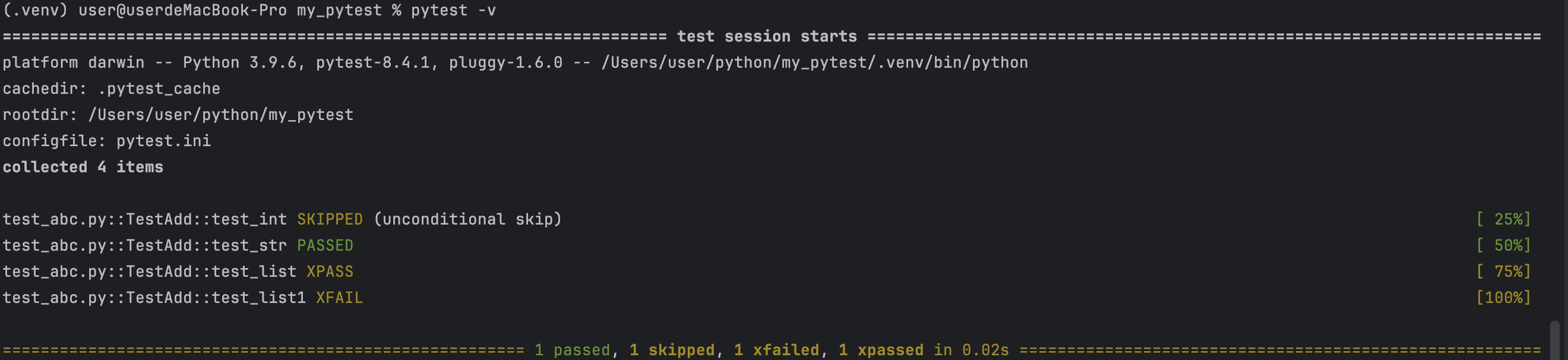
python
import pytest
def add(a, b):
return a + b
class TestAdd:
@pytest.mark.skip
@pytest.mark.api
def test_int(self):
assert add(1, 2) == 3
@pytest.mark.skipif(1 == 2,reason = "Java太难学了")
@pytest.mark.web
def test_str(self):
assert add("1", "2") == "12"
@pytest.mark.xfail
@pytest.mark.pay
def test_list(self):
assert add([1] ,[2,3,4,5]) == [1,2,3,4,5]
@pytest.mark.xfail
@pytest.mark.pay
def test_list1(self):
assert add([1] ,[2,3,4,5]) != [1,2,3,4,5]结果:
三、数据驱动测试参数
在实际项目中,为了更好地管理和维护测试数据,通常会将测试数据存储在外部文件中,例如CSV、Excel或JSON格式。Pytest结合参数化(parametrize)功能,可以方便地实现数据驱动测试,即通过外部数据文件来驱动测试用例的执行数量和内容。
我们可以编写一个辅助函数来读取这些外部数据,并将其作为@pytest.mark.parametrize装饰器的参数值(argvalues)。
1. 数据文件示例:data.csv
python
a, b, c
1, 1, 1
2, 3, 5
3, 3, 6
4, 4, 72. 测试代码示例置文件
python
@pytest.mark.ddt
@pytest.mark.parametrize(
"a, b, c",
read_csv("data.csv")
)
def test_ddt(self, a, b, c):
res = add(int (a),int(b))
assert res == int(c)在上述test_ddt测试用例中,read_csv("data.csv")会读取data.csv中的每一行数据,并将其作为a、b、c的参数值传递给测试函数。每次执行时,a和b会被转换为整数进行add操作,然后结果与转换后的c进行断言。
3. 配置文件:pytest.ini
为了更好地管理自定义标记,例如本例中的ddt标记,建议在pytest.ini文件中进行注册。这有助于避免Pytest的警告,并提供标记的清晰描述。
python
[pytest]
markers =
api:接口测试
web:UI测试
ut:单元测试
login:登录相关
pay:支付相关
ddt:数据驱动测试pytest.ini中注册ddt标记,我们可以使用pytest -m ddt命令来专门执行所有数据驱动测试用例。
总结
通过本文的详细阐述,我们深入了解了Pytest的配置机制和强大的标记功能。合理利用命令行参数、pytest.ini配置文件以及各种内置和自定义标记,可以极大地提升测试的组织性、可控性和执行效率。掌握这些高级特性,将帮助您构建更专业、更高效的Python测试实践。