Spring Boot 敏感词过滤组件实现
本文将介绍如何在Spring Boot项目中实现一个高效的敏感词过滤组件,包含两种实现方式:基于DFA算法的优化版本和简单直接的实现版本。
组件功能:
-
从文件加载敏感词库
-
敏感词检测功能
-
敏感词替换功能
-
支持Spring Boot自动装配
实现方案一:DFA算法优化版
这里放入第一个SensitiveWordFilter类的完整代码
java
package com.example.utils;
import jakarta.annotation.PostConstruct;
import org.springframework.core.io.ClassPathResource;
import org.springframework.stereotype.Component;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.util.*;
@Component
public class SensitiveWordFilter {
private static final String REPLACEMENT = "***";
private Map<Object, Object> sensitiveWordMap;
@PostConstruct
public void init() {
try {
// 读取敏感词文件
Set<String> keyWordSet = new HashSet<>();
ClassPathResource resource = new ClassPathResource("sensitive-words.txt");
InputStream inputStream = resource.getInputStream();
BufferedReader reader = new BufferedReader(new InputStreamReader(inputStream));
String line;
while ((line = reader.readLine()) != null) {
keyWordSet.add(line.trim());
}
reader.close();
// 构建DFA算法模型
addSensitiveWordToHashMap(keyWordSet);
} catch (IOException e) {
e.printStackTrace();
}
}
private void addSensitiveWordToHashMap(Set<String> keyWordSet) {
sensitiveWordMap = new HashMap(keyWordSet.size());
String key;
Map nowMap;
Map<String, String> newWorMap;
for (String aKeyWordSet : keyWordSet) {
key = aKeyWordSet;
nowMap = sensitiveWordMap;
for (int i = 0; i < key.length(); i++) {
char keyChar = key.charAt(i);
Object wordMap = nowMap.get(keyChar);
if (wordMap != null) {
nowMap = (Map) wordMap;
} else {
newWorMap = new HashMap<>();
newWorMap.put("isEnd", "0");
nowMap.put(keyChar, newWorMap);
nowMap = newWorMap;
}
if (i == key.length() - 1) {
nowMap.put("isEnd", "1");
}
}
}
}
public String filter(String text) {
if (text == null || text.trim().isEmpty()) {
return text;
}
StringBuilder result = new StringBuilder();
Map nowMap = sensitiveWordMap;
int start = 0;
int point = 0;
while (point < text.length()) {
char key = text.charAt(point);
nowMap = (Map) nowMap.get(key);
if (nowMap != null) {
point++;
if ("1".equals(nowMap.get("isEnd"))) {
result.append(REPLACEMENT);
start = point;
nowMap = sensitiveWordMap;
}
} else {
result.append(text.charAt(start));
point = ++start;
nowMap = sensitiveWordMap;
}
}
result.append(text.substring(start));
return result.toString();
}
public boolean containsSensitiveWord(String text) {
if (text == null || text.trim().isEmpty()) {
return false;
}
Map nowMap = sensitiveWordMap;
int point = 0;
while (point < text.length()) {
char key = text.charAt(point);
nowMap = (Map) nowMap.get(key);
if (nowMap != null) {
point++;
if ("1".equals(nowMap.get("isEnd"))) {
return true;
}
} else {
point = point - (point > 0 ? 1 : 0);
nowMap = sensitiveWordMap;
point++;
}
}
return false;
}
}DFA算法特点:
-
使用字典树(Trie)结构存储敏感词
-
时间复杂度接近O(n),n为文本长度
-
适合大规模敏感词库
-
支持最长匹配原则
实现方案二:简单直接版
这里放入第二个SensitiveWordFilter类的完整代码
java
package com.example.utils;
import org.springframework.core.io.ClassPathResource;
import org.springframework.stereotype.Component;
import jakarta.annotation.PostConstruct;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.util.*;
@Component
public class SensitiveWordFilter {
private static final String REPLACEMENT = "***";
private static final Set<String> sensitiveWords = new HashSet<>();
// 初始化敏感词库
@PostConstruct
public void init() {
try {
ClassPathResource resource = new ClassPathResource("sensitive-words.txt");
InputStream inputStream = resource.getInputStream();
BufferedReader reader = new BufferedReader(new InputStreamReader(inputStream));
String line;
while ((line = reader.readLine()) != null) {
sensitiveWords.add(line.trim());
}
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
// 过滤敏感词
public String filter(String text) {
if (text == null || text.trim().isEmpty()) {
return text;
}
for (String word : sensitiveWords) {
if (text.contains(word)) {
text = text.replaceAll(word, REPLACEMENT);
}
}
return text;
}
// 检查是否包含敏感词
public boolean containsSensitiveWord(String text) {
if (text == null || text.trim().isEmpty()) {
return false;
}
for (String word : sensitiveWords) {
if (text.contains(word)) {
return true;
}
}
return false;
}
}简单版特点:
-
实现简单直观
-
适合小规模敏感词库
-
使用String.contains()方法检测
-
性能在词库较大时较差
使用说明
-
在resources目录下创建
sensitive-words.txt文件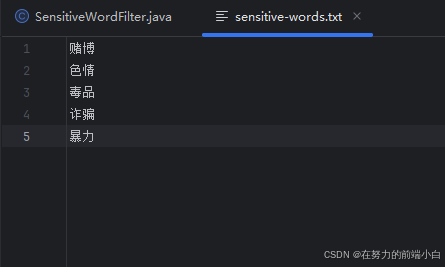
-
每行写入一个敏感词
-
在Spring Boot项目中注入组件:
java
//以下引入二选一
// 引入
@Resource
private SensitiveWordFilter sensitiveWordFilter;
// 引入
@Autowired
private SensitiveWordFilter sensitiveWordFilter;- 调用方法
java
// 引入
@Resource
private SensitiveWordFilter sensitiveWordFilter;
/**
* 新增
*/
public void add(Comment comment) {
// 过滤敏感词,哪个字段需要过滤就设置哪个
// comment.setTitle(sensitiveWordFilter.filter(comment.getTitle()));
comment.setContent(sensitiveWordFilter.filter(comment.getContent()));
commentMapper.insert(comment);
}依赖配置
XML
<!-- 敏感词处理依赖 -->
<dependency>
<groupId>jakarta.annotation</groupId>
<artifactId>jakarta.annotation-api</artifactId>
<version>2.1.1</version>
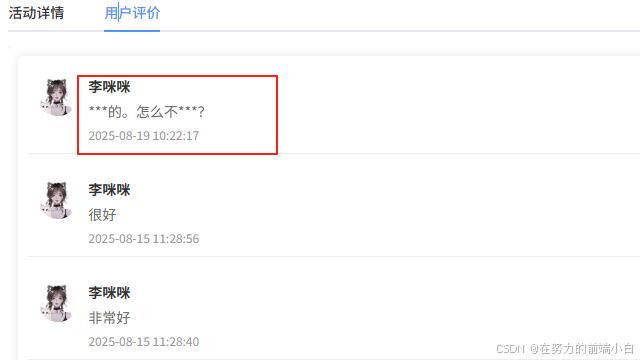
</dependency>前端效果
性能对比
| 方案 | 初始化时间 | 检测时间 | 内存占用 |
|---|---|---|---|
| DFA算法 | 较高 | O(n) | 较高 |
| 简单版 | 低 | O(n*m) | 低 |
适用场景
-
DFA算法版:适合敏感词数量多(1000+)、性能要求高的场景
-
简单版:适合敏感词数量少、快速开发的场景
扩展建议
-
可以添加动态更新敏感词库功能
-
支持多种替换策略(如随机替换、首字母保留等)
-
添加日志记录功能
-
支持多级敏感词(如政治、色情等分类)
总结
本文提供了两种不同复杂度的敏感词过滤实现,开发者可以根据项目需求选择合适的方案。DFA算法虽然实现复杂但性能优异,简单版则适合快速实现基本功能。