1、认识Buffer Pool:
InnoDB存储引擎是基于磁盘存储的,它会使得 MySQL 中的数据存储在磁盘中,这样的话,读、写数据都需要与磁盘进行交互。而在数据库系统中,由于CPU速度与磁盘速度之间的鸿沟,通常会使用缓冲池技术来提高数据库的整体性能。缓冲池简单来说就是一块内存区域,是在++MySQL服务器启动时++被操作系统分配的一块连续的内存,其存在于存储引擎层,对于读操作:首先将数据从硬盘读取到内存,待到下次相同的查询时直接从内存中获取,这样就可以有效地减少磁盘 IO 次数。对于写操作:首先从磁盘获取数据到内存,然后修改内存中的缓存页,并在redo log进行记录,最后在合适的时机进行刷盘。
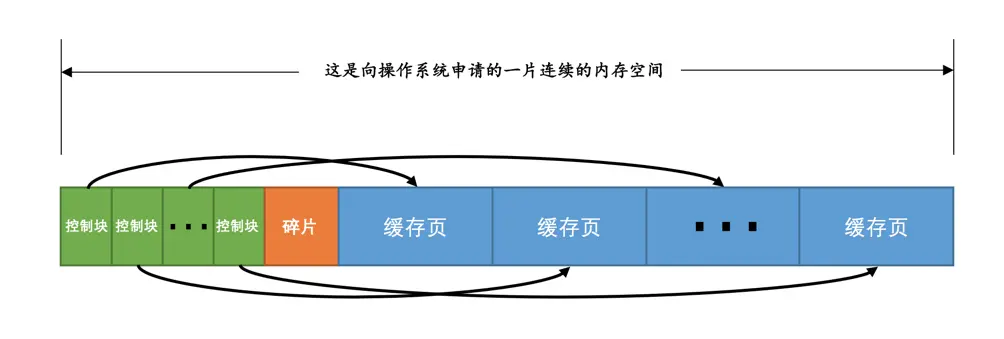
Buffer Pool中默认的缓存页大小和在磁盘上默认的页大小是一样的,都是16KB。为了更好的管理这些在Buffer Pool中的缓存页,设计InnoDB的大叔为每一个缓存页都创建了一些所谓的控制信息,这些控制信息包括该页所属的表空间编号、页号、缓存页在Buffer Pool中的地址、链表节点信息、一些锁信息以及LSN信息德等。
每个缓存页对应的控制信息占用的内存大小是相同的,我们就把每个页对应的控制信息占用的一块内存称为一个控制块,控制块和缓存页是一一对应的,它们都被存放到 Buffer Pool 中,其中控制块被存放到 Buffer Pool 的前边,缓存页被存放到 Buffer Pool 后边,所以整个 Buffer Pool 对应的内存空间看起来就是这样的:
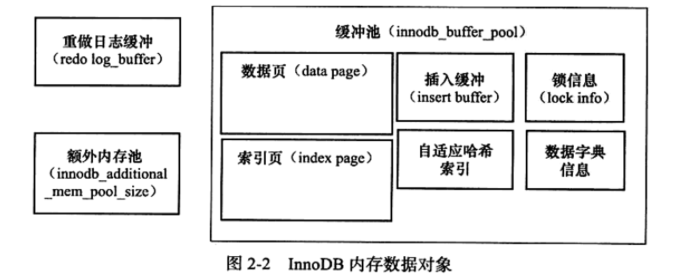
而内存中并不是只有数据页,还包括:索引页、undo页、插入缓冲、锁信息等,其结构情况如下图:
讲到这里,也许你会想到在执行一条sql语句时,通过连接器之后,不是会经过一次查询缓存吗,它和buffer poll又有什么区别呢?
查询缓存存在于 MySQL的 Server 层,存储着执行过的查询结果,但是只要对一张表进行更新时,这张表上的缓存就会被整个清空。你会发现,明明很费劲地才把查询结果存入缓存,但是还没用就被清空,简直是费力不讨好。于是,MySQL 8.0版本直接将查询缓存的整块功能删掉了。而对于表中数据更新时,buffer pool中的缓存数据并不像查询缓存一样整体失效,而是通过优化后的LRU算法将老化的数据从缓存中移除。
区别总结如下:
- 所处的层面不同
- 处理失效数据的方式不同
2、Buffer Pool内部结构:
- Free List:基于空闲缓存页对应的控制块组织起来的双向链表。主要解决了数据页被读取出来后不知道存放到 Buffer Pool 的哪个缓存页中的问题。
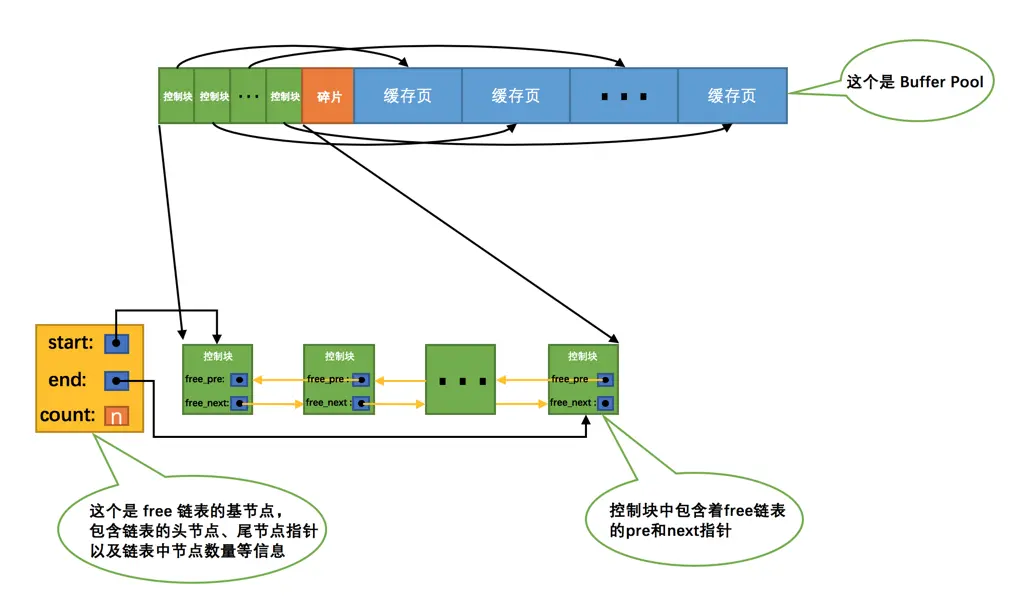
注:为了管理好这个free链表,特意为这个链表定义了一个基节点,里边儿包含着链表的头节点地址,尾节点地址,以及当前链表中节点的数量等信息。
通过上述 Free List 还没有完全解决将数据页存放到哪个缓存页的需求,比如如何判断该数据页是否已存在对应的缓存页。如果通过遍历的话,对于那么多的缓存页来说,效率明显不会高。而我们定位一个页是要通过 表空间号 + 页号 来定位的,那岂不是可以将 表空间号 + 页号 作为 key,缓存页作为 value,定义一个哈希表,这样就可以快速判断该数据页是否存在 Buffer Pool 中了。流程如下:
* 当从磁盘中读取出一个数据页并放到内存时,首先要根据++哈希表++判断该数据页是否已存在 Buffer Pool中,若存在则使用该缓存页即可,若不存在则先从 Free List 中找一个节点,通过该节点会找到对应的、未存放数据的缓存页,然后将数据页存放进该缓存页,并将该节点要移除出 Free List。
* 当缓存页中的数据被清空时,其描述信息又将被作为节点加入到 Free List 中。
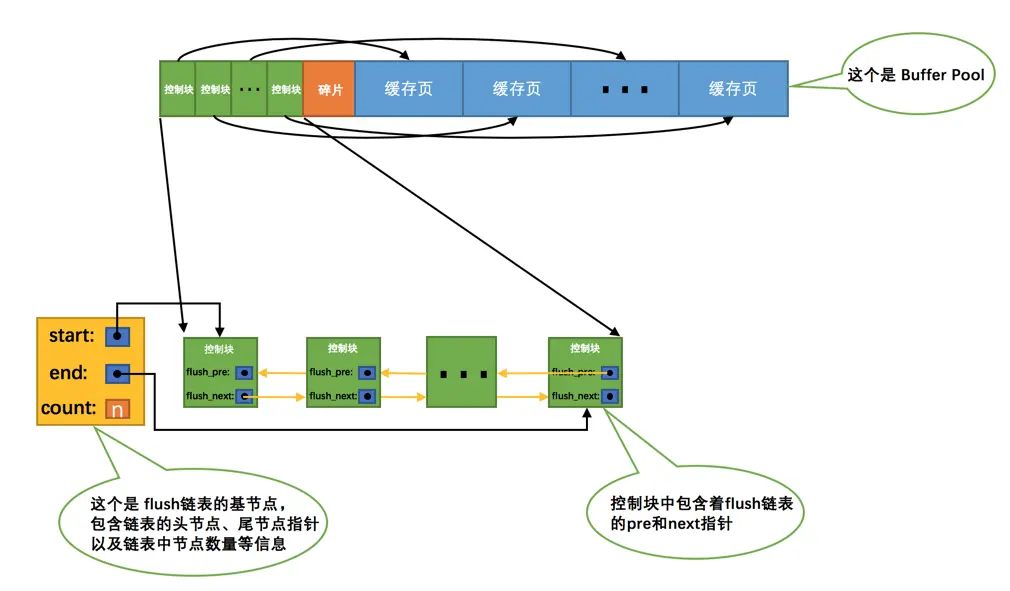
- Flush List:基于脏缓存页对应的控制块组织起来的双向链表,用来记录哪些缓存页需要进行刷盘。主要解决了在内存中修改后的数据与磁盘数据不一致的问题。
一旦对内存中的缓存页作出修改,那么该缓存页对应的控制块就会被添加进 Flush List 中。当 MySQL 进行刷盘时就会根据 Flush List 来判断要刷新哪一数据页。
- LRU List:基于缓存页控制块组织起来的双向链表。
对于传统的 LRU 链表,MySQL 的加载数据机制是:
- 如果该页不在 Buffer Pool 中,在把该页从磁盘加载到 Buffer Pool 中的缓存页时,并把该缓存页对应的控制块作为节点塞到链表的头部;
- 如果该页已经缓存在 Buffer Pool 中,则直接把该页对应的控制块移动到 LRU 链表的头部。
这样链表尾部的数据就是最近最少使用的数据了,当 Buffer Pool容量不足,或者后台线程主动刷新数据页时,就会优先刷新链表尾部的数据页。
但是 MySQL 存在预读机制,即 InnoDB 认为执行当前的请求可能之后会读取某些页面,就预先把它们加载到Buffer Pool中。其次,在执行全表扫描的 SQL 时,比如执行 select * from xxx 时,如果表中的数据页非常多,那这些数据页就会一一将 Buffer Pool 中的经常使用的缓存页挤下去,可能导致留在 LRU 链表中的全部是你不经常使用的数据。
为了减少 MySQL 预读机制对 LRU 链表的影响,利用冷热数据分离的思想,将 LRU List 分成了冷数据区(old区域)、热数据区(young区域)。
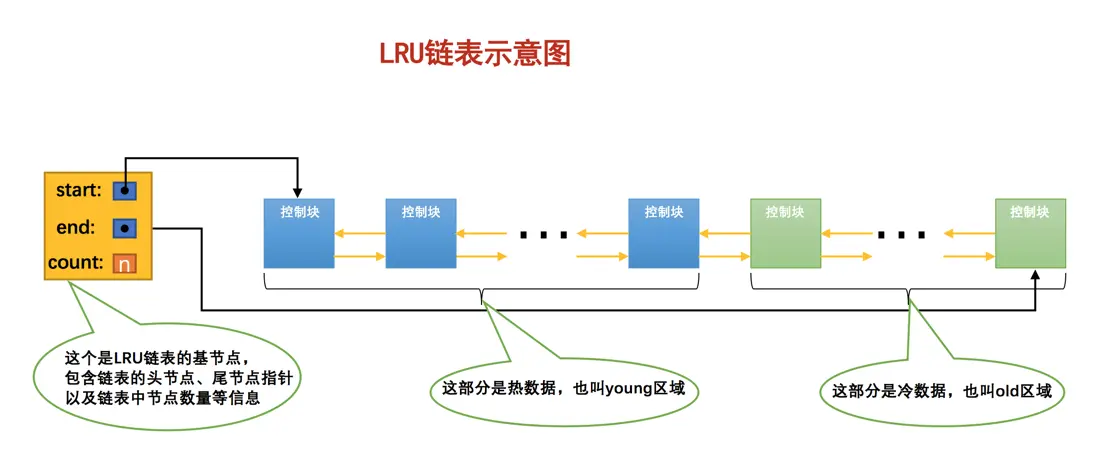
划分出冷热数据区后,针对预读场景:
当磁盘上的某个页面在初次加载到 Buffer Pool 中的某个缓存页时,该缓存页对应的控制块会被放到 old 区域的头部。这样针对预读到 Buffer Pool 却不进行后续访问的页面就会被逐渐从 old 区域逐出,而不会影响 young 区域中被使用比较频繁的缓存页。当 old 区域中的缓存页被再次访问后,该缓存页就会被提升至 young 区域。
针对全表扫描场景:
虽然首次被加载到 Buffer Pool 的页被放到了 old 区域的头部,但是后续会被马上访问到,每次进行访问的时候又会把该页放到 young 区域的头部,这样仍然会把那些使用频率比较高的页面给顶下去。对于该种场景,InnnDB 设计者们又添加了 innodb_old_blocks_time 这个系统变量,也就是说,从磁盘上被加载到 LRU 链表的 old 区域的某个页来说,如果第一次和最后一次访问该页面的时间间隔小于1s(很明显在一次全表扫描的过程中,多次访问一个页面中的时间不会超过1s),那么该页是不会被加入到young区域的。
综上所述,正是因为将 LRU 链表划分为 young 和 old 区域这两个部分,又添加了innodb_old_blocks_time 这个系统变量,才使得预读机制和全表扫描造成的缓存命中率降低的问题得到了遏制,因为用不到的预读页面以及全表扫描的页面都只会被放到 old 区域,而不影响 young 区域中的缓存页。
3、脏页刷盘:后台有专门的线程每隔一段时间负责把脏页刷新到磁盘,这样可以不影响用户线程处理正常的请求。主要有两种刷新路径:
- 从LRU链表的冷数据中刷新一部分页面到磁盘:后台线程会定时从LRU链表尾部开始扫描一些页面,扫描的页面数量可以通过系统变量innodb_lru_scan_depth来指定,如果从里边儿发现脏页,会把它们刷新到磁盘。这种刷新页面的方式被称之为BUF_FLUSH_LRU。
- 从flush链表中刷新一部分页面到磁盘:后台线程也会定时从flush链表中刷新一部分页面到磁盘,刷新的速率取决于当时系统是不是很繁忙。这种刷新页面的方式被称之为BUF_FLUSH_LIST。