阅读本文前,扣"777",建议点赞收藏以免遗失。由于文章篇幅有限,更多RAG----Agent与MCP资料+代码,也可在主页查看最新AI大模型应用开发学习资料免费赠送
个人RAG vs 企业RAG:技术架构与应用深度解析
在人工智能领域,RAG(Retrieval-Augmented Generation)作为一种融合检索与生成的范式,已广泛应用于问答系统、信息提取和内容生成任务。本文章将聚焦于个人RAG(适用于个体用户或小型场景)和企业RAG(适用于大规模商业环境)的技术实现,从架构设计、数据处理、性能优化等方面展开原创分析。
1. RAG技术概览
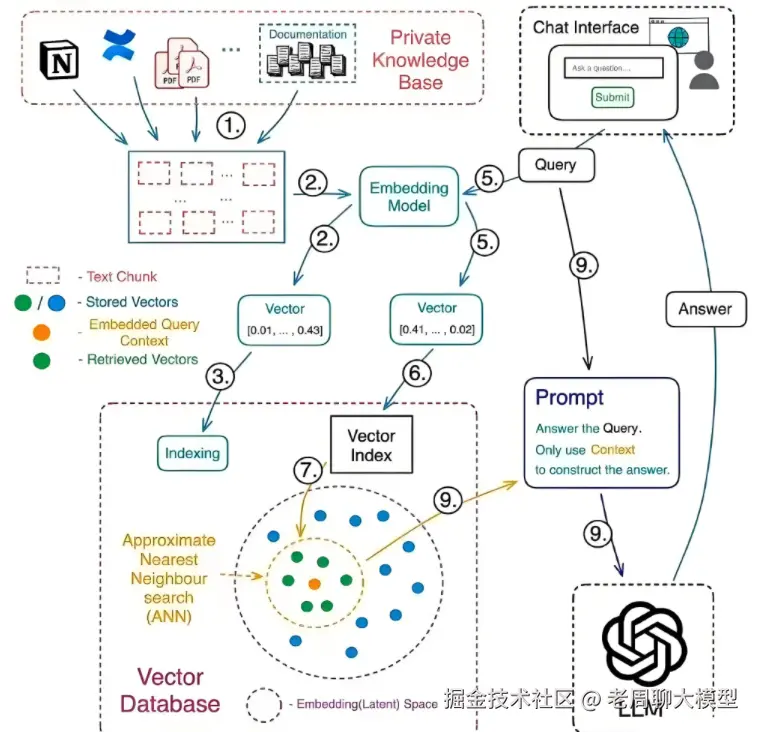
RAG技术通过"检索-增强-生成"三步框架运作:
- 检索(Retrieval) :基于用户查询,从数据库或知识库中召回相关上下文片段(如文档、网页内容)。
- 增强(Augmentation) :将检索到的上下文与用户查询结合,形成更丰富的输入。
- 生成(Generation) :使用预训练语言模型(如GPT系列、Llama)生成最终响应,确保信息准确性和语义连贯性。
核心优势在于它结合了结构化知识(如向量数据库)与大模型泛化能力,解决了纯生成模型的"幻觉"问题。然而,个人和企业应用在资源规模、安全需求和复杂度上存在显著差异。
2. 个人RAG:轻量级与个性化实现
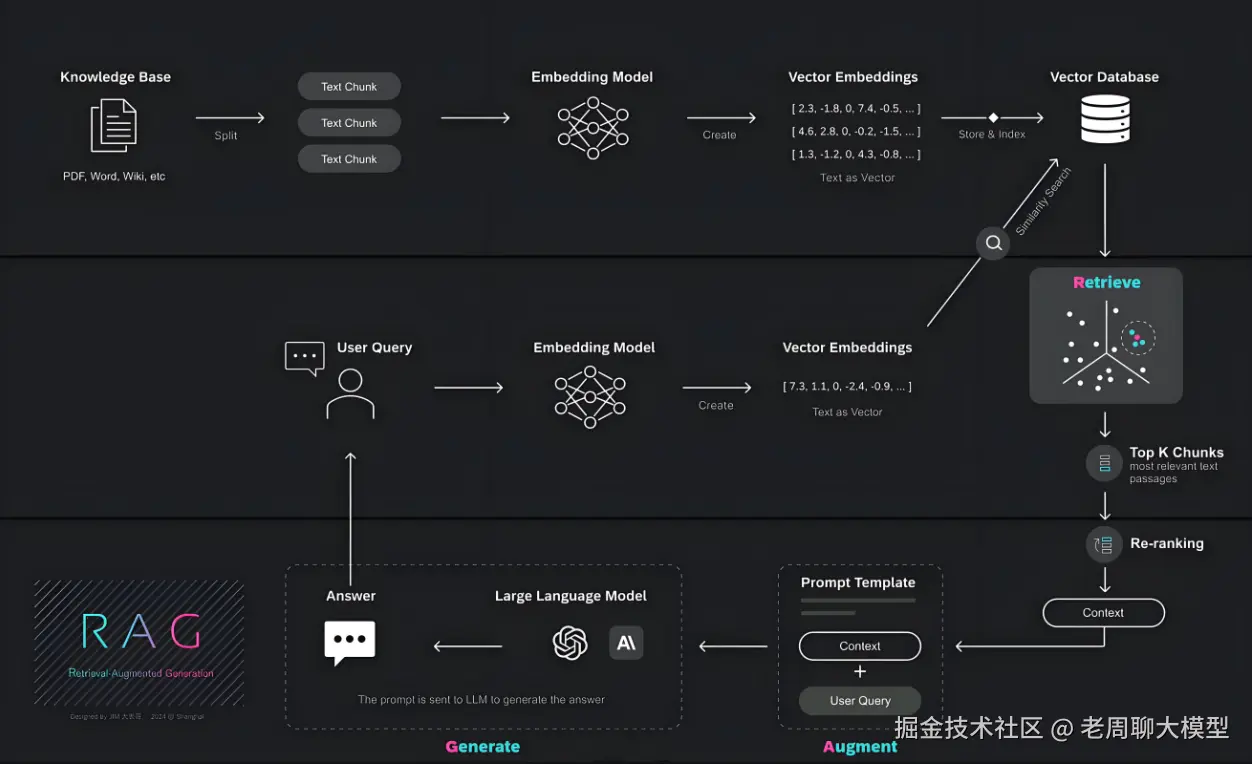
个人RAG常用于个体用户场景,如个人助手、学习工具或小型项目。其目标是低成本、快速部署和高度可定制。
技术架构核心要素:
- 数据存储:使用本地或轻量级向量数据库(如Faiss或Chroma),知识库规模小(通常 <10GB),包含个人文档、笔记或开源数据集。数据源通常是静态的,更新频率低。
- 模型选择:采用小型或微调模型(e.g., 7B参数的Llama 2),部署在个人设备(如笔记本电脑)或低算力云服务(Replit、Hugging Face Spaces),确保响应时延低(<1秒)。
- 检索算法:基于余弦相似度的简易向量检索,使用嵌入模型(如Sentence Transformers)。支持个性化设置,例如用户偏好过滤。
- 关键优化点 :资源效率 :CPU优化减少内存占用(<4GB RAM),避免GPU依赖。隐私优先 :数据本地处理(e.g., 浏览器端WebAssembly实现),不依赖云服务。开发门槛低:Python或JS实现,可集成到简单脚本(如基于LangChain的个人知识助手)。
典型应用场景:
- 个人文档检索(e.g., 搜索本地PDF笔记)。
- 学习辅助(e.g., 结合维基百科生成研究报告)。
- 缺陷:规模限制导致召回率低,大查询下易崩溃。
3. 企业RAG:高扩展性与工业级部署
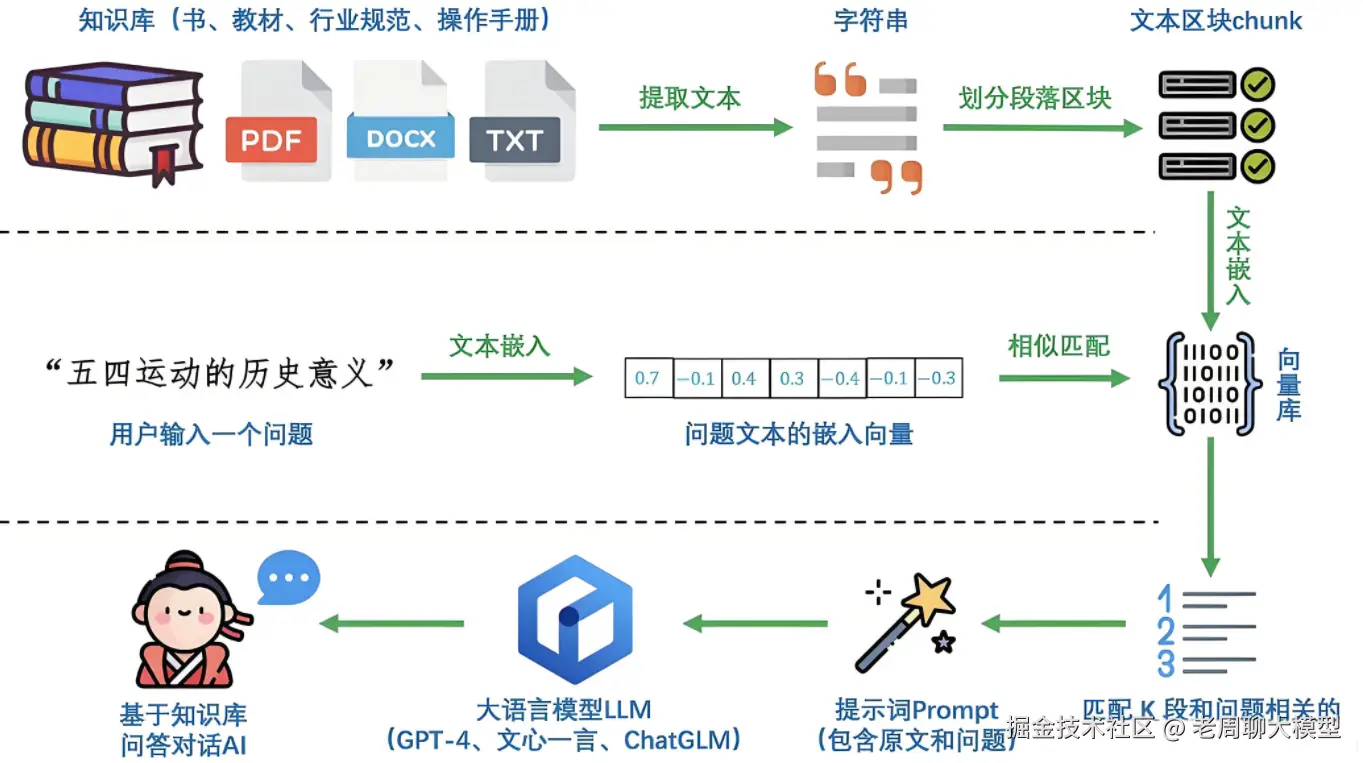
企业RAG面向商业场景,如客服系统、内部知识库或数据分析平台,强调高吞吐、安全可控和集成能力。技术复杂度显著提升,需处理海量数据和多样需求。
技术架构核心要素:
- 数据存储:分布式向量数据库(如Pinecone、Milvus),知识库规模大(>1TB),支持实时更新(流处理集成Kafka)。多源融合(e.g., CRM数据、PDF文档、API实时流)。
- 模型选择:大模型(e.g., 70B参数的GPT-4或专有模型),部署于GPU集群(Kubernetes编排),支持并发请求(吞吐量 >100QPS)。常用微调(fine-tuning)或指令微调(SFT)适配业务术语。
- 检索算法:多阶段检索(召回+精排),使用混合模型(e.g., BM25+向量相似度)。引入强化学习优化召回质量(e.g., 减少误召回率)。
- 系统设计与优化 :可扩展性 :模块化架构(检索/生成服务分离),负载均衡(e.g., Nginx)。安全合规 :数据加密(TLS传输)、访问控制(RBAC)、审计日志(SIEM集成),符合GDPR或HIPAA。性能优化 :缓存机制(Redis缓存常见查询),延迟目标(P99 <500ms)。监控与鲁棒性:Prometheus监控资源使用,自动容错(重试策略)。
典型应用场景:
- 客服自动化(e.g., 处理千级并发查询)。
- 企业内部搜索(e.g., 结合Slack或Teams生成会议摘要)。
- 挑战:成本高(云GPU费用),维护复杂。
4. 技术对比与关键差异
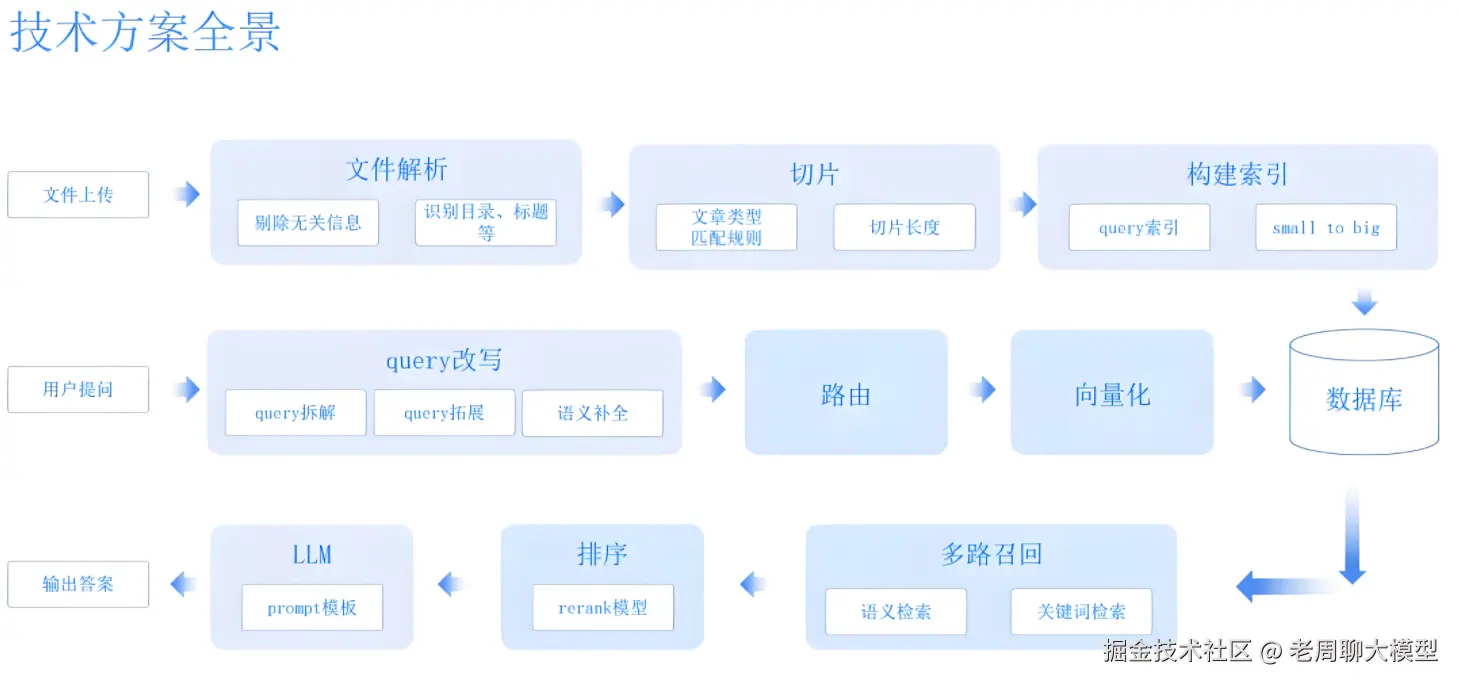
| 维度 | 个人RAG | 企业RAG |
|---|---|---|
| 数据规模 | 小 (<10GB), 静态数据 | 大 (>1TB), 动态实时更新 |
| 计算资源 | CPU/low-end GPU,单机部署 | GPU集群,分布式编排 |
| 延迟要求 | <1秒(用户感知友好) | 毫秒级(商业SLA绑定) |
| 安全机制 | 本地加密、简易隐私控制 | 企业级加密、合规审计、多级认证 |
| 成本效率 | 低(免费工具),<10美元/月 | 高(云成本), >1000美元/月 |
| 可扩展性 | 有限(仅支持少量用户) | 高(自动伸缩,应对峰值负载) |
| 典型技术栈 | LangChain + Hugging Face + FAISS | MLOps管道(Kubeflow)+ Milvus + 专有API |
核心挑战与创新方向:
- 个人挑战:如何在小资源下提升召回率?采用量化技术(模型压缩)和边缘AI。
- 企业挑战:如何平衡成本与性能?混合云部署和知识蒸馏(大模型到小模型)。
- 跨领域趋势:联邦学习(保护数据隐私)和生成评估指标(e.g., ROUGE分数)的应用。
5. 结语与未来展望
个人RAG通过轻量级部署赋能个体创新,而企业RAG则驱动业务智能化升级。随着AI硬件进步(e.g., NPU集成)和开源生态(如向量数据库标准化),RAG技术将向低延时、高可信演进。关键趋势包括多模态RAG(图像+文本检索)和AutoRAG框架(自动优化检索策略)。最终,成功部署需匹配场景需求:个人聚焦用户体验,企业强调整体ROI。
本文为原创技术分析,适用于开发者参考。如需代码实现示例或进一步讨论,欢迎提供具体需求!
请告知具体应用场景,我将提供定制资源包