第三篇 深度学习探索:神经网络的奥秘解析
从手工特征工程到自动特征学习,深度学习为什么能让AI"看懂"图片、"听懂"语音?让我们用开发者的视角揭开神经网络的神秘面纱。
深度学习的"代码革命"
还记得我们在第二篇中提到的特征工程吗?传统机器学习就像手写DOM操作,而深度学习(机器学习的一种)就像现代前端框架------他可以让机器自己学会提取特征。
从手工到自动:特征工程的进化
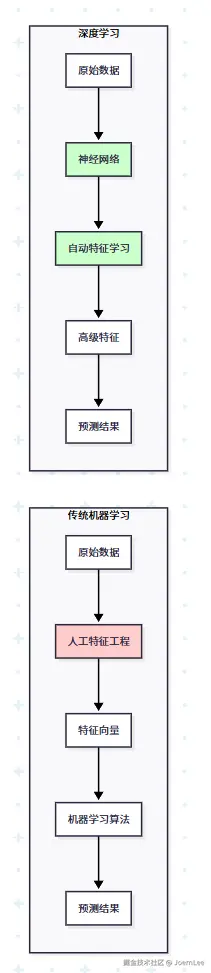
传统机器学习的痛点:
scss
# 传统方式:手工提取图像特征
def extract_image_features(image):
features = {}
# 需要人工设计大量特征
features['brightness'] = calculate_brightness(image)
features['edge_count'] = detect_edges(image)
features['color_histogram'] = get_color_distribution(image)
features['texture_pattern'] = analyze_texture(image)
features['shape_descriptor'] = extract_shapes(image)
# ... 需要专家知识设计几十个特征
return features
# 然后用这些特征训练传统模型
model = RandomForestClassifier()
model.fit(manual_features, labels)深度学习的突破:
python
# 深度学习方式:端到端自动学习
import torch
import torch.nn as nn
class ImageClassifier(nn.Module):
def __init__(self):
super().__init__()
# 神经网络自动学习特征
self.feature_extractor = nn.Sequential(
nn.Conv2d(3, 32, 3), # 自动学习边缘特征
nn.ReLU(),
nn.Conv2d(32, 64, 3), # 自动学习形状特征
nn.ReLU(),
nn.Conv2d(64, 128, 3), # 自动学习复杂特征
nn.ReLU()
)
self.classifier = nn.Linear(128, 10)
def forward(self, x):
# 直接从原始像素学习到最终分类
features = self.feature_extractor(x)
return self.classifier(features)
# 直接用原始图像数据训练
model = ImageClassifier()
# 模型自己学会:像素 → 边缘 → 形状 → 物体深度学习 = 自动化的特征工程师
ini
// 类比:前端开发的进化
// 原生JS时代(传统ML)
function updateUserList(users) {
const listElement = document.getElementById('user-list');
listElement.innerHTML = '';
users.forEach(user => {
const li = document.createElement('li');
li.textContent = user.name;
li.addEventListener('click', () => handleUserClick(user));
listElement.appendChild(li);
});
}
// React时代(深度学习)
function UserList({ users, onUserClick }) {
return (
<ul>
{users.map(user =>
<li key={user.id} onClick={() => onUserClick(user)}>
{user.name}
</li>
)}
</ul>
);
}深度学习就像React帮我们自动管理DOM一样,帮我们自动管理特征提取。
神经网络:代码世界的"大脑"
神经元:最小的计算单元
从上面的第一个图可以看到,一个神经元就像一个智能的计算函数:
python
def neuron(inputs, weights, bias):
"""
神经元的数学本质:加权求和 + 非线性激活
就像一个会"思考"的计算器
"""
# 步骤1:加权求和(每个输入都有不同的重要性)
weighted_sum = sum(input_val * weight for input_val, weight in zip(inputs, weights))
# 步骤2:加上偏置(调整触发阈值)
total_input = weighted_sum + bias
# 步骤3:激活函数(决定是否"激活")
output = activation_function(total_input)
return output
# 激活函数就像开关
def relu_activation(x):
return max(0, x) # 小于0就关闭,大于0就原样输出
def sigmoid_activation(x):
return 1 / (1 + math.exp(-x)) # 输出0-1之间的概率神经网络:智能计算的流水线
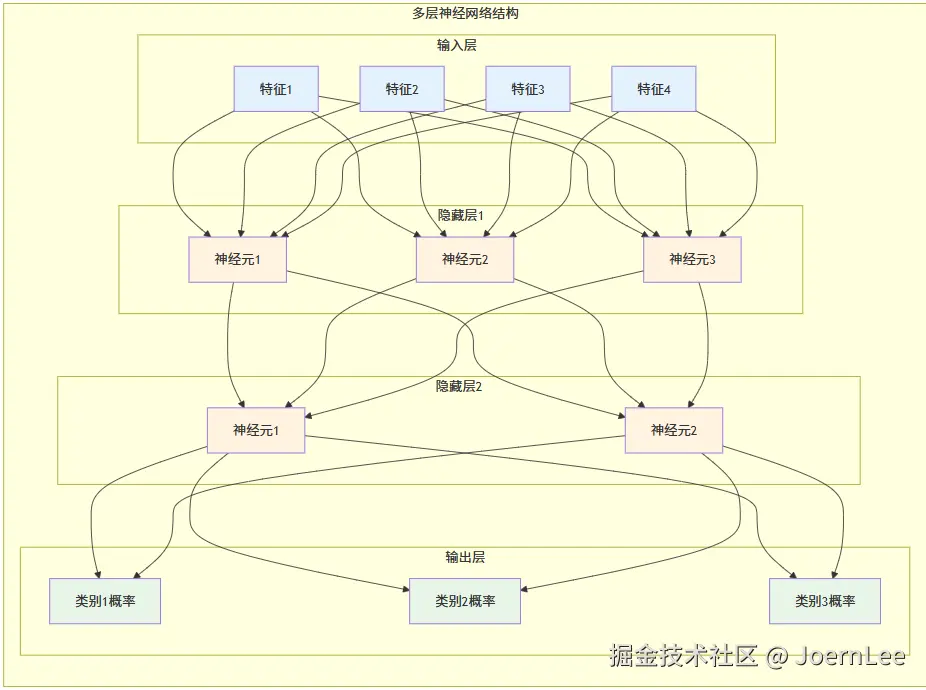
第二个图展示了神经网络的分层结构,每一层都在做不同的工作:
- 输入层:接收原始数据(像API的请求参数)
- 隐藏层:提取和处理特征(像业务逻辑层)
- 输出层:生成最终结果(像API的响应)
python
# 数据在网络中的旅程
class NeuralNetworkJourney:
def track_data_flow(self, input_data):
print(f"📥 输入层接收: {input_data}")
# 第一层:基础特征检测
layer1_output = self.layer1(input_data)
print(f"🔍 隐藏层1提取: 边缘、颜色等基础特征")
# 第二层:复杂特征组合
layer2_output = self.layer2(layer1_output)
print(f"🧩 隐藏层2组合: 形状、纹理等复杂特征")
# 输出层:最终决策
final_output = self.output_layer(layer2_output)
print(f"🎯 输出层判断: 这是一只猫 (置信度: 87%)")
return final_output学习过程:错误中的智慧
第三个图展示了神经网络如何通过"犯错误"来学习,这个过程叫反向传播:
ini
# 学习过程就像不断改进的程序员
def learning_process():
for epoch in range(1000): # 重复学习1000次
# 前向传播:做预测
prediction = neural_network.predict(input_data)
# 计算错误:对比正确答案
error = calculate_loss(prediction, correct_answer)
# 反向传播:调整参数
# 就像debug后修改代码
neural_network.adjust_weights(error)
if epoch % 100 == 0:
print(f"第{epoch}轮学习,错误率: {error:.3f}")类比理解- 神经网络的学习就像一个新手程序员:
- 刚开始写的代码错误百出(随机权重)
- 通过不断调试修改代码(反向传播)
- 最终写出正确的程序(训练完成的模型)
这样结合图表和代码,应该更容易理解神经网络的工作原理了把
深度学习的三大"专业选手"
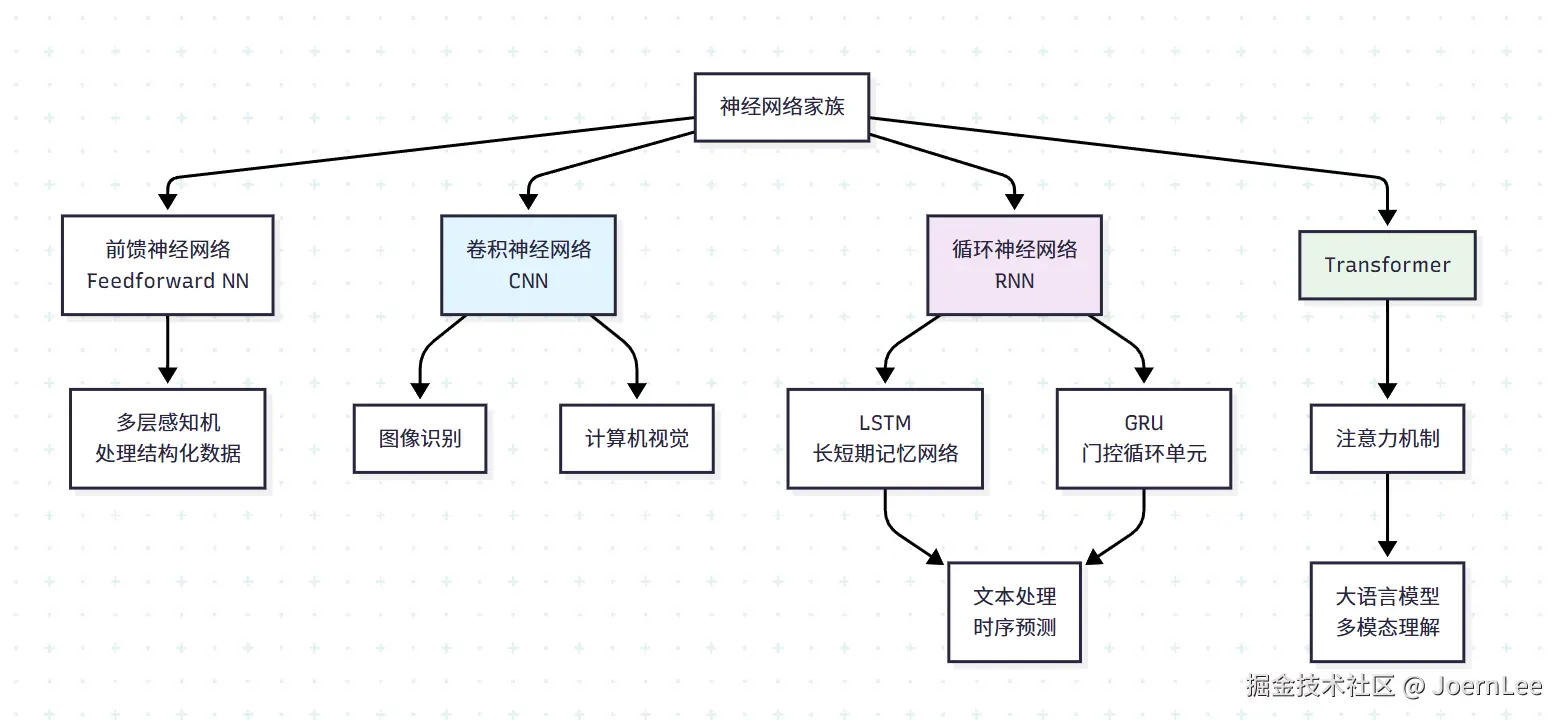
CNN:图像处理的"视觉专家"
核心理念: 模仿人类视觉系统,从局部到整体逐步识别图像
CNN就像一个专业的图像分析师,它不会一下子看整张图片,而是先关注局部细节(边缘、纹理),然后逐步组合成复杂的图案,最终识别出完整的物体。
scss
# CNN的核心思想:卷积 + 池化 + 全连接
import torch.nn as nn
class SimpleCNN(nn.Module):
def __init__(self):
super().__init__()
# 卷积层:提取图像特征(像放大镜看细节)
self.conv_layers = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=3), # 32个"特征检测器"
nn.ReLU(), # 激活函数
nn.MaxPool2d(2, 2), # 池化:压缩信息
nn.Conv2d(32, 64, kernel_size=3), # 检测更复杂的特征
nn.ReLU(),
nn.MaxPool2d(2, 2)
)
# 全连接层:做最终决策(像大脑综合判断)
self.classifier = nn.Sequential(
nn.Linear(64 * 6 * 6, 128),
nn.ReLU(),
nn.Linear(128, 10) # 10个类别
)工作流程: 输入照片 → 检测边缘 → 识别形状 → 组合特征 → 输出"这是一只猫"
擅长场景: 图像分类、人脸识别、医疗影像诊断、自动驾驶中的物体检测
RNN/LSTM:序列处理的"记忆大师"
核心理念: 拥有"记忆"的神经网络,能处理有时间顺序的数据
RNN就像一个有记忆的翻译官,它能记住前面的内容来理解当前的语境。但普通RNN记忆力有限,LSTM则像升级版,拥有选择性记忆能力。
ruby
class SimpleLSTM(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim):
super().__init__()
# 词嵌入:把单词转换成数字向量
self.embedding = nn.Embedding(vocab_size, embedding_dim)
# LSTM:核心的记忆单元
self.lstm = nn.LSTM(embedding_dim, hidden_dim, batch_first=True)
# 输出层:基于记忆做预测
self.output = nn.Linear(hidden_dim, vocab_size)
def forward(self, x):
# 处理序列数据的步骤
embedded = self.embedding(x) # 单词 → 向量
lstm_out, (h, c) = self.lstm(embedded) # 序列处理 + 记忆更新
return self.output(lstm_out) # 预测下一个词记忆机制: LSTM有三个"门"来控制记忆:
- 遗忘门: 决定忘记什么旧信息("这个主语已经过时了")
- 输入门: 决定记住什么新信息("这个新主语很重要")
- 输出门: 决定输出什么信息("现在该说动词了")
擅长场景: 机器翻译、语音识别、股价预测、聊天机器人的上下文理解
Transformer:注意力机制的"全能选手"
核心理念: 抛弃循序处理,用"注意力"机制同时关注所有重要信息
Transformer就像一个能同时处理多线程的超级大脑,它不需要按顺序读取信息,而是能同时"注意"到句子中所有重要的词汇和它们的关系。
ini
class SimpleTransformer(nn.Module):
def __init__(self, vocab_size, d_model, nhead, num_layers):
super().__init__()
# 词嵌入 + 位置编码
self.embedding = nn.Embedding(vocab_size, d_model)
self.pos_encoding = PositionalEncoding(d_model)
# 多头注意力机制:核心创新
encoder_layer = nn.TransformerEncoderLayer(
d_model=d_model,
nhead=nhead, # 多个"注意力头"
batch_first=True
)
self.transformer = nn.TransformerEncoder(encoder_layer, num_layers)
self.output = nn.Linear(d_model, vocab_size)注意力机制的魔力:
makefile
# 注意力就像这样工作:
sentence = "The cat sat on the mat"
# 当处理"sat"时,注意力会自动关注:
attention_weights = {
"The": 0.1, # 不太重要
"cat": 0.8, # 很重要!谁在坐?
"sat": 0.2, # 当前词
"on": 0.4, # 重要!动作的方向
"the": 0.1, # 不太重要
"mat": 0.7 # 很重要!坐在哪里?
}并行处理优势: 不像RNN需要等前一个词处理完,Transformer能同时处理整个句子,速度快得多。
擅长场景: 大语言模型(GPT、ChatGPT)、机器翻译、文档理解、代码生成
三大选手对比总结
| 特性 | CNN | RNN/LSTM | Transformer |
|---|---|---|---|
| 最擅长 | 空间模式识别 | 时序模式记忆 | 复杂关系理解 |
| 处理方式 | 局部到整体 | 序列化处理 | 并行处理 |
| 核心优势 | 空间不变性 | 长期记忆 | 注意力机制 |
| 典型应用 | 图像识别 | 语音/文本序列 | 大语言模型 |
| 训练速度 | 快 | 慢(串行) | 快(并行) |
现代趋势: 越来越多的应用开始融合这三种架构,比如多模态大模型就同时用到了CNN(处理图像)和Transformer(理解文本和图像关系)。
你说得非常对!确实,"学习路径"在第一篇已经有了整体规划,第三篇重复确实有些冗余。"深度学习工具与流程"对开发者来说更实用,更符合这篇文章的定位。
让我重新设计这个章节:
深度学习工具与流程
主流深度学习框架对比
PyTorch:开发者友好的"JavaScript"
ini
# PyTorch的优势:动态图,调试友好
import torch
import torch.nn as nn
# 就像写普通Python代码一样直观
x = torch.randn(1, 3, 224, 224)
model = nn.Sequential(
nn.Conv2d(3, 64, 3),
nn.ReLU(),
nn.AdaptiveAvgPool2d(1)
)
output = model(x) # 可以随时print调试TensorFlow/Keras:生产级的"Java"
python
# TensorFlow的优势:生产部署成熟
import tensorflow as tf
# 更适合大规模部署
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(64, 3, activation='relu'),
tf.keras.layers.GlobalAveragePooling2D(),
tf.keras.layers.Dense(10, activation='softmax')
])
# 一键导出为生产格式
model.save('my_model.savedmodel')深度学习项目标准流程
阶段1:环境准备 (30分钟)
ini
# 创建独立环境(像Node.js的项目初始化)
conda create -n dl_project python=3.9
conda activate dl_project
# 安装依赖(像npm install)
pip install torch torchvision jupyter matplotlib
pip install tensorboard # 可视化训练过程阶段2:数据准备 (1-2天)
ini
# 数据加载和预处理(像前端的数据格式化)
from torch.utils.data import DataLoader
from torchvision import transforms
# 数据增强:增加数据多样性
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.RandomHorizontalFlip(), # 随机翻转
transforms.RandomRotation(10), # 随机旋转
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
train_loader = DataLoader(dataset, batch_size=32, shuffle=True)阶段3:模型开发 (2-3天)
ruby
# 模型定义(像写API接口)
class MyModel(nn.Module):
def __init__(self):
super().__init__()
# 使用预训练模型(像使用成熟的库)
self.backbone = torchvision.models.resnet50(pretrained=True)
self.backbone.fc = nn.Linear(2048, num_classes)
def forward(self, x):
return self.backbone(x)
# 训练配置(像webpack配置)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=10)阶段4:训练监控 (1-2天)
scss
# 训练循环(像启动开发服务器)
for epoch in range(num_epochs):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
# 监控训练状态(像console.log调试)
if batch_idx % 100 == 0:
print(f'Epoch: {epoch}, Loss: {loss.item():.4f}')
# 验证性能(像单元测试)
validate(model, val_loader)必备开发工具推荐
开发环境:
- Jupyter Notebook:快速原型开发(像CodePen)
- PyCharm:完整项目开发
- Google Colab:免费GPU资源(像在线IDE)
可视化工具:
- TensorBoard:训练过程可视化(像Chrome DevTools)
- Weights & Biases:实验管理(像Git管理代码)
- Matplotlib/Plotly:数据可视化
模型部署:
bash
# 模型转换为生产格式
torch.jit.save(torch.jit.script(model), 'model.pt')
# 或者转换为ONNX(跨平台格式)
torch.onnx.export(model, dummy_input, 'model.onnx')云平台服务:
- AWS SageMaker:一站式ML平台
- Google AI Platform:Google的ML服务
- Azure ML:微软的ML平台
从原型到生产的完整Pipeline
ini
# 开发阶段:快速验证想法
def prototype_pipeline():
# 小数据集 + 简单模型 + 快速迭代
model = SimpleModel()
train_on_sample_data(model)
# 优化阶段:提升性能
def optimization_pipeline():
# 数据增强 + 模型调优 + 超参数搜索
model = AdvancedModel()
hyperparameter_search(model)
# 生产阶段:稳定部署
def production_pipeline():
# 模型压缩 + 服务化 + 监控
optimized_model = quantize_model(best_model)
deploy_as_api(optimized_model)深度学习实战项目
项目1:智能代码审查助手
python
import torch
import transformers
from transformers import AutoTokenizer, AutoModel
class CodeReviewAssistant:
def __init__(self):
# 使用预训练的代码理解模型
self.tokenizer = AutoTokenizer.from_pretrained('microsoft/codebert-base')
self.model = AutoModel.from_pretrained('microsoft/codebert-base')
# 常见代码问题模式
self.issue_patterns = {
'security': ['sql注入', '未转义输入', '硬编码密码'],
'performance': ['循环嵌套过深', '未使用索引', '内存泄漏'],
'maintainability': ['函数过长', '重复代码', '魔法数字']
}
def analyze_code(self, code_snippet):
"""分析代码质量和潜在问题"""
# 步骤1:代码语义理解
inputs = self.tokenizer(code_snippet, return_tensors='pt', truncation=True)
outputs = self.model(**inputs)
# 步骤2:问题检测
issues = self.detect_issues(code_snippet, outputs)
# 步骤3:生成建议
suggestions = self.generate_suggestions(issues)
return {
'code_quality_score': self.calculate_quality_score(outputs),
'detected_issues': issues,
'suggestions': suggestions,
'complexity_analysis': self.analyze_complexity(code_snippet)
}
def detect_issues(self, code, embeddings):
"""检测代码中的问题"""
issues = []
# 安全性检查
if 'SELECT * FROM' in code and 'WHERE' not in code:
issues.append({
'type': 'security',
'severity': 'high',
'message': '可能存在SQL注入风险',
'line': self.find_line_number(code, 'SELECT')
})
# 性能检查
if code.count('for') > 2 and 'break' not in code:
issues.append({
'type': 'performance',
'severity': 'medium',
'message': '嵌套循环可能影响性能',
'suggestion': '考虑使用更高效的算法'
})
return issues
def generate_suggestions(self, issues):
"""基于问题生成改进建议"""
suggestions = []
for issue in issues:
if issue['type'] == 'security':
suggestions.append({
'title': '安全性改进',
'description': '使用参数化查询防止SQL注入',
'example_code': 'cursor.execute("SELECT * FROM users WHERE id = ?", (user_id,))'
})
elif issue['type'] == 'performance':
suggestions.append({
'title': '性能优化',
'description': '考虑使用数据结构优化算法复杂度',
'example_code': '# 使用字典代替嵌套循环查找\nuser_dict = {user.id: user for user in users}'
})
return suggestions
# 使用示例
reviewer = CodeReviewAssistant()
code = """
def get_user_orders(user_id):
query = f"SELECT * FROM orders WHERE user_id = {user_id}"
cursor.execute(query)
return cursor.fetchall()
"""
analysis = reviewer.analyze_code(code)
print(f"代码质量评分: {analysis['code_quality_score']}")
for issue in analysis['detected_issues']:
print(f"⚠️ {issue['message']} (严重程度: {issue['severity']})")项目2:智能用户反馈分析系统
python
class UserFeedbackAnalyzer:
def __init__(self):
# 多任务学习:同时处理情感、意图、紧急程度
self.sentiment_model = self.load_sentiment_model()
self.intent_classifier = self.load_intent_model()
self.urgency_detector = self.load_urgency_model()
def analyze_feedback_batch(self, feedbacks):
"""批量分析用户反馈"""
results = []
for feedback in feedbacks:
analysis = {
'original_text': feedback['text'],
'timestamp': feedback['timestamp'],
'user_id': feedback['user_id'],
# 情感分析
'sentiment': self.analyze_sentiment(feedback['text']),
# 意图识别
'intent': self.classify_intent(feedback['text']),
# 紧急程度评估
'urgency': self.assess_urgency(feedback['text']),
# 关键词提取
'keywords': self.extract_keywords(feedback['text']),
# 自动回复建议
'auto_response': self.suggest_response(feedback['text'])
}
results.append(analysis)
return self.generate_summary_report(results)
def classify_intent(self, text):
"""识别用户意图"""
intents = {
'bug_report': ['错误', '崩溃', '无法使用', '问题'],
'feature_request': ['希望', '建议', '功能', '新增'],
'complaint': ['不满', '糟糕', '差劲', '投诉'],
'praise': ['很好', '棒', '满意', '赞'],
'question': ['如何', '怎么', '为什么', '什么']
}
# 实际项目中使用训练好的分类器
intent_scores = self.intent_classifier.predict(text)
return {
'primary_intent': intent_scores.argmax(),
'confidence': intent_scores.max(),
'all_scores': intent_scores.tolist()
}
def suggest_response(self, text):
"""基于分析结果建议回复"""
sentiment = self.analyze_sentiment(text)
intent = self.classify_intent(text)
response_templates = {
('negative', 'bug_report'): "非常抱歉您遇到的问题,我们技术团队会优先处理...",
('positive', 'praise'): "感谢您的认可,我们会继续努力提供更好的服务...",
('neutral', 'question'): "关于您的问题,我来为您详细解答...",
('negative', 'complaint'): "我们深表歉意,会立即调查并改进..."
}
key = (sentiment['label'], intent['primary_intent'])
template = response_templates.get(key, "感谢您的反馈,我们会认真处理...")
return {
'suggested_response': template,
'response_type': 'auto_generated',
'requires_human_review': sentiment['label'] == 'negative' and intent['primary_intent'] == 'complaint'
}
def generate_summary_report(self, analyses):
"""生成分析汇总报告"""
total_count = len(analyses)
# 情感分布统计
sentiment_stats = {}
intent_stats = {}
urgency_stats = {}
for analysis in analyses:
# 统计各项指标分布
sentiment = analysis['sentiment']['label']
sentiment_stats[sentiment] = sentiment_stats.get(sentiment, 0) + 1
intent = analysis['intent']['primary_intent']
intent_stats[intent] = intent_stats.get(intent, 0) + 1
urgency = analysis['urgency']['level']
urgency_stats[urgency] = urgency_stats.get(urgency, 0) + 1
return {
'summary': {
'total_feedback_count': total_count,
'sentiment_distribution': sentiment_stats,
'intent_distribution': intent_stats,
'urgency_distribution': urgency_stats
},
'insights': self.generate_insights(analyses),
'action_items': self.generate_action_items(analyses),
'detailed_analyses': analyses
}
def generate_insights(self, analyses):
"""生成业务洞察"""
insights = []
# 识别主要问题模式
negative_feedbacks = [a for a in analyses if a['sentiment']['label'] == 'negative']
if len(negative_feedbacks) > len(analyses) * 0.3:
insights.append({
'type': 'warning',
'message': f'负面反馈占比{len(negative_feedbacks)/len(analyses):.1%},需要重点关注',
'impact': 'high'
})
# 发现热点话题
all_keywords = []
for analysis in analyses:
all_keywords.extend(analysis['keywords'])
keyword_freq = {}
for keyword in all_keywords:
keyword_freq[keyword] = keyword_freq.get(keyword, 0) + 1
hot_topics = sorted(keyword_freq.items(), key=lambda x: x[1], reverse=True)[:5]
insights.append({
'type': 'trend',
'message': f'用户最关注的话题:{", ".join([topic[0] for topic in hot_topics])}',
'details': hot_topics
})
return insights
# 使用示例
analyzer = UserFeedbackAnalyzer()
sample_feedbacks = [
{'text': '应用经常崩溃,影响工作效率', 'timestamp': '2024-01-01', 'user_id': 'user001'},
{'text': '新功能很好用,界面也很美观', 'timestamp': '2024-01-01', 'user_id': 'user002'},
{'text': '希望能增加夜间模式', 'timestamp': '2024-01-01', 'user_id': 'user003'}
]
report = analyzer.analyze_feedback_batch(sample_feedbacks)
print("=== 用户反馈分析报告 ===")
print(f"总反馈数: {report['summary']['total_feedback_count']}")
print(f"情感分布: {report['summary']['sentiment_distribution']}")
for insight in report['insights']:
print(f"💡 洞察: {insight['message']}")写在最后:深度学习的开发者思维
深度学习看似神秘,但本质上是一种自动化的特征工程工具。就像我们从手写DOM操作进化到现代前端框架一样,深度学习让我们从手工设计特征进化到自动学习特征。
关键收获:
- 深度学习 = 自动特征工程:让机器自己学会提取有用信息
- 神经网络 = 复杂函数组合:通过多层转换逐步抽象数据
- 不同架构处理不同问题:CNN处理图像,RNN处理序列,Transformer处理注意力
- 端到端学习:从原始数据直接学到最终结果
实践建议:
- 从API开始:先学会调用,再理解原理
- 项目驱动:选择具体问题,边做边学
- 工程思维:把深度学习当作工具,专注解决业务问题
- 持续迭代:模型像代码一样需要版本管理和持续优化
记住:深度学习不是魔法,而是一套强大的模式识别工具。掌握了它,你就能让程序"看懂"图像、"听懂"语音、"理解"文本,为用户创造更智能的体验。
下期预告:《大模型时代:站在巨人肩膀上的学习革命》
在最后一篇中,我们将探索大模型如何改变整个AI应用开发范式,以及如何构建基于大模型的智能应用系统。
好的!我来按照我们讨论的框架写第四篇文章。
第四篇 大模型时代:开发者的AI应用新范式
从GPT-3到ChatGPT,从编程助手到智能应用,大模型不仅改变了AI的能力边界,更重新定义了软件开发的方式。作为开发者,我们如何理解这场革命,又该如何拥抱这个新时代?
大模型核心技术揭秘:为什么突然"智能涌现"了?
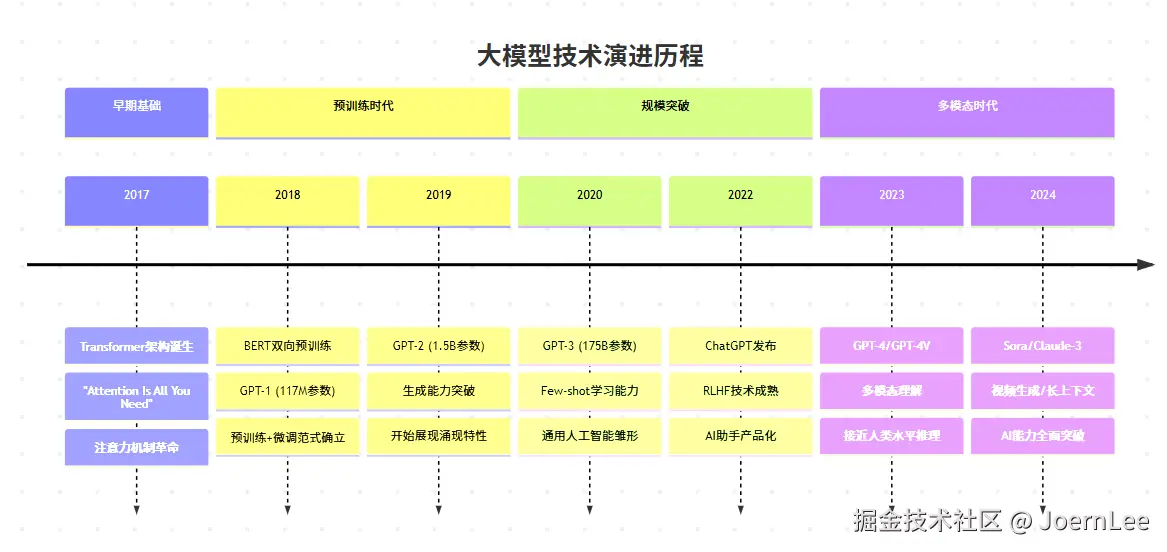
Transformer:改变游戏规则的架构革命
还记得我们在第三篇中提到的RNN需要串行处理序列数据吗?Transformer的出现彻底改变了这一切。
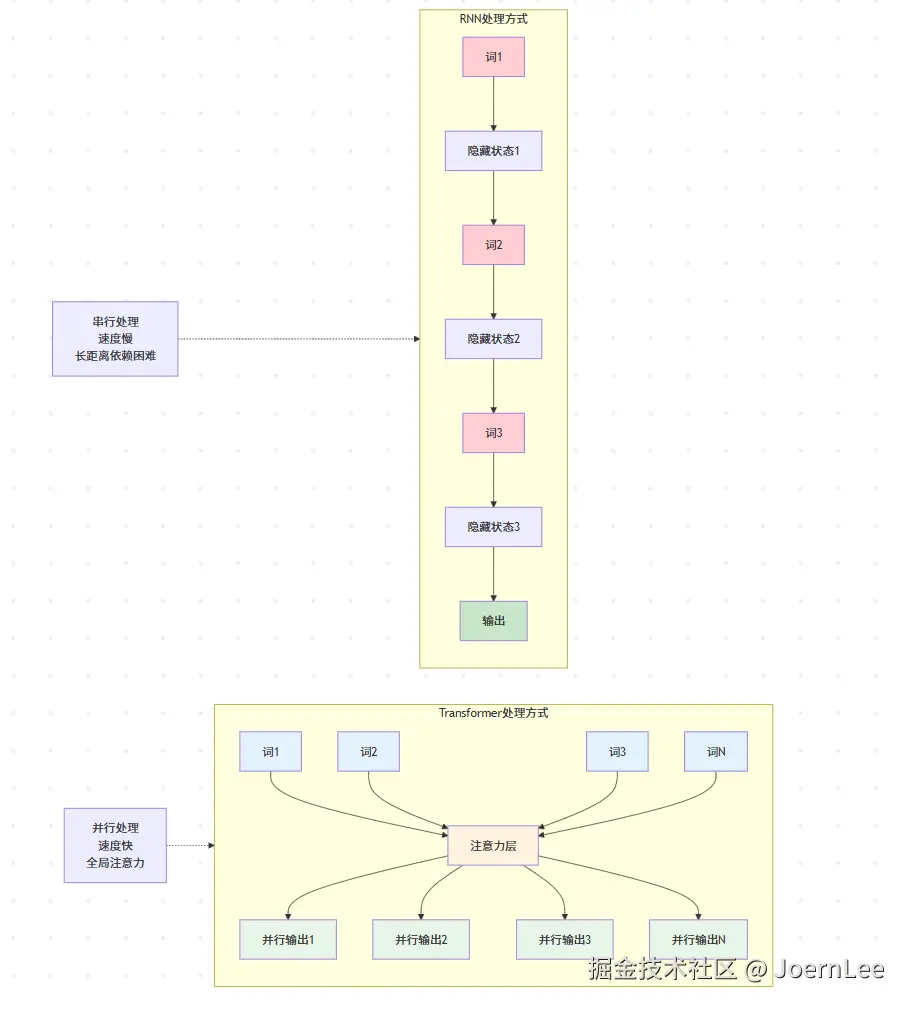
ini
# RNN的痛点:必须按顺序处理
def rnn_process_sentence(sentence):
hidden_state = initial_state
for word in sentence:
hidden_state = rnn_cell(word, hidden_state) # 必须等前一个词处理完
return hidden_state
# Transformer的突破:并行处理
def transformer_process_sentence(sentence):
# 所有词同时处理,通过注意力机制建立关系
attention_weights = calculate_attention(sentence) # 并行计算
return parallel_transform(sentence, attention_weights)注意力机制的魔力:
scss
// 类比:前端事件处理的进化
// 旧方式:串行处理事件
function handleEventsSequentially(events) {
for (let event of events) {
processEvent(event); // 必须等上一个处理完
}
}
// 新方式:并行处理 + 智能关联
function handleEventsWithAttention(events) {
const relationships = calculateEventRelationships(events); // 分析事件关系
return Promise.all(events.map(event =>
processEvent(event, relationships) // 并行处理,但考虑关联
));
}预训练革命:从"定制开发"到"基础平台"
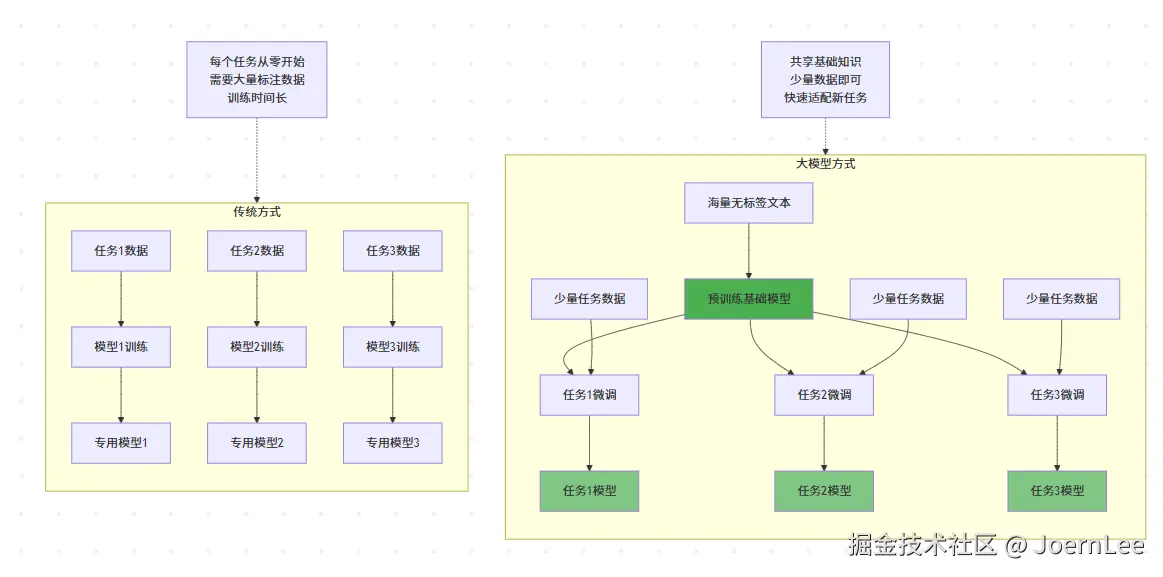
这就像从为每个项目单独搭建基础设施,转向使用云平台 + 微服务的模式。
规模效应:量变引起质变
参数规模的指数级增长:
scss
GPT-1 (2018): 1.17亿参数 → 能完成简单文本生成
GPT-2 (2019): 15亿参数 → 能写连贯的段落
GPT-3 (2020): 1750亿参数 → 能进行复杂推理
GPT-4 (2023): ~1万亿参数 → 能处理多模态任务涌现能力的神奇现象:
python
# 当模型规模达到临界点时,突然"学会"了新能力
class ModelCapabilities:
def __init__(self, parameter_count):
self.params = parameter_count
def emergent_abilities(self):
abilities = ["基础文本生成"]
if self.params > 1e9: # 10亿参数
abilities.append("逻辑推理")
if self.params > 1e11: # 1000亿参数
abilities.append("代码编写")
abilities.append("数学计算")
if self.params > 1e12: # 1万亿参数
abilities.append("多模态理解")
abilities.append("复杂规划")
abilities.append("创意写作")
return abilities
# 这种现象类似软件开发中的"复杂度临界点"
def system_complexity_effects(codebase_size):
if codebase_size < 1000:
return "简单脚本"
elif codebase_size < 100000:
return "小型应用,架构简单"
elif codebase_size < 1000000:
return "中型系统,需要架构设计"
else:
return "大型系统,需要微服务、分布式等复杂架构"多模态融合:从单一到全能
python
# 传统方式:各种模态分别处理
class TraditionalMultiModal:
def __init__(self):
self.text_model = BertModel()
self.image_model = ResNetModel()
self.audio_model = WaveNetModel()
def process_content(self, text=None, image=None, audio=None):
results = {}
if text:
results['text'] = self.text_model.process(text)
if image:
results['image'] = self.image_model.process(image)
if audio:
results['audio'] = self.audio_model.process(audio)
return results
# 大模型方式:统一处理多模态
class UnifiedMultiModal:
def __init__(self):
self.unified_model = GPT4VisionModel()
def process_content(self, inputs):
# 一个模型理解所有模态的内容和关系
return self.unified_model.understand(inputs)
def example_usage(self):
# 能理解图片+文字的组合含义
result = self.process_content({
"image": "screenshot.png",
"text": "这个界面有什么问题?",
"context": "这是我们的登录页面"
})
return result # 输出:综合分析界面设计问题为什么模型突然"聪明"了,称之为大模型了 ?
- 并行计算能力:Transformer让训练效率提升数十倍
- 数据规模:互联网文本数据的爆炸式增长
- 计算资源:GPU集群和云计算的成熟
- 算法优化:注意力机制、残差连接等关键技术突破
大模型如何重新定义软件开发?
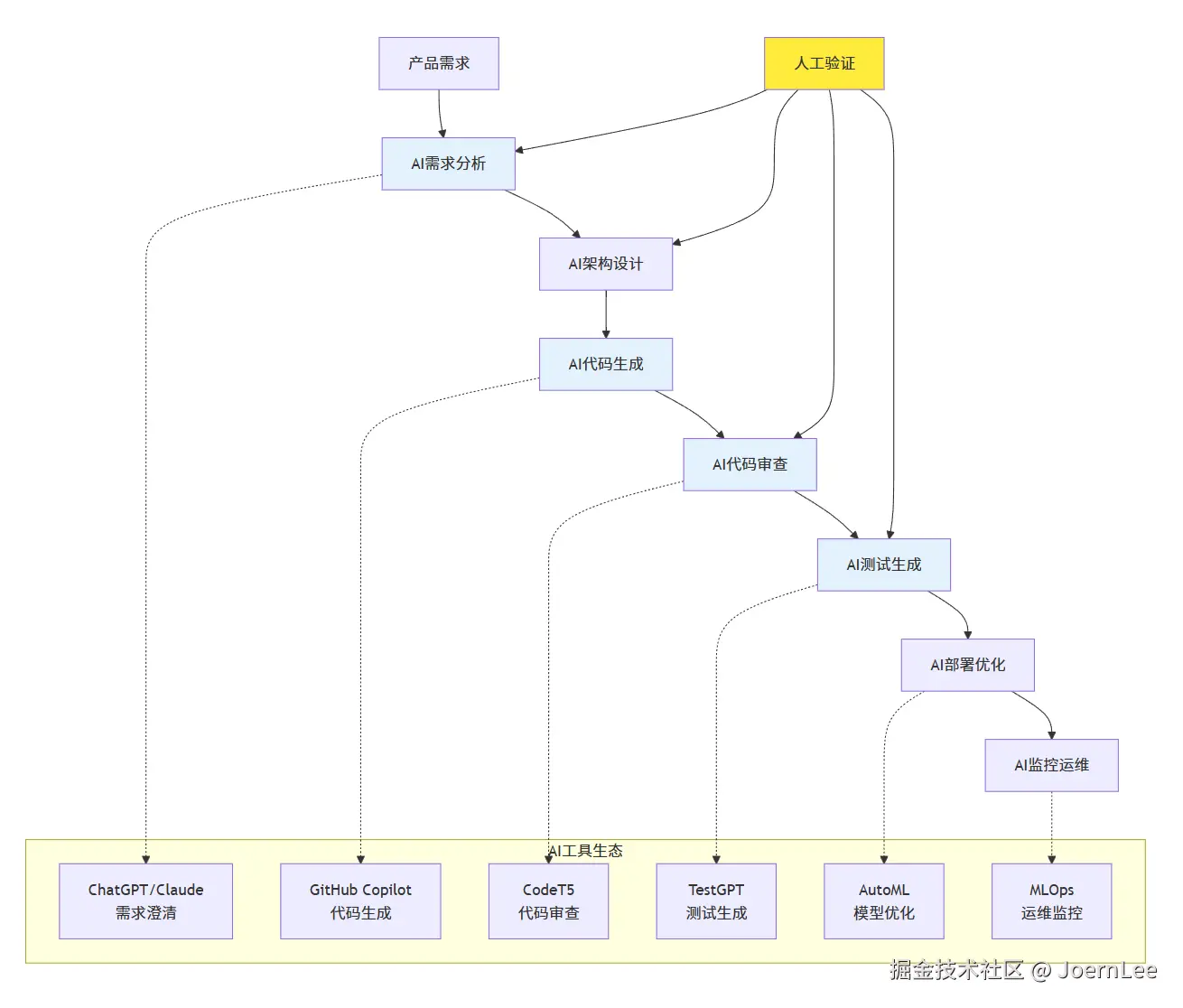
从"编写代码"到"描述需求"
ini
// 传统开发流程
function traditionalDevelopment() {
const requirements = analyzeRequirements();
const architecture = designArchitecture(requirements);
const code = writeCode(architecture);
const tests = writeTests(code);
return deployApp(code, tests);
}
// AI辅助开发流程
function aiAssistedDevelopment() {
const requirements = describeInNaturalLanguage();
const code = generateCodeFromDescription(requirements);
const optimizedCode = refactorWithAI(code);
const tests = generateTests(optimizedCode);
const bugs = findBugsWithAI(optimizedCode);
return deployApp(optimizedCode, tests);
}开发生命周期的AI增强
需求分析阶段:
python
# AI助手帮助澄清和完善需求
class RequirementsAI:
def analyze_user_story(self, user_story):
"""
输入:用户故事
输出:详细需求分析 + 潜在问题识别
"""
prompt = f"""
分析以下用户故事,指出:
1. 核心功能需求
2. 非功能性需求
3. 潜在的边界情况
4. 可能的技术挑战
用户故事:{user_story}
"""
return self.llm.generate(prompt)
# 使用示例
ai_analyst = RequirementsAI()
analysis = ai_analyst.analyze_user_story(
"作为一个用户,我希望能够快速搜索商品,以便找到我想要的产品"
)架构设计阶段:
python
class ArchitectureAI:
def suggest_architecture(self, requirements, constraints):
"""AI推荐技术架构"""
prompt = f"""
基于以下需求和约束条件,推荐合适的技术架构:
需求:{requirements}
约束:{constraints}
请提供:
1. 推荐的技术栈
2. 系统架构图描述
3. 关键技术选型理由
4. 潜在风险和解决方案
"""
return self.llm.generate(prompt)编码阶段:
python
class CodingAI:
def generate_code(self, specification):
"""根据规格说明生成代码"""
return f"""
// AI生成的代码示例
class UserSearchService {{
constructor(searchEngine, productRepository) {{
this.searchEngine = searchEngine;
this.productRepository = productRepository;
}}
async searchProducts(query, filters = {{}}) {{
// 搜索逻辑实现
const searchResults = await this.searchEngine.search(query);
const filteredResults = this.applyFilters(searchResults, filters);
return this.formatResults(filteredResults);
}}
}}
"""
def review_code(self, code):
"""AI代码审查"""
prompt = f"""
审查以下代码,检查:
1. 潜在的bug
2. 性能问题
3. 安全漏洞
4. 代码规范
5. 改进建议
代码:{code}
"""
return self.llm.generate(prompt)AI驱动的新开发模式
测试驱动开发 → AI辅助测试生成
python
# 传统TDD
def test_user_registration():
# 手动编写所有测试用例
assert register_user("valid@email.com", "password123") == True
assert register_user("invalid-email", "password123") == False
# ... 需要想到所有边界情况
# AI增强TDD
def ai_generate_tests(function_signature, requirements):
prompt = f"""
为以下函数生成全面的测试用例:
函数签名:{function_signature}
需求:{requirements}
包括:正常用例、边界情况、异常情况、安全测试
"""
return ai_model.generate(prompt)
# 自动生成全面的测试套件
test_suite = ai_generate_tests(
"register_user(email: str, password: str) -> bool",
"用户注册功能,需要验证邮箱格式和密码强度"
)提示工程:开发者的新核心技能
提示工程的技术原理
python
# 提示工程就像设计API接口
class PromptEngineering:
def __init__(self):
self.llm = LanguageModel()
def basic_prompt(self, task):
"""基础提示:直接描述任务"""
return f"请帮我{task}"
def structured_prompt(self, task, context, format_requirements):
"""结构化提示:提供上下文和格式要求"""
return f"""
任务:{task}
上下文:{context}
输出格式:{format_requirements}
请按照要求完成任务。
"""
def few_shot_prompt(self, task, examples):
"""少样本提示:提供示例"""
examples_text = "\n".join([
f"输入:{ex['input']}\n输出:{ex['output']}"
for ex in examples
])
return f"""
任务:{task}
示例:
{examples_text}
现在请处理新的输入:
"""
def chain_of_thought_prompt(self, problem):
"""思维链提示:引导逐步推理"""
return f"""
问题:{problem}
请按以下步骤分析:
1. 理解问题的核心
2. 识别需要考虑的因素
3. 逐步推理分析
4. 得出结论
让我们一步步思考:
"""代码生成的高级提示技巧
python
class CodeGenerationPrompts:
def generate_function_with_context(self, function_description,
existing_code, requirements):
"""为特定上下文生成函数"""
prompt = f"""
现有代码上下文:
```python
{existing_code}
```
需求:{requirements}
请实现函数:{function_description}
要求:
1. 与现有代码风格保持一致
2. 使用适当的错误处理
3. 添加必要的类型注解
4. 包含docstring文档
5. 考虑性能和安全性
生成的代码:
"""
return prompt
def debug_with_ai(self, buggy_code, error_message):
"""AI辅助调试"""
prompt = f"""
以下代码出现了错误:
```python
{buggy_code}
```
错误信息:{error_message}
请分析:
1. 错误的根本原因
2. 修复方案
3. 修复后的完整代码
4. 如何避免类似问题
分析和修复:
"""
return prompt
def refactor_legacy_code(self, legacy_code, modern_requirements):
"""重构遗留代码"""
prompt = f"""
需要重构以下遗留代码:
```python
{legacy_code}
```
现代化要求:{modern_requirements}
请提供:
1. 重构计划和步骤
2. 重构后的代码
3. 性能和可维护性改进说明
4. 测试建议
重构方案:
"""
return prompt系统设计的提示模板
python
class SystemDesignPrompts:
def design_api(self, service_description, requirements):
"""API设计提示"""
prompt = f"""
需要设计一个{service_description}的API。
功能需求:{requirements}
请提供:
1. RESTful API设计
2. 请求/响应格式
3. 错误处理策略
4. 认证授权方案
5. 性能考虑
6. OpenAPI规范文档
API设计:
"""
return prompt
def architecture_consultation(self, problem, constraints):
"""架构咨询提示"""
prompt = f"""
架构问题:{problem}
约束条件:{constraints}
请作为架构师提供:
1. 问题分析
2. 多种解决方案对比
3. 推荐方案及理由
4. 实施计划
5. 风险评估
6. 技术选型建议
架构建议:
"""
return prompt
# 实际使用示例
design_prompts = SystemDesignPrompts()
api_prompt = design_prompts.design_api(
"用户管理服务",
"注册、登录、个人信息管理、权限控制"
)基于大模型的应用架构设计
RAG系统:让AI拥有专业知识
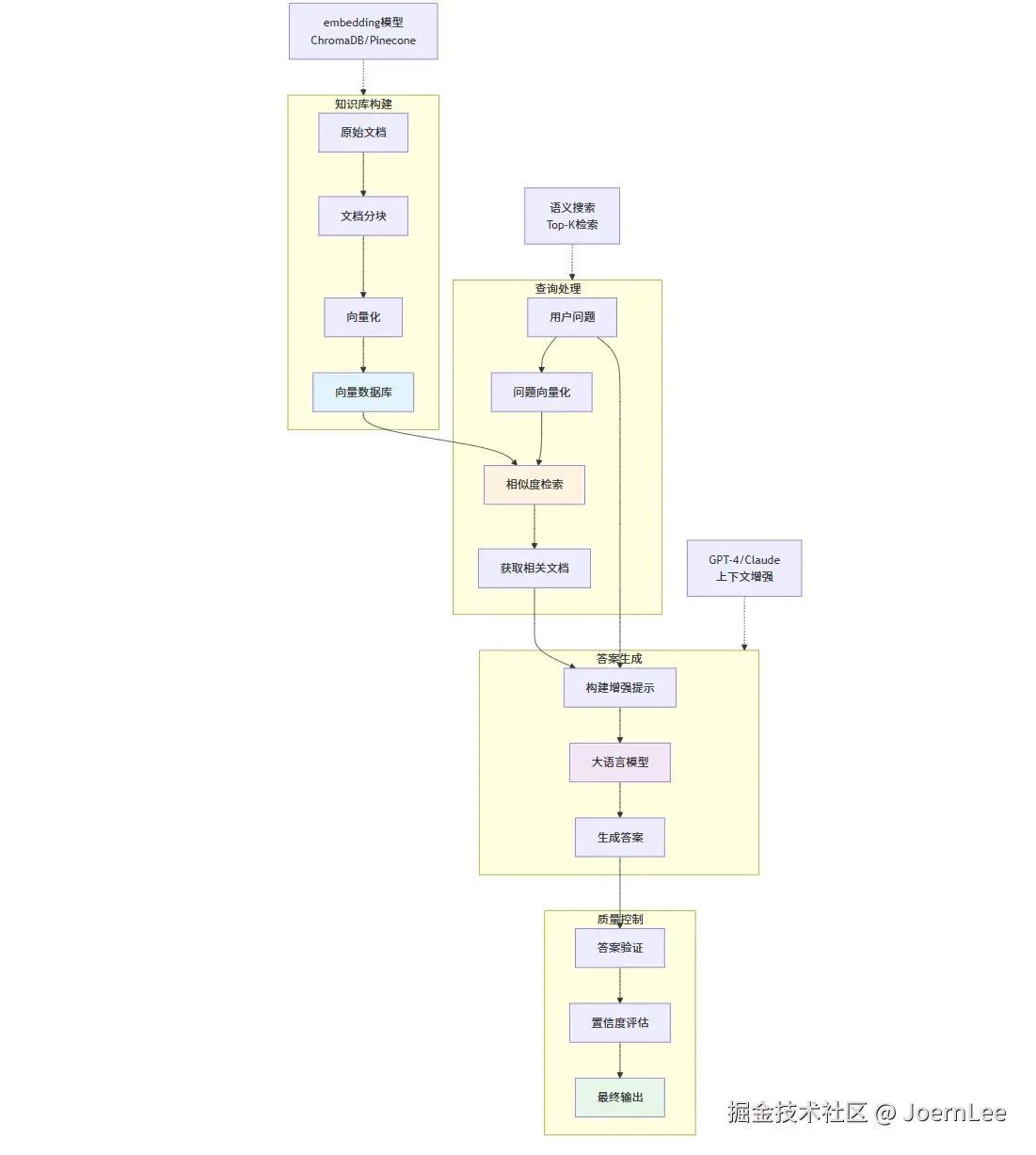
python
# RAG (Retrieval-Augmented Generation) 架构
class RAGSystem:
def __init__(self):
self.vector_db = VectorDatabase()
self.embedding_model = SentenceTransformer('all-MiniLM-L6-v2')
self.llm = OpenAIGPT4()
def index_documents(self, documents):
"""将文档转换为向量并存储"""
for doc in documents:
# 文档分块
chunks = self.chunk_document(doc)
for chunk in chunks:
# 生成嵌入向量
embedding = self.embedding_model.encode(chunk.text)
# 存储到向量数据库
self.vector_db.insert({
'id': chunk.id,
'text': chunk.text,
'embedding': embedding,
'metadata': chunk.metadata
})
def answer_question(self, question):
"""基于知识库回答问题"""
# 1. 将问题转换为向量
question_embedding = self.embedding_model.encode(question)
# 2. 检索相关文档
relevant_docs = self.vector_db.search(
question_embedding,
top_k=5
)
# 3. 构建增强提示
context = "\n".join([doc['text'] for doc in relevant_docs])
prompt = f"""
基于以下上下文回答问题:
上下文:
{context}
问题:{question}
请基于上下文提供准确的答案,如果上下文中没有相关信息,请明确说明。
"""
# 4. 生成回答
return self.llm.generate(prompt)
# 实际应用:代码知识库问答
class CodebaseQA(RAGSystem):
def __init__(self, codebase_path):
super().__init__()
self.index_codebase(codebase_path)
def index_codebase(self, codebase_path):
"""索引代码库"""
code_files = self.extract_code_files(codebase_path)
documents = []
for file_path in code_files:
with open(file_path, 'r') as f:
content = f.read()
# 提取函数和类
functions = self.extract_functions(content)
classes = self.extract_classes(content)
for func in functions:
documents.append({
'text': func['code'],
'type': 'function',
'name': func['name'],
'file': file_path,
'docstring': func['docstring']
})
self.index_documents(documents)
def ask_about_code(self, question):
"""询问代码相关问题"""
return self.answer_question(question)
# 使用示例
qa_system = CodebaseQA("/path/to/project")
answer = qa_system.ask_about_code("这个项目的用户认证是怎么实现的?")向量数据库集成
python
# 不同向量数据库的集成
class VectorDBManager:
def __init__(self, db_type="chroma"):
if db_type == "chroma":
self.db = self.setup_chroma()
elif db_type == "pinecone":
self.db = self.setup_pinecone()
elif db_type == "weaviate":
self.db = self.setup_weaviate()
def setup_chroma(self):
"""ChromaDB - 本地开发友好"""
import chromadb
client = chromadb.Client()
collection = client.create_collection("documents")
return collection
def setup_pinecone(self):
"""Pinecone - 云端高性能"""
import pinecone
pinecone.init(api_key="your-api-key", environment="us-west1-gcp")
index = pinecone.Index("document-index")
return index
def semantic_search(self, query, top_k=5):
"""语义搜索"""
query_embedding = self.embedding_model.encode(query)
if isinstance(self.db, chromadb.Collection):
results = self.db.query(
query_embeddings=[query_embedding.tolist()],
n_results=top_k
)
return results['documents'][0]
elif hasattr(self.db, 'query'): # Pinecone
results = self.db.query(
vector=query_embedding.tolist(),
top_k=top_k,
include_metadata=True
)
return [match['metadata']['text'] for match in results['matches']]大模型应用的性能优化
python
class LLMOptimization:
def __init__(self):
self.cache = {}
self.rate_limiter = RateLimiter()
def cached_generation(self, prompt, cache_key=None):
"""缓存机制减少重复调用"""
if cache_key is None:
cache_key = hashlib.md5(prompt.encode()).hexdigest()
if cache_key in self.cache:
return self.cache[cache_key]
result = self.llm.generate(prompt)
self.cache[cache_key] = result
return result
def batch_processing(self, prompts):
"""批量处理提高效率"""
with self.rate_limiter:
results = []
batch_size = 10
for i in range(0, len(prompts), batch_size):
batch = prompts[i:i+batch_size]
batch_results = self.llm.batch_generate(batch)
results.extend(batch_results)
return results
def streaming_response(self, prompt):
"""流式响应改善用户体验"""
for chunk in self.llm.stream_generate(prompt):
yield chunk
def cost_optimization(self, prompt, max_tokens=None):
"""成本优化策略"""
# 1. 选择合适的模型
if len(prompt) < 1000 and "code" not in prompt.lower():
model = "gpt-3.5-turbo" # 便宜的模型
else:
model = "gpt-4" # 复杂任务用好模型
# 2. 优化token使用
if max_tokens is None:
max_tokens = min(1000, len(prompt) * 2) # 动态调整
# 3. 使用压缩提示
compressed_prompt = self.compress_prompt(prompt)
return self.llm.generate(
compressed_prompt,
model=model,
max_tokens=max_tokens
)开发者在AI时代的技能进化
从"写代码"到"设计AI工作流"
python
# 传统开发者技能树
class TraditionalDeveloper:
skills = {
'programming_languages': ['Python', 'JavaScript', 'Java'],
'frameworks': ['React', 'Django', 'Spring'],
'databases': ['PostgreSQL', 'MongoDB'],
'tools': ['Git', 'Docker', 'Kubernetes'],
'practices': ['TDD', 'CI/CD', 'Agile']
}
# AI时代开发者技能树
class AIEraeDeveloper:
skills = {
# 传统技能仍然重要
'core_programming': ['Python', 'JavaScript', 'TypeScript'],
'traditional_tools': ['Git', 'Docker', 'Kubernetes'],
# 新增AI技能
'ai_integration': [
'API调用和管理',
'提示工程设计',
'向量数据库操作',
'RAG系统构建'
],
'ai_tools': [
'LangChain/LlamaIndex',
'Pinecone/Chroma',
'OpenAI/Anthropic APIs',
'Hugging Face'
],
'ai_workflow_design': [
'AI任务分解',
'多模型协同',
'人机协作设计',
'AI系统监控'
]
}
def design_ai_workflow(self, business_requirement):
"""设计AI工作流"""
workflow = {
'input_processing': self.design_input_handler(business_requirement),
'ai_pipeline': self.design_ai_pipeline(business_requirement),
'output_formatting': self.design_output_formatter(business_requirement),
'human_in_loop': self.design_human_oversight(business_requirement)
}
return workflow传统技能的AI增强
python
class EnhancedDevelopmentSkills:
def debugging_with_ai(self, error_log, codebase):
"""AI增强的调试能力"""
# 1. AI分析错误日志
error_analysis = self.ai_analyzer.analyze_error(error_log)
# 2. AI搜索相关代码
relevant_code = self.code_search.find_related_code(
error_analysis.keywords,
codebase
)
# 3. AI生成调试建议
debug_suggestions = self.ai_debugger.suggest_fixes(
error_analysis,
relevant_code
)
return {
'error_analysis': error_analysis,
'related_code': relevant_code,
'suggestions': debug_suggestions
}
def architecture_design_with_ai(self, requirements):
"""AI辅助架构设计"""
# 1. AI分析需求复杂度
complexity_analysis = self.ai_architect.analyze_complexity(requirements)
# 2. AI推荐技术栈
tech_stack = self.ai_architect.recommend_stack(
complexity_analysis,
self.get_team_skills(),
self.get_constraints()
)
# 3. AI生成架构图
architecture_diagram = self.ai_architect.generate_architecture(
requirements,
tech_stack
)
return {
'complexity': complexity_analysis,
'recommended_stack': tech_stack,
'architecture': architecture_diagram
}
def code_review_with_ai(self, pull_request):
"""AI增强的代码审查"""
ai_review = self.ai_reviewer.review_code(pull_request.diff)
human_review_focus = self.ai_reviewer.suggest_human_focus_areas(
ai_review,
pull_request.complexity
)
return {
'ai_findings': ai_review.issues,
'ai_suggestions': ai_review.improvements,
'human_review_needed': human_review_focus
}新兴职业机会
python
class NewAIRoles:
class AIEngineer:
"""AI工程师:构建AI系统的专家"""
responsibilities = [
"设计和实现AI应用架构",
"优化模型性能和成本",
"构建AI数据管道",
"集成多种AI服务"
]
def build_ai_application(self, requirements):
return {
'model_selection': self.select_optimal_models(requirements),
'data_pipeline': self.design_data_pipeline(requirements),
'inference_optimization': self.optimize_inference(requirements),
'monitoring_setup': self.setup_monitoring(requirements)
}
class PromptEngineer:
"""提示工程师:AI交互专家"""
responsibilities = [
"设计高效的提示模板",
"优化AI输出质量",
"构建提示管理系统",
"训练团队提示技巧"
]
def optimize_prompt_for_task(self, task, current_prompt, performance_metrics):
# A/B测试不同提示版本
prompt_variants = self.generate_prompt_variants(current_prompt)
best_prompt = self.test_prompts(prompt_variants, task, performance_metrics)
return {
'optimized_prompt': best_prompt,
'performance_improvement': self.calculate_improvement(),
'recommended_usage': self.generate_usage_guidelines()
}
class AIProductManager:
"""AI产品经理:AI产品策略专家"""
responsibilities = [
"定义AI产品功能",
"评估AI能力与业务需求匹配度",
"管理AI产品路线图",
"协调技术团队和业务团队"
]
def evaluate_ai_feasibility(self, product_idea):
return {
'technical_feasibility': self.assess_technical_feasibility(product_idea),
'data_requirements': self.analyze_data_needs(product_idea),
'cost_estimation': self.estimate_development_cost(product_idea),
'timeline': self.create_development_timeline(product_idea)
}AI技术选型指南:什么场景用什么技术?
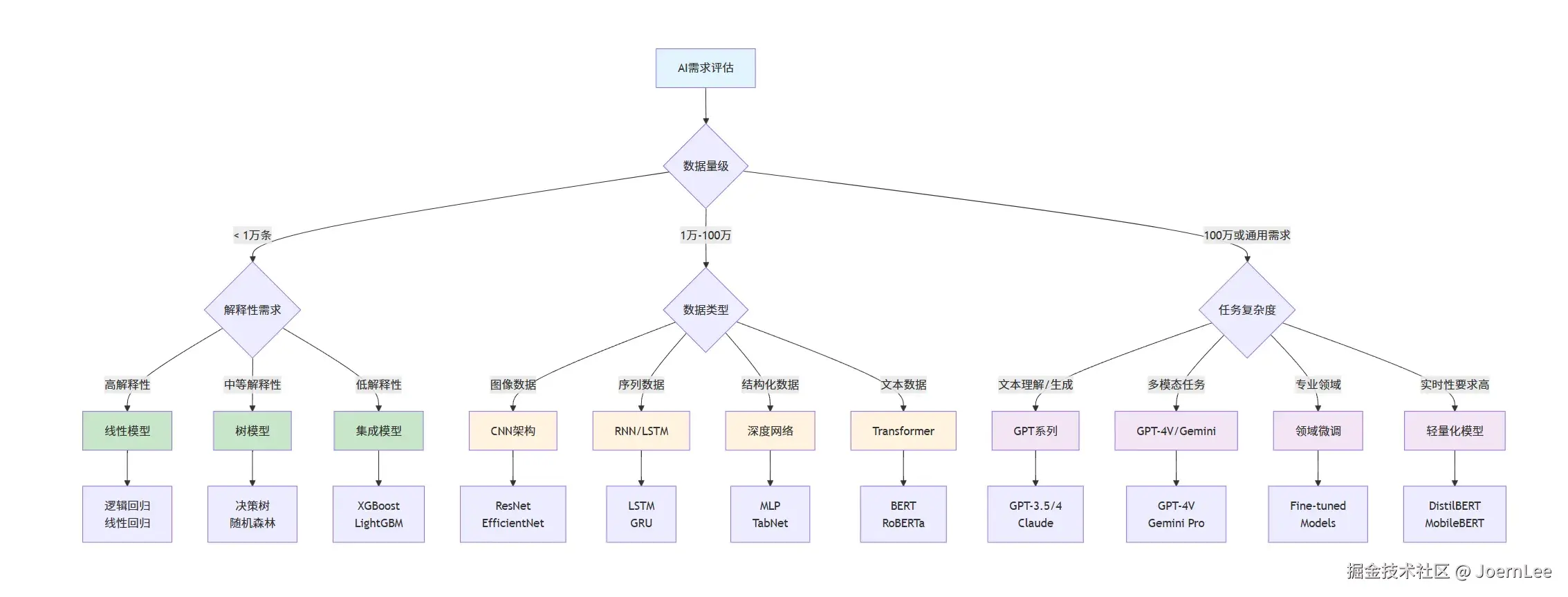
详细技术选型矩阵
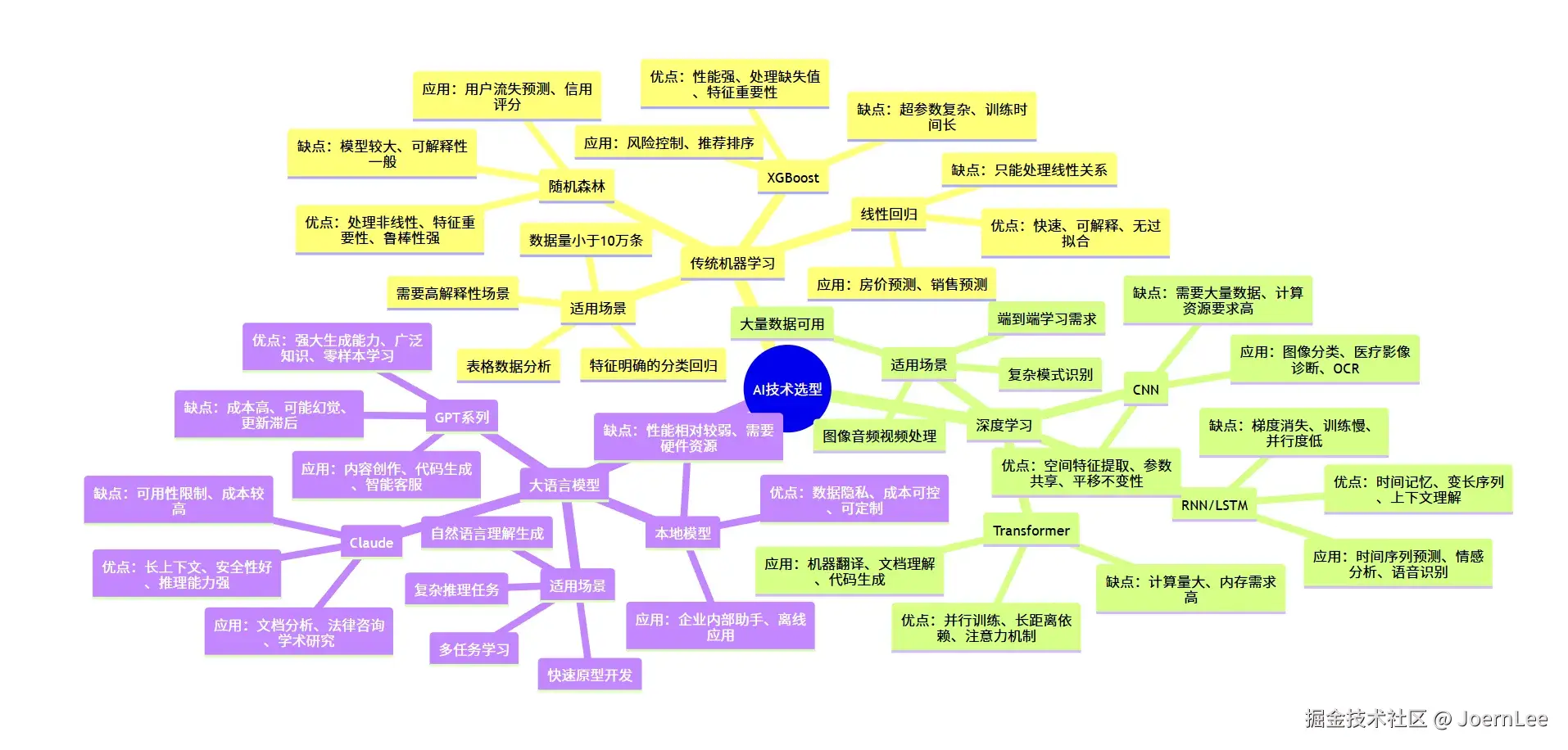
python
class TechnologySelector:
def __init__(self):
self.selection_matrix = {
'traditional_ml': {
'best_for': [
'表格数据分析',
'特征明确的分类/回归',
'需要高解释性的场景',
'数据量<10万条'
],
'algorithms': {
'linear_regression': {
'use_case': '简单回归预测',
'pros': ['快速', '可解释', '无过拟合风险'],
'cons': ['只能处理线性关系'],
'example': '房价预测、销售预测'
},
'random_forest': {
'use_case': '复杂分类问题',
'pros': ['处理非线性', '特征重要性', '鲁棒性强'],
'cons': ['模型较大', '可解释性一般'],
'example': '用户流失预测、信用评分'
},
'xgboost': {
'use_case': '竞赛级表格数据',
'pros': ['性能强', '处理缺失值', '特征重要性'],
'cons': ['超参数复杂', '训练时间长'],
'example': '风险控制、推荐排序'
}
}
},
'deep_learning': {
'best_for': [
'图像/音频/视频处理',
'复杂模式识别',
'大量数据可用',
'端到端学习需求'
],
'architectures': {
'cnn': {
'use_case': '计算机视觉任务',
'pros': ['空间特征提取', '参数共享', '平移不变性'],
'cons': ['需要大量数据', '计算资源要求高'],
'example': '图像分类、医疗影像诊断、OCR'
},
'rnn_lstm': {
'use_case': '序列数据处理',
'pros': ['时间记忆', '变长序列', '上下文理解'],
'cons': ['梯度消失', '训练慢', '并行度低'],
'example': '时间序列预测、情感分析、语音识别'
},
'transformer': {
'use_case': 'NLP和多模态任务',
'pros': ['并行训练', '长距离依赖', '注意力机制'],
'cons': ['计算量大', '内存需求高'],
'example': '机器翻译、文档理解、代码生成'
}
}
},
'large_language_models': {
'best_for': [
'自然语言理解/生成',
'复杂推理任务',
'多任务学习',
'快速原型开发'
],
'models': {
'gpt_family': {
'use_case': '通用文本生成和理解',
'pros': ['强大的生成能力', '广泛的知识', '零样本学习'],
'cons': ['成本高', '可能幻觉', '更新滞后'],
'example': '内容创作、代码生成、智能客服'
},
'claude': {
'use_case': '长文档分析和推理',
'pros': ['长上下文', '安全性好', '推理能力强'],
'cons': ['可用性限制', '成本较高'],
'example': '文档分析、法律咨询、学术研究'
},
'local_models': {
'use_case': '私有化部署需求',
'pros': ['数据隐私', '成本可控', '可定制'],
'cons': ['性能相对较弱', '需要硬件资源'],
'example': '企业内部助手、离线应用'
}
}
}
}
def recommend_technology(self, requirements):
"""基于需求推荐技术方案"""
data_size = requirements.get('data_size', 0)
data_type = requirements.get('data_type', 'structured')
performance_requirement = requirements.get('performance', 'medium')
interpretability_need = requirements.get('interpretability', 'medium')
budget = requirements.get('budget', 'medium')
latency_requirement = requirements.get('latency', 'medium')
recommendations = []
# 基于数据量初步筛选
if data_size < 10000:
category = 'traditional_ml'
elif data_size < 1000000 and data_type in ['image', 'audio', 'sequence']:
category = 'deep_learning'
else:
category = 'large_language_models'
# 详细推荐逻辑
if category == 'traditional_ml':
if interpretability_need == 'high':
recommendations.append({
'technology': 'Linear Regression/Logistic Regression',
'reason': '高可解释性,适合需要理解模型决策的场景',
'implementation_effort': 'Low',
'cost': 'Low'
})
else:
recommendations.append({
'technology': 'XGBoost/Random Forest',
'reason': '平衡性能和复杂度,适合表格数据',
'implementation_effort': 'Medium',
'cost': 'Low'
})
elif category == 'deep_learning':
if data_type == 'image':
recommendations.append({
'technology': 'CNN (ResNet/EfficientNet)',
'reason': '图像处理的最佳选择',
'implementation_effort': 'High',
'cost': 'Medium'
})
elif data_type == 'text':
recommendations.append({
'technology': 'Transformer (BERT/RoBERTa)',
'reason': '文本理解的强大架构',
'implementation_effort': 'High',
'cost': 'Medium'
})
else: # large_language_models
if budget == 'high' and performance_requirement == 'high':
recommendations.append({
'technology': 'GPT-4/Claude-3',
'reason': '最强性能,适合复杂任务',
'implementation_effort': 'Low',
'cost': 'High'
})
else:
recommendations.append({
'technology': 'GPT-3.5/Local Models',
'reason': '性价比平衡,适合大多数场景',
'implementation_effort': 'Low',
'cost': 'Medium'
})
return recommendations实际案例分析
python
class EcommerceAISelector:
def __init__(self):
self.platform_scenarios = {
'product_recommendation': {
'description': '个性化商品推荐系统',
'data_characteristics': {
'user_behavior_logs': '每日100万+条',
'product_catalog': '50万商品',
'user_profiles': '1000万用户',
'interaction_matrix': '稀疏矩阵,填充率<1%'
},
'business_requirements': {
'accuracy': '点击率提升30%以上',
'latency': '<100ms响应时间',
'scalability': '支持双11流量峰值',
'interpretability': '需要解释推荐理由'
}
},
'image_search': {
'description': '商品图像搜索与识别',
'data_characteristics': {
'product_images': '500万张高清图片',
'user_uploads': '每日10万张搜索图片',
'categories': '3000个细分类目',
'attributes': '颜色、款式、材质等多维属性'
},
'business_requirements': {
'accuracy': '图像匹配准确率>90%',
'speed': '图像检索<200ms',
'coverage': '支持所有商品类目',
'user_experience': '支持拍照搜索功能'
}
},
'customer_service': {
'description': '智能客服问答系统',
'data_characteristics': {
'historical_qa': '100万条客服对话记录',
'product_knowledge': '商品详情、政策文档',
'daily_inquiries': '5万条客户咨询',
'languages': '中英文双语支持'
},
'business_requirements': {
'resolution_rate': '80%问题自动解决',
'response_time': '<3秒响应',
'accuracy': '答案准确率>95%',
'escalation': '复杂问题无缝转人工'
}
},
'price_optimization': {
'description': '动态定价策略优化',
'data_characteristics': {
'historical_sales': '2年销售数据',
'competitor_prices': '竞品价格监控',
'market_factors': '季节性、促销、库存等',
'user_segments': '不同用户群体价格敏感度'
},
'business_requirements': {
'profit_optimization': '毛利率提升5%',
'market_competitiveness': '保持价格竞争力',
'real_time': '实时价格调整',
'compliance': '符合定价法规'
}
},
'fraud_detection': {
'description': '交易欺诈检测系统',
'data_characteristics': {
'transaction_records': '每日200万笔交易',
'fraud_samples': '0.1%欺诈率(极不平衡)',
'user_behavior': '登录、浏览、购买行为',
'device_info': '设备指纹、IP地址等'
},
'business_requirements': {
'recall_rate': '欺诈检出率>99%',
'false_positive': '误报率<1%',
'real_time': '交易时实时判断',
'explainability': '风控决策可解释'
}
}
}
def analyze_scenario(self, scenario_name):
scenario = self.platform_scenarios[scenario_name]
if scenario_name == 'product_recommendation':
return self.recommendation_system_analysis()
elif scenario_name == 'image_search':
return self.image_search_analysis()
elif scenario_name == 'customer_service':
return self.customer_service_analysis()
elif scenario_name == 'price_optimization':
return self.price_optimization_analysis()
elif scenario_name == 'fraud_detection':
return self.fraud_detection_analysis()
def recommendation_system_analysis(self):
return {
'scenario': '个性化商品推荐系统',
'challenge': '从千万级商品中为用户推荐感兴趣的商品',
'technology_options': {
'traditional_ml': {
'approach': '协同过滤 + XGBoost',
'pros': [
'成熟稳定,易于理解',
'冷启动问题有成熟解决方案',
'推荐理由可解释',
'计算成本可控'
],
'cons': [
'难以捕捉复杂用户偏好',
'特征工程工作量大',
'对新用户新商品效果有限'
],
'implementation': '''
# 协同过滤 + 特征工程
features = [
'user_age', 'user_gender', 'purchase_history',
'category_preference', 'brand_preference',
'price_sensitivity', 'seasonal_pattern'
]
model = XGBRanker()
'''
},
'deep_learning': {
'approach': 'Deep Crossing + Wide&Deep',
'pros': [
'自动学习用户商品交互',
'处理高维稀疏特征',
'捕捉非线性关系',
'支持多任务学习'
],
'cons': [
'训练复杂,需要GPU资源',
'黑盒模型,解释性差',
'冷启动仍是挑战'
],
'implementation': '''
# Wide&Deep 架构
wide_part = linear_features # 记忆能力
deep_part = dnn_features # 泛化能力
output = wide_part + deep_part
'''
},
'llm_enhanced': {
'approach': 'LLM + RAG + 传统推荐',
'pros': [
'理解商品语义信息',
'生成个性化推荐理由',
'支持自然语言查询',
'快速适配新场景'
],
'cons': [
'API调用成本高',
'响应时间可能较长',
'需要商品知识库建设'
],
'implementation': '''
# 混合推荐架构
candidates = traditional_recommender.get_candidates(user)
enhanced_candidates = llm.enrich_with_reasons(candidates, user_profile)
final_ranking = llm.personalized_ranking(enhanced_candidates)
'''
}
},
'recommended_solution': {
'primary': 'Deep Learning (Wide&Deep)',
'reasoning': [
'数据量充足,适合深度学习',
'用户行为复杂,需要强特征学习能力',
'性能要求高,深度学习效果最优'
],
'architecture': '''
用户特征 + 商品特征 + 上下文特征
↓
Wide部分(线性组合) + Deep部分(DNN)
↓
融合层 + 排序层
↓
Top-K推荐结果
''',
'fallback_strategy': '传统协同过滤作为baseline和异常情况fallback'
}
}
def image_search_analysis(self):
return {
'scenario': '商品图像搜索与识别',
'challenge': '用户上传图片搜索相似商品',
'technology_comparison': {
'traditional_cv': {
'approach': 'SIFT/ORB特征 + 传统匹配',
'verdict': '❌ 不推荐',
'reason': '无法理解商品语义,只能做像素级匹配'
},
'cnn_architecture': {
'approach': 'ResNet/EfficientNet + 向量检索',
'verdict': '✅ 强烈推荐',
'reason': '图像任务最佳选择,性能和成本平衡'
},
'multimodal_llm': {
'approach': 'GPT-4V + 商品描述生成',
'verdict': '⚠️ 辅助使用',
'reason': '成本过高,但可用于商品属性提取'
}
},
'detailed_solution': {
'core_architecture': 'CNN特征提取 + 向量数据库',
'implementation_plan': [
'1. 预训练CNN模型在商品数据上微调',
'2. 提取所有商品图像的特征向量',
'3. 构建高效的向量检索系统',
'4. 用户图片实时特征提取和匹配',
'5. 结合商品属性进行结果优化'
],
'technology_stack': {
'model': 'EfficientNet-B4微调版本',
'vector_db': 'Faiss/Pinecone向量检索',
'serving': 'TensorRT模型加速',
'caching': 'Redis缓存热门搜索'
},
'performance_optimization': [
'模型量化减少推理时间',
'特征向量预计算',
'多级检索策略(粗筛+精排)',
'CDN加速图片加载'
]
}
}
def customer_service_analysis(self):
return {
'scenario': '智能客服问答系统',
'challenge': '自动回答客户关于商品、订单、售后的问题',
'evolution_path': {
'v1_rule_based': {
'approach': '关键词匹配 + 决策树',
'coverage': '30%问题覆盖率',
'limitation': '无法理解复杂表达'
},
'v2_intent_classification': {
'approach': 'BERT意图分类 + 模板回复',
'coverage': '60%问题覆盖率',
'limitation': '回复模板化,用户体验一般'
},
'v3_rag_enhanced': {
'approach': 'RAG系统 + LLM生成',
'coverage': '85%问题覆盖率',
'advantage': '自然对话,个性化回复'
}
},
'recommended_architecture': {
'system_design': '''
用户问题
↓
意图识别(BERT) → 简单问题直接回答
↓
知识检索(RAG) → 获取相关商品/政策信息
↓
LLM生成回答 → 基于检索内容生成个性化回复
↓
置信度评估 → 低置信度转人工客服
''',
'knowledge_base': [
'商品信息库:详细商品参数、使用说明',
'政策文档库:退换货、配送、售后政策',
'常见问题库:FAQ和标准回答',
'历史对话库:优质客服对话记录'
],
'quality_control': [
'多轮对话上下文理解',
'情感分析识别用户情绪',
'敏感内容过滤',
'回答质量实时评分'
]
}
}
def fraud_detection_analysis(self):
return {
'scenario': '交易欺诈检测系统',
'challenge': '在极不平衡数据中识别欺诈交易',
'data_challenge': {
'class_imbalance': '欺诈样本仅占0.1%',
'feature_complexity': '用户行为特征维度高',
'real_time_requirement': '毫秒级决策要求',
'cost_asymmetry': '漏检成本远高于误报'
},
'solution_evolution': {
'traditional_rules': {
'approach': '基于专家经验的规则引擎',
'pros': ['可解释性强', '响应快'],
'cons': ['规则维护困难', '容易被绕过'],
'use_case': '基础风控规则'
},
'ml_enhanced': {
'approach': '特征工程 + XGBoost/Random Forest',
'pros': ['性能提升显著', '特征重要性可解释'],
'cons': ['特征工程工作量大', '需要持续调优'],
'use_case': '主要风控模型'
},
'deep_learning': {
'approach': '深度神经网络 + Embedding',
'pros': ['自动特征学习', '捕捉复杂模式'],
'cons': ['黑盒模型', '解释性差'],
'use_case': '复杂欺诈模式检测'
},
'llm_assisted': {
'approach': 'LLM分析异常行为描述',
'pros': ['理解行为语义', '辅助规则生成'],
'cons': ['成本高', '不适合实时'],
'use_case': '案例分析和规则优化'
}
},
'hybrid_architecture': {
'real_time_layer': '轻量级规则 + 简单ML模型(<10ms)',
'batch_analysis': '复杂特征工程 + 深度学习模型',
'llm_enhancement': 'LLM辅助新规则发现和案例分析',
'human_in_loop': '高风险案例人工审核',
'implementation': '''
交易请求
↓
实时规则引擎 → 明显欺诈直接拦截
↓
轻量ML模型 → 风险评分
↓
动态阈值判断 → 通过/拦截/人工审核
↓
离线深度分析 → 模型持续优化
'''
}
}错误选择的反面案例
python
class AntiPatterns:
def llm_for_simple_tasks(self):
"""反例:用大模型做简单任务"""
return {
'bad_example': {
'task': '判断邮箱地址格式是否正确',
'bad_solution': '调用GPT-4 API判断',
'problems': [
'成本高:每次调用$0.03',
'延迟高:网络请求+推理时间',
'不稳定:可能出现格式变化',
'过度复杂:杀鸡用牛刀'
]
},
'good_solution': {
'method': '正则表达式验证',
'code': '''
import re
def validate_email(email):
pattern = r'^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+.[a-zA-Z]{2,}$'
return re.match(pattern, email) is not None
''',
'benefits': [
'成本:几乎为0',
'延迟:微秒级',
'可靠:100%确定性',
'简单:易于理解和维护'
]
}
}
def traditional_ml_for_complex_nlp(self):
"""反例:用传统ML做复杂NLP"""
return {
'bad_example': {
'task': '多轮对话理解和生成',
'bad_solution': '朴素贝叶斯+规则引擎',
'problems': [
'上下文丢失:无法记住对话历史',
'泛化能力差:无法处理新表达方式',
'维护噩梦:规则越来越复杂',
'用户体验差:回复生硬不自然'
]
},
'good_solution': {
'method': '对话生成模型或LLM API',
'reason': '复杂NLP任务需要深度理解能力',
'implementation': '使用ChatGPT API或fine-tune对话模型'
}
}好的!"未来展望"章节确实应该更多地用描述性语言来展示趋势和愿景,我来重新改写这部分:
未来展望:AI-First 的软件开发
软件开发范式的根本性转变
我们正在经历软件开发历史上的第四次重大范式转变:从机器语言到汇编语言 ,从汇编到高级语言 ,从高级语言到框架/平台化开发 ,现在进入AI-First的智能化开发时代。
在这个新时代,开发者的角色正在从"代码编写者"转变为"AI工作流设计者" 。我们不再需要从零开始编写每一行代码,而是要学会如何设计和编排AI能力,让机器成为我们的编程伙伴。
开发工具的智能化演进
智能代码助手的进化路径:
- 当前阶段:代码补全和生成(如GitHub Copilot)
- 近期发展:上下文感知的架构建议和重构方案
- 未来愿景:理解业务需求,自动生成完整的功能模块
开发环境的变革: 传统的IDE正在进化为AI增强的开发环境。想象一下,当你描述一个功能需求时,IDE不仅能生成代码,还能自动进行测试、优化性能、检查安全漏洞,甚至预测用户体验问题。
低代码/无代码平台的AI化革命
AI技术正在让低代码平台变得真正"智能":
自然语言编程成为现实: 开发者可以用自然语言描述复杂的业务逻辑,AI系统理解意图后自动生成相应的工作流和代码。这不是简单的模板填充,而是真正理解业务语义的智能转换。
可视化开发的新高度: AI可以理解设计稿、业务流程图,甚至是草图,自动生成对应的应用架构和实现代码。设计到开发的鸿沟正在被AI填平。
开发团队协作模式的演变
人机协作的新模式:
- AI作为初级开发者:处理重复性工作、代码重构、测试用例生成
- 人类专注高价值工作:架构设计、产品创新、用户体验优化
- AI作为实时导师:提供最佳实践建议、性能优化方案、安全检查
代码审查的智能化: AI不仅能检查语法错误,还能理解代码逻辑,提供架构层面的改进建议,甚至预测代码的可维护性和扩展性问题。
软件质量和安全的新标准
AI驱动的质量保证: 未来的软件开发将默认集成AI质量检查。从代码编写到部署上线,AI系统持续监控和优化软件质量,自动发现和修复潜在问题。
智能化的安全防护: AI能够理解代码的业务逻辑,发现传统静态分析工具无法检测的业务逻辑漏洞,为软件安全提供更深层的保护。
开发者技能的重新定义
新的核心能力要求:
- AI工作流设计能力:如何有效组合AI工具解决复杂问题
- 提示工程精通度:与AI进行高效沟通的艺术
- 跨模态思维:整合文本、图像、音频等多种信息形式
- 业务理解深度:更多时间专注于理解和优化业务价值
持续学习的新模式: 在AI-First的时代,技术更新速度加快,开发者需要建立与AI协同的持续学习机制。AI不仅是工具,更是我们的学习伙伴和知识扩展器。
软件产品形态的变革
AI-Native应用的崛起: 未来的软件产品将天生具备AI能力,不再是"传统软件+AI功能"的组合,而是以AI为核心架构设计的全新产品形态。
个性化程度的极致提升: 每个用户看到的界面、功能和交互方式都可能不同,AI根据用户行为和偏好实时调整产品体验。
这个AI-First的未来并不遥远,它正在悄然改变我们的工作方式。作为开发者,拥抱这个变化,学会与AI协作,将是我们在新时代保持竞争力的关键。
写在最后:拥抱AI,成为更好的开发者
这四篇文章带我们走过了一段完整的AI学习之旅:
- 第一篇建立了AI的整体认知框架
- 第二篇深入理解了机器学习的实际应用
- 第三篇探索了深度学习的技术原理
- 第四篇展望了大模型时代的开发新范式
核心启示:
- AI不是威胁,而是增强器:它让我们从重复性工作中解放出来,专注于更有创造性的任务
- 技术选型要理性:不是所有问题都需要最先进的技术,选择合适的技术才是最优解
- 学习永无止境:AI技术发展很快,保持好奇心和学习能力比掌握任何具体技术都重要
- 人机协作是未来:未来的开发者不是被AI替代,而是学会与AI协作的开发者
行动建议:
- 立即开始:选择一个AI工具(如Cursor),在日常工作中使用
- 深入实践:选择一个项目,尝试集成AI能力
- 持续学习:关注AI技术发展,定期尝试新工具
- 分享交流:与团队分享AI使用经验,共同成长
记住:在AI时代,最重要的不是担心被替代,而是 学会如何利用AI成为更强的自己。
让我们一起拥抱这个激动人心的时代,用AI的力量创造更美好的数字世界!
系列完结
感谢陪伴我们走过这段AI学习之旅。愿每位开发者都能在AI时代找到属于自己的位置,用技术的力量改变自己、团队与世界。