MyBatis缓存实战指南:一级与二级缓存的深度解析与性能优化
在电商大促期间,我们的用户查询接口QPS从500骤增至5000,数据库连接池频频告警。当我将MyBatis二级缓存应用在用户基础信息模块后,数据库负载直接下降70%------这就是缓存的力量。本文带你彻底掌握MyBatis缓存机制,让性能飞起来!
一、缓存的价值:为什么我们需要它?
核心痛点:数据库交互是系统性能的主要瓶颈。假设单次数据库查询需要10ms:
- 无缓存:重复查询10次 = 100ms等待
- 有缓存:首次10ms + 后续9次0.5ms ≈ 14.5ms
延迟加载的局限性:
- 仅优化级联查询(如用户+订单)
- 对高频单表查询(如用户基础信息)无能为力
缓存的核心作用:
java
// 第一次查询:访问数据库(耗时10ms)
User user1 = sqlSession.selectById(1);
// 第二次查询:命中缓存(耗时0.5ms)
User user2 = sqlSession.selectById(1); 二、一级缓存:SqlSession级别的"私人保险箱"
1. 核心特性
- 默认开启:无需配置,永久存在
- 作用域:同一个SqlSession内有效
- 数据隔离:不同SqlSession缓存不共享
- 自动失效:执行写操作后立即清空
2. 工作流程解析
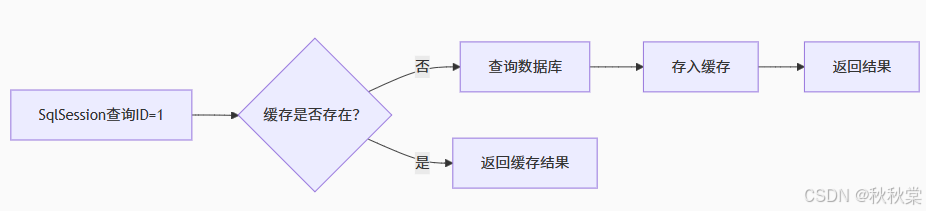
3. 实战注意事项
java
try (SqlSession session = sqlSessionFactory.openSession()) {
// 第一次查询数据库
User user1 = session.selectOne("getUserById", 1);
// 第二次命中缓存(不查库)
User user2 = session.selectOne("getUserById", 1);
// 更新操作清空缓存!
user1.setName("NewName");
session.update("updateUser", user1);
// 第三次重新查询数据库
User user3 = session.selectOne("getUserById", 1);
}典型踩坑场景:
- 长事务中缓存积累过多导致OOM
- 多线程共享SqlSession引发数据错乱
三、二级缓存:Mapper级别的"共享数据库"
1. 核心特性
- 作用域扩大:跨SqlSession共享数据
- 默认关闭:需手动开启
- 数据同步:任何写操作清空整个Mapper缓存
- 序列化要求:缓存对象必须实现Serializable
2. 三级配置流程
步骤1:实体类实现序列化
java
public class User implements Serializable {
private static final long serialVersionUID = 1L;
// 属性及方法...
}步骤2:全局启用二级缓存
xml
<!-- mybatis-config.xml -->
<configuration>
<settings>
<!-- 开启二级缓存总开关 -->
<setting name="cacheEnabled" value="true"/>
</settings>
</configuration>步骤3:Mapper文件声明缓存
xml
<!-- UserMapper.xml -->
<mapper namespace="com.example.UserMapper">
<!-- 声明使用二级缓存 -->
<cache/>
<select id="getUserById" resultType="User">
SELECT * FROM user WHERE id = #{id}
</select>
</mapper>3. 数据流转原理
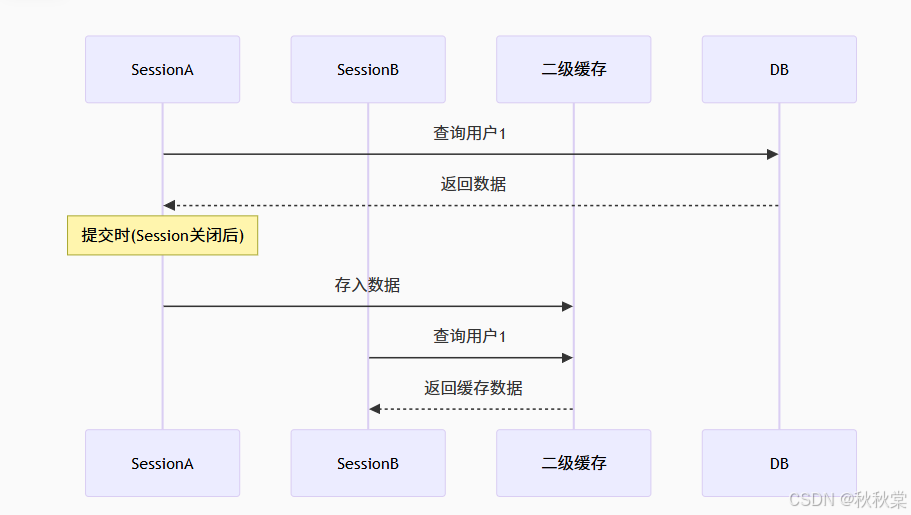
四、两级缓存对比指南
| 特性 | 一级缓存 | 二级缓存 |
|---|---|---|
| 作用域 | SqlSession内部 | 跨SqlSession的Mapper级别 |
| 开启方式 | 默认开启 | 需全局+Mapper双开启 |
| 共享性 | 不可共享 | 所有SqlSession共享 |
| 失效机制 | 写操作清空当前Session缓存 | 写操作清空整个Mapper缓存 |
| 序列化 | 不需要 | 必须实现Serializable |
| 适用场景 | 事务内重复查询 | 跨请求的高频数据查询 |
五、性能优化实战技巧
1. 缓存策略选择矩阵
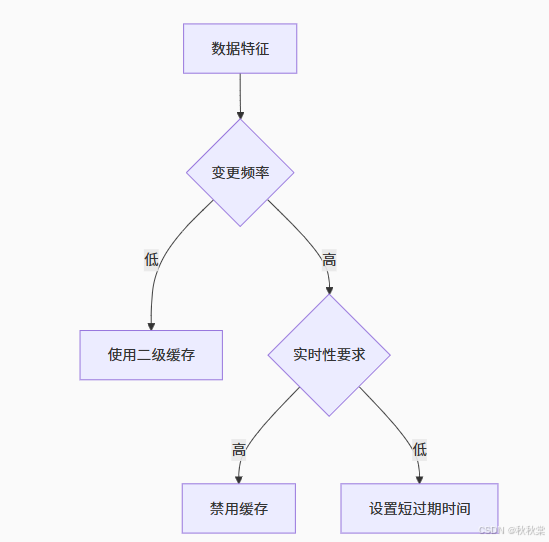
2. 缓存配置进阶
xml
<cache
eviction="LRU" <!-- 淘汰策略:最近最少使用 -->
flushInterval="60000" <!-- 60秒刷新 -->
size="1024" <!-- 最大缓存对象数 -->
readOnly="true"/> <!-- 只读模式提升性能 -->3. 避坑指南
-
缓存穿透 :缓存空对象解决反复查询不存在的数据
javaif (user == null) { cache.put("NULL_OBJECT", placeholder); } -
缓存雪崩:设置随机过期时间避免同时失效
-
分布式环境 :集成Redis实现跨节点缓存共享
xml<cache type="org.mybatis.caches.redis.RedisCache"/>
六、最佳实践总结
-
一级缓存:
- 适合短事务内的重复查询
- 避免在循环中意外触发缓存
-
二级缓存:
-
优先用于基础数据(如配置表、字典表)
-
实时性要求高的业务(如库存)慎用
-
监控缓存命中率:
bashDEBUG [main] - Cache Hit Ratio [UserMapper]: 0.75
-
-
黄金组合:
java// 开启延迟加载解决N+1问题 <setting name="lazyLoadingEnabled" value="true"/> // 二级缓存存储基础数据 <cache eviction="LRU" size="1000"/>
某金融系统应用二级缓存后的真实数据:用户基本信息查询响应时间从35ms降至3ms,数据库CPU使用率从80%降到20%。但切记:缓存是性能加速器,也可能成为数据一致性的炸弹------永远保持对缓存的敬畏之心!
思考题:当缓存命中率达到95%但查询性能反而下降,你首先会排查什么?欢迎在评论区分享你的排查思路!