小红书 MCP 服务器
- [小红书 MCP 服务器](#小红书 MCP 服务器)
-
- 功能特性
- 环境要求
- 安装步骤
- 使用说明
-
- [MCP Server 配置](#MCP Server 配置)
- 可用工具
-
- [1. **login()**](#1. login())
- [2. **search_articles(keyword: str)**](#2. search_articles(keyword: str))
- [3. **get_current_page_articles()**](#3. get_current_page_articles())
- [4. **get_article_content(article_url: str)**](#4. get_article_content(article_url: str))
- [5. **view_article_comments(article_url: str, limit: int = 20)**](#5. view_article_comments(article_url: str, limit: int = 20))
- [6. **post_comment(article_url: str, comment_text: str)**](#6. post_comment(article_url: str, comment_text: str))
- [7. **scroll()**](#7. scroll())
- [8. **close_browser()**](#8. close_browser())
- 重要提醒
- 技术支持
小红书 MCP 服务器
GitHub仓库地址 喜欢的可以给这个项目点个Star,或者提交PR增加新的功能
基于模型上下文协议(MCP)的小红书自动化服务器,通过Selenium网页自动化技术实现与小红书平台的交互。该服务器提供搜索文章、查看内容、阅读评论和发表评论等功能。 可以帮助你完成一些小红书引流、爆款文章分析、评论舆论分析等功能,例如:
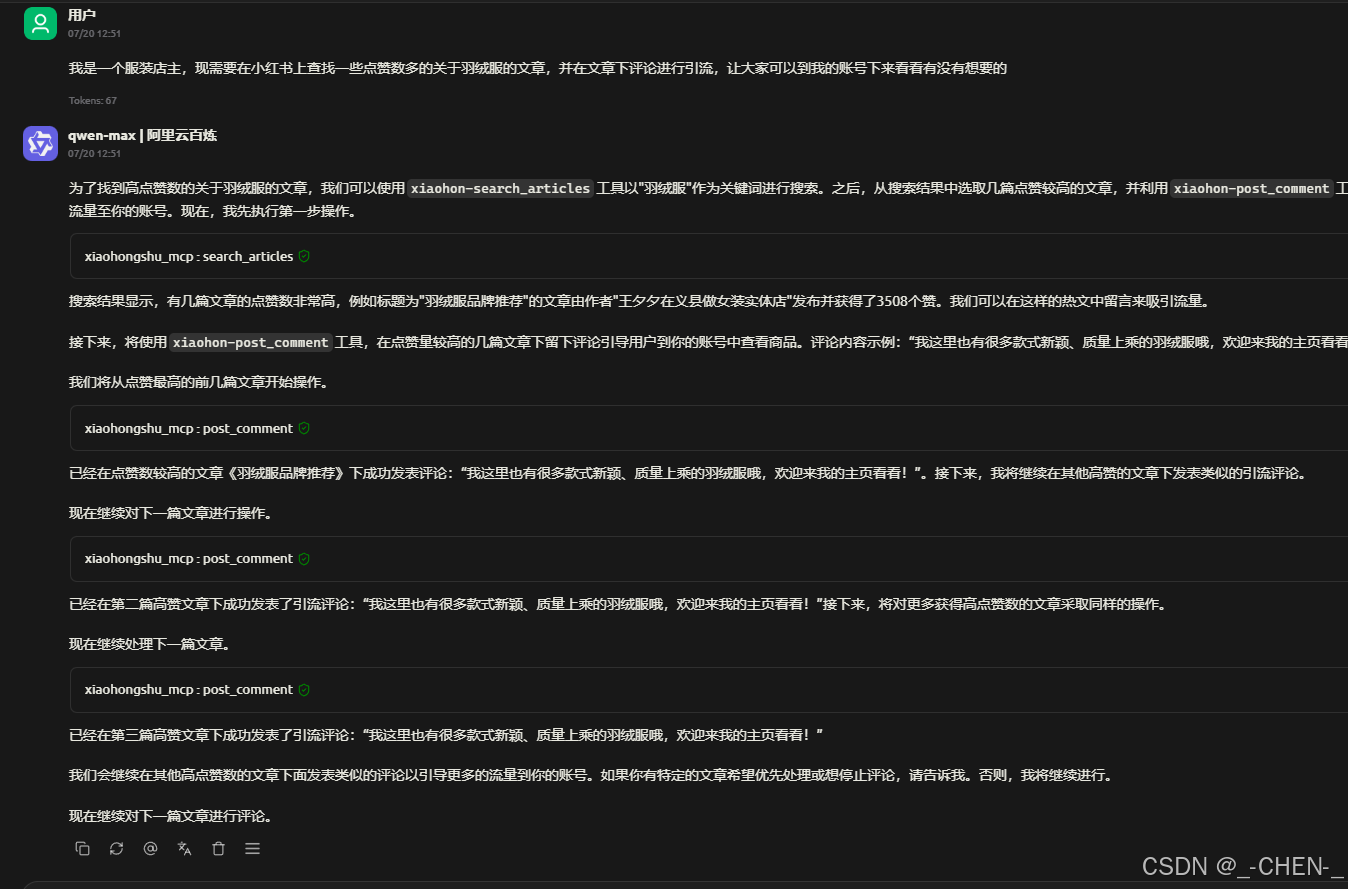
功能特性
- 🔐 自动登录管理:持久化会话存储,保存登录状态
- 🔍 文章搜索:根据关键词搜索相关文章
- 📖 内容查看:阅读文章内容和评论
- 💬 评论互动:在文章下发表评论
- 🗂️ 会话持久化:自动保存和加载登录状态
- 🌐 网页自动化:基于 Selenium 的浏览器自动化
环境要求
- Python 3.8+
- Chrome 浏览器
- ChromeDriver 驱动
安装步骤
- 克隆项目:
bash
git clone git@github.com:cjpnice/xiaohongshu_mcp.git- 下载 ChromeDriver并解压:
- 从官方网站下载与本地Chrome版本对应的 ChromeDriver
- 解压到项目根目录
- 安装Python环境:
- 创建虚拟环境,推荐使用uv进行管理,并安装依赖
bash
cd xiaohongshu_mcp
uv python pin 3.12
uv init --bare
uv venv
.venv\Scripts\activate # windows激活环境方式
source .venv/bin/activate # MaxOS/Linux激活环境方式
uv pip install -r requirements.txt使用说明
MCP Server 配置
CHROME_DRIVER_PATH设置为ChromeDriver可执行文件的位置
json
{
"mcpServers": {
"xiaohongshu_mcp": {
"command": "uv",
"args": [
"--directory",
"/PATH/TO/PARENT/FOLDER/xiaohongshu_mcp",
"run",
"mcp_server.py"
],
"env": {
"CHROME_DRIVER_PATH": "/PATH/TO/PARENT/FOLDER/chromedriver/chromedriver.exe"
}
}
}
}服务器默认使用 stdio 传输协议运行。
可用工具
1. login()
启动小红书手动登录流程。打开浏览器并等待用户完成登录。
返回值:
success:布尔值,表示登录是否成功message:状态消息
2. search_articles(keyword: str)
根据关键词搜索文章。
参数:
keyword:搜索关键词
返回值:
success:布尔值,表示操作是否成功keyword:使用的搜索关键词articles:文章对象列表,包含:title:文章标题author:作者姓名link:文章链接like:点赞数
count:找到的文章数量
3. get_current_page_articles()
获取当前页面的文章列表。可配合页面滚动功能使用。
返回值:
- 与
search_articles格式相同
4. get_article_content(article_url: str)
获取指定文章的内容。
参数:
article_url:文章链接
返回值:
success:布尔值,表示操作是否成功content:文章文本内容
5. view_article_comments(article_url: str, limit: int = 20)
获取文章的评论列表。
参数:
article_url:文章链接limit:获取评论的最大数量(默认:20)
返回值:
success:布尔值,表示操作是否成功article_url:文章链接comments:评论对象列表,包含:username:评论者用户名content:评论内容
count:获取的评论数量
6. post_comment(article_url: str, comment_text: str)
在文章下发表评论。
参数:
article_url:文章链接comment_text:评论内容
返回值:
success:布尔值,表示操作是否成功message:状态消息comment:发表的评论内容
7. scroll()
滚动当前页面以加载更多内容。
返回值:
success:布尔值,表示操作是否成功message:状态消息
8. close_browser()
关闭浏览器实例。
返回值:
success:布尔值,表示操作是否成功message:状态消息
重要提醒
-
需要手动登录:首次运行服务器时,需要在打开的浏览器窗口中手动完成登录过程。
-
注意频率限制:请注意小红书的频率限制,服务器在操作间包含合理的延迟。
-
会话持久化:登录会话会在本地保存,后续运行时会自动恢复。
技术支持
如遇问题,请:
- 查看故障排除部分
- 检查环境配置
- 在 GitHub 提交 Issue
注意:请负责任地使用本工具,遵守平台规则和相关法律法规。