突破性框架TRAPO:统一监督微调与强化学习的新范式,显著提升大语言模型推理能力
大语言模型的后训练方法正迎来重大突破!清华大学与蚂蚁集团联合提出的TRAPO框架通过创新性地统一SFT与RL训练,在数学推理任务上实现了显著性能提升。该框架解决了传统两阶段训练中的根本性矛盾,通过Trust-Region SFT和自适应专家指导机制,实现了更稳定、更高效的模型训练,为推理增强型LLMs发展开辟了新道路。
论文标题 :TRUST-REGION ADAPTIVE POLICY OPTIMIZATION
来源 :arXiv:2512.17636 + https://arxiv.org/abs/2512.17636
PS: 整理了LLM、量化投资、机器学习方向的学习资料,关注同名公众号 「 AI极客熊 」 即刻免费解锁
文章核心
研究背景
大语言模型的后训练,特别是监督微调(Supervised Fine-Tuning, SFT)和强化学习(Reinforcement Learning, RL)技术,在提升模型复杂推理能力方面发挥着重要作用。当前主流的LLM后训练流程采用两阶段方式:先进行SFT让模型模仿精心策划的专家演示,然后通过RL阶段的试错来精炼模型的推理技能。然而,这种设计存在根本性障碍阻碍了SFT与RL的协同作用。SFT倾向于将训练模型锁定在模仿性和僵化的行为模式中,这阻碍了RL阶段至关重要的有效探索;同时,SFT还容易导致训练模型的灾难性遗忘,阻碍RL阶段利用预训练知识进行改进。这些不一致性提出了一个重要挑战:如何在不损害模型探索能力和预训练知识的前提下,将SFT的知识蒸馏优势有效融入RL训练中?
研究问题
- 训练不一致性问题:传统两阶段SFT-then-RL流程中,SFT强制执行僵化模仿会抑制探索并导致遗忘,限制了RL的改进潜力。
- 分布混合效应:标准SFT最小化前向KL散度表现出强烈的模式覆盖特性,当在实例级别与RL交错时,那些膨胀的模式会立即导致目标策略退化(如重复或错误解码),使RL远离有效探索。
- 专家指导效率问题:"一刀切"的前缀长度本质上效率低下:在模型能够独立解决的问题上扼杀了有价值的探索,而在更具挑战性的问题上提供不足的指导。
主要贡献
- 统一的训练框架:引入TRAPO(Trust-Region Adaptive Policy Optimization),这是一个在实例级别结合SFT和RL的新型后训练框架。它具有TrSFT用于稳定知识内化和动态指导选择机制以平衡指导与探索。
- 理论分析突破:识别SFT(前向KL)的模式覆盖特性作为不稳定性来源,理论上证明TrSFT将优化目标从SFT的模式覆盖转向反向KL的模式寻求行为,确保RL的稳定更新。
- 实验验证充分:在五个数学推理基准上进行广泛实验,证明TRAPO超越了传统SFT、RL和SFT-then-RL流程,以及最近结合SFT和RL的最先进方法。
方法论精要
TRAPO框架概述
TRAPO框架的核心思想是实现协同的"边学边练"范式,将从离线专家轨迹学习与在线RL更新相结合。核心工作流程如下:对于每个提示,(1)从离线专家轨迹中选择的前缀作为起始上下文;(2)目标策略从那里开始展开以完成推理;(3)然后执行双重更新,其中生成的完成用于标准RL更新,而专家前缀用于直接策略优化以内化专家的推理技能。
通过实证研究验证了在目标策略展开中引入专家轨迹前缀的好处。在MATH-500基准测试中,为Qwen2.5-3B-Instruct提供来自DeepSeek-R1的前缀,然后计算响应准确率并统计完成的后缀中两种关键推理行为的频率,即回溯和反向链式推理。清楚地观察到更长的专家前缀稳步提高准确率并刺激高级推理行为的出现。
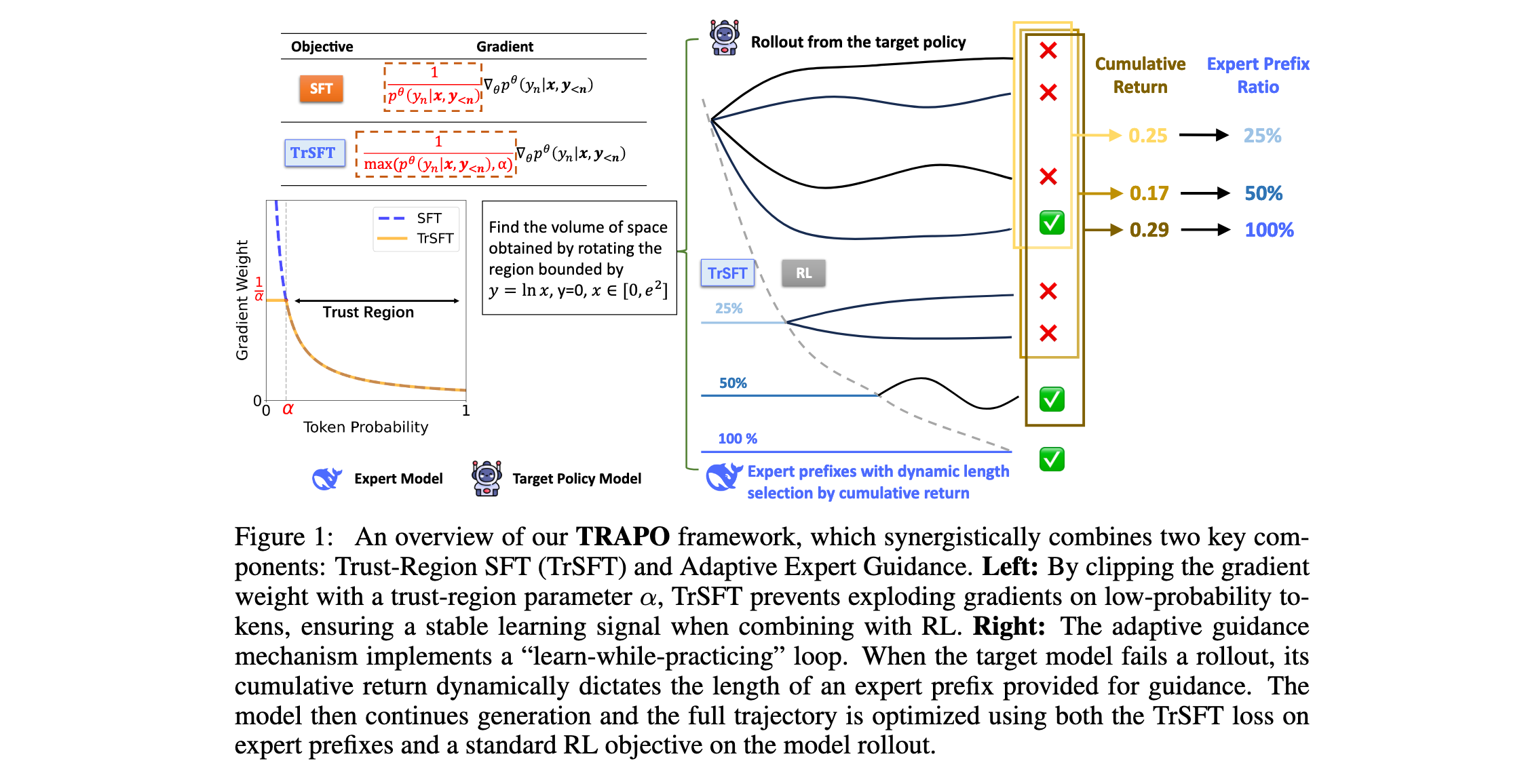
Trust-Region SFT (TrSFT)
针对内化专家推理技能的第一个挑战,直接在专家前缀上结合标准SFT损失与模型生成展开的RL目标会导致严重的性能下降。为了揭示根本原因,作者首先进行了SFT训练动态的试点研究。
SFT训练动态分析 :标准SFT训练目标强制 p θ T p_\theta^T pθT模仿专家策略 p E p_E pE,通过最小化来自专家策略的每个轨迹 y = ( y 1 , ⋯ , y n ) y = (y_1, \cdots, y_n) y=(y1,⋯,yn)的负对数似然(NLL):
L S F T ( θ ) = E x ∼ X E y ∼ p E ( ⋅ ∣ x ) \[ − log p θ T ( y ∣ x ) ] L_{SFT}(\theta) = \mathbb{E}_{x \sim \mathcal{X}} \left \\mathbb{E}_{y \\sim p_E(\\cdot\|x)} \\left\[ -\\log p_\\theta\^T(y\|x) \\right \right] LSFT(θ)=Ex∼XEy∼pE(⋅∣x)\[−logpθT(y∣x)]
SFT目标等价于最小化累积令牌级前向KL散度。为了理解其训练动态,作者进行了一个说明性实验,训练一个双模式高斯混合模型(GMM)来模仿一个三模式专家GMM。这个过程揭示了分布混合现象:目标策略为任一策略都不支持的空区域分配概率(如图3(a)中的阴影区域)。这对RL有害,因为这些区域导致退化的输出(如重复),阻碍有效探索。
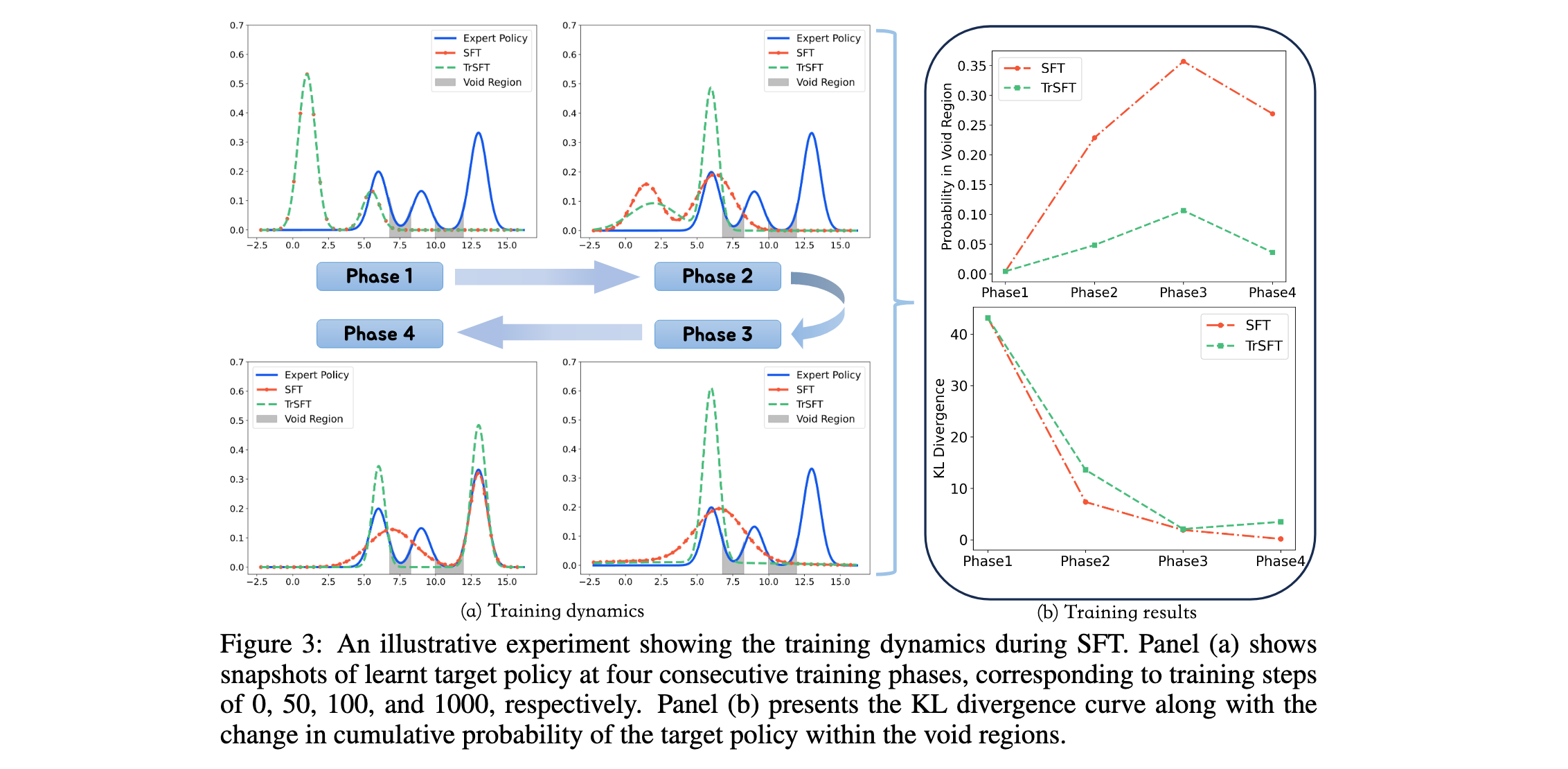
TrSFT梯度裁剪:为了减轻在线模型更新期间分布混合的负面影响,提出了Trust-Region SFT (TrSFT),一个旨在自适应利用SFT更新的机制。核心思想是建立一个区域,其中标准SFT损失的梯度可以被信任,而在此区域之外需要干预以防止模型崩溃到解决方案空间的不良部分:
∇ θ L T r S F T α = − 1 N ∑ i = 1 N ∑ n = 1 ∣ y i ∣ 1 max ( p θ T ( y i n ∣ x i , y i < n ) , α ) ∇ θ p θ T ( y i n ∣ x i , y i < n ) \nabla_\theta L_{TrSFT}^\alpha = -\frac{1}{N} \sum_{i=1}^{N} \sum_{n=1}^{|y_i|} \frac{1}{\max(p_\theta^T(y_i^n|x_i,y_{i<n}), \alpha)} \nabla_\theta p_\theta^T(y_i^n|x_i,y_{i<n}) ∇θLTrSFTα=−N1∑i=1N∑n=1∣yi∣max(pθT(yin∣xi,yi<n),α)1∇θpθT(yin∣xi,yi<n)
其中 α ∈ 0 , 1 \alpha \in 0,1 α∈0,1是定义信任区域边界的超参数。该优化目标表现出几个理想特性:
- 信任区域内的安全知识灌输 :TrSFT通过基于目标策略自身信念定义动态信任区域来缓解分布混合。在此区域内,它采用标准SFT目标积极模仿专家策略行为。在区域外,常数权重 1 / α 1/\alpha 1/α显著抑制梯度,从而减少大梯度更新对目标策略即时行为的破坏性影响。
- 合理的优化端点 :作者提出了由Eq.(3)定义的梯度定义的优化问题,并理论上推导了解决方案。TrSFT的最优解决方案通过修剪专家策略中的低概率区域( p T ∗ ( c ) = 0 p_T^*(c) = 0 pT∗(c)=0)和重新缩放主要模式( p T ∗ ( c ) = p E ( c ) / λ p_T^*(c) = p_E(c)/\lambda pT∗(c)=pE(c)/λ)来对抗分布混合。这种双重行动有效地将目标从前向KL的模式覆盖转变为类似于反向KL的模式寻求,迫使策略专注于专家的核心技能,从而有利于RL的高回报展开。
微组采样(Micro-group Sampling)
为了优雅地解决指导选择的第二个挑战,提出了微组采样,它基于当前策略展开的观察回报自适应地分配专家前缀的指导,从而最小化对专家前缀的不必要依赖并适应每个训练批次内提示难度的异质性。
如图1所示,在每个训练提示中,TRAPO按顺序创建N个微组,其中每个微组 g i g_i gi(对于 i = 1 , ⋯ , N i = 1, \cdots, N i=1,⋯,N)由三个关键超参数指定:前缀长度比例 L i L_i Li、回报阈值 t i t_i ti和采样预算 n i n_i ni。
对于微组 g i g_i gi,TRAPO首先计算在前面微组中生成的所有样本的平均回报。如果平均回报小于阈值 t i t_i ti,TRAPO向当前目标策略提供一个前缀,其长度设置为完整专家轨迹的比例 L i L_i Li,然后从目标策略采样 n i n_i ni个完成。否则,不提供专家前缀,直接从目标策略获得 n i n_i ni个策略展开。
设置 0 = L 1 < L 2 < ⋯ < L N = 1 0 = L_1 \lt L_2 \lt \cdots \lt L_N = 1 0=L1<L2<⋯<LN=1。 L 1 = 0 L_1 = 0 L1=0确保在每个训练提示中,TRAPO总是从无指导的自我探索RL开始,而 L N = 1 L_N = 1 LN=1允许目标策略在必要时访问来自专家的完整推理路径。因此, L i L_i Li的递增水平确保只有在较短前缀被证明不足时才提供更丰富的指导。
实验洞察
实验设置
训练细节:主要训练数据集是OpenR1-Math-46k-8192,包含由DeepSeek-R1为复杂数学问题生成的大量已验证推理轨迹。为了增强指导的多样性,作者还为每个问题配对了从OpenR1-Math-200k中采样的另一个轨迹。遵循最近的工作,使用Qwen2.5-Math-7B作为基础模型。为了进一步验证方法的通用性,还在通用目的模型Qwen2.5-7B-Instruct上进行了评估。
实施细节 :采用不带KL惩罚的Group Relative Policy Optimization (GRPO)算法进行RL。训练配置为128的批大小和 5 × 1 0 − 6 5 \times 10^{-6} 5×10−6的恒定学习率。自适应指导机制在总共8个组大小上运行,这些组被划分为四个大小为{4, 2, 1, 1}的微组。这些微组对应相对专家前缀长度比例 ( L 1 , ⋯ , L 4 ) = ( 0 , 0.2 , 0.5 , 1.0 ) (L_1, \cdots, L_4) = (0, 0.2, 0.5, 1.0) (L1,⋯,L4)=(0,0.2,0.5,1.0),并由回报阈值 ( t 1 , ⋯ , t 4 ) = ( − 1 , 0.5 , 0.7 , 0.9 ) (t_1, \cdots, t_4) = (-1, 0.5, 0.7, 0.9) (t1,⋯,t4)=(−1,0.5,0.7,0.9)激活。阈值 t 1 = − 1 t_1 = -1 t1=−1确保第一个微组总是没有指导。对于TrSFT目标,Eq.(3)中的信任区域参数 α \alpha α设置为0.1。
评估基准和指标:专注于数学推理任务,同时在数学和通用领域基准上评估各种方法。具体来说,数学基准包括AIME2024、AMC、Minerva、OlympiadBench和MATH-500。鉴于AIME2024和AMC的测试样本相对较少,在这些基准上报告avg@32,其余三个使用pass@1。对于通用领域推理基准,在ARC-c和MMLU-Pro上报告pass@1,以检查推理能力的改进是否推广到其他推理任务。
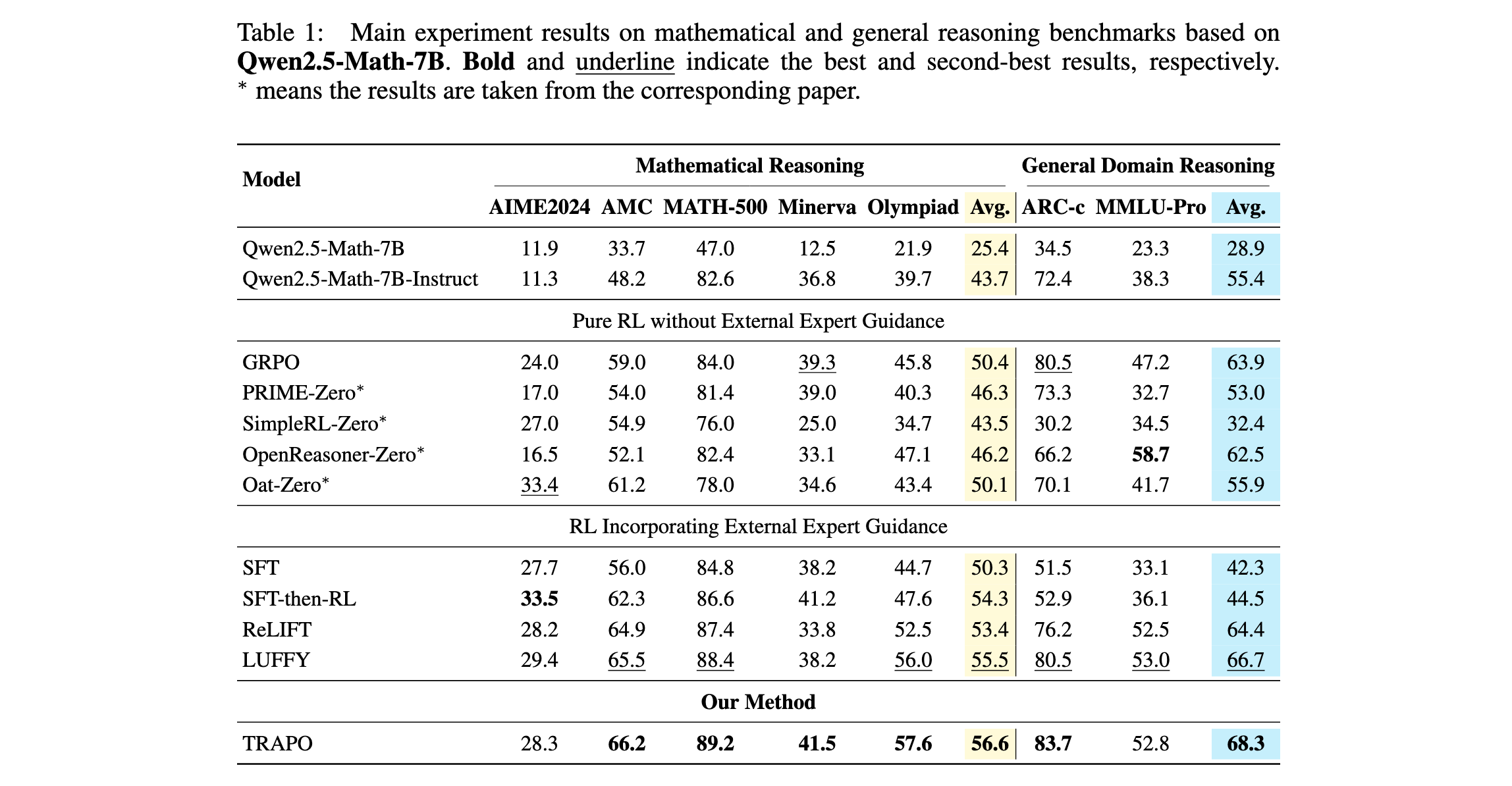
主要实验结果
数学推理性能:如表1所示,TRAPO在五个数学推理基准上实现了56.6的平均分数,优于所有基线。特别是,TRAPO相对于SFT和GRPO分别产生了+6.3和+6.2的改进,相对于SFT-then-RL基线获得了+2.3的增益。这些结果验证了核心假设:TRAPO有效地使模型既能够内化专家技能,又能够利用指导进行卓越的探索,从而更稳健地获得推理能力。
通用领域推理性能:在两个通用推理基准上,TRAPO达到68.3的平均分数,超过所有基线。相比之下,SFT和SFT-then-RL在这些基准上表现出明显较低的分数,表明TRAPO在利用外部指导的同时,不会将模型限制在僵化的推理模式中;相反,它产生更强的泛化能力。
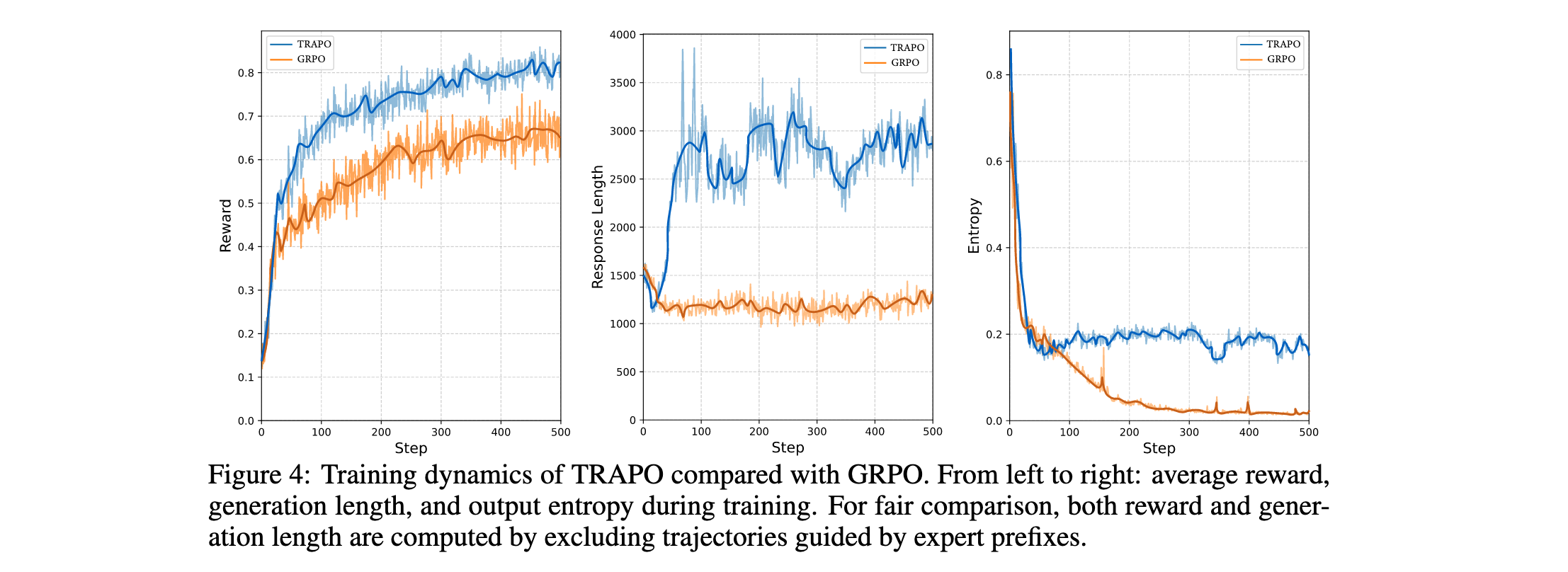
训练动态:图4展示了TRAPO与GRPO之间训练动态的比较分析,揭示了方法的三个关键优势:(1)TRAPO在整个训练过程中始终实现更高的回报,并最终收敛到显著更高的最终回报水平。(2)生成长度曲线显示TRAPO在早期阶段迅速增加其输出长度,表明快速内化了专家的扩展推理模式。相比之下,GRPO难以产生更长的解决方案,始终保持较短的输出长度。(3)虽然两种方法都显示策略熵的初始下降,但它们的长期行为不同。TRAPO稳定在相对较高的熵水平。这归因于其保持动态平衡的能力:它同时精炼自己的高概率推理路径,同时对学习外部提供的、潜在低概率的专家指导保持开放。
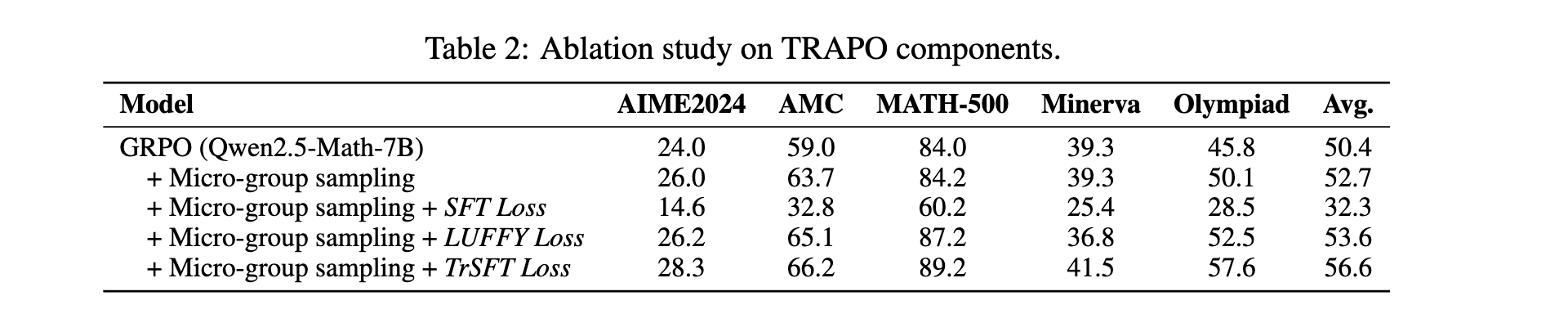
消融研究
为了评估微组采样和TrSFT的贡献,在Qwen2.5-Math-7B上进行了消融研究。结果表明,仅微组采样,即使没有明确的前缀学习,也通过自适应确定前缀长度来增强推理和回报密度,超越了GRPO。添加TrSFT进一步提高了性能:与标准SFT损失(降低性能)或LUFFY的离线RL损失(带来有限增益)不同,TrSFT有效地内化了专家前缀。
测试时间扩展
评估pass@k(k个独立展开的成功率)以更好地估计模型能力的上限,因为最近的研究表明,多次生成尝试比少数展开更准确地揭示推理潜力。图6展示了AIME2024基准上的pass@k性能,从中得出两个关键见解:(1)观察到基础模型(Qwen2.5-Math-7B)在用足够大的k评估时超过了GRPO训练的模型。这与之前的发现一致,表明标准RL主要刺激模型从其现有知识空间中选择更好的解决方案,但不会从根本上用新的问题解决技能扩展该空间。(2)TRAPO和基于SFT的方法都展示了在更大k下的强性能扩展,表明它们拥有更丰富的底层解决方案空间。TRAPO的卓越性能突显了其成功有效地内化了来自专家轨迹的外部知识,从而扩展了模型的内在能力。