导语
运维工程师的目光紧锁在监控大屏上,Nginx监控显示:上游服务的响应时长曲线诡异地上扬成60度陡坡。更匪夷所思的是:上游流量未出现激增的情况下,客户端并发越高,上游响应耗时($upstream_response_time)越长 ,完全违背了系统资源未饱和时的性能预期。一场围绕Nginx核心机制的探秘之旅就此展开... 
悖论初现:前端并发越大,后端响应越慢?
在常规认知中,只要后端资源充足:
- 上游服务器游刃有余:CPU负载低于30%
- 上游网络通道畅通无阻:网络链路利用率不足30%
- 上游应用处理稳如磐石:业务处理耗时稳定在1ms
此时增加前端并发,理应像增加流水线工人般提升整体效率。然而,冰冷的监控数据却给出了相反的答案:
bash
# 低并发场景(QPS=1000)
$upstream_response_time: 1ms, 1ms, 1ms...
# 高并发场景(QPS=10000)
$upstream_response_time: 86ms, 102ms, 79ms...这场反直觉的性能衰退:上游服务资源监控风平浪静------CPU、内存、网络、业务处理耗时均在健康阈值内,在Nginx代理层却出现了扭曲。问题矛头直指Nginx自身处理逻辑,将我们引向了Nginx底层架构的深水区。
核心洞察:事件循环------Nginx的节拍器
要解开谜团,必须深入Nginx异步非阻塞的事件驱动引擎,其核心是一个高效运转的事件循环(Event Loop) : 
单次事件循环的关键步骤:
- 收集就绪事件 :通过
epoll/kqueue从内核获取已就绪的网络事件(新连接、可读、可写等)。 - 执行事件回调:按顺序处理这些事件,执行对应的收发数据、连接管理、超时检查等操作。
- 完成本轮循环:处理完当该批次的所有就绪事件后,进入下一轮循环。
其中$upstream_response_time统计的起点是连接发出时刻,终点是响应数据处理完成时刻,但响应数据处理必须等待事件循环的调度!而在前端高并发情况下:
-
epoll_wait()需收集更多事件 -
单次循环需要处理的请求数量激增
-
完整处理一轮事件循环的时间成倍增长
正是一轮事件循环处理时长的微妙变化,导致了上游响应时延($upstream_response_time)的异常增长。
eBPF显微镜:直击事件循环时延膨胀现场
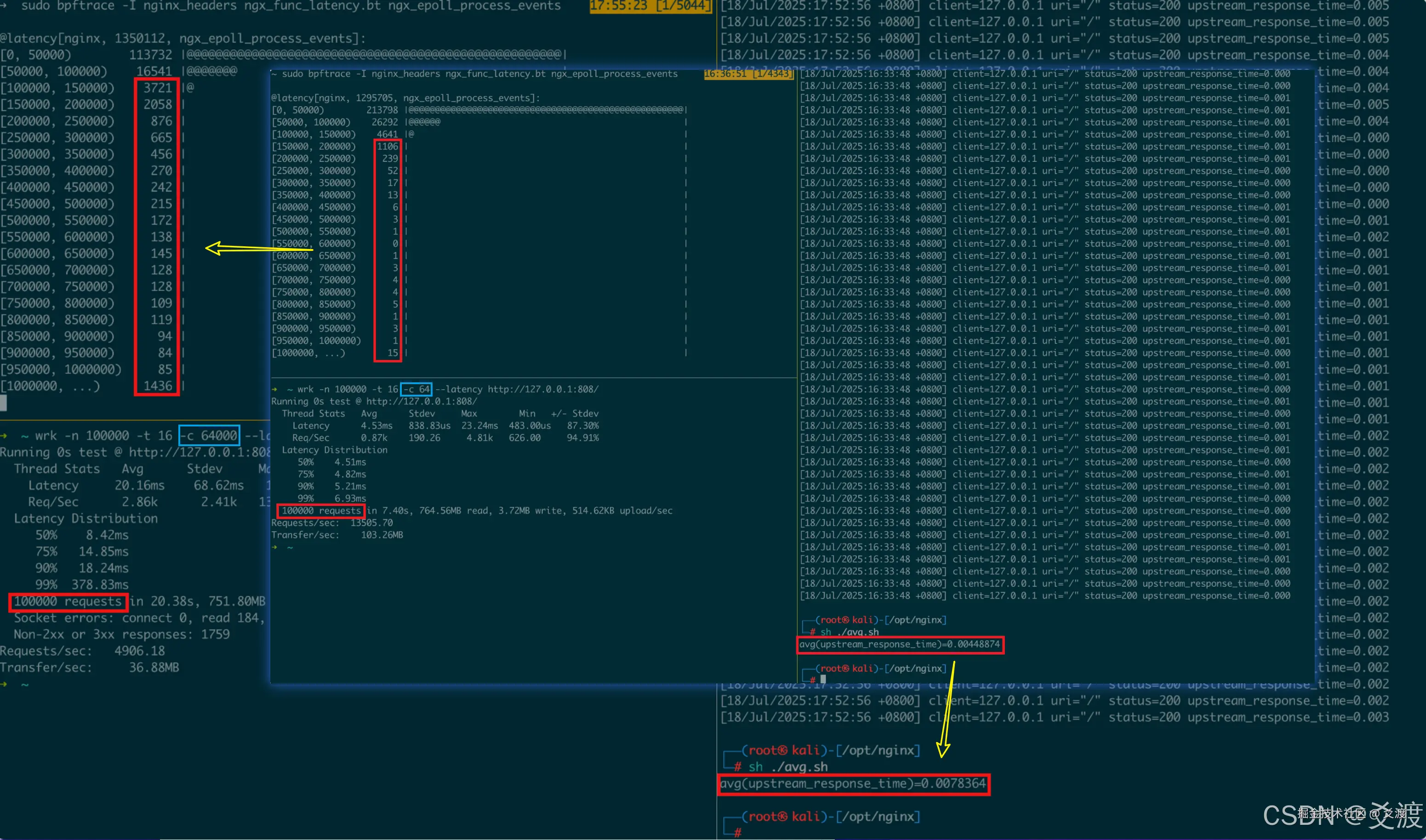
当常规性能工具(如strace, perf)难以定位根因时,我们祭出了观测利器------eBPF,对Nginx Worker进程进行深度追踪:
bash
# 追踪一轮事件循环的处理时长
sudo bpftrace -I nginx_headers ngx_func_latency.bt ngx_epoll_process_events观测结果揭示关键规律,当前端并发增长时:
- 单次循环处理事件数激增,处理耗时显著延长:P99耗时从6.93ms 跃升至 378.83ms
- 事件积压效应显现:新到达的事件(如上游响应)需等待更长时间才能被处理
上游时延倍增真相:幽灵般的"排队等待期"
Nginx记录的$upstream_response_time计算公式实为:
scss
$upstream_response_time = T2(响应数据返回Nginx到被处理) - T1(连接到上游) 我们的eBPF观测锁定了关键问题------T2阶段的隐性排队等待:
- 上游响应已抵达:上游服务器完成处理,响应数据包已到达Nginx服务器的内核TCP接收缓冲区
- Worker正忙:此时Nginx Worker进程正忙于处理本轮事件循环中的其他事件(如其他请求的收发、超时检查等)
- 上游响应等待处理 :响应数据包对应的"可读"事件虽然已在内核就绪队列中,但Worker必须等到下一轮事件循环才能处理它,这段等待时间也被计入
$upstream_response_time
在前端高并发下,上游响应数据需要排队等待才能被Nginx Worker处理------这正是$upstream_response_time异常增长的罪魁祸首。

后记
当巨轮鱼贯驶入巴拿马运河,每艘船舶过闸的操作时间其实恒定不变。但当船队规模超越闸口调度能力时,测量员记录的「从入港到离港」总时长却持续攀升------因为待闸船只已蜿蜒成了星光下的长龙。
在Nginx的事件运河里,上游服务的处理引擎仍在全速运转,高并发洪流却让事件循环的闸门应接不暇。那些已完成响应的数据不得不在待泊区静候事件循环的放行信号,导致$upstream_response_time这把计时标尺,测量到的不只是纯粹的上游服务处理时长,而是包括了自身调度时延的指标。而eBPF这类透明、低开销的观测技术,正成为工程师手中的"量子探针",帮助我们在复杂的性能迷宫中,精准定位那些隐藏的"幽灵延迟",让系统的每一次脉动都清晰可辨。
更多精彩内容
微信搜一搜:爻渡