目录
[卷积神经网络-3D 卷积](#卷积神经网络-3D 卷积)
[Batch Normalization](#Batch Normalization)
激活函数
隐藏层只能使用非线性激活函数,不能使用线性,
因为不管多少个线性函数组合得到还是个线性函数。
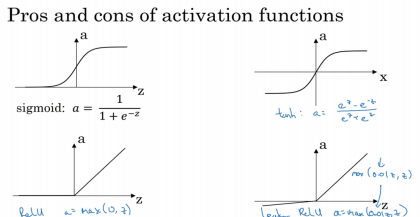
Sigmoid激活函数-二分类
其它基本都用ReLU,因为它的斜率基本
不会为0所以学习速率比较快
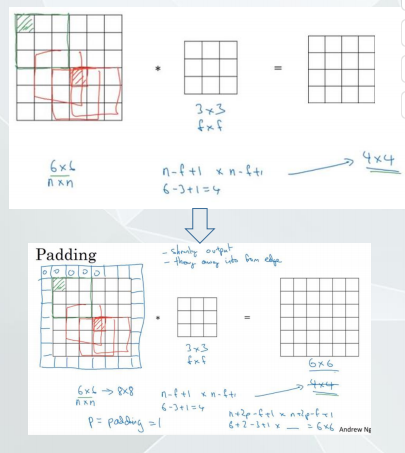
卷积神经网络-padding
可以解决卷积过程遇到的问题:
- 输出图像缩小,如果每层都减小经过比如100层图像
会变得非常小 - 图像边缘大部分信息都被丢失了
加入Padding后,卷积后图像大小计算公式:
输入:n x n 卷积核大小f x f Padding 大小为p
则输出: (n+2p-f+1) x (n+2p-f+1)
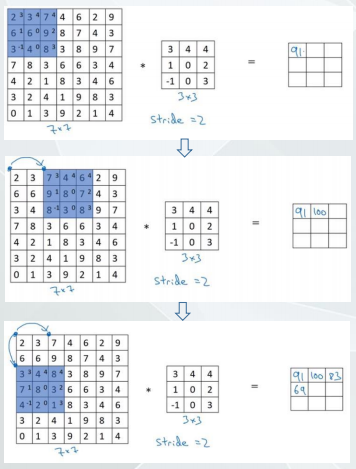
卷积神经网络-Stride
Strided Convolution:
卷积过程中,不是逐像素,而是有个步长如右图所示。
计算大小 :
公式如下,如果得到的大小不是整数,则向下取整也就
是只有滤波器完全覆盖在图像上才能计算

卷积神经网络-3D 卷积
3D Convolution:
➢ 当输入的通道数大于 1 时例如 3 ,滤波器的通道数与输入保持
一致为 3 ,所以计算的过程中如右图所示,卷积的时候是
3x3x3 共 27 个参数计算然后加和得到的结果是当前像素卷积
后的值。
➢ 也可以实现多个滤波器进行卷积,滤波器的个数决定了输出
的图像的通道数。
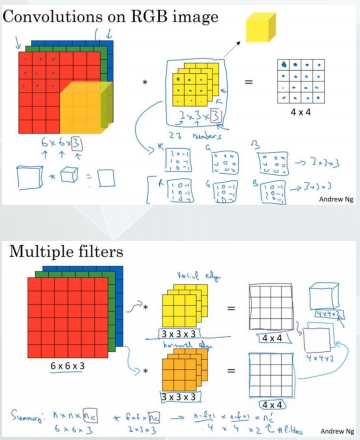
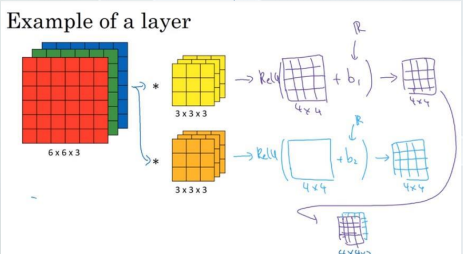
卷积神经网络-一个卷积层示例
参数计算 :
➢ 当输入的通道数与滤波器的通道数相同
➢ 滤波器的个数与输出的通道数相同
➢ 权重参数 w= 滤波器大小与输入和输出通道数乘积
➢ 偏置 b= 滤波器个数即输出通道的个数
**卷积神经网络-**Pooling
在卷积神经网络中通常会在相邻的卷积层之间加入一个池化层,
1. 特征不变性( feature invariant )
使模型更关注是否存在某些特征而不是特征具体的位置可看作
是一种很强的先验,使特征学习包含某种程度自由度,能容忍
一些特征微小的位移
2. 特征降维
降采样作用,从而使模型可以抽取更广范围的特征同时减小了
下一层输入大小,进而减小计算量和参数个数
3. 在一定程度上能防止过拟合的发生
a. 池化前后不改变通道数,池化后图像大小计
算方式与卷积相同
b. 用到的超参数就是 filter 和 stride (常用
f=2,s=2 相当于图像减半,或者 f=3,s=2 ),很
少用到 padding
c. 池化过程中没有需要学习的参数
参数和超参数
➢ 参数:需要网络学习的参数: w b
➢ 超参数:模型训练需要的外部设置的参数比
如学习率迭代次数,隐藏层的层数,激活函
数的选择等
➢ 找到最优的超参数方法就是不断尝试
过拟合、梯度消失与爆炸
过拟合解决办法 :
➢ 正则化
➢ 数据增强
➢ Dropout
➢ Early stopping

Batch与miniBatch
Batch gradient descent
➢ 遍历全部数据集算一次损失函数,然后算函
数对各个参数的梯度,更新梯度。
➢ 计算量开销大,计算速度慢,不支持在线学
习
Mini-batch gradient decent :
➢ 小批的梯度下降,这种方法把数据分为若干个批,
按批来更新参数,这样,一个批中的一组数据共
同决定了本次梯度的方向,下降起来就不容易跑
偏,减少了随机性。
➢ 另一方面因为批的样本数与整个数据集相比小了
很多,计算量也不是很大。
Batch Normalization
➢ 2015年由 Google 提出,开 Normalization 之先
河。其规范化针对单个神经元进行,利用网
络训练时一个 mini-batch 的数据来计算该神经
元的均值和方差 , 因而称为 Batch Normalization
➢ 正则化,帮助模型快速收敛
➢ 防止梯度爆炸或消失
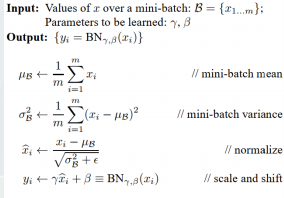
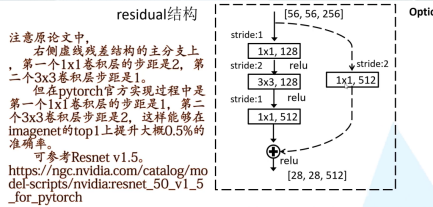
ResNet
➢ 虚线残差块,仅在conv3_1, conv4_1,conv5_1中使用,
目的是调整特征矩阵的深度和大小
➢ 在深层网络(50,101,152)中除了上面提到的
在conv2_1也会使用虚线残差块仅调整特征的深度
UNet
➢ 全卷积神经网络,对称的U型
➢ 主要用于医学图像分割
➢ 左半边:将图像->高语义feature map的过程
看成编码器
➢ 右半边:高语义->像素级别的分类score map
的过程看作解码器