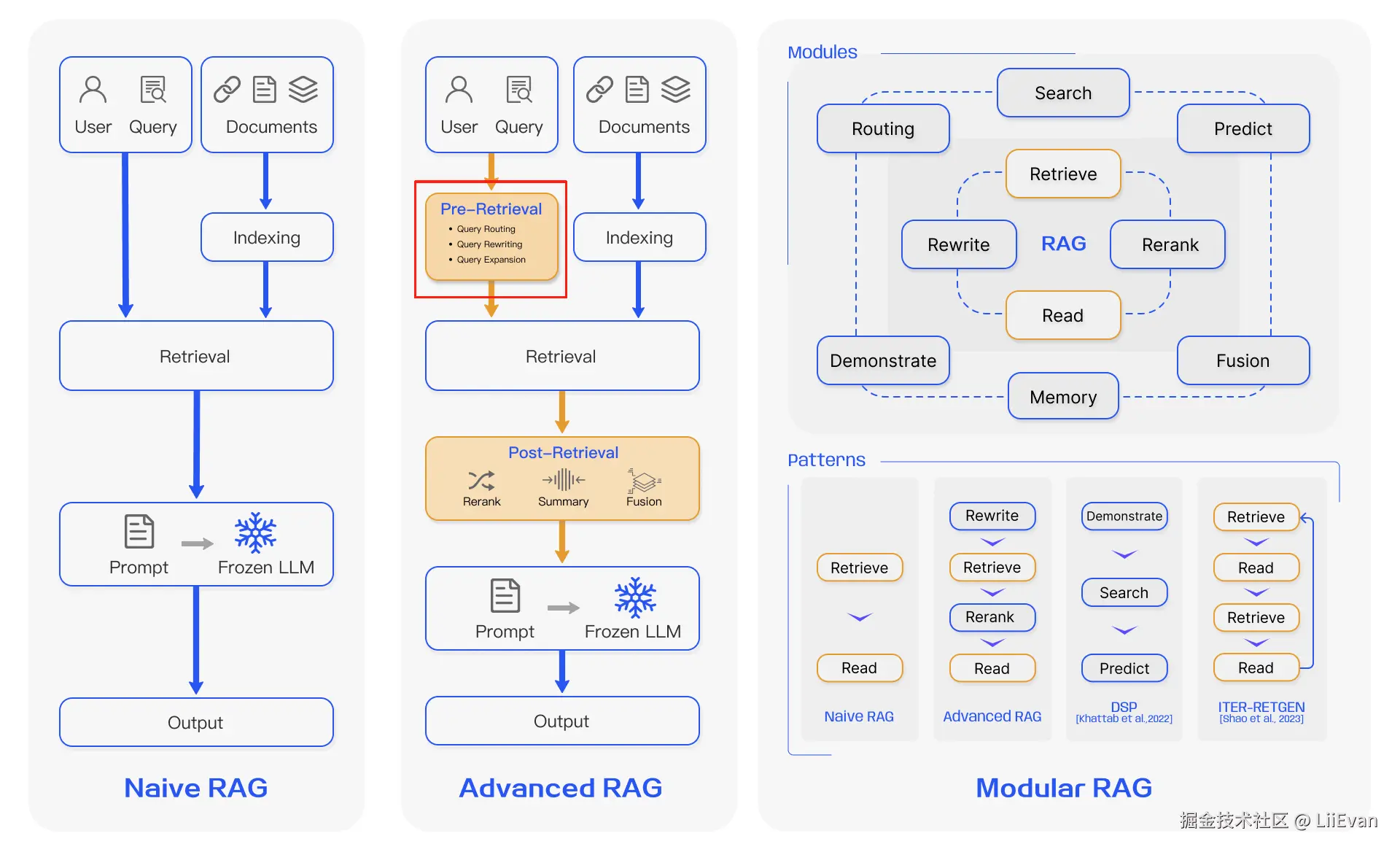
Pre-Retrieval指的是把用户问题传入检索模块之前,对查询进行预处理的过程(下图红框的位置)
今天我们要讲的是HyDE(Hypothetical Document Embeddings) - 假设性文档嵌入
1. 概念
我们之前的RAG思路,都是通过问题去检索答案,但是对于用户来说,问题的表述方式有可能千奇百怪。所以我们可以换个思路,不直接找"问题"的近义词,而是先想象一下"答案"可能长什么样,然后去找跟这个"假想答案"相似的真实答案。这种"答案到答案"的匹配,比"问题到答案"的匹配通常更精准。因为一个问题的表述方式可能不同,但正确的答案内容上总是相似的。
2. 通俗理解
比如你是一个图书馆管理员,有一个读者问:"关于罗马帝国衰亡的原因的书在哪?" 与其去思考"衰亡"、"原因"这些词的同义词,你不如在脑子里快速构思一个假设性的答案(一个虚构的文档):
"罗马帝国的衰亡是一个复杂的过程,主要原因包括内部的政治腐败 、连年的内战 、过度扩张 导致的边防压力,以及蛮族的入侵 。经济上,过度的税收 和奴隶制的崩溃也起到了关键作用..."
你很可能会找到爱德华·吉本的《罗马帝国衰亡史》,因为它的内容和你虚构的答案高度匹配。
3. 代码示例
- prompt
markdown
# 指令:生成用于 HyDE 检索的假设性文档
## 背景
我正在实施一个基于 HyDE (Hypothetical Document Embeddings) 的信息检索流程。你的任务是根据用户问题,生成一个内容详尽、信息准确的假设性回答。这个回答将直接用于向量嵌入,以检索最相关的真实文档。
## 任务
针对以下"用户问题",请生成一篇理想的、内容丰富的回答。
## 要求
- **直接输出:** 你的回答本身就是那篇假设性文档,请勿包含任何开场白、结尾或解释性文字 (例如,不要说"这是一个假设性的回答..."或"希望这能帮到你。")。
- **内容详实:** 回答应力求全面、准确,仿佛它就是一篇针对该问题的最佳参考资料。
- **格式中立:** 使用简洁的段落格式,专注于陈述事实和信息。
## 用户问题
{query}- 代码
ini
from openai import OpenAI
import os
import dotenv
dotenv.load_dotenv()
def query_llm(prompt):
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"), base_url=os.getenv("OPENAI_BASE_URL"))
completion = client.chat.completions.create(
model="gpt-4o-mini",
stream=False,
temperature=0,
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
)
return completion.choices[0].message.content
def hyde(query):
prompt = f"""
# 指令:生成用于 HyDE 检索的假设性文档
## 背景
我正在实施一个基于 HyDE (Hypothetical Document Embeddings) 的信息检索流程。你的任务是根据用户问题,生成一个内容详尽、信息准确的假设性回答。这个回答将直接用于向量嵌入,以检索最相关的真实文档。
## 任务
针对以下"用户问题",请生成一篇理想的、内容丰富的回答。
## 要求
- **直接输出:** 你的回答本身就是那篇假设性文档,请勿包含任何开场白、结尾或解释性文字 (例如,不要说"这是一个假设性的回答..."或"希望这能帮到你。")。
- **内容详实:** 回答应力求全面、准确,仿佛它就是一篇针对该问题的最佳参考资料。
- **格式中立:** 使用简洁的段落格式,专注于陈述事实和信息。
## 用户问题
{query}
"""
return query_llm(prompt)
if __name__ == "__main__":
query = "特斯拉在中国市场的挑战是什么?"
res = hyde(query)
print(res)- 结果展示

然后我们就可以把这个假设性的回答都作为检索的输入,检索出文档,再综合检索得到的文档得到最终的回答