背景
作为一个非算法的研发同学,虽然平常业务与开发中或多或少都接触过AI相关知识与场景,但是还真没有怎么完整了解过它,随着大模型的火热,我突然意识到:既然AI已经强大到可以回答各种复杂问题,为什么不让它来教我理解AI本身呢?
这个想法一出现就让我兴奋不已。毕竟:
- 我的目标很明确:理解AI的核心概念原理和实际应用,暂时不需要深入算法底层细节
- 大模型恰好擅长用通俗易懂的方式解释复杂概念
- 我可以随时提问,获得个性化的解答,比看教科书高效多了 于是,我决定开启一场特殊的学习实验:用AI学AI。 我打开大模型,输入了这样一段提示词:
"我是一名前端开发工程师,想要系统学习AI相关知识。请从开发者的角度,用我能理解的方式介绍人工智能的基础概念、技术发展历程和实际应用场景。重点关注概念理解和应用层面,暂时不需要深入数学公式和算法细节。先给我一个大纲,例如分为几个篇章,各自核心内容包括什么"
下面是它的回答:
明白了!面向非算法同学的入门科普,那内容重点应该放在理解概念、应用场景和实际体验上:
第一篇:《AI全景图:工程师的AI入门指南》
核心内容:
- AI是什么?开发者视角下的技术定义和价值
- AI技术栈全貌:从传统编程到AI编程的演进
- AI家族成员解析:机器学习、深度学习、大模型的层次关系
- API优先的学习方式:像调用接口一样使用AI能力
- AI如何改变开发工作流:从需求分析到部署上线的全流程升级
- 开发者学习AI的路线图:3个月内具备AI应用开发能力
- 用AI学习AI:最好的AI老师就是AI本身
第二篇:《机器学习实战:开发者的算法应用指南》
核心内容:
- 从"调用API"到"理解算法":机器学习的三大任务类型解析
- 分类vs回归:开发者最常遇到的两大问题类型
- 数据处理:开发者的新技能栈(数据就是新的代码)
- 算法选择:像选择技术栈一样选择机器学习算法
- 模型训练和评估:像调试代码一样优化模型性能
- 实战项目案例:用户流失预测、内容推荐、API性能预测
- 生产环境部署:模型服务化、监控和更新策略
- 常见坑点和解决方案:过拟合、欠拟合、类别不平衡的实用解决方案
第三篇:《深度学习揭秘:神经网络如何模拟大脑思考》
核心内容:
- 神经网络的直观理解(不涉及数学推导)
- 图像识别、语音合成等酷炫应用体验
- CNN处理图像、RNN处理序列的生活化解释
- 用大模型理解为什么深度学习这么强大
- 普通人如何使用现成的深度学习服务
- 深度学习的局限性和注意事项
第四篇:《大模型时代:开发者的AI应用新范式》
核心内容:
- 大模型核心技术揭秘:为什么突然"智能涌现"了?
- 大模型如何重新定义软件开发?
- 开发者必知的大模型工具与API
- 提示工程:开发者的新核心技能
- 基于大模型的应用架构设计
- 开发者在AI时代的技能进化
- AI技术选型指南:什么场景用什么技术?
- 未来展望:AI-First 的软件开发
写作风格调整
- 零门槛:用生活中的例子解释技术概念
- 重体验:让读者动手试用工具,而不是理解原理
- 强实用:重点讲"能用来做什么"而不是"为什么能做"
- 有趣味:用故事和类比让内容更生动
- 接地气:关注普通人关心的实际问题
这样调整后,文章更适合非算法背景的读者快速入门,你觉得这个方向如何?
整体上我觉得还挺好,但是内容略微有点粗略,至少我个人还是有很多不太能完全理解的地方,于是我便让AI每个篇章单独去回答,整体框架都是AI提供的,但是内容我根据自己的想法和问题进行了很多轮对话后补全,最后呈现出来就是本篇文章了~
第一篇 AI全景图:工程师的AI入门指南
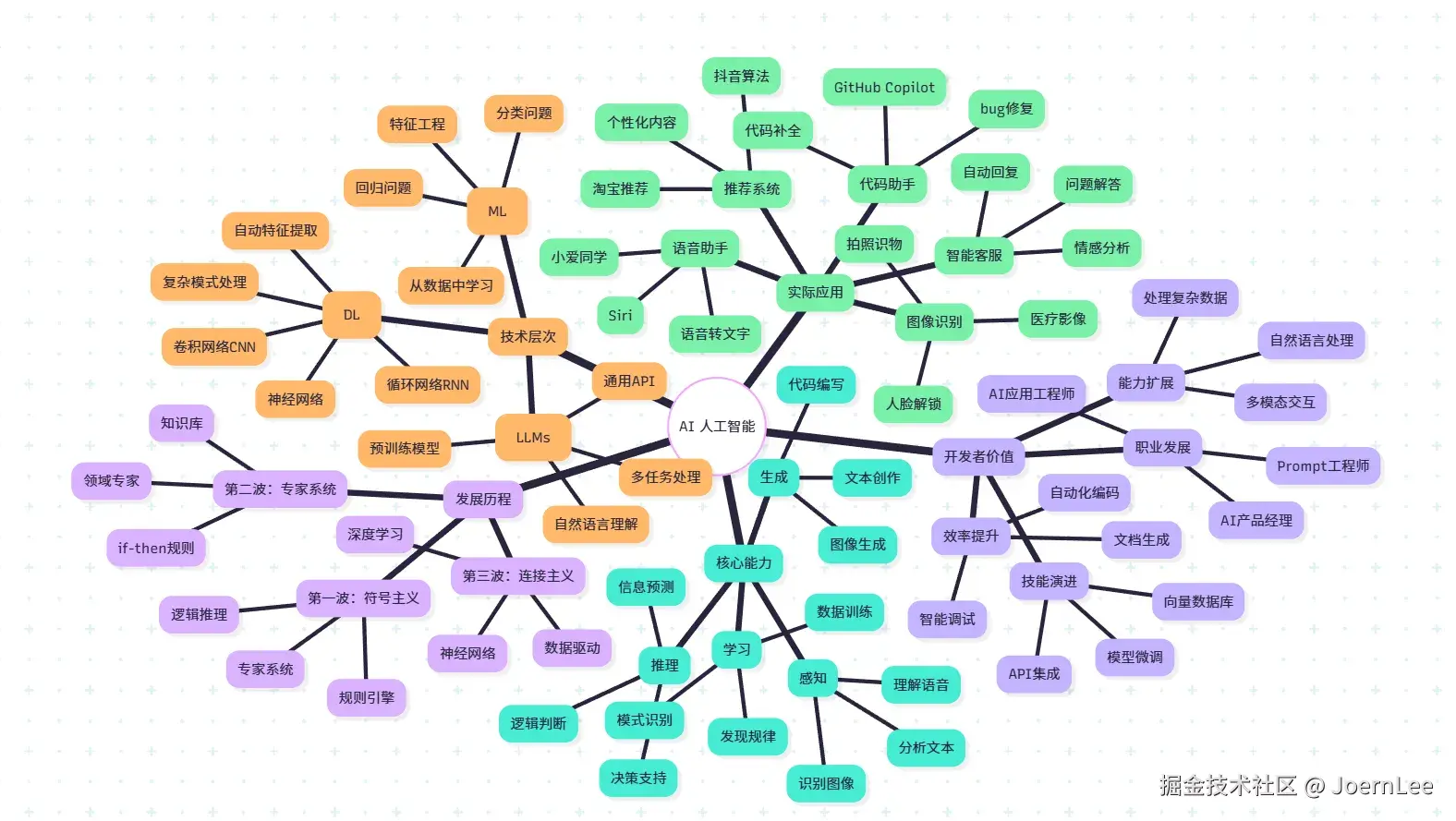
AI是什么
简单定义: AI(人工智能)是让计算机表现出类似人类智能行为的技术总称。
开发者视角: AI就是让程序能够:
- 感知:识别图像、理解语音、分析文本
- 学习:从数据中自动发现规律和模式
- 推理:基于已有信息做出判断和预测
- 生成:创造新的内容(文本、图像、代码等)
技术层次:
scss
AI(人工智能)- 总体目标
├── 机器学习(ML) - 让程序从数据中学习
├── 深度学习(DL) - 用神经网络处理复杂模式
└── 大模型(LLMs) - 预训练的超大规模智能系统实际应用:
- 推荐算法(淘宝、抖音)
- 图像识别(人脸解锁、拍照识物)
- 语音助手(Siri、小爱同学)
- 智能客服(自动回复、问题解答)
- 代码助手(GitHub Copilot)
核心特征: 不需要为每种情况编写规则,而是让程序通过大量数据"学会"如何处理类似情况。
AI的价值
对开发者而言: AI技术栈为我们提供了处理复杂数据模式与快速生成内容的工具集 。机器学习让我们能从数据中自动发现规律和做预测 ;深度学习让我们处理图像、语音等复杂信息;大模型让我们理解和生成自然语言。原本需要手工编写复杂算法的智能功能,现在通过训练模型或调用API就能实现。
对产品而言: AI赋予了产品感知、理解和决策的能力。从推荐系统的个性化匹配,到图像识别的自动分类,从语音助手的交互体验,到智能客服的问题解答------AI让产品能够"看懂"图片、"听懂"语音、"理解"文本,并做出智能响应。
本质上: AI是数据驱动决策的技术基础设施 ,让软件从"执行指令"进化到"学习推理"。它将人类的感知和认知能力编码成算法,让每个应用都能拥有类似人类的智能处理能力。
AI家族成员解析
作为开发者,理解AI技术栈就像理解前端框架的演进史一样重要。让我用我们熟悉的编程概念来解析AI这个"大家族"。
AI技术架构的演进史
第一波(1950s-1960s):符号主义时代
javascript
// 类似早期的规则引擎
const chessAI = {
rules: [
"if 对方暴露王,then 将军",
"if 可以吃子,then 优先考虑"
],
makeMove(board) {
// 基于预设规则的逻辑推理
return this.evaluateRules(board);
}
};第二波(1980s):专家系统时代
javascript
// 类似配置驱动的系统
const medicalExpert = {
knowledgeBase: {
"发烧 + 咳嗽": "感冒",
"胸痛 + 呼吸困难": "肺炎"
},
diagnose(symptoms) {
return this.knowledgeBase[symptoms.join(" + ")];
}
};第三波(2010s+):连接主义/数据驱动时代
javascript
// 类似现代的数据驱动框架
const modernAI = {
model: neuralNetwork,
async predict(input) {
// 从海量数据中学习模式
return await this.model.forward(input);
}
};机器学习:让程序自己写程序
传统编程 vs 机器学习的思维转换:
csharp
// 传统编程:我们写规则
function detectSpam(email) {
if (email.includes('中奖') ||
email.includes('免费') ||
email.from.includes('noreply')) {
return 'spam';
}
return 'normal';
}
// 机器学习:让程序从数据中学习规则
const spamDetector = trainModel(
emails, // 输入数据
labels, // 正确答案
algorithm // 学习算法
);
// 模型自动发现:某些词汇组合 + 发送时间 + 链接数量 = 垃圾邮件ML的核心工作流程:
markdown
数据收集 → 特征工程 → 模型训练 → 评估优化 → 部署应用
↓ ↓ ↓ ↓ ↓
像收集用户 像设计数据库 像编译代码 像性能测试 像发布上线
行为日志 字段结构 优化算法 调试Bug 监控运维两大核心问题:分类 vs 回归
arduino
// 分类问题:离散标签预测(像枚举值)
const classificationTasks = {
email: ['spam', 'normal'], // 二分类
image: ['cat', 'dog', 'bird'], // 多分类
sentiment: ['positive', 'negative', 'neutral']
};
// 回归问题:连续数值预测(像计算结果)
const regressionTasks = {
price: 1234.56, // 房价预测
temperature: 23.8, // 温度预测
duration: 45.2 // 用户停留时长
};深度学习:自动特征工程的革命
传统ML vs 深度学习的区别:
arduino
// 传统机器学习:需要手工特征工程
function extractFeatures(image) {
return {
brightness: calculateBrightness(image),
edges: detectEdges(image),
colors: extractColorHistogram(image),
texture: calculateTexture(image)
// 需要专家知识设计几十个特征...
};
}
// 深度学习:自动特征学习
const deepModel = {
layers: [
convolutionalLayer, // 自动学习边缘特征
poolingLayer, // 自动学习形状特征
fullyConnectedLayer // 自动学习高级概念
],
// 模型自己发现:像素组合 → 边缘 → 形状 → 物体
};深度学习的突破性意义:
就像从手写DOM操作到声明式框架的跃迁:
ini
// 手写DOM(传统ML的特征工程)
document.getElementById('list').innerHTML = '';
data.forEach(item => {
const li = document.createElement('li');
li.textContent = item.name;
li.addEventListener('click', handleClick);
document.getElementById('list').appendChild(li);
});
// React声明式(深度学习的自动化)
const List = ({ data }) => (
<ul>
{data.map(item =>
<li key={item.id} onClick={handleClick}>
{item.name}
</li>
)}
</ul>
);深度学习让我们从"手工设计特征"进化到"自动学习特征"。
大模型:预训练的超级API
传统开发 vs 大模型开发:
javascript
// 传统方式:从零构建NLP功能
class TextProcessor {
constructor() {
this.tokenizer = new Tokenizer();
this.posTagging = new POSTagger();
this.sentimentAnalyzer = new SentimentAnalyzer();
// 需要集成N个专门的库...
}
async process(text) {
const tokens = this.tokenizer.tokenize(text);
const tags = this.posTagging.tag(tokens);
const sentiment = this.sentimentAnalyzer.analyze(tokens);
// 几百行复杂的处理逻辑...
return result;
}
}
// 大模型方式:一个API搞定所有NLP任务
const textProcessor = async (text, task) => {
const response = await openai.chat.completions.create({
model: "gpt-4",
messages: [
{ role: "system", content: `执行${task}任务` },
{ role: "user", content: text }
]
});
return response.choices[0].message.content;
};
// 用法简单得令人震惊
await textProcessor("今天天气不错", "情感分析");
await textProcessor("Hello world", "翻译成中文");
await textProcessor("写一篇产品介绍", "内容生成");大模型的游戏规则改变:
- 从训练模型到调用API
csharp
// 以前:需要准备数据、训练模型、部署服务
const model = await trainCustomModel(data, labels);
// 现在:直接调用预训练模型
const result = await callLLMAPI(prompt);- 从特定任务到通用能力
ini
// 以前:每个任务需要专门的模型
const spamDetector = loadModel('spam-detection');
const translator = loadModel('translation');
const summarizer = loadModel('summarization');
// 现在:一个模型处理多种任务
const llm = loadModel('gpt-4');
// 同一个模型可以做分类、翻译、总结、代码生成...符号主义 vs 连接主义:两种AI哲学
符号主义:逻辑编程思维
javascript
// 像写业务规则引擎
const diagnosticSystem = {
rules: [
{ if: ["fever", "cough"], then: "flu" },
{ if: ["chest_pain", "shortness_of_breath"], then: "pneumonia" }
],
diagnose(symptoms) {
return this.rules.find(rule =>
rule.if.every(condition => symptoms.includes(condition))
)?.then;
}
};连接主义:数据驱动思维
javascript
// 像训练神经网络
const diagnosticNetwork = {
weights: trainFromData(symptoms, diagnoses),
predict(symptoms) {
return this.forward(symptoms); // 黑盒推理
}
};现代AI的融合趋势:
javascript
// 神经符号AI:结合两者优势
const hybridAI = {
perception: neuralNetwork, // 连接主义:感知和模式识别
reasoning: ruleEngine, // 符号主义:逻辑推理
async solve(problem) {
const features = await this.perception.extract(problem);
const solution = this.reasoning.infer(features);
return solution;
}
};对开发者的实际意义
技能栈的演进:
ini
// Web 1.0时代
const skills2000 = ['HTML', 'CSS', 'JavaScript'];
// Web 2.0时代
const skills2010 = [...skills2000, 'jQuery', 'AJAX', 'PHP'];
// 现代前端时代
const skills2020 = ['React', 'TypeScript', 'Node.js', 'GraphQL'];
// AI增强时代
const skills2024 = [...skills2020, 'OpenAI API', 'Vector DB', 'Prompt Engineering'];开发模式的变化:
-
数据成为新的代码:训练数据比算法更重要
-
API优先:调用预训练模型比从零训练更高效
-
提示工程:如何"询问"AI成为新技能
-
人机协作:AI辅助开发成为标准工作流
AI如何改变开发工作流
从需求到产品的新流程
传统流程:
需求分析 → 技术选型 → 编码实现 → 测试调试 → 上线维护AI增强流程:
markdown
需求分析 + AI分析
↓
技术选型 + AI能力评估
↓
编码实现 + AI代码助手
↓
测试调试 + AI自动化测试
↓
上线维护 + AI监控分析实际开发场景举例
场景1:智能表单验证
ini
// 传统方式:写一堆正则表达式
const isValidEmail = /^[^\s@]+@[^\s@]+.[^\s@]+$/.test(email);
// AI增强方式:语义理解
const validateWithAI = async (userInput, expectedType) => {
const prompt = `判断这个输入是否是有效的${expectedType}: ${userInput}`;
const result = await callAI(prompt);
return result.isValid;
};场景2:智能日志分析
python
# 传统方式:写复杂的日志解析脚本
def parse_error_log(log_line):
# 100行复杂的正则和字符串处理
pass
# AI增强方式:让AI理解日志含义
def analyze_log_with_ai(log_line):
prompt = f"分析这条错误日志的原因和解决方案: {log_line}"
return ai_client.analyze(prompt)开发者学习AI的路线图
阶段1:API集成入门 (1-2周)
目标:能够在项目中集成AI功能
-
核心技能:
- 调用OpenAI/Claude等主流API
- 理解Token计费和请求限制
- 基础Prompt设计技巧
-
实践项目:
php
// 实现一个AI客服机器人
const chatbot = async (userMessage) => {
const response = await openai.chat.completions.create({
model: "gpt-3.5-turbo",
messages: [
{ role: "system", content: "你是专业客服..." },
{ role: "user", content: userMessage }
]
});
return response.choices[0].message.content;
};阶段2:场景应用实战 (2-4周)
目标:解决实际业务问题
-
核心技能:
- 向量数据库和语义搜索
- 多模态应用(文本+图像)
- 成本优化和性能调优
-
实践项目:
ini
// 智能文档问答系统
const docQA = {
vectorize: text => embeddings.create(text),
search: query => vectorDB.similaritySearch(query),
answer: context => llm.generate(context + query)
};阶段3:深度集成进阶 (1-2月)
目标:构建完整的AI产品
-
核心技能:
- Fine-tuning和模型定制
- AI Agent和工作流设计
- 生产环境部署和监控
-
实践项目:
ini
// AI代码review助手
const codeReviewer = {
analyze: code => staticAnalysis(code) + aiAnalysis(code),
suggest: issues => generateOptimizationSuggestions(issues),
autofix: simple => applyAutomaticFixes(simple)
};学习策略:
- 边用边学:从API调用开始,不要陷入理论
- 项目驱动:每个阶段都有具体的可交付项目
- 社区资源:关注GitHub上的AI项目和开源工具
- 持续跟进:AI技术更新快,保持学习习惯
时间分配建议:
- 70% 实践编码
- 20% 理论学习
- 10% 社区交流
从第一行代码开始,3个月内就能具备AI应用开发能力!
用AI学习AI:开发者的超能力
最神奇的是,AI本身就是学习AI最好的老师:
技术问题即时解答
markdown
我:如何优化OpenAI API的调用性能?
ChatGPT:
1. 批量请求:将多个请求合并
2. 异步处理:使用Promise.all并发调用
3. 缓存策略:相同请求结果缓存
4. 流式响应:大文本分块处理
5. 模型选择:根据任务复杂度选择合适模型代码调试和优化
csharp
// 问题代码
const buggyCode = `
async function processUserData(users) {
const results = [];
for (let user of users) {
const aiResponse = await openai.chat.completions.create({...});
results.push(aiResponse);
}
return results;
}
`;
// 向AI求助:"这段代码有什么性能问题?如何优化?"
// AI会指出串行调用的问题,并提供并发优化方案技术文档理解
当遇到复杂的AI论文或文档时,可以让AI帮忙解释:
- "用开发者能理解的方式解释Transformer架构"
- "RAG(检索增强生成)的具体实现原理是什么?"
- "向量数据库在AI应用中的作用"
AI给开发工作带来的实际改变
创意和效率的双重提升
代码生成: 从写样板代码到描述需求
dart
// 原来:手写CRUD接口
app.get('/users/:id', async (req, res) => {
// 20行标准代码...
});
// 现在:向Copilot描述需求
// "创建一个用户管理的RESTful API,包含CRUD操作和数据验证"
// 几秒钟生成完整代码框架问题解决: 从Google搜索到AI对话
arduino
// 原来:遇到bug → Google → Stack Overflow → 尝试N种方案
// 现在:遇到bug → 问AI → 获得针对性的解决方案和解释需要注意的陷阱
作为开发者,我们也要警惕AI的局限性:
- 代码质量:AI生成的代码需要人工review
- 安全性:AI可能生成有安全漏洞的代码
- 依赖性:不能完全依赖AI,基础能力仍需保持
- 成本控制:API调用费用需要合理规划
开发者的AI时代机遇
新的职业发展方向
- AI应用开发工程师:专注AI产品开发
- Prompt工程师:专门设计和优化AI提示
- AI运维工程师:负责AI系统的部署和监控
- AI产品经理:规划AI功能和用户体验
现有技能的AI升级
- 前端开发 + AI = 智能交互界面
- 后端开发 + AI = 智能数据处理
- 全栈开发 + AI = 端到端智能应用
- DevOps + AI = 智能运维和监控
写在最后:拥抱变化,保持学习
AI不会取代开发者,但会用AI的开发者会取代不会用AI的开发者。
作为技术人,我们最大的优势就是学习与适应性。AI只是我们工具箱里的新工具,就像当年学习Git、Docker、云服务一样。
重要的是:
- 保持好奇心:主动尝试新的AI工具和API
- 实践优先:边用边学,在项目中验证AI的价值
- 理性思考:既不盲目追捧,也不固执排斥
- 持续学习:AI技术发展很快,保持更新
下期预告:《机器学习实战:开发者的算法应用指南》
在下一篇中,我们将深入探索如何在实际项目中应用机器学习,包括数据处理、模型选择、API集成等开发者关心的实操内容。
第二篇 机器学习实战:开发者的算法应用指南
第一篇我们了解了AI的全貌,现在让我们撸起袖子,从API调用走向算法理解,看看如何在实际项目中应用机器学习。
从"调用API"到"理解算法"
还记得第一次调用OpenAI API时的震撼吗?几行代码就能让机器理解自然语言。但作为开发者,我们总是想知道"黑盒子里到底发生了什么"。
机器学习就像我们熟悉的技术栈一样,有自己的"框架"和"设计模式"。理解这些模式,能让我们更好地:
- 选择合适的算法:就像选择React还是Vue
- 优化模型性能:就像优化代码性能
- 解决实际问题:就像用技术解决业务需求
机器学习的三大任务类型
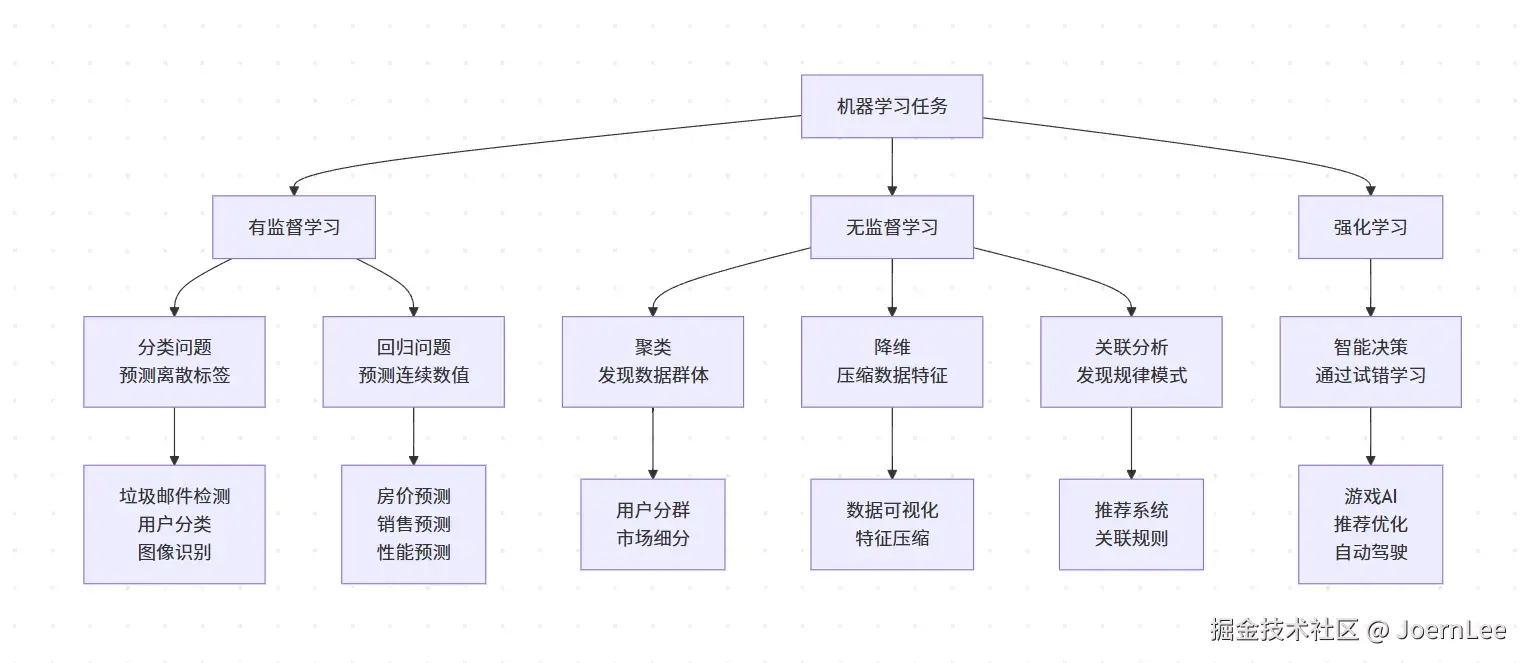
有监督学习:给答案的"考试"
ini
// 类比:带标准答案的编程练习
const trainingData = [
{ input: "用户点击了5次,停留30秒", output: "不会购买" },
{ input: "用户点击了20次,停留300秒", output: "会购买" },
// ... 更多标注数据
];
// 训练后,模型可以预测新用户
const newUser = "用户点击了15次,停留180秒";
const prediction = model.predict(newUser); // "会购买"典型应用场景:
- 邮件 分类:垃圾邮件 vs 正常邮件
- 用户画像:高价值用户 vs 普通用户
- 内容推荐:用户是否会点击某个内容
- 价格 预测:房价、股价、销售额预测
无监督学习:没有标准答案的"探索"
yaml
// 类比:分析用户行为模式,没有预设分类
const userData = [
{ pageViews: 50, sessionTime: 300, orders: 2 },
{ pageViews: 5, sessionTime: 30, orders: 0 },
{ pageViews: 100, sessionTime: 600, orders: 5 },
// ... 大量用户数据
];
// 算法自动发现用户群体
const userGroups = clusteringAlgorithm.fit(userData);
// 结果可能是:活跃用户、潜在用户、流失用户典型应用场景:
- 用户 分群(聚类) :发现不同类型的用户群体
- 异常检测:发现网络攻击、系统故障
- 数据 降维:压缩高维数据,便于可视化
- 关联分析:发现"啤酒与尿布"这样的关联规律
强化学习:在试错中成长
kotlin
// 类比:游戏AI通过不断试错学会玩游戏
class RecommendationAgent {
async recommend(user) {
const action = this.chooseAction(user); // 推荐某个商品
const reward = await this.getReward(action); // 用户是否点击/购买
this.updateStrategy(action, reward); // 更新推荐策略
return action;
}
}典型应用场景:
- 推荐系统:动态调整推荐策略
- 广告投放:实时优化广告出价策略
- 游戏AI:训练NPC或游戏助手
- 自动化运维:系统自动调参和优化
开发者最常遇到的两大问题
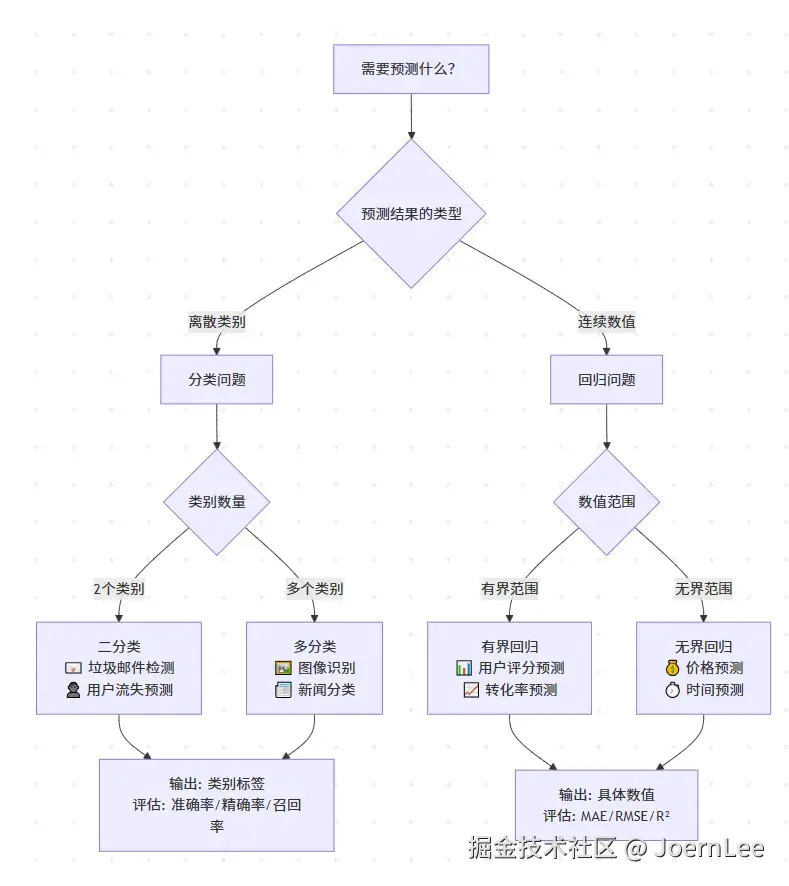
分类问题:给数据"贴标签"
ini
// 就像枚举类型的判断
enum EmailType {
SPAM = "垃圾邮件",
NORMAL = "正常邮件",
PROMOTION = "营销邮件"
}
// 分类模型的输出
function classifyEmail(email) {
const features = extractFeatures(email);
return model.predict(features); // 返回 EmailType 中的一个值
}开发中的分类场景:
- 内容审核:文本是否违规(是/否)
- 用户意图识别:查询意图(搜索/购买/咨询)
- 图片标注:上传图片的内容类型
- 系统监控:日志级别分类(ERROR/WARN/INFO)
回归问题:预测具体数值
javascript
// 就像计算函数的返回值
function predictHousePrice(features) {
const { area, location, age, rooms } = features;
return model.predict([area, location, age, rooms]); // 返回具体价格:2350000
}
// 类似这样的计算逻辑
function calculateUserValue(user) {
return user.orders * 100 + user.sessionTime * 0.1 + user.referrals * 50;
}开发中的回归场景:
- 性能预测:API响应时间预测
- 容量规划:服务器负载预测
- 业务指标:用户生命周期价值(LTV)
- 资源优化:广告出价金额优化
数据处理:开发者的新技能栈
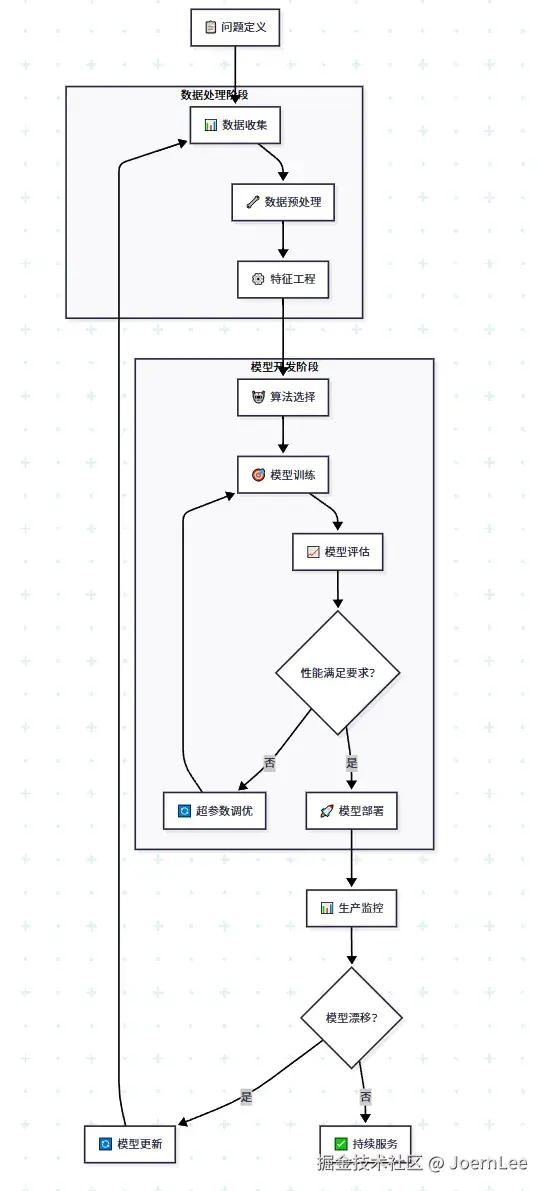
数据就是新的代码
在传统开发中,我们关注代码质量;在机器学习中,数据质量同样重要。
javascript
// 传统开发:代码决定逻辑
function isVIP(user) {
return user.totalSpent > 10000 && user.orderCount > 50;
}
// 机器学习:数据决定逻辑
const vipModel = trainModel(userHistoryData); // 数据"编程"
function isVIP(user) {
return vipModel.predict(user.features) > 0.8;
}数据预处理工作流
- 数据收集(像API设计一样)
arduino
// 设计数据收集接口
const dataSchema = {
userId: "string",
timestamp: "datetime",
action: "enum", // click, view, purchase
metadata: "object"
};
// 数据来源多样化
const dataSources = [
"用户行为日志",
"数据库记录",
"第三方API",
"传感器数据",
"人工标注数据"
];- 数据清洗(像代码重构一样)
bash
import pandas as pd
import numpy as np
# 处理缺失值(就像处理null值)
df['age'].fillna(df['age'].median(), inplace=True)
# 处理异常值(就像边界检查)
df = df[df['price'] < df['price'].quantile(0.99)]
# 数据类型转换(就像类型转换)
df['date'] = pd.to_datetime(df['date'])
df['category'] = df['category'].astype('category')- 特征工程(像设计数据结构一样)
scss
# 从原始数据创建有用特征
def create_features(user_data):
features = {}
# 基础特征
features['avg_session_time'] = user_data['session_times'].mean()
features['total_orders'] = len(user_data['orders'])
# 时间特征
features['days_since_last_order'] = (today - user_data['last_order_date']).days
features['is_weekend_user'] = user_data['weekend_activity'] > user_data['weekday_activity']
# 交互特征
features['orders_per_session'] = features['total_orders'] / user_data['total_sessions']
return features算法选择:像选择技术栈一样
根据问题选择算法
arduino
// 就像根据需求选择技术栈
const algorithmChoice = {
// 数据量小,需要可解释性 → 线性模型
smallData: {
classification: "LogisticRegression", // 像用jQuery,简单直接
regression: "LinearRegression"
},
// 数据量中等,需要高准确率 → 树模型
mediumData: {
classification: "RandomForest", // 像用React,功能强大
regression: "XGBoost"
},
// 数据量大,复杂模式 → 深度学习
bigData: {
classification: "NeuralNetwork", // 像用微服务架构,处理复杂场景
regression: "DeepLearning"
}
};实用算法选择指南
快速启动项目(MVP阶段)
ini
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
# 先用简单模型验证想法
quick_model = LogisticRegression()
quick_model.fit(X_train, y_train)
# 如果效果不理想,再尝试复杂模型
better_model = RandomForestClassifier()
better_model.fit(X_train, y_train)生产环境考虑
makefile
# 考虑因素就像选择数据库一样
model_selection_criteria = {
"推理速度": "线性模型 > 树模型 > 深度学习",
"内存占用": "线性模型 < 树模型 < 深度学习",
"可解释性": "决策树 > 线性模型 > 深度学习",
"准确率": "深度学习 > 集成模型 > 线性模型"
}模型训练和评估:像调试代码一样
训练过程监控
python
# 就像监控应用性能一样
def train_with_monitoring(model, X_train, y_train, X_val, y_val):
history = []
for epoch in range(100):
# 训练一轮
model.fit(X_train, y_train)
# 评估性能(就像运行测试用例)
train_score = model.score(X_train, y_train)
val_score = model.score(X_val, y_val)
history.append({
'epoch': epoch,
'train_accuracy': train_score,
'val_accuracy': val_score
})
# 早停机制(就像性能降级保护)
if len(history) > 10 and val_score < max([h['val_accuracy'] for h in history[-10:]]):
print("验证集性能不再提升,早停训练")
break
print(f"Epoch {epoch}: Train={train_score:.3f}, Val={val_score:.3f}")
return model, history模型评估指标
在机器学习项目中,选择合适的评估指标往往比优化算法更关键。不同的业务场景需要关注不同的指标,就像开发中选择合适的性能指标一样。
分类任务的指标策略:
对于不平衡数据场景(如欺诈检测、疾病筛查),准确率会产生误导。此时需要关注精确率和召回率的权衡:
- 高精确率优先:当误报代价高时(如推送营销信息给用户),宁可保守一些也要确保推送的用户确实有需求
- 高召回率优先:当漏报代价高时(如安全威胁检测),宁可多报警也不能遗漏真正的威胁
- F1分数:需要平衡两者时的折中选择
回归任务的指标选择:
- R²(决定系数) :衡量模型解释力,适合向业务方汇报"模型能解释多少数据变化"
- RMSE:对大误差敏感,适合对异常值敏感的场景(如金融预测)
- MAE:对异常值鲁棒,适合存在噪声数据的场景(如用户行为预测)
实际应用建议: 根据业务容错度选择指标。电商推荐系统可以容忍一定误推(用MAE),但自动驾驶系统必须对危险情况零容忍(用召回率)。记住:没有万能的指标,只有最适合业务场景的指标。
csharp
# 根据业务场景选择评估重点
def choose_metrics(business_scenario):
scenarios = {
"欺诈检测": {"primary": "recall", "reason": "不能漏掉真实欺诈"},
"内容推荐": {"primary": "precision", "reason": "避免推送无关内容"},
"价格预测": {"primary": "MAE", "reason": "关注平均预测偏差"},
"安全监控": {"primary": "recall", "reason": "不能遗漏安全威胁"}
}
return scenarios.get(business_scenario, {"primary": "accuracy"})实战项目案例
案例1:用户流失预测系统
业务场景: 电商平台希望识别可能流失的用户,提前进行挽留。
ini
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report
# 1. 数据准备
def prepare_user_data():
# 特征工程
features = [
'days_since_last_login', # 距离上次登录天数
'total_orders', # 总订单数
'avg_order_value', # 平均订单金额
'session_frequency', # 登录频率
'customer_service_contacts', # 客服联系次数
'app_crashes_experienced', # 遇到的APP崩溃次数
'promotion_engagement_rate' # 促销活动参与率
]
# 目标变量:30天内是否流失
target = 'will_churn_30days'
return features, target
# 2. 模型训练
def train_churn_model(df, features, target):
X = df[features]
y = df[target]
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
# 训练随机森林模型
model = RandomForestClassifier(
n_estimators=100,
max_depth=10,
random_state=42
)
model.fit(X_train, y_train)
# 评估模型
predictions = model.predict(X_test)
print(classification_report(y_test, predictions))
# 特征重要性分析
feature_importance = pd.DataFrame({
'feature': features,
'importance': model.feature_importances_
}).sort_values('importance', ascending=False)
print("特征重要性:")
print(feature_importance)
return model
# 3. 生产环境部署
class ChurnPredictionAPI:
def __init__(self, model):
self.model = model
def predict_churn_risk(self, user_id):
# 从数据库获取用户特征
user_features = self.get_user_features(user_id)
# 预测流失概率
churn_probability = self.model.predict_proba([user_features])[0][1]
# 根据概率分级
if churn_probability > 0.8:
risk_level = "高风险"
recommended_action = "立即发送挽留优惠券"
elif churn_probability > 0.5:
risk_level = "中风险"
recommended_action = "推送个性化内容"
else:
risk_level = "低风险"
recommended_action = "正常运营"
return {
'user_id': user_id,
'churn_probability': churn_probability,
'risk_level': risk_level,
'recommended_action': recommended_action
}
def get_user_features(self, user_id):
# 实际项目中从数据库查询
# 这里返回示例数据
return [7, 15, 299.5, 0.8, 2, 1, 0.6]
# 使用示例
# model = train_churn_model(user_data, features, target)
# api = ChurnPredictionAPI(model)
# result = api.predict_churn_risk("user_12345")案例2:智能内容推荐系统
业务场景: 新闻APP根据用户行为推荐个性化内容。
python
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
from sklearn.decomposition import PCA
class ContentRecommendationSystem:
def __init__(self):
self.tfidf_vectorizer = TfidfVectorizer(
max_features=5000,
stop_words='english',
ngram_range=(1, 2)
)
self.content_vectors = None
self.user_profiles = {}
def fit_content(self, articles):
"""训练内容向量化模型"""
# 文章内容向量化
content_texts = [article['title'] + ' ' + article['content'] for article in articles]
self.content_vectors = self.tfidf_vectorizer.fit_transform(content_texts)
# 降维以提高效率
pca = PCA(n_components=100)
self.content_vectors = pca.fit_transform(self.content_vectors.toarray())
return self
def update_user_profile(self, user_id, article_interactions):
"""更新用户画像"""
if user_id not in self.user_profiles:
self.user_profiles[user_id] = np.zeros(self.content_vectors.shape[1])
# 基于用户交互更新画像
for article_id, interaction_score in article_interactions.items():
if article_id < len(self.content_vectors):
# 正反馈增强兴趣,负反馈减弱兴趣
self.user_profiles[user_id] += self.content_vectors[article_id] * interaction_score
def recommend_articles(self, user_id, num_recommendations=10, exclude_seen=None):
"""为用户推荐文章"""
if user_id not in self.user_profiles:
# 新用户返回热门文章
return self.get_trending_articles(num_recommendations)
user_vector = self.user_profiles[user_id]
# 计算用户兴趣与所有文章的相似度
similarities = cosine_similarity([user_vector], self.content_vectors)[0]
# 排除已读文章
if exclude_seen:
for seen_id in exclude_seen:
if seen_id < len(similarities):
similarities[seen_id] = -1
# 获取推荐结果
recommended_indices = np.argsort(similarities)[::-1][:num_recommendations]
return [
{
'article_id': idx,
'similarity_score': similarities[idx],
'recommendation_reason': self.explain_recommendation(user_vector, self.content_vectors[idx])
}
for idx in recommended_indices if similarities[idx] > 0
]
def explain_recommendation(self, user_vector, article_vector):
"""解释推荐原因"""
# 找到最相似的特征维度
feature_similarity = user_vector * article_vector
top_features = np.argsort(feature_similarity)[::-1][:3]
return f"基于您的兴趣特征: {', '.join([f'特征{i}' for i in top_features])}"
def get_trending_articles(self, num_articles):
"""获取热门文章(冷启动用)"""
# 实际项目中从数据库查询
return [{'article_id': i, 'type': 'trending'} for i in range(num_articles)]
# 使用示例
recommender = ContentRecommendationSystem()
# 训练内容模型
articles = [
{'title': 'AI技术发展', 'content': '人工智能技术...'},
{'title': '前端开发指南', 'content': 'React Vue Angular...'},
# ... 更多文章
]
recommender.fit_content(articles)
# 更新用户画像
user_interactions = {
0: 1.0, # 点击
1: 2.0, # 收藏
2: -0.5 # 快速划过(负反馈)
}
recommender.update_user_profile('user_123', user_interactions)
# 生成推荐
recommendations = recommender.recommend_articles('user_123', num_recommendations=5)案例3:API性能预测系统
业务场景: 预测API接口在不同负载下的响应时间,用于容量规划。
python
import pandas as pd
import numpy as np
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
import joblib
class APIPerformancePredictor:
def __init__(self):
self.model = None
self.scaler = StandardScaler()
self.feature_names = [
'concurrent_users', # 并发用户数
'cpu_usage', # CPU使用率
'memory_usage', # 内存使用率
'db_connections', # 数据库连接数
'request_size_kb', # 请求大小
'hour_of_day', # 时间段
'day_of_week' # 星期几
]
def prepare_features(self, raw_data):
"""特征工程"""
features = pd.DataFrame()
# 基础特征
features['concurrent_users'] = raw_data['concurrent_users']
features['cpu_usage'] = raw_data['cpu_usage']
features['memory_usage'] = raw_data['memory_usage']
features['db_connections'] = raw_data['db_connections']
features['request_size_kb'] = raw_data['request_size_bytes'] / 1024
# 时间特征
timestamps = pd.to_datetime(raw_data['timestamp'])
features['hour_of_day'] = timestamps.dt.hour
features['day_of_week'] = timestamps.dt.dayofweek
# 交互特征
features['load_factor'] = features['concurrent_users'] * features['cpu_usage']
features['resource_pressure'] = features['cpu_usage'] + features['memory_usage']
return features
def train(self, training_data):
"""训练模型"""
# 准备特征和目标变量
X = self.prepare_features(training_data)
y = training_data['response_time_ms']
# 数据划分
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# 特征标准化
X_train_scaled = self.scaler.fit_transform(X_train)
X_test_scaled = self.scaler.transform(X_test)
# 训练梯度提升模型
self.model = GradientBoostingRegressor(
n_estimators=200,
learning_rate=0.1,
max_depth=6,
random_state=42
)
self.model.fit(X_train_scaled, y_train)
# 评估模型
train_score = self.model.score(X_train_scaled, y_train)
test_score = self.model.score(X_test_scaled, y_test)
print(f"训练集 R²: {train_score:.3f}")
print(f"测试集 R²: {test_score:.3f}")
# 特征重要性
feature_importance = pd.DataFrame({
'feature': X.columns,
'importance': self.model.feature_importances_
}).sort_values('importance', ascending=False)
print("特征重要性:")
print(feature_importance)
return self
def predict_performance(self, system_state):
"""预测API性能"""
# 准备特征
features = pd.DataFrame([system_state])
features_scaled = self.scaler.transform(features)
# 预测响应时间
predicted_time = self.model.predict(features_scaled)[0]
# 性能等级评估
if predicted_time < 100:
performance_level = "优秀"
color = "green"
elif predicted_time < 500:
performance_level = "良好"
color = "yellow"
else:
performance_level = "需要关注"
color = "red"
return {
'predicted_response_time_ms': predicted_time,
'performance_level': performance_level,
'color': color,
'recommendations': self.get_recommendations(system_state, predicted_time)
}
def get_recommendations(self, system_state, predicted_time):
"""根据预测结果给出优化建议"""
recommendations = []
if predicted_time > 500:
if system_state['cpu_usage'] > 0.8:
recommendations.append("CPU使用率过高,建议扩容或优化算法")
if system_state['memory_usage'] > 0.8:
recommendations.append("内存使用率过高,建议检查内存泄漏")
if system_state['db_connections'] > 80:
recommendations.append("数据库连接数过多,建议优化连接池配置")
return recommendations
def save_model(self, filepath):
"""保存模型"""
joblib.dump({
'model': self.model,
'scaler': self.scaler,
'feature_names': self.feature_names
}, filepath)
def load_model(self, filepath):
"""加载模型"""
loaded = joblib.load(filepath)
self.model = loaded['model']
self.scaler = loaded['scaler']
self.feature_names = loaded['feature_names']
return self
# 使用示例
predictor = APIPerformancePredictor()
# 训练模型(使用历史性能数据)
# predictor.train(historical_data)
# 实时预测
current_system_state = {
'concurrent_users': 150,
'cpu_usage': 0.75,
'memory_usage': 0.60,
'db_connections': 45,
'request_size_kb': 2.5,
'hour_of_day': 14,
'day_of_week': 1
}
prediction = predictor.predict_performance(current_system_state)
print(f"预测响应时间: {prediction['predicted_response_time_ms']:.0f}ms")
print(f"性能等级: {prediction['performance_level']}")生产环境部署考虑
模型服务化
python
from flask import Flask, request, jsonify
import joblib
import numpy as np
app = Flask(__name__)
# 加载训练好的模型
model = joblib.load('model.pkl')
scaler = joblib.load('scaler.pkl')
@app.route('/predict', methods=['POST'])
def predict():
try:
# 获取输入数据
data = request.get_json()
features = np.array(data['features']).reshape(1, -1)
# 数据预处理
features_scaled = scaler.transform(features)
# 模型预测
prediction = model.predict(features_scaled)[0]
probability = model.predict_proba(features_scaled)[0] if hasattr(model, 'predict_proba') else None
return jsonify({
'prediction': prediction,
'probability': probability.tolist() if probability is not None else None,
'status': 'success'
})
except Exception as e:
return jsonify({
'error': str(e),
'status': 'error'
}), 400
@app.route('/health', methods=['GET'])
def health_check():
return jsonify({'status': 'healthy'})
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)模型监控和更新
python
import time
import logging
from datetime import datetime, timedelta
class ModelMonitor:
def __init__(self, model, threshold_accuracy=0.85):
self.model = model
self.threshold_accuracy = threshold_accuracy
self.predictions = []
self.actual_results = []
def log_prediction(self, features, prediction, actual_result=None):
"""记录预测结果"""
self.predictions.append({
'timestamp': datetime.now(),
'features': features,
'prediction': prediction,
'actual_result': actual_result
})
def calculate_recent_accuracy(self, hours=24):
"""计算最近的准确率"""
cutoff_time = datetime.now() - timedelta(hours=hours)
recent_predictions = [
p for p in self.predictions
if p['timestamp'] > cutoff_time and p['actual_result'] is not None
]
if not recent_predictions:
return None
correct = sum(
1 for p in recent_predictions
if p['prediction'] == p['actual_result']
)
return correct / len(recent_predictions)
def check_model_drift(self):
"""检查模型漂移"""
recent_accuracy = self.calculate_recent_accuracy()
if recent_accuracy is not None and recent_accuracy < self.threshold_accuracy:
logging.warning(f"模型准确率下降到 {recent_accuracy:.2f},需要重新训练")
return True
return False
def should_retrain(self):
"""判断是否需要重新训练"""
return self.check_model_drift()常见坑点和解决方案
过拟合 vs 欠拟合
欠拟合:就像写了个过于简单的函数,只考虑一个变量预测房价。
javascript
function predictPrice(area) {
return area * 100; // 太简单,忽略了地段、装修等重要因素
}
// 结果:训练和测试都表现差过拟合:就像记住了每个训练样本的具体细节,包括噪声。
arduino
// 模型记住了"张三家120平米的房子卖250万"这种具体案例
// 结果:训练数据上完美,新数据上崩溃检测方法:
- 训练集准确率 > 95%,测试集 < 80% → 过拟合
- 训练集和测试集都 < 70% → 欠拟合
解决方案:
- 欠拟合:增加模型复杂度、添加特征
- 过拟合:增加数据、降低复杂度、添加正则化
类别不平衡:数据的"偏科"问题
就像用99%数学题和1%语文题训练学生,模型会"偏科"严重。
典型场景:垃圾邮件检测中,正常邮件9900封,垃圾邮件100封。
陷阱:模型可能学会"懒惰策略"------永远预测"正常邮件",准确率达99%,但完全没学会识别垃圾邮件。
实用解决方案:
ini
# 方案1:调整权重
model = RandomForestClassifier(class_weight='balanced')
# 方案2:数据重采样
from imblearn.over_sampling import SMOTE
X_balanced, y_balanced = SMOTE().fit_resample(X_train, y_train)
# 方案3:调整决策阈值
probabilities = model.predict_proba(X)[:, 1]
predictions = (probabilities >= 0.3).astype(int) # 降低阈值关键原则:
- 不要只看准确率,重点关注精确率、召回率
- 根据业务成本选择策略:宁可误报也不能漏报?还是相反?
记住:机器学习中的"公平"是让模型对每个类别都认真对待,而不是数量相等。
必备Python库
python
# 数据处理和分析
import pandas as pd # 数据操作的Excel
import numpy as np # 数值计算的基础
# 机器学习核心库
from sklearn import * # 机器学习的瑞士军刀
import xgboost as xgb # 竞赛神器
import lightgbm as lgb # 微软出品的快速梯度提升
# 深度学习
import torch # Facebook的深度学习框架
import tensorflow as tf # Google的深度学习框架
# 数据可视化
import matplotlib.pyplot as plt # 基础绘图
import seaborn as sns # 统计可视化
import plotly # 交互式图表
# 模型解释
import shap # 模型解释神器
from lime import lime_tabular # 局部解释
# 工程化工具
import joblib # 模型序列化
import mlflow # 实验管理
import dvc # 数据版本控制写在最后:从理论到实践的跃迁
通过这篇实战指南,我们从API调用深入到了算法理解,从简单应用走向了项目实战。机器学习不再是遥远的黑科技,而是解决实际问题的工具箱。
关键收获:
- 数据 思维:从代码逻辑思维转向数据驱动思维
- 问题抽象 :将业务问题抽象为分类、回归、聚类等标准问题(建模)
- 工程实践:掌握从数据处理到模型部署的完整流程
- 性能优化:像优化代码一样优化模型性能
下一步行动:
- 选择一个实际项目开始动手实践
- 加入ML社区(如Kaggle)参与竞赛学习
- 关注业务价值而不只是技术指标
- 建立数据意识在日常开发中思考ML的应用场景
记住:机器学习的核心不是算法,而是解决问题的思维方式 。当你开始用数据的眼光看待业务问题时,你就已经踏上了AI时代开发者的进化之路。
下期预告:《深度学习探索:神经网络的奥秘解析》
在下一篇中,我们将深入神经网络的世界,探索深度学习如何处理图像、文本等复杂数据,以及如何构建自己的深度学习应用。