最近体验了一下 Deepwiki 的 AI 文档生成功能,本文展示其自动生成的《SeaTunnel 云端数据仓库连接器》文档内容,欢迎大家一起"挑刺捉虫",看看 AI 写技术文档到底靠不靠谱?
本文档介绍了 Apache SeaTunnel 的云数据仓库连接器,这些连接器支持与现代云原生分析型数据存储和搜索引擎进行数据集成。它们具备 Source 和 Sink 双向能力,可从分布式云数据仓库中读取数据或写入数据。
如需了解传统数据库连接器,请参阅 JDBC Connectors。如需了解基于文件的云存储连接器,请参阅 File System Connectors。
概览
目前,SeaTunnel 提供以下云数据仓库连接器:
- Elasticsearch Connector:支持 Elasticsearch 2.x 到 8.x 版本的集群,具备向量化、模式演进和多种查询 API 等高级功能。
- SelectDB Cloud Connector:提供面向 SelectDB Cloud 仓库的 Sink 能力,支持精准一次性语义(Exactly-Once Semantics)。
这些连接器基于 SeaTunnel 的统一连接器框架构建,并与平台的 Catalog 系统、Checkpoint 机制和分布式执行引擎集成。
Elasticsearch 连接器架构
Elasticsearch 连接器通过完善的架构实现了 Source 和 Sink 双功能,支持多种 Elasticsearch 部署场景。
核心组件

查询 API 类型与查询方式
Elasticsearch 连接器支持多种查询方式,以满足不同的性能和一致性需求: 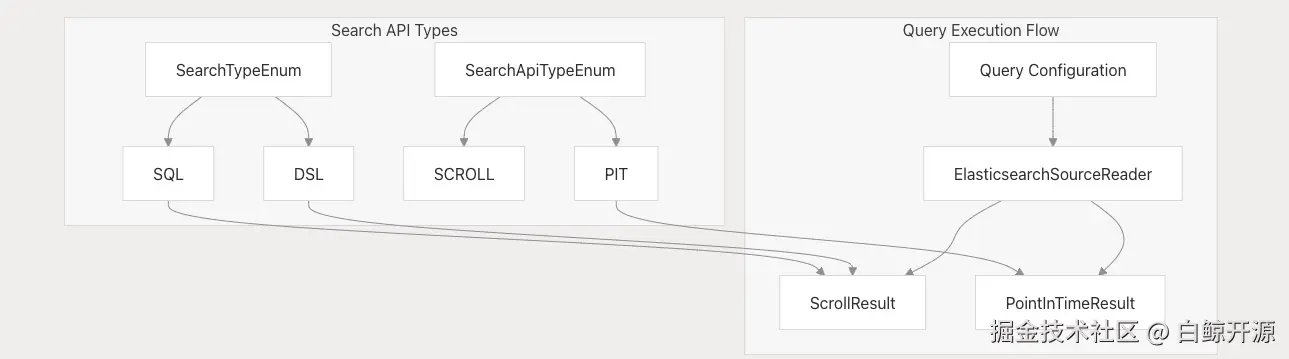
该连接器在 ElasticsearchSourceReader 中实现了多种搜索策略:
- Scroll API :使用
searchByScroll()和searchWithScrollId()方法的传统分页方式 - PIT(Point-in-Time)API :使用
searchWithPointInTime()方法,适用于大规模数据集的高效分页方式 - SQL 查询 :通过
searchBySql()和searchWithSql()方法支持 X-Pack SQL 查询
向量化支持
Elasticsearch Sink 支持向量字段处理,适用于机器学习与 AI 场景:

模式演进(Schema Evolution)
Elasticsearch Sink 支持部分模式演进功能: 
模式演进通过 ElasticsearchSinkWriter.applySchemaChange() 方法实现,目前支持在现有索引中添加列。
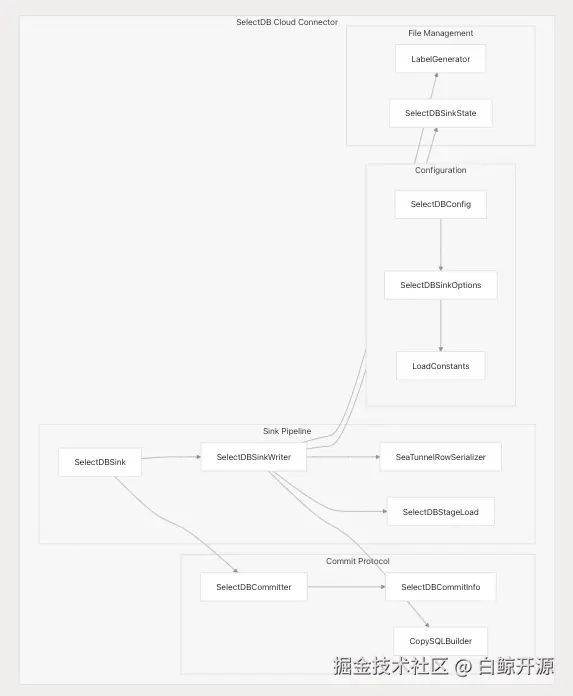
SelectDB Cloud 连接器架构
SelectDB Cloud 连接器仅支持 Sink 功能,专注于高吞吐量批量加载与精准一次性语义(Exactly-Once Semantics)。
核心组件
两阶段提交协议(2PC)
SelectDB Cloud 通过两阶段提交协议实现精准一次性写入: 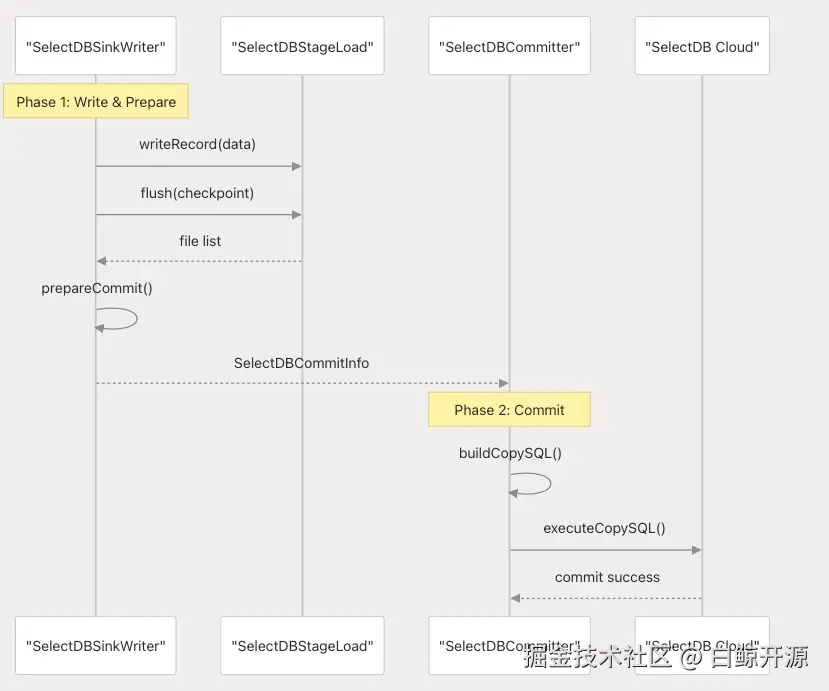
此两阶段提交过程由配置项 enable-2pc 控制,确保数据在 Checkpoint 之间的一致性。
数据序列化格式
SelectDB Cloud 支持多种数据格式用于批量导入:

格式选择通过 selectdb.config.file.type 配置,决定数据上传前的序列化方式。
通用配置模式
两个云数据仓库连接器共享部分 SeaTunnel 核心系统的通用配置模式:
连接配置
| 配置类型 | Elasticsearch | SelectDB Cloud |
|---|---|---|
| 主机配置 | hosts: ["host:port"] |
load-url + jdbc-url |
| 认证信息 | 用户名/密码 | 用户名/密码 + 集群名称 |
| SSL/TLS | tls_verify_certificate, tls_keystore_path |
不适用 |
| 批次控制 | max_batch_size, scroll_size |
sink.buffer-size, sink.buffer-count |
Save Mode 集成
两种连接器均集成了 SeaTunnel 的 Save Mode 系统:
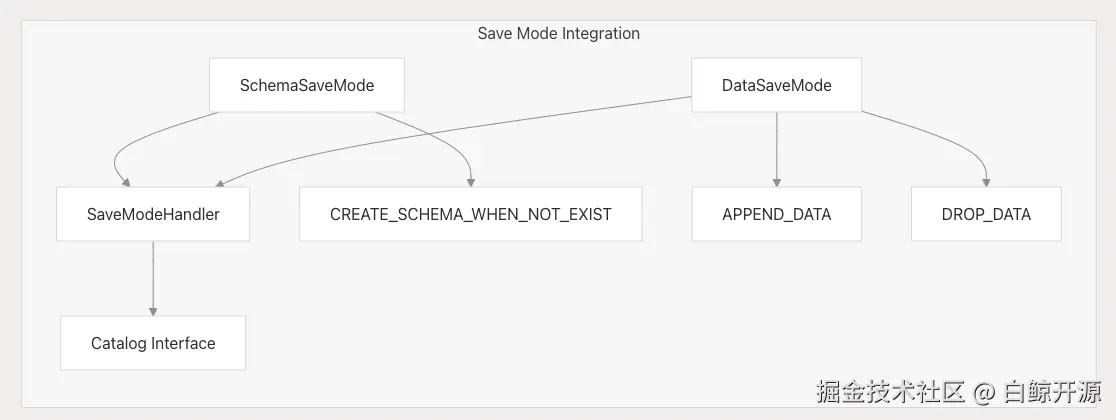
通过 Save Mode,连接器可自动管理 schema 和数据生命周期。
多表支持
Elasticsearch 连接器支持多表同步能力:
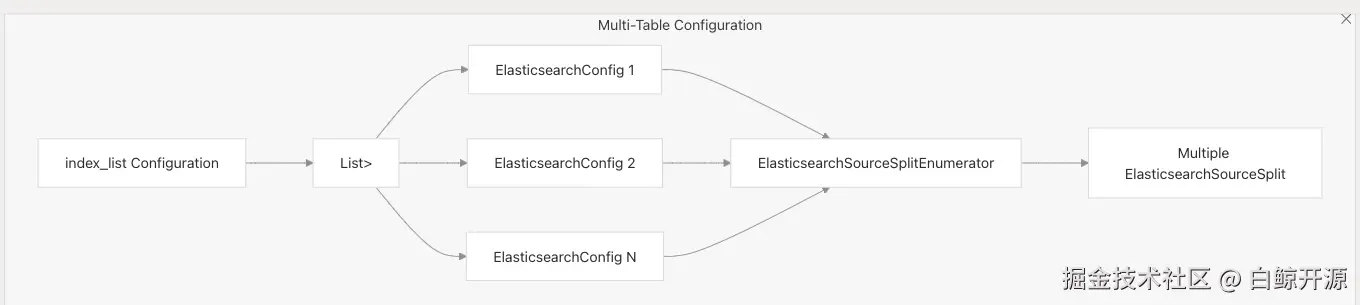
该模式支持在一个作业中同步多个索引的数据。