第54天 -微服务-zookeeper-kafka
前言核心内容总结
1.了解内容
单体**(巨石)架构**
传统架构(单机系统),一个项目一个工程:比如:商品、订单、支付、库存、登录、注册等等,统一部署,一个进程。
all in one的架构方式,把所有的功能单元放在一个应用里。然后把整个应用部署到一台服务器上。如果负载能力不行,将整个应用进行水平复制,进行扩展,然后通过负载均衡实现访问。
架构简单,部署方便,打包编译部署升级效率低下,各功能耦合度高,扩展困难,扩缩容不灵活,适合小型简单项目
SOA(Service Oriented Architecture)是由多个服务组成的分布式系统
各个服务之间通过**ESB(Enterprise Service Bus)**进行通信,ESB是一个由大量规则和原则集成的软件架构,可以将一系列不同的应用程序集成到单个基础架构中,由于没有好的开源方案,只能使用商业公司的产品,因此成本很高。ESB的单点依赖和商业ESB的费用问题反而成为了所有服务的瓶颈。
2.什么是微服务?
微服务(Microservices)是一种软件架构设计模式,它将一个复杂的应用程序拆分为多个小型、独立的服务,每个服务专注于完成单一业务功能,并通过轻量级通信机制(如 HTTP/REST、gRPC)协同工作。简单来说,就是 "化整为零"------ 把原来一个庞大的单体应用,拆成多个可独立开发、部署、维护的小服务。
微服务还是单体,单体在绝大部分时候是更好的选择,即单体优先。
3.Spring Cloud
Spring Cloud
官网地址: https://spring.io/projects/spring-cloud
SpringCloud是目前国内使用最广泛的Java微服务框架。
4.什么是无服务架构(serverless)?
无服务架构(Serverless Architecture) 是一种云计算模型,核心特点是开发者无需关心底层服务器的管理、运维、扩展等基础设施问题,只需专注于编写业务逻辑代码,由云厂商自动处理服务器的资源分配、弹性伸缩、故障恢复等工作。
5.Zookeeper是什么?工作流程是什么?
ZooKeeper 是一个分布式服务框架,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:命名服务、状态同步、配置中心、集群管理等。
ZooKeeper 是一个开源的分布式协调服务,ZooKeeper 是一个典型的分布式数据一致性解决方案,分布式应用程序可以基于 ZooKeeper 实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能。
学习zookeeper是因为它是kafka的重要组件,不过kafka4.0以后不再依赖zookeeper,Kafka 4.0 依赖 KRaft
工作流程如下:
- 生产者启动
- 生产者注册至zookeeper
- 消费者启动并订阅频道
- zookeeper 通知消费者事件
- 消费者调用生产者
- 监控中心负责统计和监控服务状态
生产者、消费者:独享 抢占式
订阅者:共享
6.zookeeper的安装与配置
zookeeper依赖java环境 需要安装jdk或jre
安装略
配置按照二进制安装的配置 我将建议修改成的用红色的字体标出
root@ubuntu1804 \~#grep -v "#" /usr/local/zookeeper/conf/zoo.cfg
tickTime=2000 #"滴答时间",用于配置Zookeeper中最小的时间单元长度,单位毫秒,是其它时间配置的基础
initLimit=10 #初始化时间,包含启动和数据同步,其值是tickTime的倍数
syncLimit=5 #正常工作,心跳监测的时间间隔,其值是tickTime的倍数
dataDir=/tmp/zookeeper #配置Zookeeper服务存储数据快照的目录,可以自动创建,可以修改为 dataDir=/usr/local/zookeeper/data
dataLogDir=/usr/local/zookeeper/logs #指定日志路径,默认与 dataDir 一致,事务日志对性能影响非常大,强烈建议事务日志目录和 数据目录分开,如果后续修改路径,需要先删除中dataDir中旧的事务日志,否则可能无法启动,此目录可以自动创建,
clientPort=2181 #配置当前Zookeeper服务对外暴露的端口,用户客户端和服务端建立连接会话
preAllocSize:#为事务日志预先开辟磁盘空间。默认是64M,意味着每个事务日志初始大小64M。如果ZooKeeper产生快照频率较大,可以考虑减小这个参数,因为每次快照后都会切换到新的事务日志,即使前面的64M没有写满。
snapCount:#该配置项指定ZooKeeper在将内存数据库保存为快照之前,需要先写多少次事务日志,即,每写几次事务日志就快照一次。默认值为
100000。为了防止所有的ZooKeeper服务器节点同时生成快照(一般情况下,所有集群的实例的配置文件是完全相同的),当某节点的先写事务数量在
(snapCount/2+1,snapCount)范围内时挑选一个随机值做为该节点拍快照的时机。
autopurge.snapRetainCount=3 #3.4.0中的新增功能:启用后,ZooKeeper 自动清除功能,会将只保留此最新3个快照和相应的事务日志,并分别保留在dataDir 和dataLogDir中,删除其余部分,默认值为3,最小值为3
autopurge.purgeInterval=24 #3.4.0及之后版本,ZK提供了自动清理日志和快照文件的功能,这个参数指定了清理频率,单位是小时,需要配置一个1或更大的整数,默认是 0,表示不开启自动清理功能
#通过prometheus监控的相关配置,需要stop再start,restart可能会失败
Metrics Providers
https://prometheus.io Metrics Exporter
#提供prometheus监控功能
metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider
metricsProvider.httpHost=0.0.0.0
metricsProvider.httpPort=7000
metricsProvider.exportJvmInfo=true
定义dataDir目录出现FAILED TO START的报错 原因是dataDir=/usr/local/zookeeper 这么写

开启:/usr/share/zookeeper/bin/zkServer.sh start 适用于包安装
7.ZooKeeper****集群部署
集群角色
1 领导者(Leader)
负责处理写入请求的,事务请求的唯一调度和处理者,负责进行投票发起和决议,更新系统状态
2 跟随者(Follower)
接收客户请求并向客户端返回结果,在选Leader过程中参与投票
3 观察者(Observer)
转交客户端写请求给leader节点,和同步leader状态和Follower唯一区别就是不参与Leader投票,也不参与写操作的"过半写成功"策略
4 学习者(Learner)
和leader进行状态同步的节点统称Learner,包括:Follower和Observer
5 客户端(client)
请求发起方
集群特性:整个集群中只要有超过集群数量一半的 zookeeper工作是正常的,那么整个集群对外就是可用的。反之则不可用
只需要在所有主机的配置文件zoo.cfg里面添加下面的内容 其中
2888端口用于 ZooKeeper 集群内各节点之间的 Leader 选举和数据同步
3888端口用于 ZooKeeper 集群内的 Leader 选举投票。
#格式: server.MyID服务器唯一编号=服务器IP:Leader和Follower的数据同步端口(只有leader才会打开):Leader和Follower选举端口(L和
F都有)
server.1=10.0.0.101:2888:3888
server.2=10.0.0.102:2888:3888
server.3=10.0.0.103:2888:3888
在各个节点生成****ID文件
root@zookeeper-node1 \~#mkdir /usr/local/zookeeper/data; echo 1 > /usr/local/zookeeper/data/myid
root@zookeeper-node2 \~#mkdir /usr/local/zookeeper/data; echo 2 > /usr/local/zookeeper/data/myid
root@zookeeper-node3 \~#mkdir /usr/local/zookeeper/data; echo 3 > /usr/local/zookeeper/data/myid
下面的命令可以看到错误的信息
zkServer.sh start-foreground
注意在官网或者其他地方下载包 例 apache-zookeeper-3.9.3-bin.tar.gz 别下错了
ss -ntl |grep 888
可以看到:
#follower会监听3888/tcp端口
#只有leader监听2888/tcp端口和3888/tcp端口
8.ZooKeeper****客户端访问(了解)
#可连接至zookeeper 集群中的任意一台zookeeper 节点进行以下操作,zkCli.sh 默认连接本机
例如:zkCli.sh -server 10.0.0.103:2181
#输入TAB键可以列出所有支持命令 quit退出
9.什么是MQ?
消息队列(Message Queue,简称 MQ)是构建分布式互联网应用的基础设施,通过 MQ 实现的松耦合架构设计可以提高系统可用性以及可扩展性,是适用于现代应用的最佳设计方案。
消息队列是一种异步的服务间通信方式,适用于无服务器和微服务架构。消息在被处理和删除之前一直存储在队列上。每条消息仅可被一位用户处理一次。消息队列可被用于分离重量级处理、缓冲或批处理工作以及缓解高峰期工作负载。
主流****MQ
目前主流的消息队列软件有 Kafka、RabbitMQ、ActiveMQ、RocketMQ等,还有相对小众的消息队列软件如ZeroMQ、Apache Qpid 等。
10.kafka的工作机制是什么?
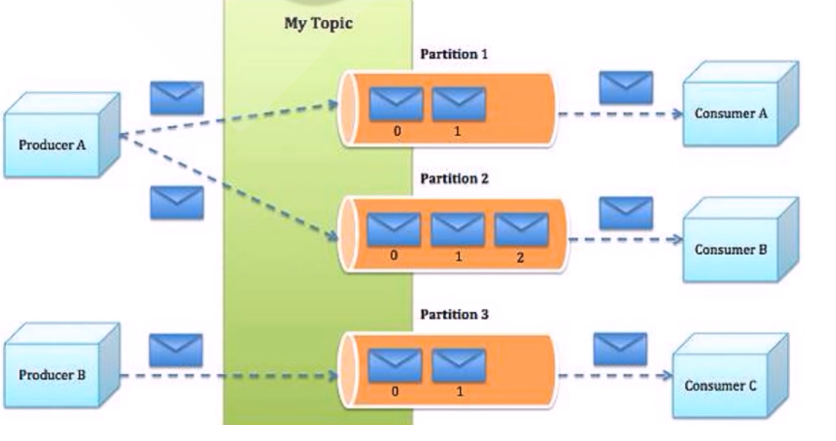
Producer:Producer即生产者,消息的产生者,是消息的入口。负责发布消息到Kafka broker。
Consumer:消费者,用于消费消息,即处理消息
Broker:Broker是kafka实例,每个服务器上可以有一个或多个kafka的实例,假设每个broker对应一台服务器。每个kafka集群内的broker
都有一个不重复的编号,如: broker-0、broker-1等......
Controller**:**是整个 Kafka 集群的管理者角色,任何集群范围内的状态变更都需要通过 Controller 进行,在整个集群中是个单点的服务,可
以通过选举协议进行故障转移,负责集群范围内的一些关键操作:主题的新建和删除,主题分区的新建、重新分配,Broker 的加入、退出,
触发分区 Leader 选举等,每个 Broker 里都有一个 Controller 实例,多个 Broker 的集群同时最多只有一个 Controller 可以对外提供集群管
理服务,Controller 可以在 Broker 之间进行故障转移,Kafka 集群管理的工作主要是由 Controller 来完成的,而 Controller 又通过监听
Zookeeper 节点的变动来进行监听集群变化事件,Controller 进行集群管理需要保存集群元数据,监听集群状态变化情况并进行处理,以及
处理集群中修改集群元数据的请求,这些主要都是利用 Zookeeper 来实现
Topic:消息的主题,可以理解为消息的分类,一个Topic相当于数据库中的一张表,一条消息相当于关系数据库的一条记录,或者一个Topic
相当于Redis中列表数据类型的一个Key,一条消息即为列表中的一个元素。kafka的数据就保存在topic。在每个broker上都可以创建多个
topic。
虽然一个 topic的消息保存于一个或多个broker 上同一个目录内, 物理上不同 topic 的消息分开存储在不同的文件夹,但用户只需指定消息的
topic即可生产或消费数据而不必关心数据存于何处,topic 在逻辑上对record(记录、日志)进行分组保存,消费者需要订阅相应的topic 才能
消费topic中的消息。
**Consumer group:**每个consumer 属于一个特定的consumer group(可为每个consumer 指定 group name,若不指定 group name 则
属于默认的group),同一topic的一条消息只能被同一个consumer group 内的一个consumer 消费,类似于一对一的单播机制,但多个
consumer group 可同时消费这一消息,类似于一对多的多播机制,默认消费组的多个消费者是共享消息
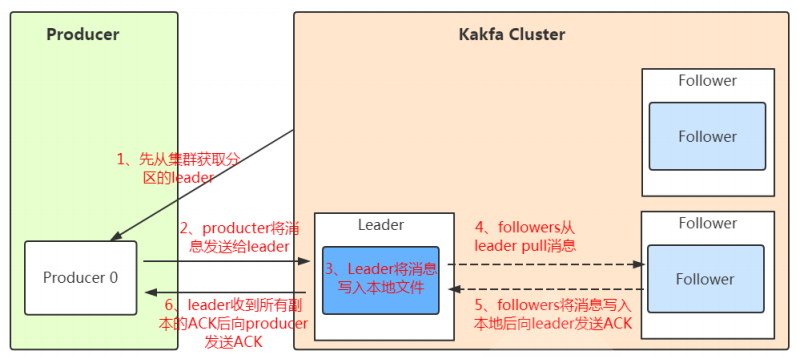
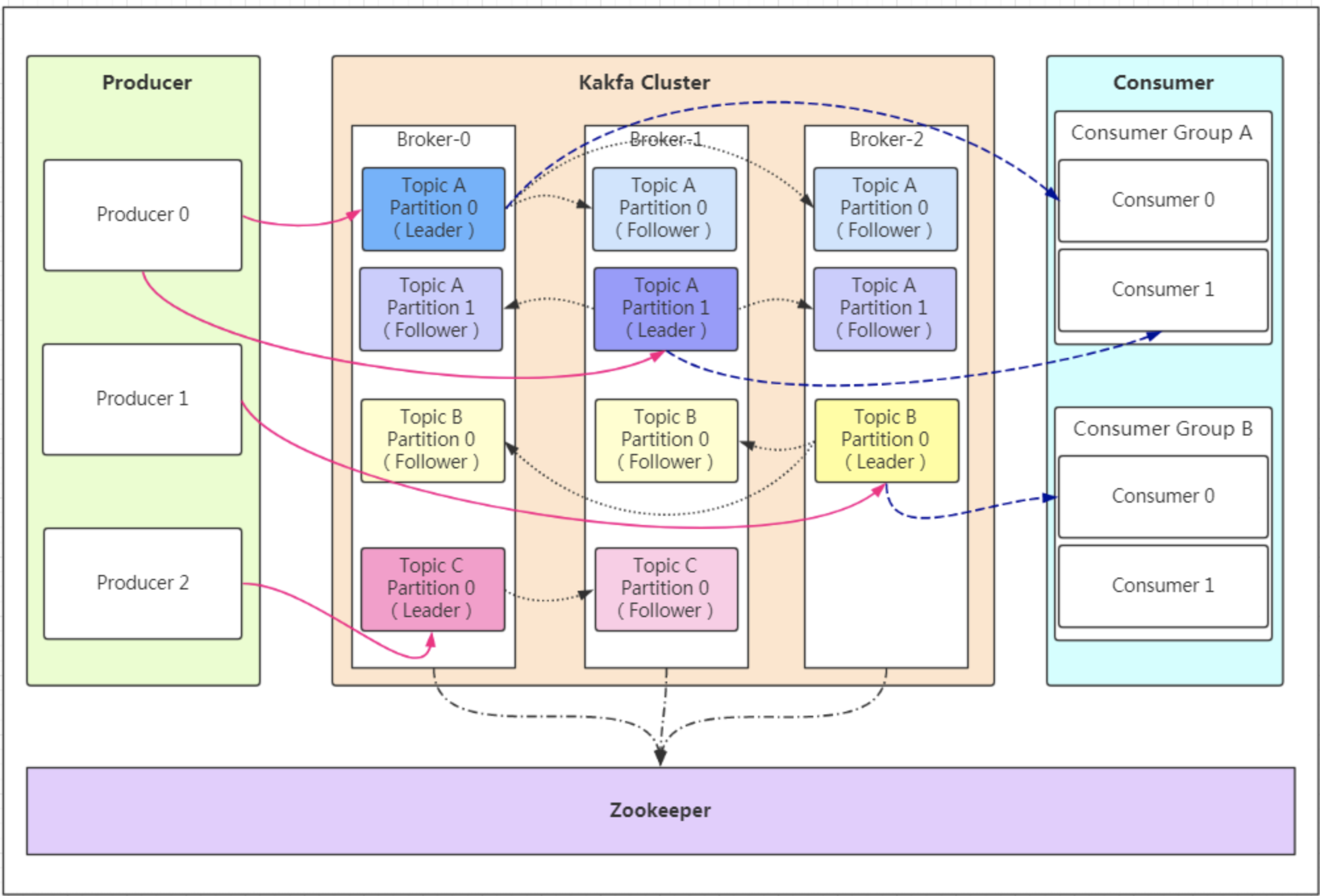
分区和副本的优势:
实现存储空间的横向扩容,即将多个kafka服务器的空间组合利用
提升性能,多服务器并行读写
实区即 leader 分布在不同的kafka 服务器,并且有对应follower 分布在和leader不同的服务器上
11.kafka的安装配置与注意事项
kafka的安装需要java的环境
①安装jdk 8以上的
②#修改配置文件
root@ubuntu2204 kafka#vim config/zookeeper.properties
dataDir=/data/zookeeper #此目录无需手动创建,启动会自动创建
root@ubuntu2204 kafka#bin/zookeeper-server-start.sh config/zookeeper.properties
#修改配置文件
root@ubuntu2204 kafka#vim config/server.properties
log.dirs=/data/kafka-logs
root@ubuntu2204 kafka#bin/kafka-server-start.sh config/server.properties #前台执行 如下图所示 如果要后台执行 则bin/kafka-server-start.sh -daemon config/server.properties
遇到的问题
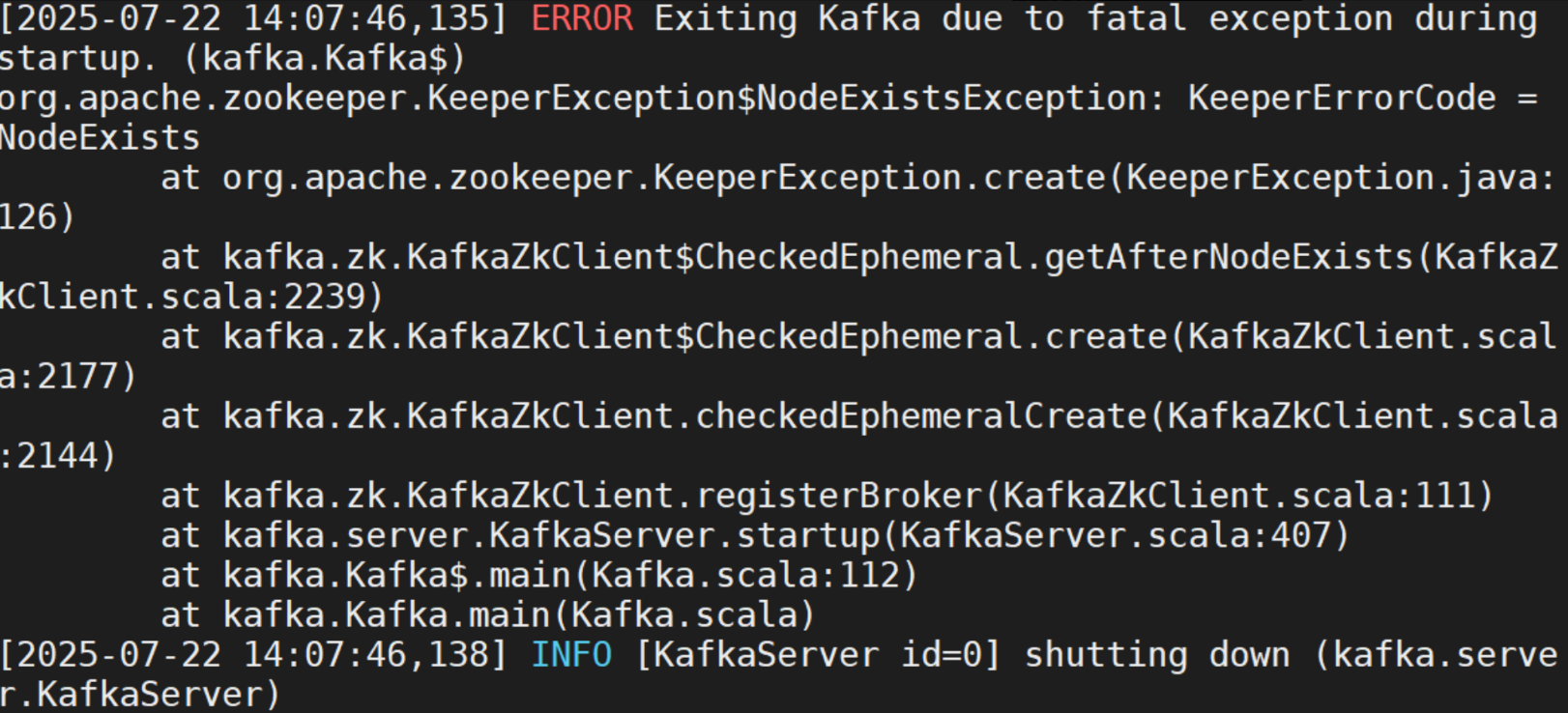
config/server.properties 里面的broker.id和上一个主机安装的id一样 要保持broker.id 唯一

修改broker.id后依然出现报错(如上),原因是存在日志的元数据还是跟之前的broker.id一样(类似于浏览器的cookie缓存),删掉相应的日志即可:rm -rf /data/kafka-logs/*
12.基于zookeeper模式的集群(重点)
10.0.0.101 node1
10.0.0.102 node2
10.0.0.103 node3
....config/server.properties文件修改的地方如下
Zookeeper连接信息,如果是zookeeper集群,则以逗号隔开,此行必须修改
zookeeper.connect=10.0.0.101:2181,10.0.0.102:2181,10.0.0.103:2181 #根据自己的主机ip来
kafka监听端口,默认9092
listeners=PLAINTEXT://10.0.0.101:9092 #当前主机的ip地址
常见命令
kafka-topics.sh #消息的管理命令
kafka-console-producer.sh #生产者的模拟命令
kafka-console-consumer.sh #消费者的模拟命令
创建Topic 在一个机器上创建就行
创建topic名为 hehe,partitions(分区)为3,replication(每个分区的副本数/每个分区的分区因子)为 2
usr/local/kafka/bin/kafka-topics.sh --create --topic hehe --bootstrap-server 10.0.0.101:9092 -
-partitions 3 --replication-factor 2
在各节点上观察生成的相关数据
/usr/local/kafka/data/
获取所有Topic
/usr/local/kafka/bin/kafka-topics.sh --list --bootstrap-server 10.0.0.101:9092
查看Topic详情
状态说明:hehe 有三个分区分别为0、1、2,分区0的leader是2 (broker.id),分区 0 有2 个副本,并且状态都为 lsr(ln-sync,表示可以参加选举成为 leader)。

/usr/local/kafka/bin/kafka-topics.sh --describe --bootstrap-server 10.0.0.101:9092 --topic hehe
生产 Topickafka-console-producer.sh 格式
#发送消息命令格式: 出来是交互式的输入消息
kafka-console-producer.sh --broker-list <kafkaIP1>:<端口>,<kafkaIP2>:<端口> --topic <topic名称> --producer-property group.id=<组名>
举例:
/usr/local/kafka/bin/kafka-console-producer.sh --broker-list 10.0.0.101:9092,10.0.0.102:9092,10.0.0.103:9092 --topic hehe
**消费 Topic (即接收信息)**kafka-console-consumer.sh 格式
#接收消息命令格式:
kafka-console-consumer.sh --bootstrap-server <host>:<post> --topic <topic名称> --from-beginning --consumer-property group.id=<组名称>
举例:
/usr/local/kafka/bin/kafka-console-consumer.sh --topic hehe --bootstrap-server 10.0.0.102:9092
--from-beginning
#一个消息同时只能被同一个组内一个消费者消费(单播机制),实现负载均衡,而不能组可以同时消费同一个消息(多播机制)
在node2主机输入下面的内容
/usr/local/kafka/bin/kafka-console-consumer.sh --topic wang --bootstrap-server 10.0.0.102:9092 --from-beginning --consumer-property group.id=group2
在node3主机输入下面的内容
/usr/local/kafka/bin/kafka-console-consumer.sh --topic wang --bootstrap-server 10.0.0.103:9092 --from-beginning --consumer-property group.id=group3
删除****Topic
/usr/local/kafka/bin/kafka-topics.sh --delete --bootstrap-server
10.0.0.101:9092,10.0.0.102:9092,10.0.0.103:9092 --topic hehe
13.什么是消息挤压,怎么解决?
消息积压是指在消息传递系统中,积累了大量未被处理或未被消费的消息Kafka 消息积压可能由多种原因引起,以下是一些可能的原因:
Kafka 消息积压可能由多种原因引起,以下是一些可能的原因:
- **消费者处理速度慢:**如果消费者处理消息的速度不足以跟上生产者的速度,就会导致消息积压。这可能是因为消费者逻辑复杂、消费者数量不足、消费者宕机或者网络延迟等原因引起的。
- **消费者宕机:**如果某个消费者宕机,其负责处理的分区将没有消费者来消费消息,导致消息在该分区上积压。
- **网络问题:**网络故障可能导致生产者和消费者之间的通信延迟或中断,从而影响消息的传递速度。
- 硬件资源不足: Kafka 集群所在的机器,包括生产者、消费者和 Broker 所在的机器,可能由于 CPU、内存或磁盘等资源不足,导致消息处理速度变慢。
- **分区不均匀:**如果某些分区的负载比其他分区更高,可能导致这些分区上的消息积压。这可能是由于分区数量设置不合理、数据分布不均匀等原因引起的。
- **生产者速度过快:**如果生产者生产消息的速度过快,而消费者无法及时处理,就会导致消息积压。
- 配置不当: Kafka 的一些配置参数,如副本数、分区数、消费者数量等,需要根据实际情况进行合理的配置。如果配置不当,可能导致消息积压问题。
- **异常情况:**突发性的异常情况,如硬件故障、网络故障、软件 bug 等,都可能导致消息积压。
Kafka 消息积压可能的解决方案: - 增加消费者数量:如果消费者处理速度不足导致消息积压,可以增加消费者的数量来提高处理速度。
- 扩展Kafka集群:如果消息积压是由于Kafka集群的吞吐量达到极限导致的,考虑扩展Kafka集群的规模来增加其处理能力。
- 数据分区:合理划分数据分区可以提高并行处理能力,从而减少消息积压。
- 数据清理:定期清理过期的数据和日志文件,以释放磁盘空间并提高性能。
- 优化消费者代码:检查消费者代码,确保它们是高效的。可能存在一些性能瓶颈或不必要的延迟。
- 调整Kafka配置:根据需要调整Kafka的配置参数,例如增加分区数量、调整副本数量、调整日志清理策略等。
- 监控和警报:设置监控系统,及时发现消息积压问题并发送警报。这样可以在问题出现之前采取行动。
- 故障排除:检查系统日志,查找可能的问题源,并采取相应的措施解决问题。
kafka 要发现消息积压,可以考虑以下方法: - 监控工具: Kafka 提供了一些监控工具,例如 Kafka Manager、Burrow、Kafka Offset Monitor 等。这些工具可以帮助你监控每个分区的偏移量(offset)和消费者组的状态。通过检查偏移量的增长速度,你可以判断是否有消息积压。
- Consumer Lag**:** Consumer Lag 是指消费者组相对于生产者的消息偏移量的差异。通过监控 Consumer Lag,你可以了解消费者是否跟上了生产者的速度。如果 Consumer Lag 增长较快,可能表示消息积压。
- Kafka Logs****目录: Kafka 的每个分区都有一个日志目录,其中包含了该分区的消息数据。可以检查每个分区的日志目录,查看是否有大量的未消费的消息。
- Kafka Broker Metrics**:** Kafka 提供了一系列的 broker metrics,包括消息入队速率、出队速率等。通过监控这些指标,可以了解Kafka 集群的负载状况。
- **操作系统资源:**如果 Kafka 所在的机器资源不足,可能导致消息积压。监控 CPU、内存、磁盘等系统资源,确保它们没有达到极限。
- **警报系统:**设置警报系统,当某些指标达到预定的阈值时触发警报,通知运维人员或相关团队及时处理。
通过Kafka提供的工具查看格式:
#发现当前消费的offset和最后一条的offset差距很大,说明有大量的数据积压
kafka-consumer-groups.sh --bootstrap-server {kafka连接地址} --describe --group {消费组} | --all-groups