Vanna 是一个结合了检索增强生成(RAG, Retrieval-Augmented Generation) 和 交互式数据库查询的 AI agent 开源框架,专为自然语言与数据库交互的场景设计。它允许用户通过自然语言提问,自动生成 SQL 查询并连接数据库执行,最终返回人类可读的结果。Vanna 框架有高度的可拓展性,支持自定义向量数据库用于存储 embedding,并可连接和查询任意数据库。
DolphinDB 提供的文本存储引擎(TextDB)和向量存储引擎(VectorDB)可用于实现 RAG 的知识库。本文介绍如何使 Vanna 框架适配 DolphinDB,存储 DolphinDB 的文档文本以及对应的 embedding 向量到 DolphinDB,然后让 Vanna 框架能够连接和查询 DolphinDB,并生成 DolphinDB 语义的 SQL 或脚本。基于 DolphinDB 实现的 RAG 框架具有如下优势:
- 支持海量文本与向量数据的高效检索和响应。
- 提供丰富且便利的计算函数可用于数据处理。
- 一站式实现存储、检索与计算。
1. 关键组件
1.1 TextDB
DolphinDB 在 3.00.2 版本中,推出了基于倒排索引的文本存储引擎(TextDB)。TextDB 能够为主键存储引擎( PKEY) 中的文本数据建立倒排索引,使得用户在对有倒排索引的文本列上进行全文检索时,性能得到显著提升,满足现代应用对海量文本数据高效检索与快速响应的需求。本教程使用 TextDB 存储分片的 DolphinDB 函数文档文本。
1.2 VectorDB
DolphinDB 在 3.00.1 版本中,基于 TSDB 存储引擎,开发并实现了支持向量检索的向量存储引擎(VectorDB)。VectorDB 针对 TSDB 中以数组向量(Array Vector)形式存储的向量数据,引入了向量检索技术。它支持对向量数据创建索引,并实现了快速的近似最近邻搜索,满足现代应用场景下对海量数据高效检索和响应的需求。本教程使用 VectorDB 存储文档文本的 embedding 向量。
1.3 Vanna
Vanna 是一个开源的 AI agent 框架,作为一个 Python 包使用,通过检索增强(Retrieval Augmentation)技术,帮助用户利用大语言模型为数据库生成精准的 SQL 查询。核心工作原理为:
- 训练 RAG "模型":基于数据(如数据库结构、历史查询等)训练一个检索增强生成模型。
- 提问生成 SQL:输入自然语言问题后,Vanna 会自动生成对应的 SQL 查询,并可配置为直接在数据库上执行。
本教程通过继承 VannaBase 类为 DolphinDBVanna 类并重写相关方法来使 Vanna 框架适配 DolphinDB。
1.4 DolphinDB Python API
dolphindb 是 DolphinDB 的官方 Python API,用于连接 DolphinDB 服务端和 Python 客户端,从而实现数据的双向传输和脚本的调用执行。dolphindb 可以方便您在 Python 环境中调用 DolphinDB 进行数据的处理、分析和建模等操作,利用其优秀的计算性能和强大的存储能力来帮助您加速数据的处理和分析。本教程使用 Python API 来连接 DolphinDB 和执行查询等操作。
2. 系统流程
提高 RAG 系统的准确性的一个关键是能否提供合适的上下文给大模型,而目前主流的大模型并不擅长 DolphinDB 脚本的编写,因此我们存储 DolphinDB 文档的切片来作为大模型的知识库,然后对于每次问答,我们利用 VectorDB 和 TextDB 的索引功能快速查询出相关文档,作为上下文提供给大模型,从而使大模型能够了解 DolphinDB 的相关函数的用法。整体处理流程图如下:

图 2.1 DolphinDB + Vanna 问答系统流程图
整体流程与 Vanna 框架的官方流程(https://vanna.ai/docs/)基本相同,为了更高地准确率,我们引入了分词与重排序的步骤。具体步骤说明:
-
调用 LLM 对原始问题提取出关键词;
-
分 2 种途径检索相关文档:
a. 直接使用关键词,查询 TextDB 进行文本匹配; b. 先调用 embedding 模型计算关键词的 embedding,然后查询 VectorDB 进行向量检索;
-
对检索的文档根据 id 去重,得到相关的前 n+ 份文档;
-
调用 rerank 模型对检索的文档做重排序,得到最相关的前 k 份文档;
-
结合相关文档和问题来编写 prompt,调用 LLM 得到回答文本和脚本;
-
连接 DolphinDB 执行脚本。
a. 若无报错,输出回答和脚本执行结果;
b. 若有报错,且用户在 Vanna web 前端点击纠错按钮,则结合相关文档、错误回答、报错信息来编写提示,再 次调用 LLM 来纠正回答;
-
输出回答文本和脚本。
3. 接口说明
3.1 配置项
DolphinDBVanna 类是后端的核心类,支持 Vanna 官方的配置项,这里介绍需要额外配置的配置项。通过在构造时传入一个 config 字典来配置。

3.2 主要接口
这里介绍一些重要的接口功能、实现原理和注意事项,包括对 Vanna 官方定义的接口的修改和使用说明。
3.2.1 train
train 接口用于训练 RAG 框架,实际操作是对问题和答案计算 embedding,然后存储到向量数据库中。该接口实际上是一个封装接口,会根据不同的入参来调用如下不同接口:
- add_ddl: 计算 DDL 文本的 embedding 并存储到向量数据库。
- add_document: 计算文档文本的 embedding 并存储到向量数据库。
- add_question_sql: 计算问题-SQL对的 embedding 并存储到向量数据库。
我们重写了上述接口,使用 python 的 request 库来请求远程大模型,并使用 DolphinDB Python API 来连接指定的 DolphinDB 节点,写入文本和向量数据。
使用示例:
ini
vn.train(ddl='''
create database "dfs://test"
partitioned by VALUE(1..10), HASH([SYMBOL, 40])
engine='TSDB'
''')3.2.2 ask
ask 接口用于提问,会自动将提问转换为 SQL 或 DolphinDB 脚本并执行,可通过参数启用自动画图和训练。我们主要重写了 ask 调用的 extract_sql 接口,将提取回答中以 DolphinDB 标签包含的脚本内容来执行。
使用示例:
arduino
vn.ask("查询merge_TB库的merge_tradeTB表的前100条数据")注: 为了避免该接口自动执行 SQL 或脚本引发性能或安全问题,建议配置一个仅有分布式库表读权限的账号使用 Vanna,且限制其查询内存大小,详见用户权限管理。
3.2.3 generate_sql
ask 接口会执行 SQL、绘图、训练等多种操作,响应速度相对较慢。同时,其自动执行生成的 SQL 或脚本可能带来性能或安全风险。如果只需要 LLM 根据相关文档生成 SQL 或脚本,而不需要执行、绘图、训练等后续操作,可以使用 generate_sql 接口。
使用示例:
arduino
vn.generate_sql("在DolphinDB怎么做全连接?")4. DolphinDB 脚本问答系统实现
4.1 建库建表
需要在 DolphinDB 中创建用于存储文档文本内容及其 embedding 向量的库表。设计库表字段如下:
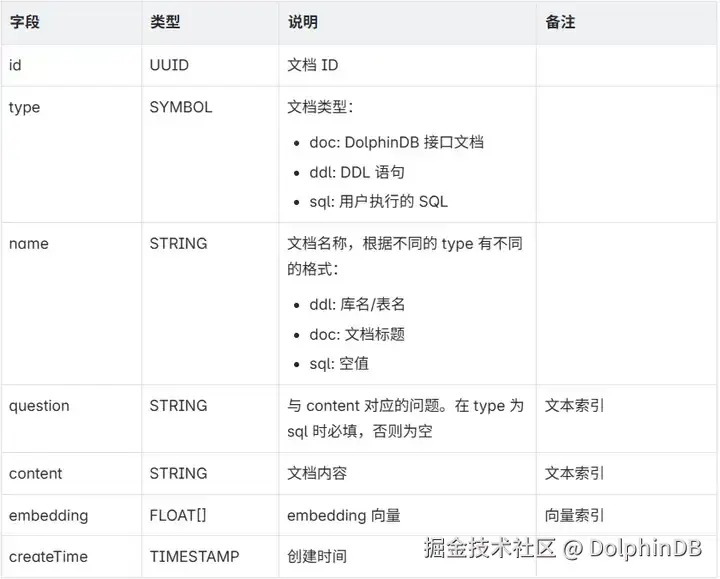
对应的建库建表语句如下:
ini
db = database(dbpath, VALUE, 2025.01.01..2025.12.31, engine="PKEY")
schemaTb = table(1:0, `id`type`name`question`content`embedding`createTime, [UUID, SYMBOL, STRING, STRING, STRING, FLOAT[], TIMESTAMP])
pt = createPartitionedTable(
dbHandle=db,
table=schemaTb,
tableName=tbname,
partitionColumns=`createTime,
primaryKey=`createTime`id,
indexes={
"question":"textindex(parser=chinese,full=false,lowercase=true,stem=true)",
"content":"textindex(parser=chinese,full=false,lowercase=true,stem=true)",
"embedding":"vectorindex(type=flat, dim=1536)"
}
)关键参数说明:
- 建库时指定 engine="PKEY",即使用主键存储引擎;建表时配置 id 为主键,从而能够根据 id 高效地读写记录。
- 建表时为 question 和 content 列配置文本索引,从而支持快速计算关键词匹配。
- 建表时为 embedding 列配置向量索引,从而支持快速计算向量近似检索。
4.2 训练
在使用 Vanna 前,需要首先对已有的文本文档进行切片、计算 embedding 和存储,从而使 Vanna 能够在问答时查询参考文档。文本文档分为三种类型:
- sql: 用户执行的 SQL
- doc: 接口文档
- ddl: DDL 语句
本节介绍如何导入自定义的问题-SQL 对、DolphinDB 接口文档、已有库表的 DDL 语句。
4.2.1 导入自定义的问题-SQL 对
根据 Vanna 官方的训练建议,提升回答准确率的最重要的训练数据是问题-SQL 对,即对于一个提问,使用怎样的 SQL 来回答,这些数据能够使 LLM 理解并更准确地回答相似问题。该训练集需要结合实际数据编写,例如存在库 dfs://level2 和 snapshot 表,存储 level2 的快照数据,那么一条对应的问题-SQL 对可以是 "查询 2025.04.27 日期的 level2 快照数据的前 10 条"-"select top 10 * from loadTable('dfs://level2', 'snapshot') where TradeDay = 2025.04.27 limit 10",表示该问题可以用该 SQL 来回答。我们重写了 VannaBase 类的 add_question_sql 接口,可以在 python 调用该接口添加一条新的问题-SQL 对,使用示例:
bash
vn.add_question_sql(
"查询 2025.04.27 日期的 level2 快照数据的前 10 条",
"select top 10 * from loadTable('dfs://level2', 'snapshot') where TradeDay = 2025.04.27"
)
# 或
vn.train(
question="查询 2025.04.27 日期的 level2 快照数据的前 10 条",
sql="select top 10 * from loadTable('dfs://level2', 'snapshot') where TradeDay = 2025.04.27"
)4.2.2 文档处理与导入
可以对 DolphinDB 的接口文档进行切片,计算 embedding 并导入到知识库,从而使 Vanna 提问时能够知道有哪些接口可以调用,生成更合理的 SQL 语句或脚本。我们编写了一段 DolphinDB 脚本来对 DolphinDB 官方文档进行处理与导入,整体流程为:
- 递归读取指定文件夹下的所有 md 文件,读取内容并写入到指定的 csv 文件里;
- 加载 csv 并逐行遍历,对过长的行做切片;
- 使用 httpClient 插件请求外部 embedding 模型,计算切片的 embedding;
- 将文档切片和 embedding 写入到知识库。
完整脚本见附件 import.dos 的 importDoc 方法。
另外,我们重写了 VannaBase 类的 add_documentation 接口,也可以在 python 调用该接口添加一条新的文档,使用示例:
ini
vn.add_documentation("定义了函数视图 xxx 用于查询 xxx")
# 或
vn.train(documentation="定义了函数视图 xxx 用于查询 xxx")4.2.3 DDL 语句生成与导入
可提取 DolphinDB 当前库表的建库建表语句,计算其 embedding 并导入知识库,从而提升 Vanna 在提问时对库表结构的理解,生成更合理的 SQL 或脚本。我们编写了一段 DolphinDB 脚本来提取所有库表的 DDL 语句做处理并导入,整体流程为:
- 遍历 DolphinDB 的所有库名和表名,使用 ops 模块的 getDatabaseDDL 和 getDBTableDDL 方法提取出对应的 DDL 语句;
- 使用 httpClient 插件请求外部 embedding 模型,计算 DDL 语句的 embedding;
- 将 DDL 语句和 embedding 写入到知识库。
完整脚本见附件 import.dos 的 importDDL 方法。
另外,我们重写了 VannaBase 类的 add_ddl 接口,也可以在 python 调用该接口添加一条新的文档,使用示例:
python
vn.add_ddl('''
create database "dfs://test"
partitioned by VALUE(1..10), HASH([SYMBOL, 40])
engine='TSDB'
''')
# 或
vn.train(ddl='''
create database "dfs://test"
partitioned by VALUE(1..10), HASH([SYMBOL, 40])
engine='TSDB'
''')4.3 文档关键词匹配
DolphinDB 提供了多种文本索引查询函数来查询已建立文本索引的列。本教程使用 matchAny 函数来进行关键词匹配,即查询包含任意给定词语的文档文本。例如在 get_related_ddl 接口中,查询匹配关键字的 DDL 语句使用了如下 SQL:
csharp
select id, question, content, embedding from loadTable("{self.db_name}", "{self.tb_name}")
where type == "ddl" and matchAny(content, keywords)注: 注意文本存储引擎存在一些使用限制,若自定义或修改接口,请确定查询能正常触发文本索引加速。
4.4 向量相似度检索
DolphinDB 提供了 rowEuclidean 函数来查询已建立向量索引的列,即计算输入向量与指定向量列的欧式距离。例如在 get_related_ddl 接口中,查询距离关键字 embedding 最近的 DDL 语句使用了如下 SQL:
csharp
select id, question, content, embedding from loadTable("{self.db_name}", "{self.tb_name}")
where type == "ddl"
order by rowEuclidean(embedding, embedding_) asc
limit {self.top_n}注: 注意向量存储引擎存在一些使用限制,若自定义修改接口,请使用 HINT_EXPLAIN 确定查询能正常触发向量索引加速。
5. 依赖
执行如下命令安装依赖:
pip install dolphindb
pip install vanna离线安装 dolphindb 包可参考《离线安装 Python API》。
6. 使用案例
注: LLM 的幻觉问题目前依然无法完全避免,请注意甄别回答的正确性。
在首次使用前,需要连接配置的 DolphinDB 数据节点,修改附件的 import.dos 内的相关配置项并全选执行,创建 Vanna 的后端库表并导入 DolphinDB 文档和 DDL 定义。
Vanna 官方提供了开箱即用的 web 应用,可以在 jupyter notebook 里启动或独立启动。启动前需要参照《配置项》一节填写附件 demo.py 内的配置项,然后可以使用如下命令启动 web 应用:
python demo.py命令行会输出 Vanna web 应用的默认地址为 http://localhost:8084,使用浏览器前往该地址,可见页面如下:
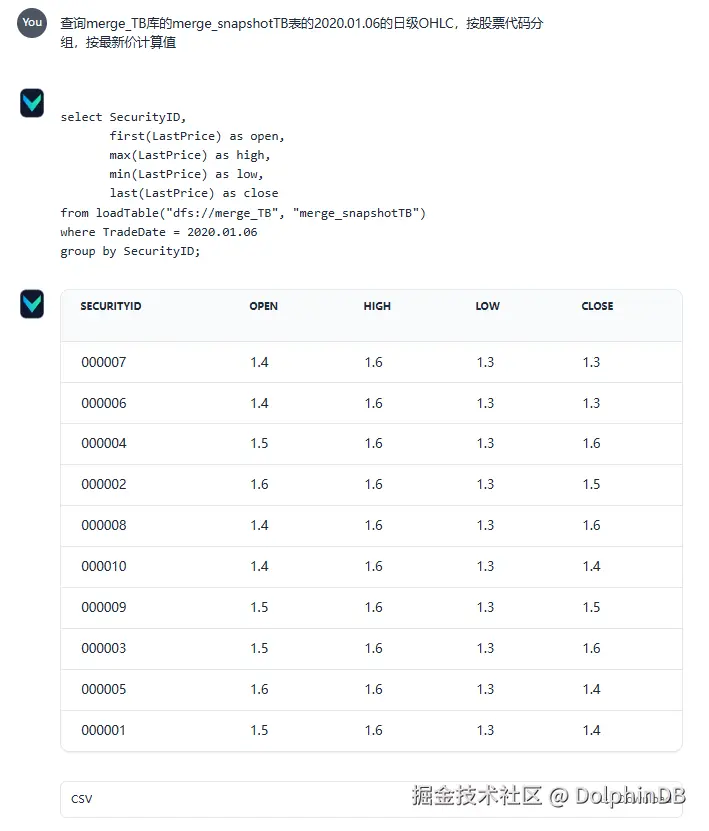
输入查询问题后,Vanna 会自动生成对应的 SQL,执行查询并返回结果。
接着 Vanna 会尝试对结果进行绘图,并用文本总结结果:
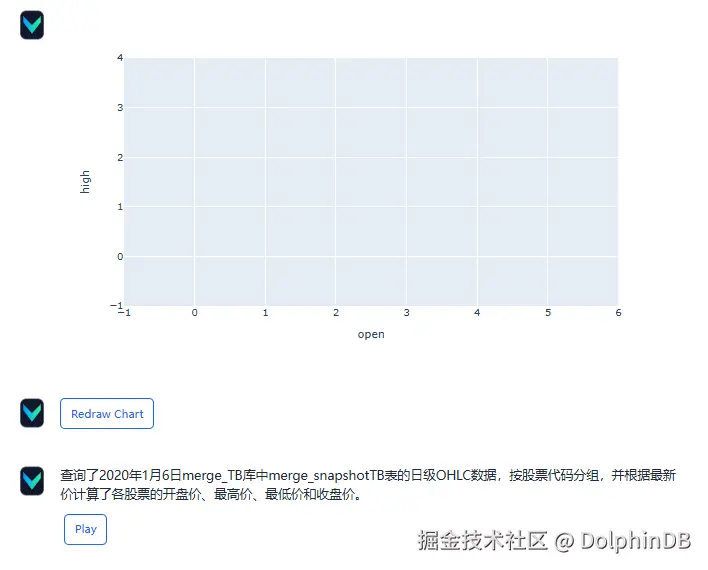
然后 Vanna 会询问该回答是否正确,可见除了绘图以外均正确,可以点击 Yes, train as Question-SQL pair 按钮将本次回答存储为训练数据(绘图结果不参与训练):

最后 Vanna 会给出一些 followup 问题,可以直接点击询问:

下面展示回答错误的情况,询问一个比较困难的问题:
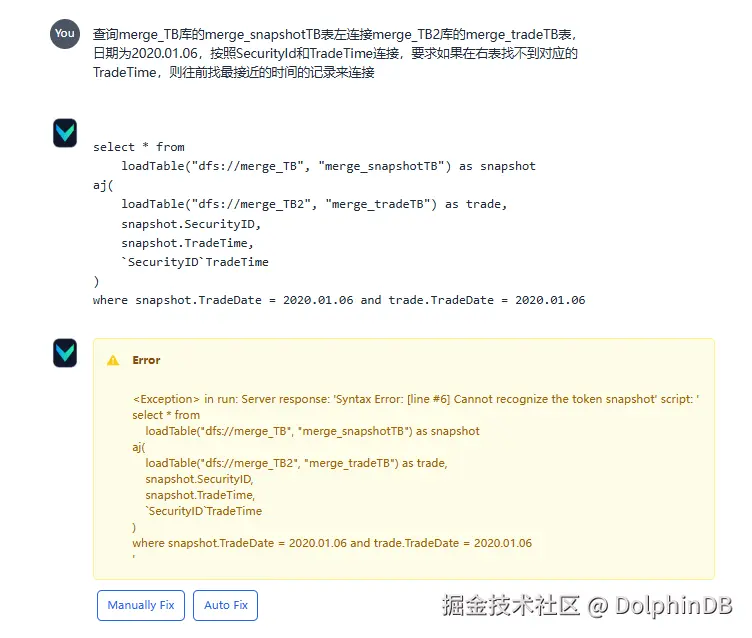
可以点击 Auto Fix 来让 Vanna 根据错误信息自动纠错,但依然回答错误:
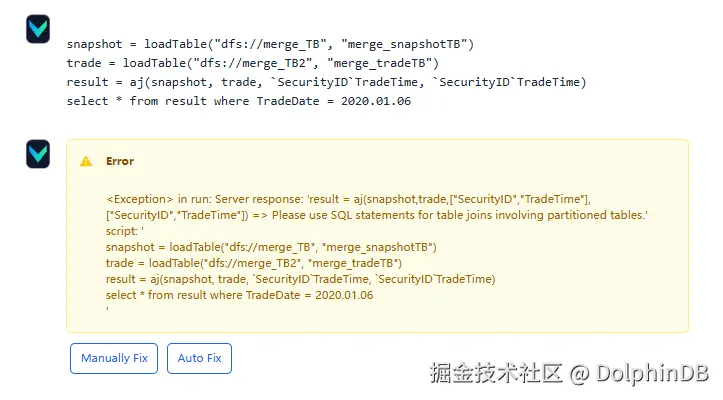
由于缺少正确的问题-SQL对示例,加上 asof join 是 DolphinDB 独特的语法,Vanna 很难给出正确答案。此时我们可以点击 Manually Fix 按钮手动给出答案:

可见查出了正确的结果,可以点击 Yes, train as Question-SQL pair 按钮将其存储为训练数据,这样下次提出类似问题时,Vanna 更有可能给出正确的答案。

新建一个会话,然后再次询问同样的问题,可见 Vanna 能够根据上次的回答给出正确的答案:
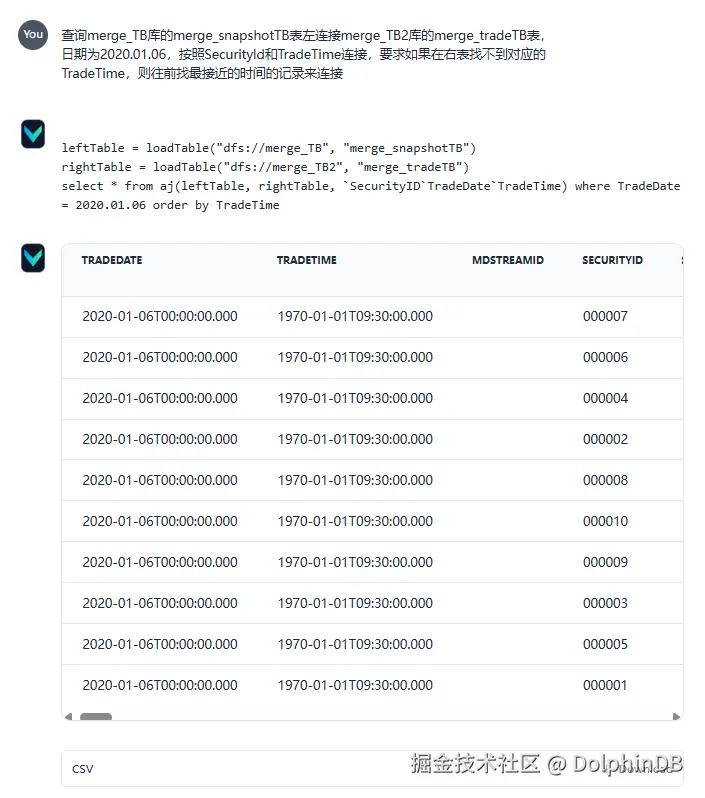
另外查看启动程序的终端,可以看到打印了相关日志,可用于调试程序:

7. 总结
DolphinDB 凭借其高性能的文本存储引擎(TextDB)和向量存储引擎(VectorDB),为 Vanna 这一融合 RAG 与交互式数据库查询的 AI 框架提供了理想的底层支持。借助 DolphinDB,Vanna 能够高效处理海量文本与向量数据、利用丰富计算函数优化提示工程,并实现一站式数据存储、检索与分析,充分展现了 DolphinDB 在 AI 增强数据库场景下的卓越性能与扩展优势。