前言
在AI技术飞速发展的今天,大语言模型(LLM)、多模态模型等前沿技术正深刻改变行业格局。推理服务是大模型从"实验室突破"走向"产业级应用"的必要环节,需直面高并发流量洪峰、低延时响应诉求、异构硬件优化适配、成本精准控制等复杂挑战。
阿里云人工智能平台 PAI 致力于为用户提供全栈式、高可用的推理服务能力。在本系列技术专题中,我们将围绕分布式推理架构、Serverless弹性资源全球调度、压测调优和服务可观测等关键技术方向,展现 PAI 平台在推理服务侧的产品能力,助力企业和开发者在AI时代抢占先机,让我们一起探索云上AI推理的无限可能,释放大模型的真正价值!
当大模型推理服务遭遇突发流量,扩容往往慢在"最后一分钟":新实例扩缩容过程中,仍需从存储系统上拉取数十乃至上百 GB 的模型或数据,网络 IO 成为瓶颈。当突发流量来临时,这种延迟会导致自动扩缩容机制失效,算力在等待模型加载的过程中持续闲置,而客户请求已在接入层大量堆积。另外在多模态AIGC生成的场景中,推理请求会涉及到频繁切换基础模型和lora模型,每次切换都需从存储系统回源读取模型,导致推理延迟大幅延时增加。
为了解决这个问题,PAI-EAS提供本地目录内存缓存(Memory Cache)的大模型分发加速功能。具体的实现原理如下图所示: 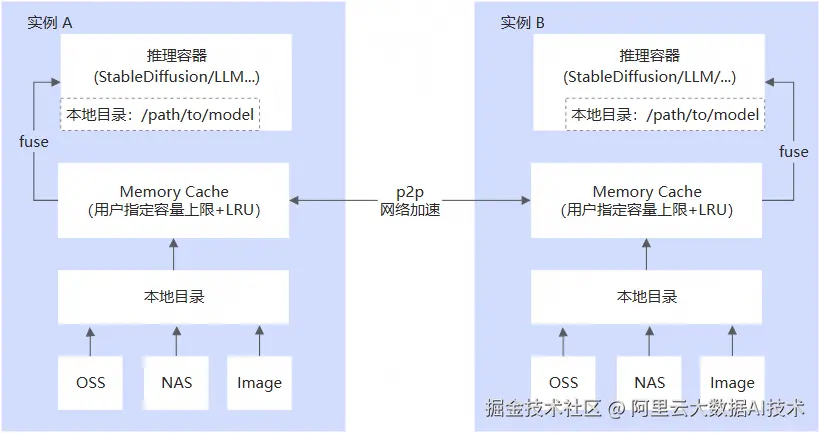
-
利用空闲内存将本地目录中的模型文件缓存到内存中。
-
该缓存支持LRU淘汰策略和实例间共享,以文件系统目录形式呈现。
-
无需修改业务代码,直接读取缓存配置的目标本地目录中的文件,即可享受加速效果。
-
同一服务的不同实例会形成p2p网络,实例扩容时可通过p2p网络就近读取缓存文件,加速扩容速度。
模型切换的加速效果如下:
注:单位为秒,下表为实验结果,最终的加速效果以实际情况为准 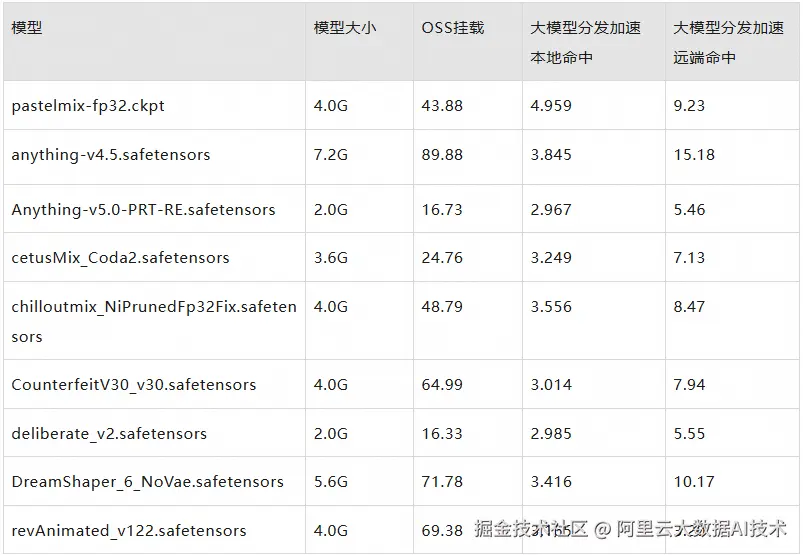
-
当缓存中没有对应的模型时,大模型缓存加速会自动回源读取模型。如该文件通过OSS挂载,则大模型缓存加速会从OSS拉取文件。
-
服务内的多个实例会形成内存共享集群,加载相同模型时直接从远端内存拉取,读取时间与文件大小呈线性相关。
-
服务扩容时,新实例会加入内存共享集群,初始化模型可直接从远端读取,弹性扩缩容更快,适合弹性场景。
使用方式
-
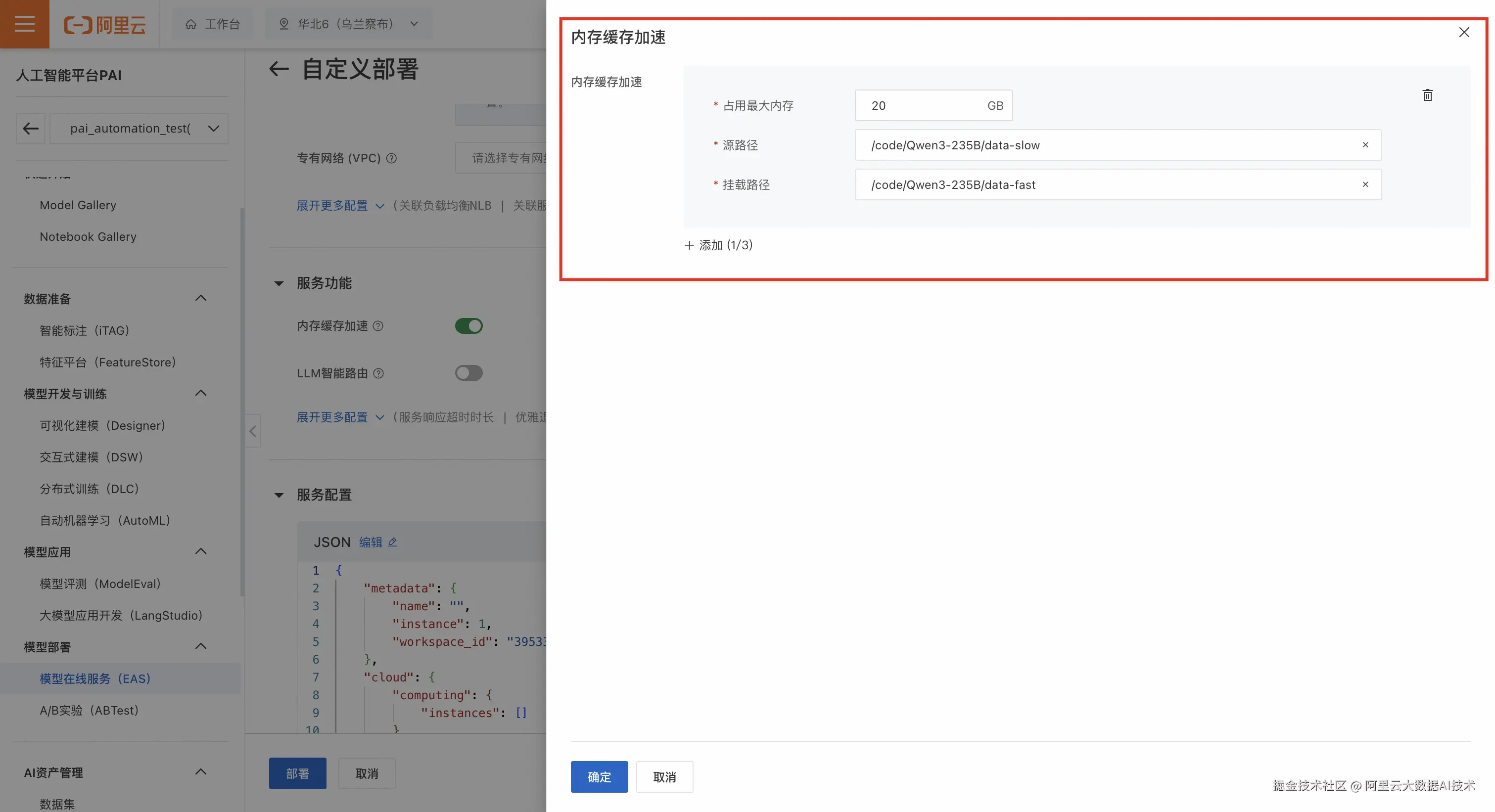
登录PAI控制台,在页面上方选择目标地域,并在右侧选择目标工作空间,然后单击进入EAS。
-
在推理服务 页签,单击部署服务 ,选择自定义模型部署>自定义部署。
-
在服务功能 的区域,进行内存缓存加速的相关配置。

PAI同时发布了模型权重服务能力,可以大幅度降低LLM场景下的推理服务冷启动与扩容时长。详见链接:
PAI 重磅发布模型权重服务,大幅降低模型推理冷启动与扩容时长
系列简介:云上AI推理平台全掌握
本系列 《云上AI推理平台全掌握》 将深度解析阿里云AI推理平台的技术架构、最佳实践与行业应用,涵盖以下核心内容:
-
技术全景:从分布式推理、动态资源调度到Serverless,揭秘支撑千亿参数模型的底层能力。
-
实战指南:通过压测调优、成本优化、全球调度等场景化案例,手把手教你构建企业级推理服务。
-
行业赋能:分享金融、互联网、制造等领域的落地经验,展示如何通过云上推理平台加速AI业务创新。
无论客户是AI开发者、架构师,还是企业决策者,本系列都将为客户提供从理论到实践的全方位指导,助力客户在AI时代抢占先机。让我们一起探索云上AI推理的无限可能,释放大模型的真正价值!
立即开启云上 AI 推理之旅,就在阿里云人工智能平台PAI。