引言
近日,阿里云 PAI 团队、通义实验室与中国科学院大学前沿交叉科学学院合作在机器学习顶级会议 ICML 2025 上发表题为 Efficient Long Context Fine-tuning with Chunk Flow 的论文。机器学习国际会议 (ICML) 是致力于推动人工智能分支机器学习的专业人士的重要聚会,是人工智能领域的顶级学术会议之一。ChunkFlow 做为阿里云在变长和超长序列数据集上高效训练解决方案,支撑着通义千问 Qwen 全系列模型的长序列续训练和微调任务,在阿里云内部的大量的业务上带来2倍以上的端到端性能收益,大大降低了训练消耗的GPU卡时。Qwen2.5 系列模型性能测试结果表明,ChunkFlow 相较于其他框架,训练的端到端性能有最高4.53倍的提升 。 
研究背景
长文本能力是语言模型的核心能力之一,对诸多下游任务都至关重要。续训练(Continue Pre-Training)和长文本微调(Long Context Fine-Tuning)是扩展大语言模型长文本能力的重要一环。通常情况下,这些训练场景通常会在精心挑选的数据集中进行,在数据长度分布上会有显著的特点,展现出极度的长尾效应(数据集中短数据占绝大多数,同时存在超长的训练数据)。这种特殊的数据分布特征给现有的训练系统带来了广泛的性能问题,如GPU利用率的不高效、流水线并行的空泡率高等问题。ChunkFlow是在变长和超长序列数据集上提出的高效训练解决方案。
现有问题
- 变长数据集中固定的显存策略/并行策略与变化的Sequence长度之间的存在矛盾。
现有的训练系统通常会根据数据集中最长的数据制定显存策略和并行策略,但是这种设置对于大多数训练数据来说是不必要的。同时又因为变长数据,在大规模训练过程中存在负载不均衡问题,同时也会增加流水线并行的空泡问题,导致严重的训练性能退化。
- 超长训练数据带来的巨大显存压力问题。
超长序列带来非常大的激活值的内存占用,使得在训练过程中使用重算或者offload成为必要,同时也进一步加剧了训练过程中各个迭代步间内存占用的不均衡。对于流水线并行,处理包含超长序列的迭代步的时候,更倾向于使用更小的微批次数量,降低了流水线并行的效率。
论文成果
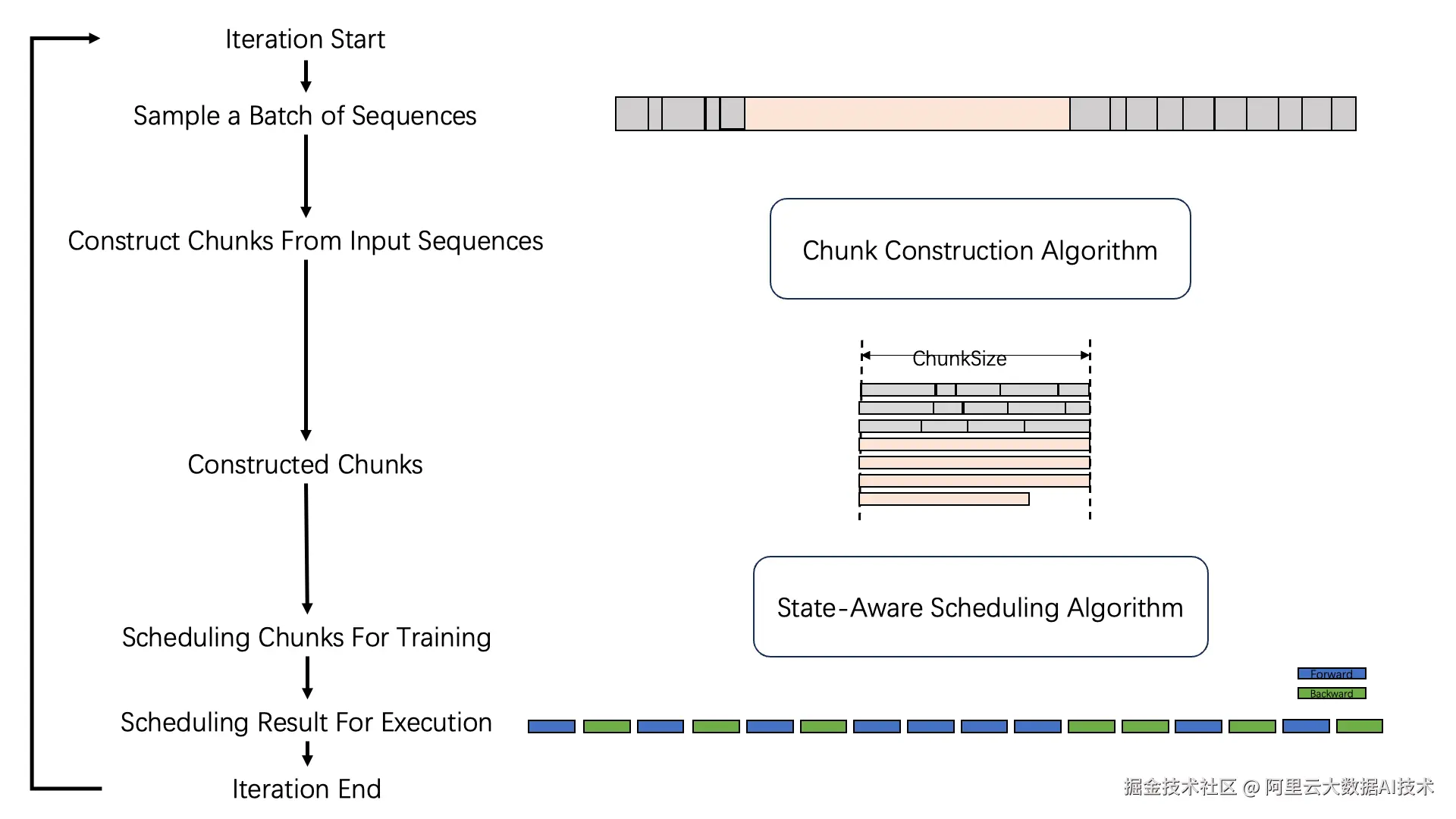 ChunkFlow整体的工作流程
ChunkFlow整体的工作流程
在每个iteration开始采样的到一批训练样本后,通过将短序列拼接、长序列切分,ChunkFlow将数据重新构建成以ChunkSize为单位的训练样本。在训练过程中为了维持计算的正确性和显存控制,ChunkFlow采用了状态感知的调度机制。
ChunkFlow针对处理变长和超长序列数据的性能问题,提出了以Chunk为中心的训练机制。我们期望训练过程中的内存需求能够与我们设定的固定的ChunkSize成正比,解决在变长数据和超长数据集训练过程中不稳定的内存占用和GPU利用率低下的问题。ChunkFlow重新组织了数据,将短的训练数据做拼接,长的训练数据做切分,把变长的训练数据重新组织成以ChunkSize为大小的形式。如下图所示,Algorithm 1展现了训练Chunk构建的过程。 
对于拼接的序列,其计算的正确性可以通过注意力掩码来保证,但是对于被切分到各个Chunk的长序列,由于语言模型中注意力机制的因果特性,我们需要仔细的按照顺序去维持计算正确性。为此,我们对于这些相互依赖的Chunk提出了一套调度机制。如下图 Algorithm 2所展示,这个调度机制可以根据内存需求,通过使用重算等显存优化方式调整相互依赖Chunk计算过程中的显存问题。 
下图展示了Chunk的调度机制,包含独立的Chunk和相互依赖Chunk处理流程,以及不同显存预算下的策略选择。 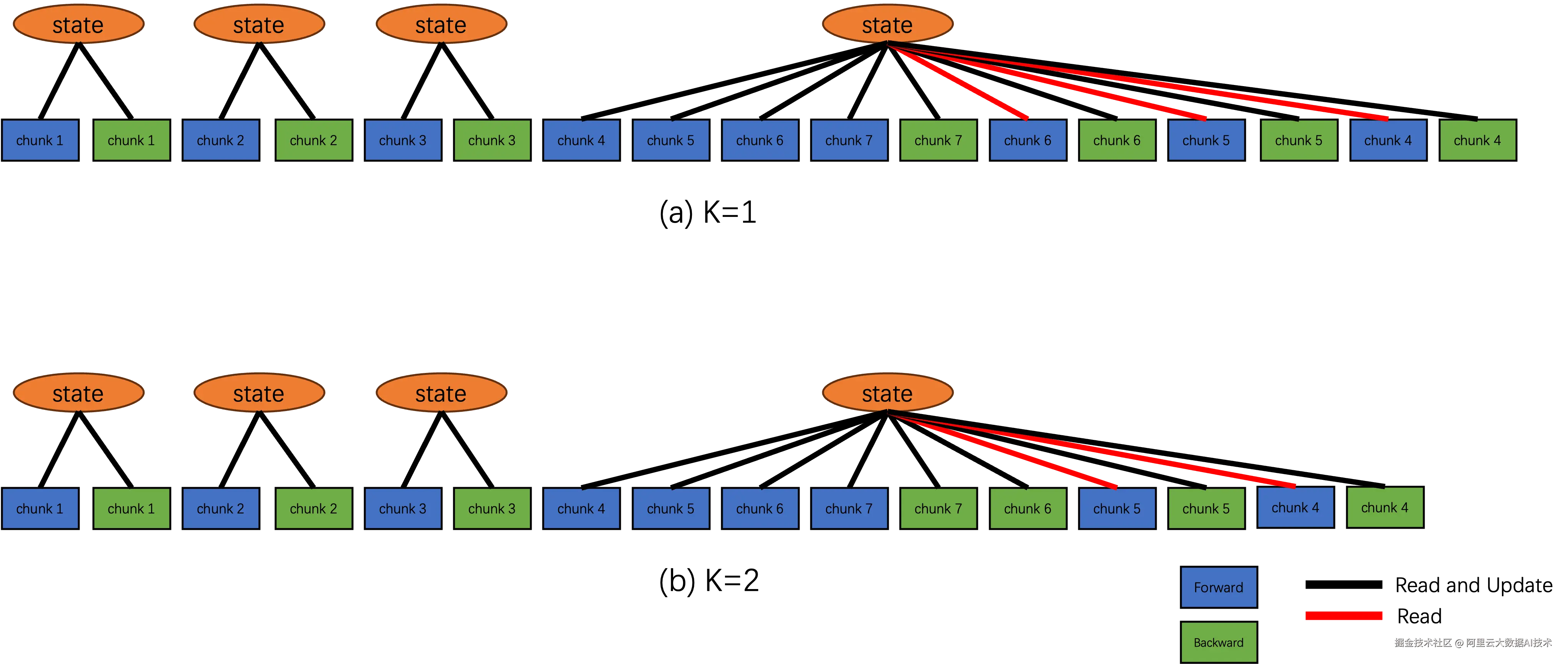
通过ChunkFlow的计算机制,我们能够的到更均衡的流水线切片的处理时间,从而大幅降低流水线并行中的空泡率。同时,由于对长数据的切分,ChunkFlow增加了流水线并行中的微批次数量,进一步提升了流水线并行的性能。 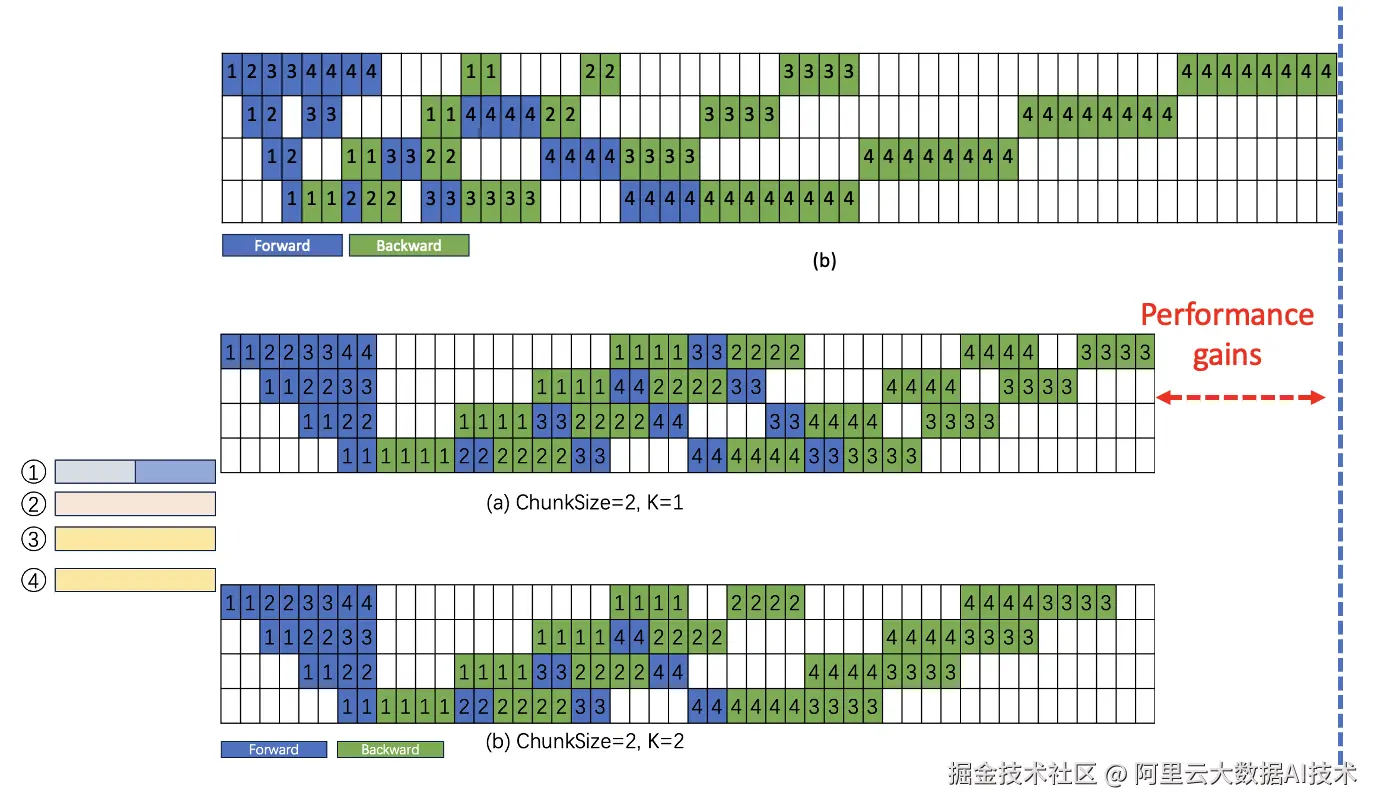
实验数据
我们在多种尺寸的Qwen2.5系列模型中分别做了文本长度为32K和256K的端到端性能测试,下图展示了ChunkFlow相较于Megatron-LM,训练的端到端性能有最高4.53倍的提升。 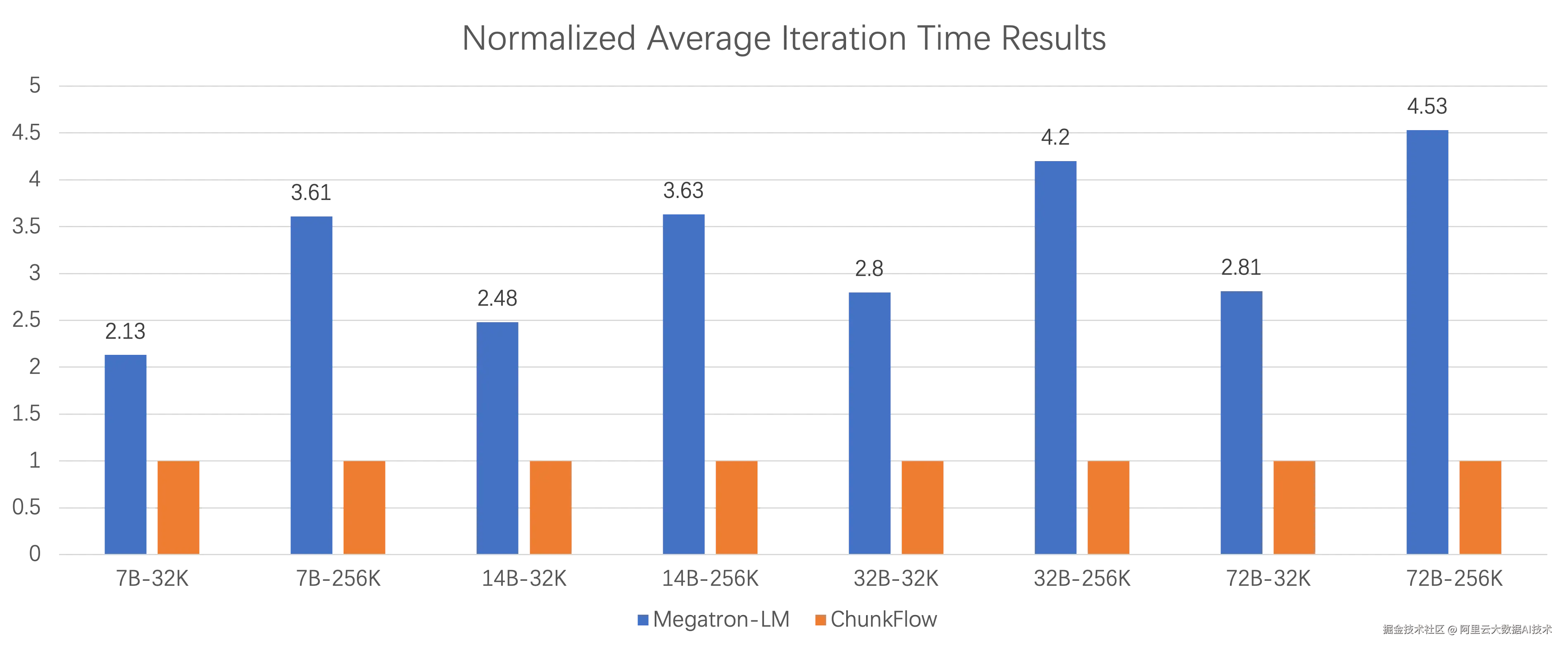
同时,我们测试了不同ChunkSize的设定对训练过程中显存侧的影响,如下图,ChunkFlow可以做到可控的峰值显存占用,使得训练所需显存和预设的ChunkSize相关而不是与训练数据中的最长序列相关,大大提升了训练过程中的鲁棒性。 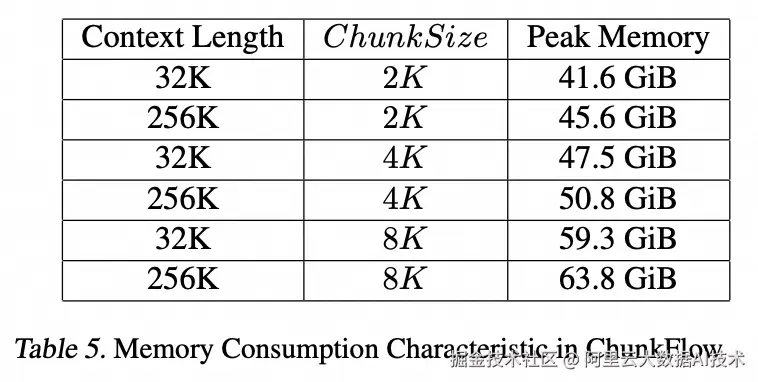
目前,ChunkFlow 作为统一的解决方案支撑着全系 Qwen 模型的SFT任务和长序列CPT任务,并在大量的业务上带来2X+的性能收益,为Qwen业务节省可观的GPU成本。
更多论文相关信息
- 论文标题:
Efficient Long Context Fine-tuning with Chunk Flow
- 论文作者:
Xiulong Yuan, Hongtao Xu, Wenting Shen, Ang Wang, Xiafei Qiu, Jie Zhang, Yuqiong Liu, Bowen Yu, Junyang Lin, Mingzhen Li, Weile Jia, Yong Li, Wei Lin
- 论文链接: