1、MegaDepth介绍
MegaDepth是一个大型多视图立体视觉数据集,包含196个场景,每个场景是一个.npy文件,包含该场景的所有图像的相机参数和图像对信息,数据用于训练深度学习的特征匹配模型,如LoFTR、XFeat、RoMa等。
MegaDepth数据集地址:https://www.cs.cornell.edu/projects/megadepth/
(补充说明)
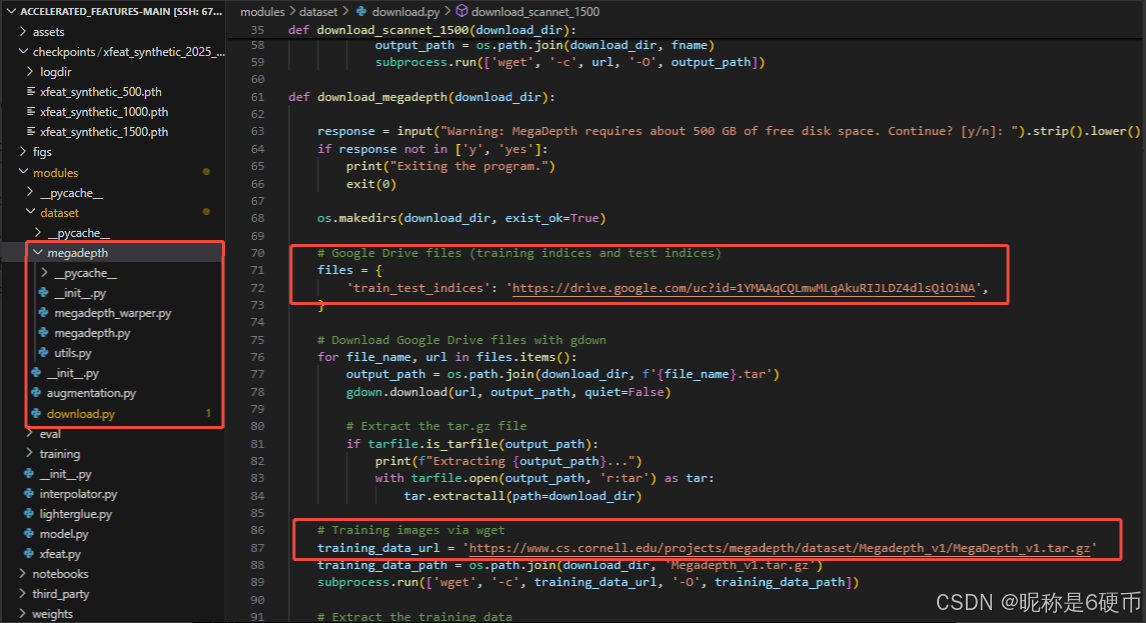
XFeat工程中的modules/dataset/download.py也指定了它所用的MegaDepth数据集地址,并且在modules/dataset/megadepth给出了数据处理的多个脚本,此外XFeat也提到了scannet_test_1500数据集。如下
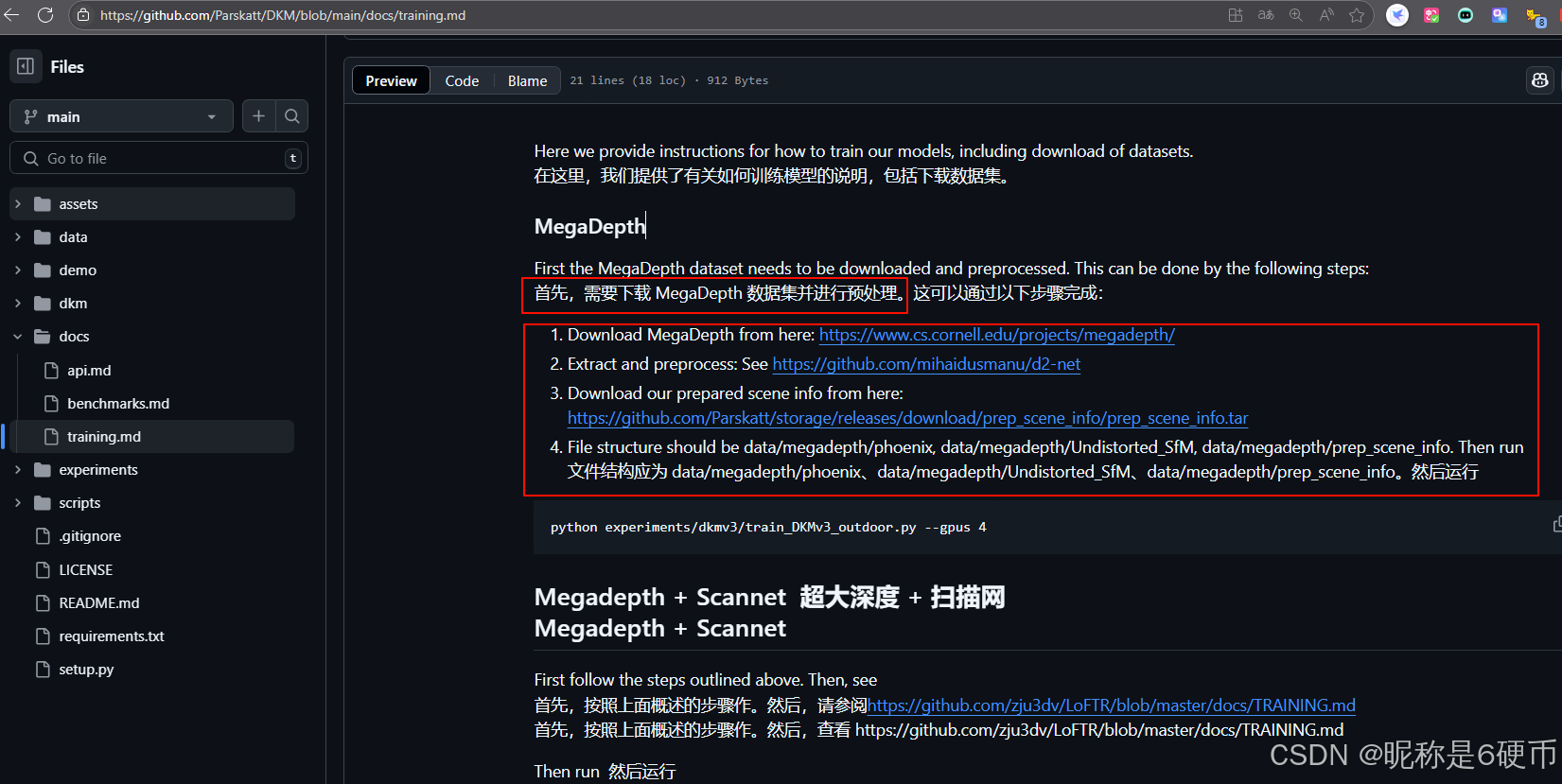
DKM工程中training.md也说明了MegaDepth数据集的下载和使用。如下
MegaDepth数据集是出自CVPR 2018论文 "MegaDepth: Learning Single-View Depth Prediction from Internet Photos",即"MegaDepth:从 Internet 照片中学习单视图深度预测",论文作者 李正琪 Noah Snavely(康奈尔大学/康奈尔理工学院)
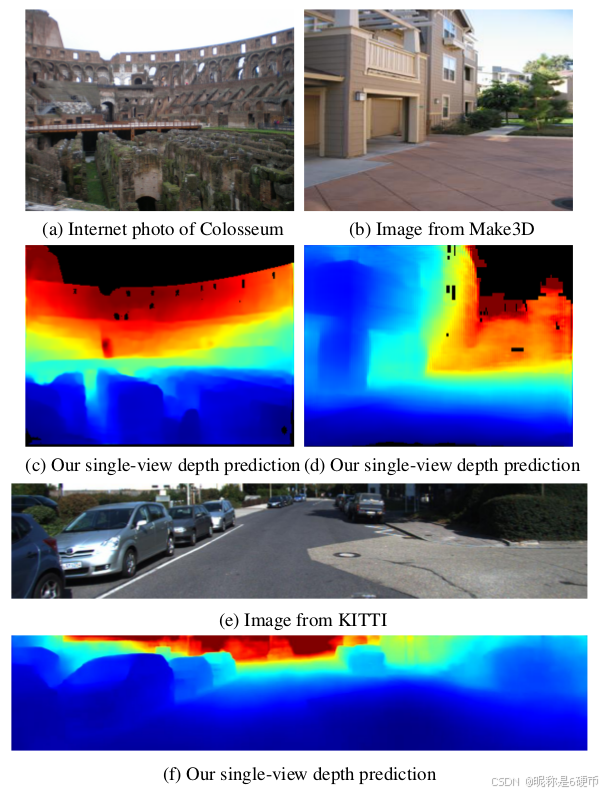
作者关于该数据集的介绍:我们使用大型 Internet 图像集合,结合 3D 重建和语义标注方法,生成大量训练数据,用于单视图深度预测。(a)、(b)、(e):输入 RGB 图像示例。(c)、(d)、(f):由 MegaDepth 训练的 CNN 预测的深度图(蓝色 = 近,红色 = 远)。对于这些结果,网络没有使用 Make3D 和 KITTI 数据进行训练。
MegaDepth论文摘要:单视图深度预测是计算机视觉中的一个基本问题。最近,深度学习方法取得了重大进展,但此类方法受到可用训练数据的限制。当前基于 3D 传感器的数据集存在关键局限性,包括仅限室内的图像 (NYU)、少量训练示例 (Make3D) 和稀疏采样 (KITTI)。我们建议使用多视图 Internet 照片集,一个几乎无限的数据源,通过现代运动结构(modern structure-from-motion)和多视图立体 (multi-view stereo,MVS) 方法生成训练数据,并基于这个想法提出了一个名为 MegaDepth 的大深度数据集。从 MVS 获得的数据有其自身的挑战,包括噪声和不可重建的对象。我们通过新的数据清理方法来应对这些挑战,并使用语义分割生成的序数深度关系自动增强我们的数据。我们验证了大量 Internet 数据的使用,结果表明在 MegaDepth 上训练的模型表现出很强的泛化---不仅对新场景,而且对其他不同的数据集(包括 Make3D、KITTI 和 DIW)都表现出很强的泛化性,即使在训练期间看不到来自这些数据集的图像。
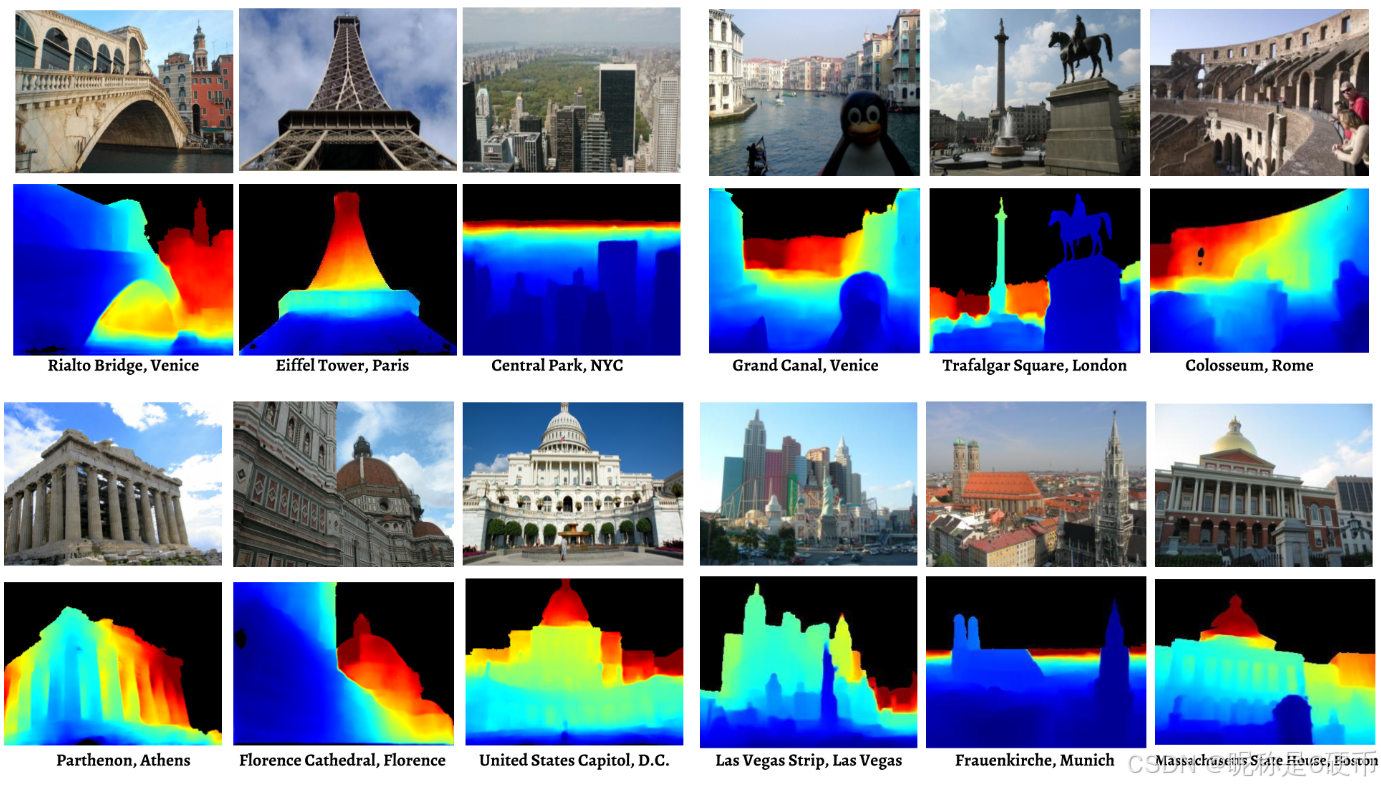
其中,互联网照片上的单视图深度预测示例:
2、MegaDepth官方更新动态
-
10/23/2018 更新说明
我们意识到论文原始版本中提出的一些评估存在问题。我们最初使用来自其他(非 MegaDepth)数据集的验证数据,在其他数据集上评估 MD 训练模型时,在某些情况下可以提前停止。尽管在实践中,当我们进行跨数据集评估时,避免由于数据集偏差而导致的过度拟合在技术上是正确的,但对于本文的具体实验,我们意识到只有将其他模型与在自己的数据集上训练和验证的模型进行比较是公平的。
因此,我们重做了所有实验,包括在所有数据集上运行我们的模型和其他模型,以确保所有预测都处于相同的评估指标中,并且我们更新了我们的论文,以展示在 MegaDepth 数据上训练和验证的模型的结果,正如最初预期的那样。我们还更新了 MegaDepth 测试集的结果,使其与已发布的公共数据集和模型保持一致。这些更新反映在表 1 到表 6 以及图 7、 8 和 9 (以及补充材料中的图表) 中。该论文已在 arXiv 上更新。
-
MegaDepth v1 Dataset
MegaDepth 数据集包括从 COLMAP SfM/MVS 重建的 196 个不同位置。(使用从 COLMAP MVS 生成的原始分辨率更新图像/深度图)
MegaDepth v1 Dataset (tar.gz, 199 GB)
MegaDepth v1 Dataset README (数据集自述文件)
-
MegaDepth v1 SfM models
我们还为全球所有 196 个地点提供 SfM 模型,每个模型包括 SIFT 特征位置、稀疏 3D 点云以及 COLMAP 和 Bundler 格式的相机内在/外在(intrinisics/extrinsics)。
-
用于后处理 MVS 深度的 MegaDepth 演示代码
应几个人的要求,我们提供了一个简单的演示代码,用于从 COLMAP 获取 MVS 深度,异常值明显较少,可用于训练网络(用 Matlab 编写)。
-
MegaDepth 训练/验证集列表
-
MegaDepth 测试集列表
-
用于 MegaDepth 测试集中 SDR 评估的预计算备用特征
-
Code
-
简单的演示训练代码
根据要求,我们提供了一个简单的演示训练代码。请注意,这不是完全有效的代码,但应该为您提供在 MegaDepth 数据集上训练网络的基本概念。
-
预训练模型
MegaDepth 预训练模型,如我们论文中所述。如果您想在论文中将您的算法与我们的算法进行数值和定性比较,请考虑使用这些模型。有关更多说明,请参阅 README。
任意户外 Internet 照片的 Demo 预训练模型(您可以在任何 Internet 照片上自己尝试)。注意:为澄清起见,此模型用于更通用的用途。我们使用 MegaDepth 和 DIW 数据集训练了网络,并在 DIW 网站上的 NYU/DIW 预训练权重上对其进行了预训练。因此,它可能具有比论文中描述的更好的性能
3、MegaDepth数据集说明
下载下来的数据集主要包含MegaDepth_v1文件夹和megadepth_indices文件夹即可用于训练配准模型。
-
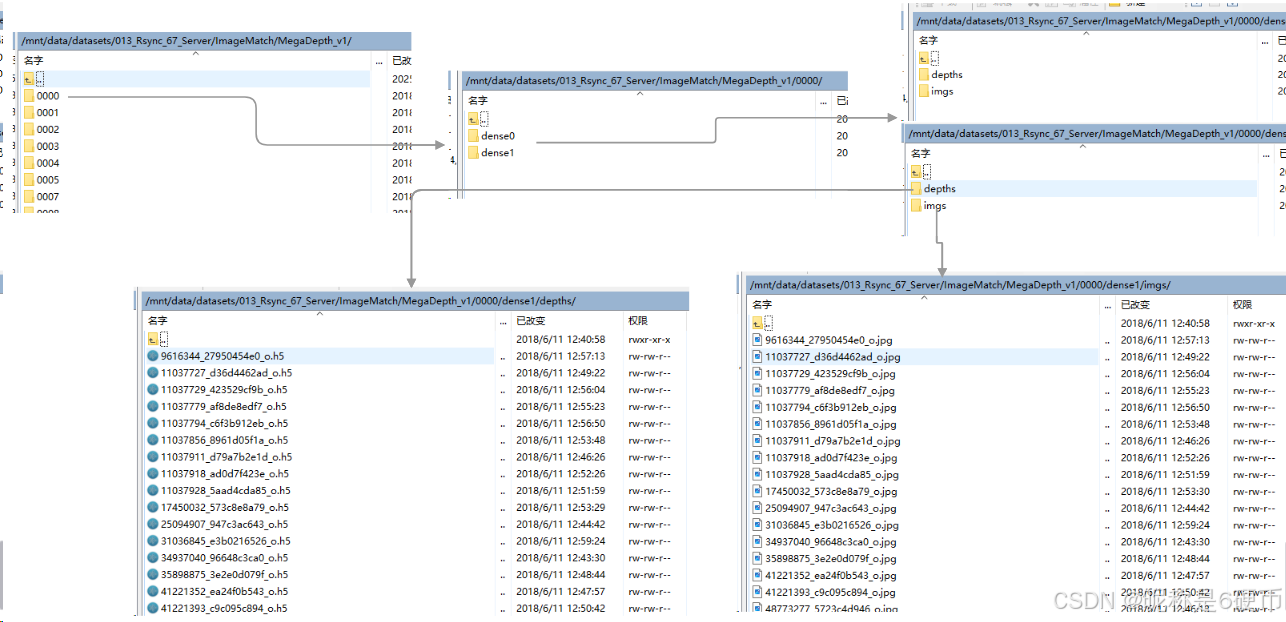
MegaDepth_v1:存放各种场景的RGB图像(.jpg)和深度文件(.h5) -
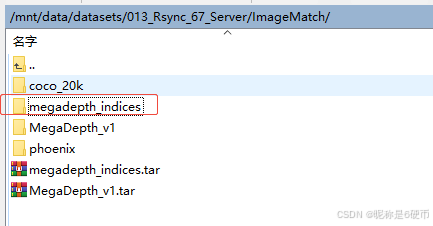
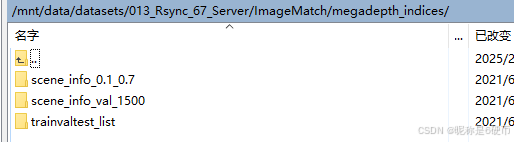
megadepth_indices:主要包含三个文件夹scene_info_0.1_0.7、scene_info_val_1500、trainvaltest_list
【注意】我这里是参考XFeat的源码使用方式,直接将外层嵌套的Undistorted_SfM、phoenix/S6/zl548/MegaDepth_v1/文件夹进行了删除,然后XFeat代码会进行路径替换,XFeat相关代码如下:
Python
self.scene_info = np.load(npz_path, allow_pickle=True) # npz_path是场景信息文件,在scene_info_0.1_0.7文件夹中
for idx in range(len(self.scene_info['image_paths'])):
self.scene_info['image_paths'][idx] = fix_path_from_d2net(self.scene_info['image_paths'][idx])
for idx in range(len(self.scene_info['depth_paths'])):
self.scene_info['depth_paths'][idx] = fix_path_from_d2net(self.scene_info['depth_paths'][idx])
# 其中的fix_path_from_d2net函数用于替换外层的Undistorted_SfM、phoenix/S6/zl548/MegaDepth_v1/文件夹
def fix_path_from_d2net(path):
if not path:
return None
path = path.replace('Undistorted_SfM/', '')
path = path.replace('images', 'dense0/imgs')
path = path.replace('phoenix/S6/zl548/MegaDepth_v1/', '')
return path(当然,也可以不删除嵌套文件夹而是简单修改一下XFeat源码将路径对应上即可,因为毕竟数据集场景信息npz文件中记录的image_paths和depth_paths都是基于包含嵌套文件夹的相对路径,而且其它配准算法多是严格按照MegaDepth的格式去设计读取逻辑的,总之,路径对应上即可)
MegaDepth_v1结构如下:
megadepth_indices结构如下:
里面包含:
场景信息文件夹(scene_info_0.1_0.7)每个.npz文件保存了一个场景的配准信息,每一个场景都涵盖很多可以配对的图像等等内容。
每个.npz文件保存了一个场景的完整配准信息,包括图像路径、配对关系、相机参数、3D点云等。这些信息可以用于图像匹配、3D重建等任务。具体包含了['image_paths', 'depth_paths', 'intrinsics', 'poses', 'pairs', 'overlaps']
完整示例代码:加载并查看.npz文件内容
Python
import numpy as np
# 加载npz文件
scene_info = np.load('scene_info.npz', allow_pickle=True)
# 查看内容
print("Image paths:", scene_info['image_paths'])
print("Pair infos:", scene_info['pair_infos'])
print("Intrinsics:", scene_info['intrinsics'])
print("Poses:", scene_info['poses'])进一步地,可以查看详细的总的场景数量、总的配对数量、总的图像数量、平均每个场景的配对的数量、平均每个场景的图像数、平均每个场景的重叠分数,代码如下:
Python
import os
import numpy as np
import glob
from tqdm import tqdm
from PIL import Image
def fix_path_from_d2net(path):
if not path:
return None
path = path.replace('Undistorted_SfM/', '')
path = path.replace('images', 'dense0/imgs')
path = path.replace('phoenix/S6/zl548/MegaDepth_v1/', '')
return path
def analyze_megadepth(MegaDepth_v1_path, npz_root, save_dir=None):
"""
分析MegaDepth数据集,统计配准图像对和标签数量,并可选择保存配对图像
参数:
MegaDepth_v1_path (str): MegaDepth数据集根目录
npz_root (str): 包含.npz文件的目录路径
save_dir (str): 保存配对图像的目录路径,如果为None则不保存
"""
# 获取所有场景的npz文件
npz_paths = glob.glob(os.path.join(npz_root, '*.npz'))
# 初始化统计变量
total_scenes = 0
total_pairs = 0
total_images = 0
overlap_scores = []
# 创建保存目录
if save_dir is not None:
os.makedirs(save_dir, exist_ok=True)
print(f"Analyzing {len(npz_paths)} scenes...")
# 遍历每个场景
for npz_path in tqdm(npz_paths):
# 加载场景信息
scene_info = np.load(npz_path, allow_pickle=True)
# 统计信息
total_scenes += 1
total_pairs += len(scene_info['pair_infos'])
total_images += len(scene_info['image_paths'])
# 收集重叠分数
for pair_idx, pair_info in enumerate(scene_info['pair_infos']):
# 检查pair_info结构是否正确
if len(pair_info) >= 2 and isinstance(pair_info[1], (int, float)):
overlap_scores.append(pair_info[1])
else:
print(f"Warning: Invalid pair_info structure in {npz_path}, pair {pair_idx}")
# # 保存配对图像
if save_dir is not None:
img1_path = os.path.join(MegaDepth_v1_path, scene_info['image_paths'][pair_info[0][0]])
img2_path = os.path.join(MegaDepth_v1_path, scene_info['image_paths'][pair_info[0][1]])
img1_path = fix_path_from_d2net(img1_path)
img2_path = fix_path_from_d2net(img2_path)
# 读取并保存图像
try:
img1 = Image.open(img1_path)
img2 = Image.open(img2_path)
# 创建保存路径
scene_id = os.path.splitext(os.path.basename(npz_path))[0]
pair_id = f"{scene_id}_pair_{pair_idx:04d}"
pair_dir = os.path.join(save_dir, pair_id)
os.makedirs(pair_dir, exist_ok=True)
# 保存图像
img1.save(os.path.join(pair_dir, "img1.jpg"))
img2.save(os.path.join(pair_dir, "img2.jpg"))
# 保存配对信息
with open(os.path.join(pair_dir, "info.txt"), 'w') as f:
f.write(f"Image1: {img1_path}\n")
f.write(f"Image2: {img2_path}\n")
f.write(f"Overlap score: {pair_info[1] if len(pair_info) >= 2 else 'N/A':.3f}\n")
except Exception as e:
print(f"Error processing pair {total_pairs}: {e}")
# 计算统计信息
avg_pairs_per_scene = total_pairs / total_scenes
avg_images_per_scene = total_images / total_scenes
avg_overlap = np.mean(overlap_scores) if overlap_scores else 0 # 处理空列表情况
# 打印结果
print("\n=== MegaDepth Dataset Analysis ===")
print(f"Total scenes: {total_scenes}")
print(f"Total image pairs: {total_pairs}")
print(f"Total unique images: {total_images}")
print(f"Average pairs per scene: {avg_pairs_per_scene:.1f}")
print(f"Average images per scene: {avg_images_per_scene:.1f}")
print(f"Average overlap score: {avg_overlap:.3f}")
if __name__ == '__main__':
# 设置MegaDepth数据集路径
megadepth_root = '/mnt/data/datasets/013_Rsync_67_Server/ImageMatch/MegaDepth_v1' # 替换为实际路径
npz_root = '/mnt/data/datasets/013_Rsync_67_Server/ImageMatch/megadepth_indices/scene_info_0.1_0.7' # 包含.npz文件的目录
save_dir = './megadepth_pairs' # 保存配对图像的目录
# 运行分析
analyze_megadepth(megadepth_root, npz_root, save_dir)最终打印结果:
Python
=== MegaDepth Dataset Analysis ===
Total scenes: 441
Total image pairs: 11174617
Total unique images: 695023
Average pairs per scene: 25339.3
Average images per scene: 1576.0
Average overlap score: 0.216注意到总的图像数量远小于总的配对数量,即Total unique images远小于Total image pairs的原因主要有以下几点:
1、图像复用:在MegaDepth数据集中,同一张图像可能会与多张其他图像形成配对。例如,假设有3张图像A、B、C,它们可以形成3对:(A,B)、(A,C)、(B,C)。这里只有3张unique images,但形成了3对。
-
密集匹配:MegaDepth数据集的设计目的是进行密集的3D重建,因此每个场景中的图像会与多个其他图像进行匹配,以建立完整的3D模型。这种设计导致了大量的图像对。
-
场景结构:每个场景通常包含数十到数百张图像,这些图像之间会形成大量的配对关系。例如,一个包含100张图像的场景,理论上可以形成C(100,2) = 4950对图像。
2、重叠要求:MegaDepth在生成配对时,要求图像之间有一定的重叠区域(通常由overlap score控制),这进一步增加了配对数量。
Total unique images: 695,023
Total image pairs: 11,174,617
这个比例是合理的,因为每个unique image平均与约16个其他图像形成配对(11,174,617 / 695,023 ≈ 16),这符合MegaDepth数据集的设计特点。
这种设计对于3D重建任务是有益的,因为它提供了丰富的视角信息和匹配关系,有助于构建更完整和准确的3D模型。
完整配准信息说明:
-
image_paths: 图像文件相对路径数组,包含该场景的所有图像 -
depth_paths: 对应的深度图文件路径(.h5格式) -
intrinsics: 相机内参矩阵数组(3x3),包含焦距和主点信息 -
poses: 相机位姿矩阵数组(4x4),表示相机在世界坐标系中的位置和朝向 -
pairs: 图像对索引数组(Nx2),定义哪些图像之间可以进行匹配 -
overlaps: 对应图像对的重叠度数组,用于训练时的样本选择
使用方式:
-
训练时根据重叠度阈值筛选合适的图像对
-
低重叠度对(0.01-0.1)用于学习困难匹配
-
高重叠度对(0.3+)用于学习简单匹配
-
通过内参和位姿可以计算相对位姿变换