系列文章目录
文章目录
概念介绍
系统调用
system call是linux内核给应用层的API,是进入内核的入口,应用程序用过调用系统接口实现使用内核提供的服务、资源以及各种各样的功能。
驱动开发工程师通过调用 Linux 内核提供的接口完成设备驱动的注册,驱动程序负责底层硬件操作相关逻辑。
Linux 应用编程(系统编程)则指的是基于 Linux 操作系统的应用编程,在应用程序中通过调用系统调用 API 完成应用程序的功能和逻辑,应用程序运行于操作系统之上。
通常在操作系统下有两种不同的状态:内核态和用户态,应用程序运行在用户态、而内核则运行在内核态。
应用编程简单点来说就是:开发 Linux 应用程序,通过调用内核提供的系统调用或使用 C 库函数来开发具有相应功能的应用程序。
文件I/O
文件 I/O(Input、Outout),对文件的读写操作,Linux 下一切皆文件,文件作为 Linux 系统设计思想的核心理念,在 Linux 系统下显得尤为重要
文件描述符:file description,非负整数,比如在open函数成功时会返回的这个值,这个值是内核向进程返回的,指代被打开的文件,失败操作会返回-1。
一个进程可以打开多个文件,在 Linux 系统中,一个进程可以打开的文件数是有限制,打开的文件是需要占用内存资源的,如果超过进程可打开的最大文件数限制,内核将会发送警告信号给对应的进程,然后结束进程;可以通过 ulimit 命令来查看进程可打开的最大文件数,一般是1024
c
ulimit -n对于一个进程来说,文件描述符是一种有限资源,文件描述符是从 0 开始分配的,进程中第一个被打开的文件对应的文件描述符是 0、第二个文件是 1、第三个文件是 2、第 4 个文件是 3......文件描述符数字最大值为 1023(0~1023)。每一个被打开的文件在同一个进程中都有一个唯一的文件描述符,不会重复,如果文件被关闭后,它对应的文件描述符将会被释放,那么这个文件描述符将可以再次分配给其它打开的文件绑定起来。
一般012这三个文件描述符被系统占用了,分别分配给了系统标准输入(0)、标准输出(1)以及标准错误(2)
硬件设备也对应的文件,叫做设备文件,应用程序通过对设备文件进行读写等操作、来使用、操控硬件设备,譬如 LCD 显示器、串口、音频、键盘等。
标准输入一般是键盘,标准输出一般是LCD屏幕,标准错误一般也是LCD显示器
open
c
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);man命令可以查看帮助信息,譬如函数功能介绍、函数原型、参数、返回值以及使用该函数所需包含的头文件等信息。
2表示系统调用,1代表Linux命令,3表示标准C库函数
c
man 2 openopen命令有两种,这是可变参数的写法,需要包含三个头文件
参数:
pathname:字符串类型,用于标识需要打开或创建的文件,可以包含路径(绝对路径或相对路径)信息,譬如:"./src_file"(当前目录下的 src_file 文件)、"/home/dengtao/hello.c"等;如果 pathname 是一个符号链接,会对其进行解引用。
flags:调用 open 函数时需要提供的标志,包括文件访问模式标志以及其它文件相关标志,都是宏定义常量,可以单独使用某一
个标志,也可以通过位或运算(|)将多个标志进行组合。
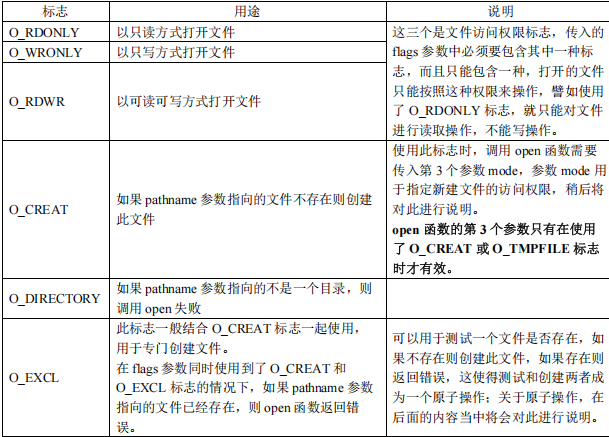

还有很多的标志位,O_APPEND、O_ASYNC、O_DSYNC、O_NOATIME、O_NONBLOCK、O_SYNC 以及 O_TRUNC 等,不同内核版本可能也不一样。但这些命令只有文件有相关的权限时,才能正常操作。
O_TRUNC:打开文件的时候会将文件原本的内容全部丢弃,文件大小变为 0
O_APPEND :每次使用 write()函数对文件进行写操作时,都会自动把文件当前位置偏移量移动到文件末尾,从文件末尾开始写入数据。调用后,不会影响读取偏移量,还是从文件头开始,调用后写的lseek函数不会起作用。每次调用写入时,都会从末尾开始
mode:此参数用于指定新建文件的访问权限,只有当 flags 参数中包含 O_CREAT 或 O_TMPFILE 标志时才有效(O_TMPFILE 标志用于创建一个临时文件)。一般用touch创建文件后,会有默认的权限,经常通过chmod来修改权限
c
ls -l 查看文件权限mode参数u32无符号整数,

O---这 3 个 bit 位用于表示其他用户的权限;
G---这 3 个 bit 位用于表示同组用户(group) 的权限,即与文件所有者有相同组 ID 的所有用户;
U---这 3 个 bit 位用于表示 文件所属用户 的权限,即文件或目录的所属者;
S---这 3 个 bit 位用于表示文件的特殊权限,一般不管
然后每3bit都是按照rwx来分配的,read/write/execute,读/写/执行,0表示没有,1表示有
最高权限表示方法:111111111(二进制表示)、777(八进制表示)、511(十进制表示)
111000000(二进制表示):表示文件所属者具有读、写、执行权限,而同组用户和其他用户不具有任何权限;
100100100(二进制表示):表示文件所属者、同组用户以及其他用户都具有读权限,但都没有写、执行权限。
除了自己赋值,还可以用linux里面弄好的宏定义
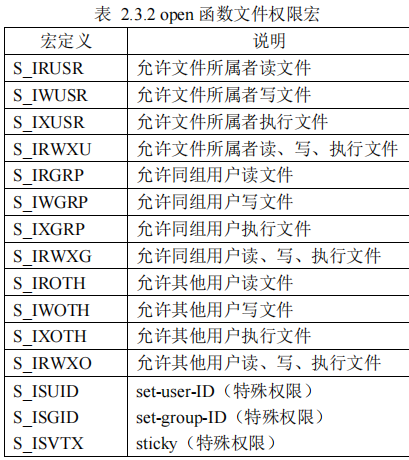
打开范例:
c
//可读可写方式打开已经存在的文件
int fd = open("./app.c", O_RDWR)
if (-1 == fd)
return fd;
//打开指定文件
int fd = open("/home/dengtao/hello", O_RDWR | O_NOFOLLOW);
if (-1 == fd)
return fd;write
c
#include <unistd.h>
ssize_t write(int fd, const void *buf, size_t count);fd:文件描述符
buf:指定写入数据对应的缓冲区。
count:指定写入的字节数。
返回值:如果成功将返回写入的字节数(0 表示未写入任何字节),如果此数字小于 count 参数,譬如磁盘空间已满,可能会发生这种情况;如果写入出错,则返回-1。
read
c
#include <unistd.h>
ssize_t read(int fd, void *buf, size_t count);fd:文件描述符。与 write 函数的 fd 参数意义相同。
buf:指定用于存储读取数据的缓冲区。
count:指定需要读取的字节数。
返回值:如果读取成功将返回读取到的字节数,实际读取到的字节数可能会小于 count 参数指定的字节数,也有可能会为 0,譬如进行读操作时,当前文件位置偏移量已经到了文件末尾。
close
关闭文件
c
#include <unistd.h>
int close(int fd);fd:文件描述符,需要关闭的文件所对应的文件描述符。
返回值:如果成功返回 0,如果失败则返回-1。
在 Linux 系统中,当一个进程终止时,内核会自动关闭它打开的所有文件,很多程序都利用了这一功能而不显式地用 close 关闭打开的文件。
文件描述符是有限资源,当不再需要时必须将其释放、归还于系统。
lseek
对于每个打开的文件,系统都会记录它的读写位置偏移量,我们也把这个读写位置偏移量称为读写偏移量,记录了文件当前的读写位置
c
#include <sys/types.h>
#include <unistd.h>
off_t lseek(int fd, off_t offset, int whence);当打开文件时,会将读写偏移量设置为指向文件开始位置处,以后每次调用 read()、write()将自动进行累计,指向已读或已写数据后的下一字节
fd:文件描述符。
offset:偏移量,以字节为单位。可以正也可以负。
whence:用于定义参数 offset 偏移量对应的参考值
SEEK_SET:读写偏移量将指向 offset 字节位置处
SEEK_CUR:读写偏移量将指向当前位置偏移量 + offset 字节位置处
SEEK_END:读写偏移量将指向文件末尾 + offset 字节位置处
c
//将读写位置移动到文件开头处
off_t off = lseek(fd, 0, SEEK_SET);
if (-1 == off)
return -1;
//将读写位置移动到文件末尾:
off_t off = lseek(fd, 0, SEEK_END);
if (-1 == off)
return -1;
//将读写位置移动到偏移文件开头 100 个字节处
off_t off = lseek(fd, 100, SEEK_SET);
if (-1 == off)
return -1;
//获取当前读写位置偏移量
off_t off = lseek(fd, 0, SEEK_CUR);
if (-1 == off)
return -1;文件解析
文件存储与节点区
文件是存放在磁盘里面,硬盘的最小存储单位叫做"扇区"(Sector),每个扇区储存 512 字节(相当于 0.5KB),操作系统一般会一次性读取多个扇区,这叫做块,是文件存取的最小单位一个块4KB,所以1个块是8个扇区
磁盘在进行分区、格式化时分为两个区域,数据区,用于存储文件中的数据;== inode 节点区,用于存放 inode table(inode 表)==,每一个文件都必须对应一个 inode,inode 实质上是一个结构体,里面元素记录了文件信息如文件字节大小、文件所有者、文件对应的读/写/执行权限、文件时间戳(创建时间、更新时间等)、文件类型、文件数据存储的 block(块)位置等等信息,文件名并不是记录在 inode 中
查看inode编号
c
ls -i
stat xxx文件名
之前买的闪迪的U盘,就有数据恢复软件,原因就是其实删除数据时删掉的是inode表,数据内容还在,只有新的数据在存入时才会覆盖掉。
windows里面的快速格式化就是例子,这种格式化会非常快,也是因为删掉的只是inode table表,数据也是可以找回来的。
open打开文件时,内核会申请内存拷贝静态文件,叫动态文件,然后对动态文件进行读写操作,之后再同步更新到设备中。
这就是为啥打开大文件很慢,文档忘记保存丢失数据的原因
硬盘这些块设备,读写起来按块单位操作,内存就能按照字节操作,灵活快速效率高。
进程操作文件原理
在 Linux 系统中,内核会为每个进程设置一个专门的数据结构用于管理该进程,譬如用于记录进程的状态信息、运行特征等,我们把这个称为进程控制块(Process control block,缩写PCB)。
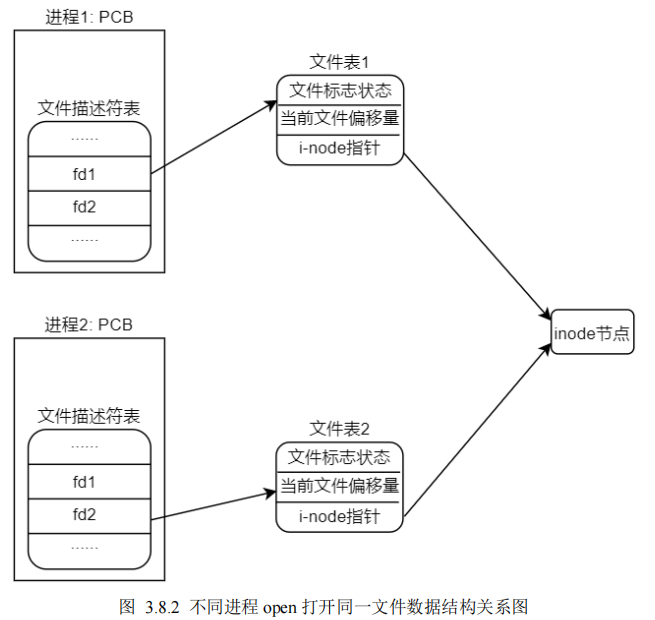
PCB 数据结构体中有一个指针指向了文件描述符表(File descriptors),文件描述符表中的每一个元素索引到对应的文件表(File table),文件表也是一个数据结构体,其中记录了很多文件相关的信息,譬如文件状态标志、引用计数、当前文件的读写偏移量以及 i-node 指针(指向该文件对应的 inode)等,进程打开的所有文件对应的文件描述符都记录在文件描述符表中,每一个文件描述符都会指向一个对应的文件表
返回错误处理与errno
errno是一个全局变量,每种错误都对应一个编号,errno存储函数执行错误编号,也意味会覆盖上一次的错误码。
本质是int型变量,并不是执行所有的系统调用或 C 库函数出错时,操作系统都会设置 errno
c
man 2 xxx用man打开时,可以看返回值有没有

程序当中包含<errno.h>头文件即可,就能获取errno
c
#include <stdio.h>
#include <errno.h>
int main(void)
{
printf("%d\n", errno);
return 0;
}strerror
调用strerror函数可以将errnoo 转换成适合我们查看的字符串信息,C库函数
c
#include <string.h>
char *strerror(int errnum);
c
测试:
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <stdio.h>
#include <errno.h>
#include <string.h>
int main(void)
{
int fd;
/* 打开文件 */
fd = open("./test_file", O_RDONLY);
if (-1 == fd) {
printf("Error: %s\n", strerror(errno));
return -1;
}
close(fd);
return 0;
}strerror 返回的字符串是"No such file or directory",可以很直观的知道 open 函数执行的错误原因是文件不存在

perror函数
这个查看错误的函数用的多,不需要传参errno,而且直接打印错误信息,不是返回字符串,还能在打印前添加自己的信息
c
#include <stdio.h>
void perror(const char *s);s:在错误提示字符串信息之前,可加入自己的打印信息,也可不加,不加则传入空字符串即可。
例子:
c
fd = open("./test_file", O_RDONLY);
if (-1 == fd) {
perror("open error");
return -1;
}exit、_exit、_Exit
程序出错的时候要停止,在 Linux 系统下,进程(程序)退出可以分为正常退出和异常退出。
异常往往更多的是一种不可预料的系统异常,可能是执行了某个函数时发生的、也有可能是收到了某种信号等。
进程正常退出除了可以使用 return 之外,还可以使用 exit()、_exit()以及_Exit()
return 执行后把控制权交给调用函数,结束该进程。
_exit()函数会清除其使用的内存空间,并销毁其在内核中的各种数据结构,关闭进程的所有文件描述符,并结束进程、将控制权交给操作系统。
_exit()和_Exit()两者等价
c
#include <unistd.h>
void _exit(int status);
#include <stdlib.h>
void _Exit(int status);传入status状态标志,一个整数,表示程序的 "退出状态码"。操作系统(如 Windows、Linux)会根据这个值判断程序是否正常结束。
通常约定:status = 0 或 EXIT_SUCCESS(宏定义,值为 0)表示程序正常结束;
status ≠ 0(如 EXIT_FAILURE,宏定义值为 1)表示程序异常终止(具体含义由开发者自定义)
c
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <stdio.h>
int main(void)
{
int fd;
/* 打开文件 */
fd = open("./test_file", O_RDONLY);
if (-1 == fd) {
perror("open error");
_exit(-1);
}
close(fd);
_exit(0);
}这里的意思就是打开失败的时候,传入一个表示程序异常终止
exit()是一个标准 C 库函数,而_exit()和_Exit()是系统调用。执行 exit()会执行一些清理工作,最后调用_exit()函数
c
#include <stdlib.h>
void exit(int status);所以有三种:
main 函数中运行 return
调用 Linux 系统调用_exit()或_Exit()
调用 C 标准库函数 exit()
空洞文件
有一个 test_file,该文件的大小是 4K(也就是 4096 个字节),如果通过 lseek 系统调用将该文件的读写偏移量移动到偏移文件头部 6000 个字节处。使用 write()函数对文件进行写入操作,也就是说此时将是从偏移文件头部 6000 个字节处开始写入数据,也就意味着 4096~6000 字节之间出现了一个空洞,因为这部分空间并没有写入任何数据,称为文件空洞,文件叫做空洞文件。
文件空洞部分实际上并不会占用任何物理空间,直到在某个时刻对空洞部分进行写入数据时才会为它分配对应的空间
多线程操作的时候,利用空洞文件的特性,一个很大的文件,如果单个线程从头开始依次构建该文件需要很长的时间。将文件分为多段,然后使用多线程来操作,每个线程负责其中一段数据的写入。
例子:
在日常电脑使用中,比如迅雷下载文件,会先占用全部空间,也是利用多线程在下载。
c
//查看文件的逻辑大小(包含空洞文件)
ls -h xxx
//查看实际占用存储块大小(不包含空洞文件)
du -h xxx重复打开一个文件
一个进程内多次 open 打开同一个文件,那么会得到多个不同的文件描述符 fd,同理在关闭文件的时候也需要调用 close 依次关闭各个文件描述符
一个进程内多次 open 打开同一个文件,在内存中并不会存在多份动态文件
==一个进程内多次 open 打开同一个文件,不同文件描述符所对应的读写位置偏移量是相互独立的。==同一个文件被多次打开,会得到多个不同的文件描述符,也就意味着会有多个不同的文件表,而文件读写偏移量信息就记录在文件表数据结构,里面的i-node指向的也是同一个inode
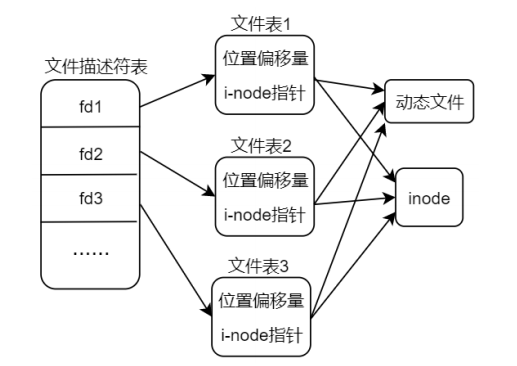
当文件的引用计数为0的时候,系统就会自动关闭动态文件。
重复打开一个文件进行写操作,不调用O_APPEND是分别写入各从各的位置偏移量开始写,所以有重复的位置会覆写,调用了O_APPEND会从文件末尾开始写,所以会接续起来。
复制文件描述符
在 Linux 系统中,open 返回得到的文件描述符 fd 可以进行复制,复制成功之后可以得到一个新的文件描述符,可以多次复制
dup 或 dup2 这两个系统调用对文件描述符进行复制,一样的权限,指向的同一个文件表,使用完毕也要close关闭
c
#include <unistd.h>
int dup(int oldfd);oldfd:需要被复制的文件描述符。
返回值:成功时将返回一个新的文件描述符,由操作系统分配,分配置原则遵循文件描述符分配原则;
如果复制失败将返回-1,并且会设置 errno 值。
c
#include <unistd.h>
int dup2(int oldfd, int newfd);dup2 系统调用修复了这个缺陷,可以手动指定文件描述符,而不需要遵循文件描述符分配原则。
oldfd:需要被复制的文件描述符。
newfd:指定一个文件描述符(需要指定一个当前进程没有使用到的文件描述符)。
返回值:成功时将返回一个新的文件描述符,也就是手动指定的文件描述符 newfd;如果复制失败将返回-1,并且会设置 errno 值
文件共享
就是指前面多次打开同一份文件,复制文件描述符等操作。同时进行 IO 操作指的是一个读写体操作文件尚未调用 close 关闭的情况下,另一个读写体去操作文件。
在多线程里面要考虑,核心就是不同的文件描述符fd。
原子操作和竞争冒险
竞争冒险在linux应用和驱动层都有
操作共享资源的两个进程(或线程),其操作之后的所得到的结果往往是不可预期的,因为每个进程(或线程)去操作文件的顺序是不可预期的,即这些进程获得 CPU 使用权的先后顺序是不可预期的,完全由操作系统调配,这就是所谓的竞争状态。
原子操作就是这个操作像一个原子,是最小执行单位,要么一步也不执行,一旦执行,必须要执行完所有步骤,不可能只执行所有步骤中的一个子集。
1.O_APPEND每次执行 write 写入操作时都会将文件当前写位置偏移量移动到文件末尾,然后再写入数据。不管怎么写入数据都会是从文件末尾写,这样就不会导致出现"进程 A 写入的数据覆盖了进程 B 写入的数据"这种情况了。
2.pread()和 pwrite()都是系统调用,与 read()、write()函数的作用一样,用于读取和写入数据。但是这两个可以实现原子操作。可传入一个位置偏移量 offset 参数,调用 pread 相当于调用 lseek 后再调用 read;同理,调用 pwrite相当于调用 lseek 后再调用 write。所以将偏移量和读写合并了,组成原子操作
c
#include <unistd.h>
ssize_t pread(int fd, void *buf, size_t count, off_t offset);
ssize_t pwrite(int fd, const void *buf, size_t count, off_t offset);fd、buf、count 参数与 read 或 write 函数意义相同。
offset:表示当前需要进行读或写的位置偏移量。
3.O_EXCL 可以用于测试一个文件是否存在,如果不存在则创建此文件,如果存在则返回错误,这使得测试和创建两者成为一个原子操作。
同一个文件创造两次是不允许的,所以最好把检测和创建绑定在一起。
fcntl 和 ioctl
fcntl()函数可以对一个已经打开的文件描述符执行一系列控制操作,譬如复制一个文件描述符(与 dup、dup2 作用相同)、获取/设置文件描述符标志、获取/设置文件状态标志等,类似于一个多功能文件描述符管理工具箱。
c
#include <unistd.h>
#include <fcntl.h>
int fcntl(int fd, int cmd, ... /* arg */ )复制文件描述符(cmd=F_DUPFD 或cmd=F_DUPFD_CLOEXEC);
获取/设置文件描述符标志(cmd=F_GETFD 或 cmd=F_SETFD);
获取/设置文件状态标志(cmd=F_GETFL 或 cmd=F_SETFL);
获取/设置异步 IO 所有权(cmd=F_GETOWN 或 cmd=F_SETOWN);
获取/设置记录锁(cmd=F_GETLK 或 cmd=F_SETLK);
第三个参数需要根据不同的 cmd 来传入对应的实参,配合 cmd 来使用。
返回值:执行失败情况下,返回-1,并且会设置 errno;执行成功的情况下,其返回值与 cmd(操作命令)有关,譬如cmd=F_DUPFD(复制文件描述符)将返回一个新的文件描述符、cmd=F_GETFD(获取文件描述符标志)将返回文件描述符标志、cmd=F_GETFL(获取文件状态标志)将返回文件状态标志等。
ioctl()可以认为是一个文件 IO 操作的杂物箱,通过 ioctl 获取 LCD 相关信息等
c
#include <sys/ioctl.h>
int ioctl(int fd, unsigned long request, ...);fd:文件描述符。
request:此参数与具体要操作的对象有关,没有统一值,表示向文件描述符请求相应的操作。
...:此函数是一个可变参函数,第三个参数需要根据 request 参数来决定,配合 request 来使用。
返回值:成功返回 0,失败返回-1。
截断文件
使用系统调用 truncate()或 ftruncate()可将普通文件截断为指定字节长度
c
#include <unistd.h>
#include <sys/types.h>
int truncate(const char *path, off_t length);
int ftruncate(int fd, off_t length);ftruncate()使用文件描述符 fd 来指定目标文件,而 truncate()则直接使用文件路径 path 来指定目标文件
截断:如果文件目前的大小大于参数 length 所指定的大小,则多余的数据将被丢失;如果文件目前的大小小于参数 length 所指定的大小,则将其进行扩展,对扩展部分进行读取将得到空字节"\0"。
使用 ftruncate()函数进行文件截断操作之前,必须调用 open()函数打开该文件得到文件描述符,并且必须要具有可写权限,也就是调用 open()打开文件时需要指定 O_WRONLY 或 O_RDWR。
调用这两个函数并不会导致文件读写位置偏移量发生改变,所以截断之后一般需要重新设置文件当前的读写位置偏移量,以免由于之前所指向的位置已经不存在而发生错误(譬如文件长度变短了,文件当前所指向的读写位置已不存在)。
标准I/O库
标准 I/O 库则是标准 C 库中用于文件 I/O 操作(譬如读文件、写文件等)相关的一系列库函数的集合,一般都在<stdio.h>头文件里面,这些函数是在文件 I/O(open()、read()、write()、lseek()、close()等)这些系统调用之上的封装函数。
设计库函数为了更好的使用接口
虽然标准 I/O 和文件 I/O 都是 C 语言函数,但是标准 I/O 是标准 C 库函数,而文件 I/O 则是 Linux系统调用;标准 I/O 是由文件 I/O 封装而来,标准 I/O 内部实际上是调用文件 I/O 来完成实际操作的;
可移植性:标准 I/O 相比于文件 I/O 具有更好的可移植性,通常对于不同的操作系统,其内核向应用层提供的系统调用往往都是不同,譬如系统调用的定义、功能、参数列表、返回值等往往都是不一样的;而标准 I/O 库在不同的操作系统之间其接口定义几乎是一样的,所以标准 I/O 在不同操作系统之间相比于文件 I/O 具有更好的可移植性。
性能、效率:标准 I/O 库在用户空间维护了自己的 stdio 缓冲区,所以标准 I/O 是带有缓存的,而文件 I/O 在用户空间是不带有缓存的,所以在性能、效率上,标准 I/O 要优于文件 I/O。
FILE指针
当使用标准 I/O 库函数打开或创建一个文件时,会返回一个指向 FILE 类型对象的指针(FILE *),该 FILE 指针与被打开或创建的文件相关联。
FILE 指针的作用相当于文件描述符,只不过 FILE 指针用于标准 I/O 库函数中、而文件描述符则用于文件I/O 系统调用中。
FILE 是一个结构体数据类型,它包含了标准 I/O 库函数为管理文件所需要的所有信息,包括用于实际I/O 的文件描述符、指向文件缓冲区的指针、缓冲区的长度、当前缓冲区中的字节数以及出错标志等。FILE数据结构定义在标准 I/O 库函数头文件 stdio.h 中。