目录
- 数据库基础
- [drop、delete 与 truncate 区别?](#drop、delete 与 truncate 区别?)
- In、Between、Like
- [执行一条 select 语句,期间发生了什么?](#执行一条 select 语句,期间发生了什么?)
- [MySQL 的存储引擎有哪些?它们之间有什么区别?默认使用哪个?](#MySQL 的存储引擎有哪些?它们之间有什么区别?默认使用哪个?)
- [MyISAM 与 InnoDB 有什么区别?如何选择?](#MyISAM 与 InnoDB 有什么区别?如何选择?)
- [InnoDB 是如何存储数据的?](#InnoDB 是如何存储数据的?)
- [详细描述一条 SQL 在 MySQL 中的执行过程](#详细描述一条 SQL 在 MySQL 中的执行过程)
- [MySQL 的查询优化器如何选择执行计划?](#MySQL 的查询优化器如何选择执行计划?)
- [SQL 中 select、from、join、where、group by、having、order by、limit 的执行顺序](#SQL 中 select、from、join、where、group by、having、order by、limit 的执行顺序)
- [MySQL 中的数据排序(ORDER BY)是如何实现的?](#MySQL 中的数据排序(ORDER BY)是如何实现的?)
- [MySQL 中 int (11) 的 11 表示](#MySQL 中 int (11) 的 11 表示)
- [CHAR 与 VARCHAR 有何区别](#CHAR 与 VARCHAR 有何区别)
- 如何存储emoij?
- 一个汉字占多少字节
- 查询执行频次
- 慢查询
- SQL性能分析
- SQL优化
- 窗口函数
- 锁
- MVCC
- 分库分表
数据库基础
查看表结构
sql
SHOW create table xx
或
DESC xx候选码和主码
候选码是能够唯一标识关系中元组的最小属性集,"学号" 和 "身份证号" 都是 "学生" 关系表的候选码 。
从多个候选码中选定一个用来唯一标识关系中的元组,称为主码,只能有一个。通常会选择 "学号" 作为主码
事务特性
原子性(UndoLog),隔离性(MVVC),持久性(RedoLog),一致性
隔离级别
- 读未提交(脏读)
- 读已提交(不可重复读)
- 可重复读(幻读,两次查询返回的行数不一致。 )
为什么会出现幻读? :可重复读通过 MVCC(多版本并发控制) 保证了 "读取一致性"(即避免不可重复读),但新插入的行没有 "历史版本"。 - 串行化
总结:不可重复读主要针对 "已有行的更新 / 删除",而幻读专门针对 "新插入的行"。
三大范式
- 不可再分性
- 消除部分函数依赖(非主属性必须完全依赖主键)
- 消除传递依赖(非主属性不能依赖其他非主属性)
存储引擎
- InnoDB:遵循事务;行级锁;支持外键约束
- MyISAM:不支持事务和外键,支持表锁,访问速度快
- Memory:表数据存储在内存中 ;哈希索引 ,用作临时表
JOIN
内连接
- INNER JOIN(默认)内连接
sql
SELECT a.id
FROM table a
INNER JOIN table b ON a.id = b.id;
等同于
SELECT a.id
FROM table a
,table b WHERE a.id = b.id;外连接
OUTER JOIN 外连接:至少返回一个表中的所有记录
-
LEFT JOIN 返回左表中的所有行
-
FULL OUTER JOIN 返回两个表中所有记录,但在Mysql不直接支持,需要使用
sql
SELECT * FROM table1 LEFT JOIN table2 ON ...
UNION
SELECT * FROM table1 RIGHT JOIN table2 ON ...;实现。
自连接
应用场景:查询层级结构,例如查询员工的上级名称
sql
SELECT
e.name AS employee_name,
m.name AS manager_name
FROM
employees e
JOIN
employees m ON e.manager_id = m.employee_id;IF、CASE
sql
IF condition THEN
statements;
ELSEIF condition THEN
statements;
ELSE
statements;
END IF;
sql
CASE expression
WHEN value1 THEN statements;
WHEN value2 THEN statements;
ELSE statements;
END CASE;
sql
WHILE condition DO
statements;
END WHILE;多种条件判断语句
- IF(dept="computer",1,0)
- coalesce(name,"无名氏")返回首个非null值
- ifnull(a,b)a为空则返回b
索引
索引是一种用于快速查询和检索数据的数据结构。
优点是提高查询效率,缺点是占用额外内存,降低增删改的效率。
B+树又叫多路平衡查找树:
- 大数据下,层级平均。
- 叶子节点存储数据,并通过链表串联。
- 所有元素都会出现在叶子结点。非叶子节点仅用于索引。
一个3阶B+树,每个节点最多2个关键字,3个子树。插入时遵循中间元素向上分裂原则。
为什么InnoDB选择B+树作为索引结构?
- 大数据下,层级低。
- 相对比B树,层级更低,范围查询效率更高
分类
按结构分类:
- B+树索引,最常见。在InnoDB中分为聚簇索引(叶子节点挂载行数据,必须有且只有一个)和二级索引(索引指向数据存储的位置)。
- 哈希索引:精确匹配 。是Memory引擎支持的类型
- 全文索引:用于文本内容的关键词搜索
- 空间索引:针对地理位置数据查询,是MyISAM引擎的一个特殊索引类型。
按功能分类:
- 主键索引:主键,不允许NULL
- 唯一索引:唯一,允许NULL
- 普通索引:最基本的索引类型,没有限制。
- 前缀索引:使用列的前 N 个字符
- 联合索引:多个列组合索引
根据索引的存储形式:
- 在InnoDB中分为聚簇索引(索引即数据,必须有且只有一个,默认为主键)和二级索引(索引指向数据存储的位置)。
- 聚簇索引的叶子结点挂载行数据。
- 二级索引的叶子节点挂载行id。
创建索引:
sql
## 将name作为索引,名为idx_name
INDEX idx_name (name) 验证索引是否被使用
使用EXPLAIN语句
sql
EXPLAIN SELECT * FROM users WHERE name = 'Alice';显示
type :显示访问类型,理想值为 const (主键 / 唯一索引)或 ref(普通索引)
key :实际使用的索引名称(主键还是唯一还是、)
rows :扫描的行数。如果显示全部则反应没使用索引。

索引失效的场景
- 对索引使用函数或表达式计算
- 对索引进行左模糊查询(因为索引的有序性无法利用)
sql
SELECT * FROM users WHERE name LIKE '%Alice'; - 类型不匹配
例如 select name=zcm不加引号时 - 符合索引未遵循最左前缀原则
- 使用OR连接非索引字段,使用NULL
select id or age 因为age没有索引,name索引均失效。索引无法快速定位NULL值,-可以使用空字符来避免NULL
视图
视图是虚拟的表,不能对其进行索引操作。
事务处理
Mysql默认是隐式提交,当BEGIN或START TRANSACTION时,会关闭隐式提交,变为显示提交,当COMMIT或ROLLBACK执行后,事务会自动关闭,重新恢复隐式提交。
存储过程
存储过程可以看成是对一系列 SQL 操作的批处理。它类似于编程语言中的函数或子程序,可接收参数、执行复杂逻辑,并返回结果。
游标
在 MySQL 中,游标(Cursor) 是一种用于遍历查询结果集的数据库对象。它允许你逐行处理查询结果,类似于编程语言中的迭代器。
- 作用:处理 SELECT 语句返回的多行数据
drop、delete 与 truncate 区别?
- drop用于删除表
- delete from table where x=x 删除某一行数据
- truncate清空表中的数据,再插入数据时候自增长id又从1开始。
In、Between、Like
in和betwwen在where子句中使用,分别表示指定值、指定范围。
like在where子句中使用,用于字符串匹配,支持两个通配符:%和_
代表出现任意字符出现多次和一次
sql
SELECT *
FROM products
WHERE vend_id IN ('DLL01', 'BRS01');
sql
SELECT *
FROM products
WHERE prod_price BETWEEN 3 AND 5执行一条 select 语句,期间发生了什么?
xxx
MySQL 的存储引擎有哪些?它们之间有什么区别?默认使用哪个?
存储引擎:InnoDB、MyISAM、Memory、CSV 等。
区别:
InnoDB 支持事务、外键和行级锁定,适合高并发写场景;MyISAM 不支持事务和外键,适合读多写少场景 。
InnoDB 使用聚簇索引组织数据,MyISAM 使用非聚簇索引 。
默认:MySQL 默认使用 InnoDB 。
MyISAM 与 InnoDB 有什么区别?如何选择?
区别:
InnoDB 支持事务、行锁和表锁,使用聚簇索引,适合写场景;MyISAM 不支持事务,支持表锁,使用非聚簇索引,适合读场景 。
选择:写操作多、需事务支持(如电商订单系统)选 InnoDB;读操作多、对事务要求低(如日志查询系统 )选 MyISAM 。
InnoDB 是如何存储数据的?
InnoDB 通过表空间、页和行的结构化方式存储数据,将数据保存在磁盘上的数据文件中,采用聚簇索引来组织数据,支持事务、外键和行级锁定 。
- MySQL 一行记录是怎么存储的?
MySQL 一行记录存储在数据页中,包含行头信息、实际数据和可变长度字段的偏移量 。
详细描述一条 SQL 在 MySQL 中的执行过程
一条 SQL 在 MySQL 中的执行过程包括解析器解析 SQL,优化器生成执行计划,访问存储引擎获取数据,将数据返回给客户端 。
MySQL 的查询优化器如何选择执行计划?
MySQL 查询优化器通过生成多种可能的执行计划,并分析出成本最低的执行计划。优化器会考虑使用索引,表连接顺序,排序和分组等操作的效率 。
SQL 中 select、from、join、where、group by、having、order by、limit 的执行顺序
SQL 的执行顺序通常为:from->join->where->group by->having->select->order by->limit 。
MySQL 中的数据排序(ORDER BY)是如何实现的?
如果 Order by 的字段有索引 ,那么直接利用索引的有序性返回排序结果 。
当无法使用索引进行排序时,mysql 使用文件排序算法 。
对于某些特殊查询,例如 limit,使用堆排序,可以简化排序开销
MySQL 中 int (11) 的 11 表示
int(11) 里的 11 是显示宽度 ,不影响存储范围(int 类型存储范围由类型本身决定,如普通 int 是 -2147483648 ~ 2147483647 )。它仅用于查询结果格式化显示,配合 ZEROFILL(零填充)时,不足 11 位会用 0 补齐,比如 int(11) ZEROFILL 存 5 会显示 00000000005 ,主要为界面展示对齐,不改变实际存储值 。
CHAR 与 VARCHAR 有何区别
前者固定长度,按定义长度分配空间 后者varchar可变长度,按实际内容 + 1/2 字节(记录长度)分配
如何存储emoij?
Emoij需要4字节的utf编码,而utf-8默认是3字节,所以需要设置utf8mb4字符集
一个汉字占多少字节
一个中文字符所占字节数,会因编码方式的不同而有所差异。
对于UTF-8 编码通常占用 3 个字节 。不过,在 UTF-8 编码中,一些生僻字可能会占用 4 个字节
查询执行频次
查询CRUD的各执行频次:
sql
SHOW GLOBAL STATUS LIKE 'Com______'; -- 匹配所有以Com_开头后6个字符的变量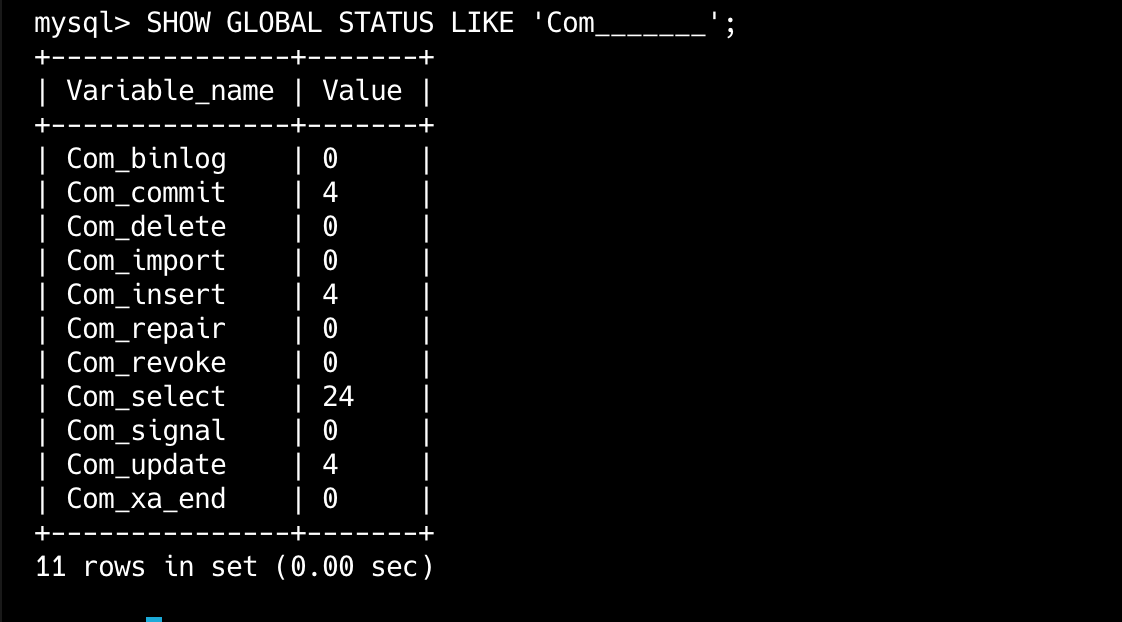
慢查询
当sql执行时间超过指定参数时间(s),视为慢查询。
需要在mysql配置文件中设置slow_query_lof=1,long_query_time=2
从而可以找出慢查询的语句,继而优化该语句效率。
show variables like 'slow_query_log'查询是否开启慢查询日志
SQL性能分析
sql
SET profiling = 1; -- 1表示开启查询分析
SELECT ...
SHOW PROFILES; -- 查看所有已记录查询的概要信息
SHOW profile for query id; --查看具体语句的阶段耗时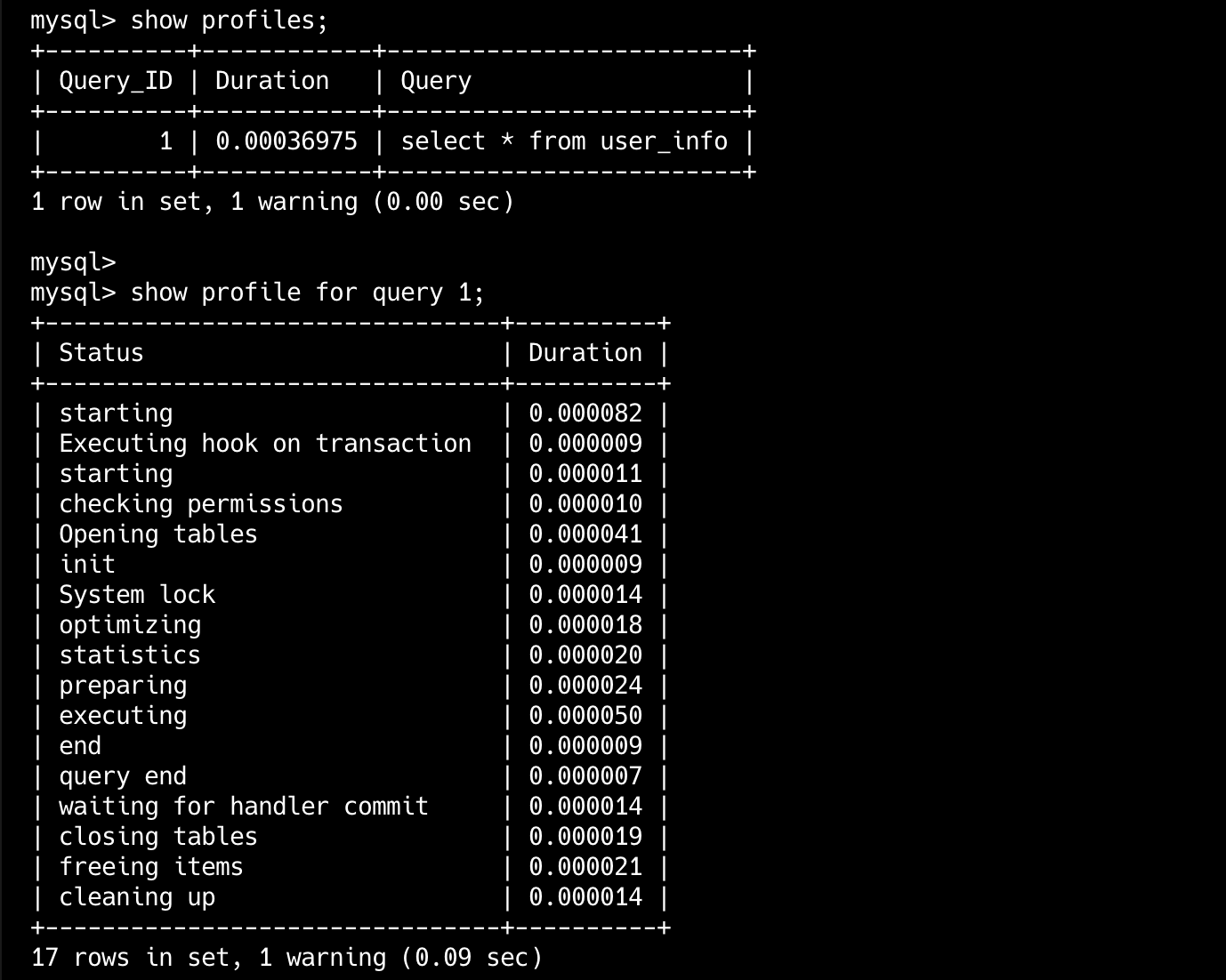
SQL优化
Insert优化
- 批量插入
Insert iinto tb values()()()() - 手动提交事务
- 主键顺序插入
- 当一次性插入大批量时,使用load 指令
LOAD DATA INFILE 'data.csv' INTO TABLE users;
order by优化
- 使用索引排序
- 并且符合最左前缀原则,(否则不使用索引,使用文件排序)
- 多个字段同时符合 创建索引时的排序顺序(asc还是desc)
Group by同理
Limit优化
对于Limit 100000,10分页这种问题,select * from tb order by id limit 100000,10这种普通操作代价很大。因为需要大量回表查询。
优化方式:覆盖索引+子查询
sql
select * from tb WHERE id>=(select id from tb order by id limit 100000,1) ORDER BY id limit 10;Count优化
对于返回数据行总数,MyISAM可以直接读取总数的属性,但Innodb需要一个个加。
- select count(*)统计所有行的数量,包括 NULL
- select count(col)统计列的不为NULL的行
- select count(1),作用同count(*)
count(id)取出id累加,count(*) count(1)则不取值,直接累加行,因此性能略高。
总结:count(*)最常用
Update优化
update语句中 where的字段
- 若是索引(此时数据库可以通过索引快速定位到具体的行),则加行锁;
- 若不是索引,则加表锁。
窗口函数
窗口函数允许在查询结果集的特定 "窗口" 内执行计算,而无需像传统聚合函数那样分组,而是返回每行。
sql
SUM() OVER (
[PARTITION BY 列1, 列2, ...] -- 分区(分组)
[ORDER BY 列1 [ASC/DESC], ...] -- 排序
)锁
- 全局锁
- 表级锁
- 表读锁,表写锁
- 元数据锁:自动加,用于保护表结构不被同时修改
- 意向锁:表示某个事务正在锁定表中的某一行或某些行
- 行锁
- 间隙锁:在一个区间内加锁,不包括两端。防止其他事务插入间隙,即解决幻读。
- 临键锁:可以理解为记录锁和间隙锁,因此【区间+右端点】加锁。是 InnoDB 行级默认锁
MVCC
多版本并发控制
- 隐藏字段(事务id,undolog上个版本指针)
- undolog版本链:每个版本包括(事务id,回滚指针,数据)
- readview读视图:包含当前活跃的事务列
分库分表
为了解决单库并发量大,数据量大的问题:
- 垂直拆分:按业务拆分。
- 水平拆分:按数据行拆分。
分片算法
- 哈希取模
- 范围分片
- 一致性哈希
分库分表中间件
Mycat