前言
根据个人的经历,无论在工作中,还是即将要经历的面试,MQ这部分是肯定要了解的,虽然之前工作中一直使用Kafka但是一些详细的细节知识还是了解的不深,所以这次总结一波。
Kafka为什么吞吐量这么大还能这么快(高吞吐&低延迟)?
顺序写
Kafka是会将消息持久化到本地磁盘的,但是一般我们认为对磁盘的操作性能都不会太高,实际上不管是内存还是磁盘,读写快或慢关键在于寻址的方式,磁盘和内存都有顺序写与随机写,基于磁盘的随机写却是很慢,但是基于磁盘的顺序写性能是很高的 ,一般高于随机写3个数量级,某些情况下磁盘的顺序写性能甚至高于内存的随机写。
顺序写的快的主要原因在于:减少了磁盘寻道时间,顺序写不需要硬盘磁头的寻道时间,只需很少的扇区旋转时间,所以速度远快于随机写。
页缓存(page cache)+异步刷盘机制
即便是顺序写入磁盘,磁盘的访问速度还是不可能跟内存相比的,所以kafka充分利用了现代操作系统分页存储来利用内存提高I/O效率。
**当kafka接收到生产者发送的一条消息时,并不会直接将消息写入到磁盘,而是写入到操作系统的页缓存中,然后通过定时操作,批量将页缓存中的数据刷到磁盘中,当然如果达到页缓存数据量阈值也是会提前触发刷盘操作。
**
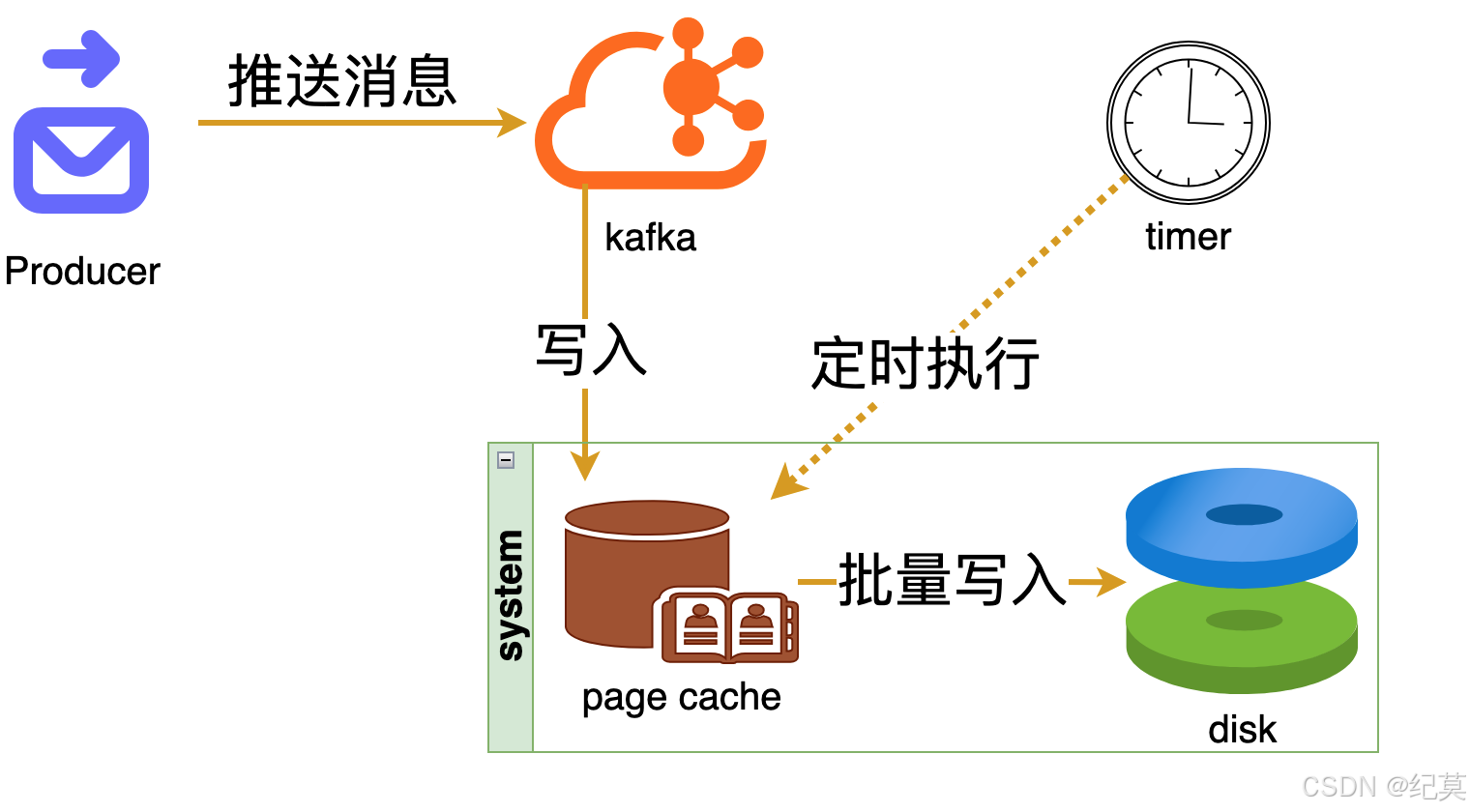
页缓存是操作系统预留的一部分内存区域,以固定大小的页为单位(4K或8K)来缓存磁盘数据。
同步副本机制(ISR)
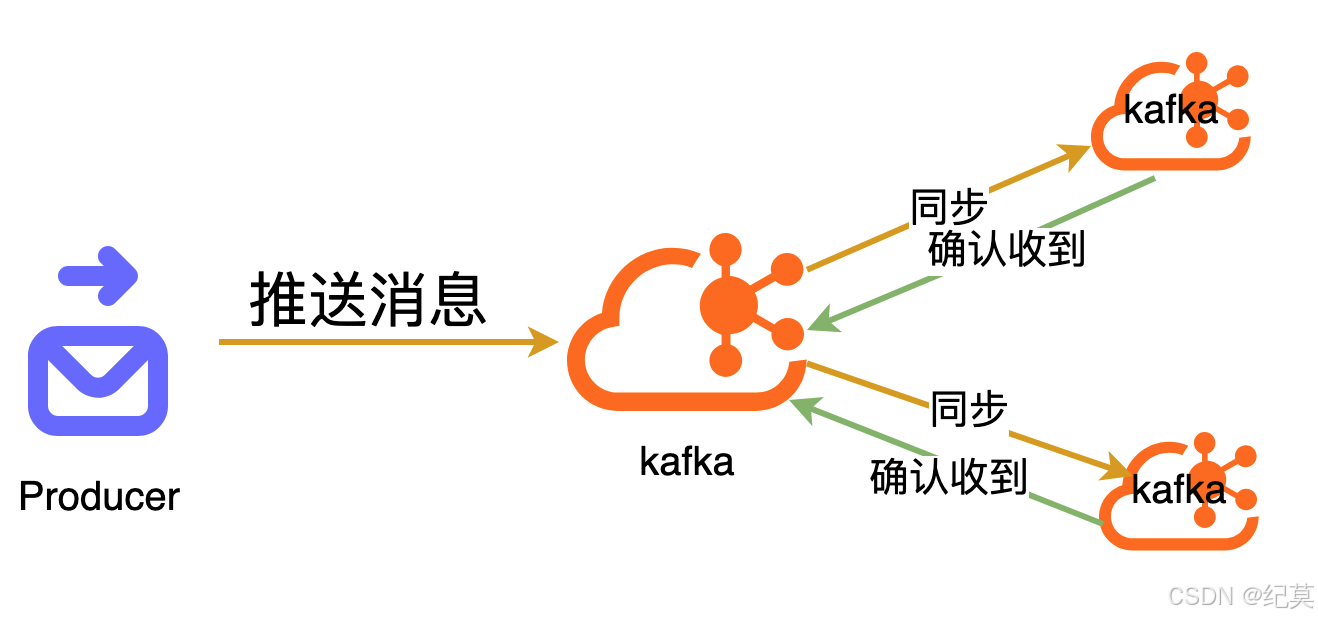
通过使用页缓存,让kafka的写入操作在明面上都是与内存交互的,速度肯定就很快了,但是因为是先写入到缓存中,然后再刷盘,所以就有可能存在还没来得及从缓存刷到磁盘,服务节点就宕机了,这样消息就丢了。
所以,kafka引入了同步副本节点,即一个 Kafka 节点可有多个同步副本节点。生产者发送消息后,Kafka 需等同步副本节点也接收到消息,才向生产者返回成功,这样主节点挂掉后,可从同步副本节点重新选举新主节点。
日志分段与索引机制
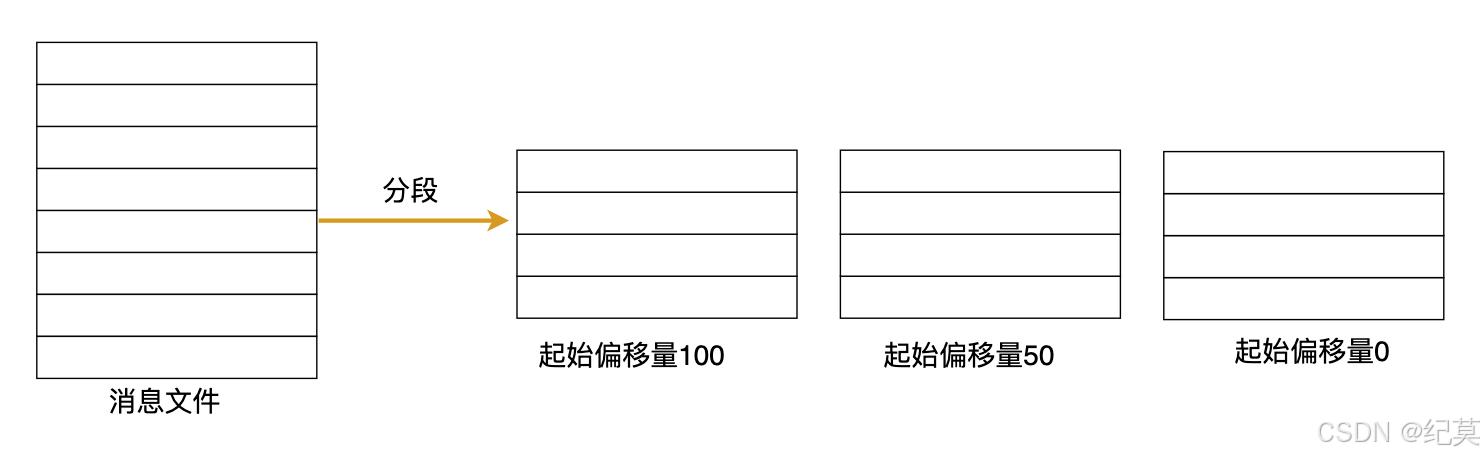
上面都是在说kafka如何提高写的速度了,那么写的再快,读的很慢,kafka还是快不起来,所以为了提升读的速度,kafka将文件按段分成多个小文件,一是为了方便删除老数据,二是可以通过偏移量基于二分法快速定位到具体的小文件。同时加入了索引机制,用小文件粗颗粒度记录偏移量和物理地址的关系,还增加时间索引,支持通过时间戳快速定位消息,以此加快读取速度。
零拷贝技术
我们知道操作系统分为内核态和用户态,而我们正常情况下想从磁盘中读取一条数据并通过网络发送给消费者,需要先通过 DMA 将数据从磁盘拷贝到内核态的页缓存,然后再通过 CPU 把数据从内核态拷贝到用户态的 kafka,把数据拷贝到内核态的网络缓冲区,最后 DMA 把数据拷贝给网卡。
这拷贝来拷贝去的 CPU 还需要在内核态和用户态之间来回切换,看着就很麻烦。那有没有更好的方法?LINUX2.1 便提供了一个 sendfile 的系统函数,它可以直接把数据从页缓存拷贝到网络缓冲区,然后发送给网卡。
后来到了 LINUX2.4 时代,如果有带收集功能的 DMA 可以更进一步直接将数据从页缓存拷贝到网卡,实现了真正的零拷贝。
分区并行
无论 kafka 速度有多快,如果消费者速度跟不上怎么办?
我们知道一个消息队列只能消费者一个一个消费,就算我多加几个消费者也只会增加锁争抢的压力。
所以 kafka 便将消息队列分成多个区,每个区可以有单独的消费者。
批量处理
kafka的一个消费者可一次性从消息队列中获取多个消息进行批量处理,同样生产者也可以批量处理。
生产者发送消息后会先暂存在本地,然后再异步批量向消息队列投递消息。不过这个就不推荐了,容易导致丢消息。
reactor 线程模型
请看IO模型解释:https://www.cnblogs.com/jimoer/p/11462457.html#autoid-2-4-0
数据压缩
卡夫卡会通过压缩算法将消息压缩后进行传输和持久化,这个也能一定程度上提高网络传输和磁盘存储的速度。
Kafka 还支持对消息集合进行压缩,Producer可以通过GZIP或Snappy格式对消息集合进行压缩,压缩的好处就是减少传输的数据量,减轻对网络传输的压力,Producer压缩之后,在Consumer需进行解压,虽然增加了CPU的工作,但在对大数据处理上,瓶颈在网络上而不是CPU,所以这个成本很值得。