部署Dify
代码拉取
bash
git clone https://github.com/langgenius/dify.git
cd dify/docker启动容器
bash
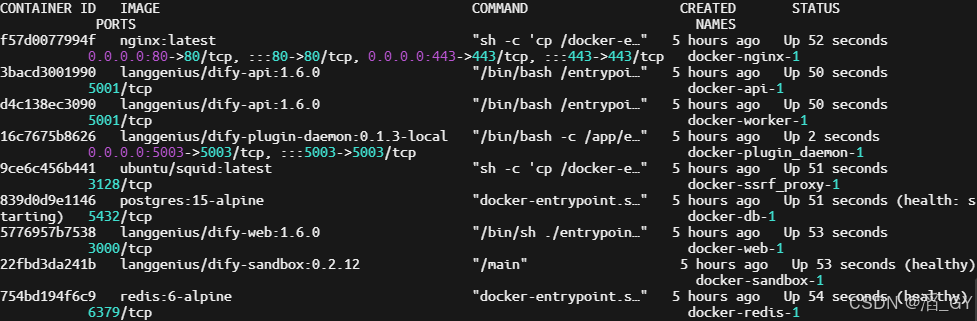
docker-compose up -d启动成功
准备知识库
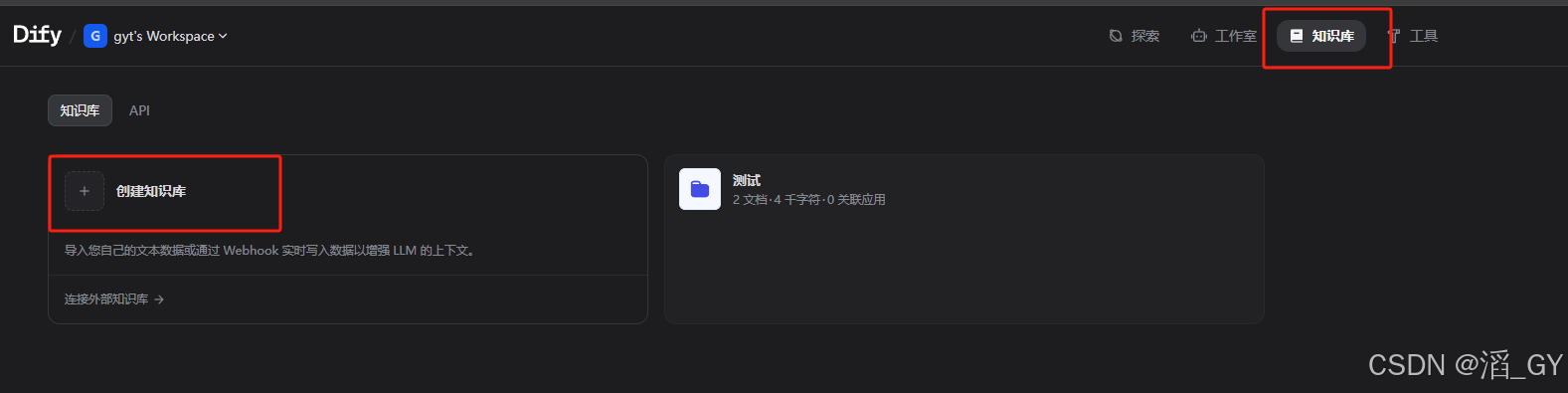
创建知识库
创建一个空的知识库
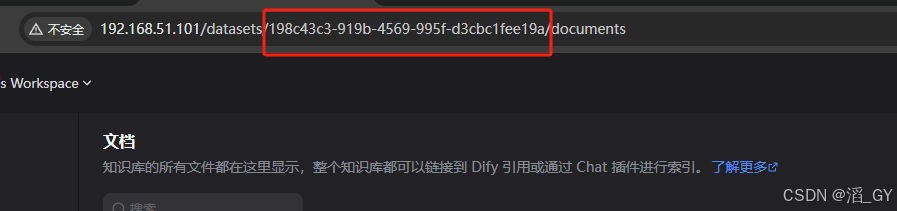
要先从网址中,找到这个知识库的id,记下后面需要用到。
新建API密钥
创建密钥,后面通过API将数据写入知识库用到

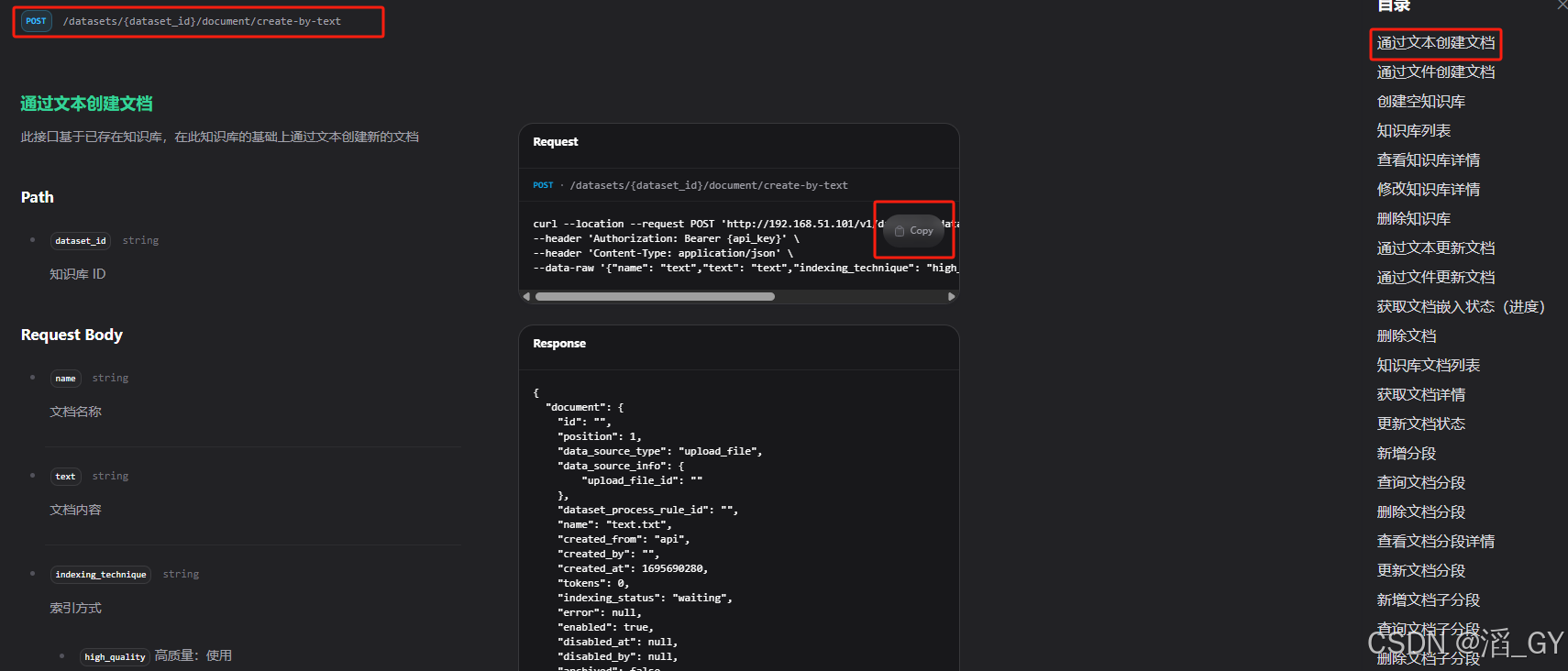
记下创建文档的API
后面通过这个API将数据写入知识库用到
安装工具
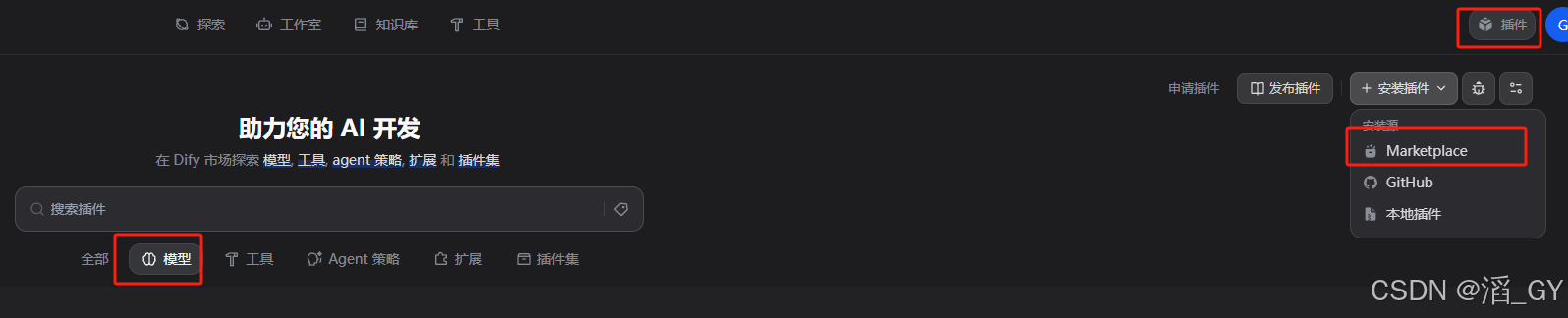
安装模型
打开插件,选择模型
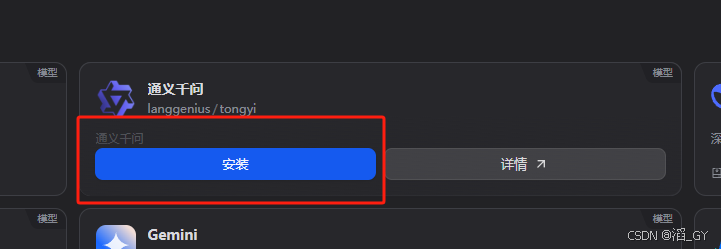
安装模型
配置模型
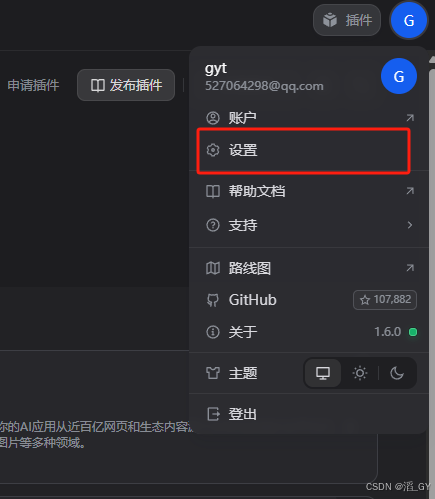
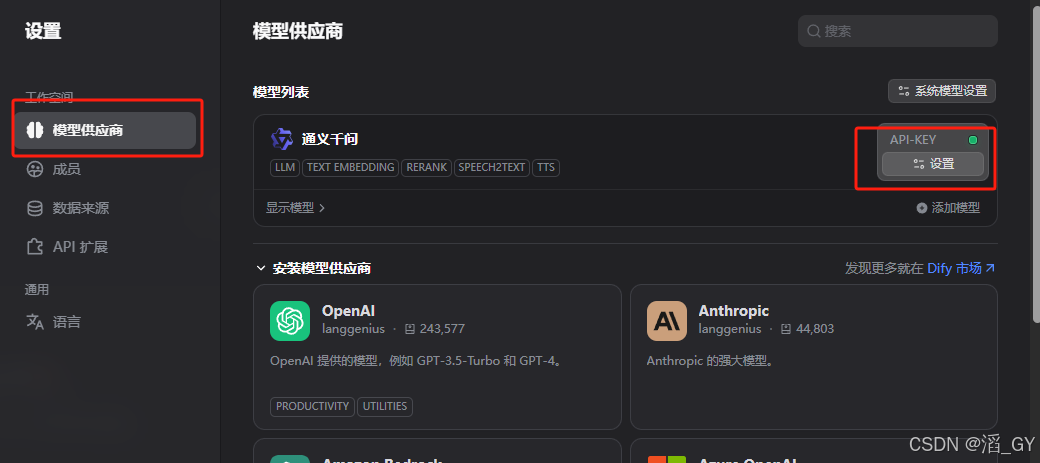
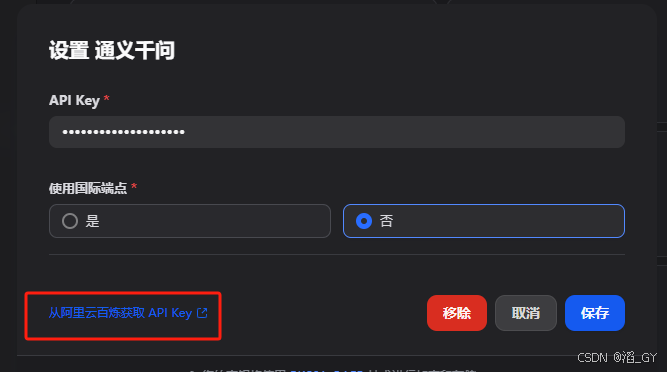
这里使用通义千问,因为开通的180天内免费100万个token。没有API Key可以从左下角获取。
安装Firecrawl
Firecrawl是一个爬虫工具。
配置Firecrawl
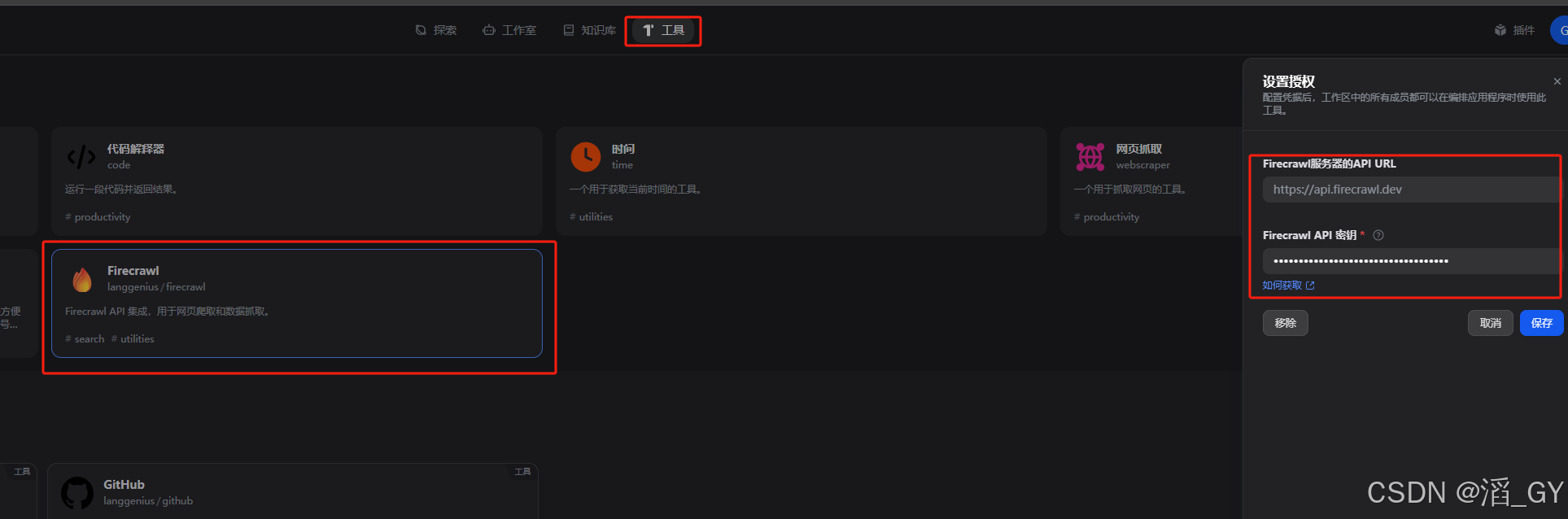
获取Firecrawl的API Key

创建爬虫知识库
创建Chatflow
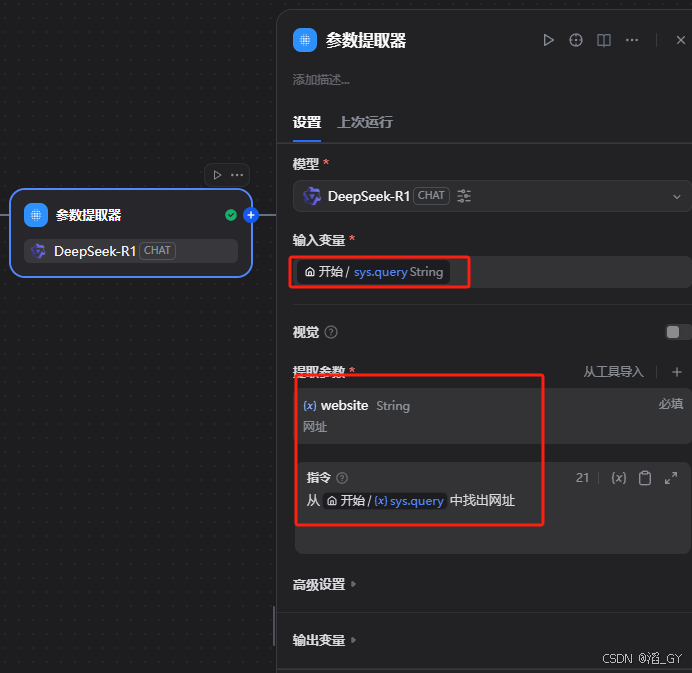
创建参数提取器
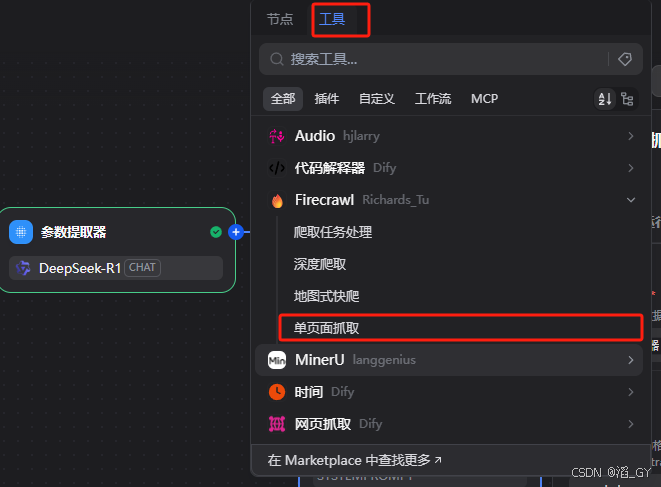
创建爬虫
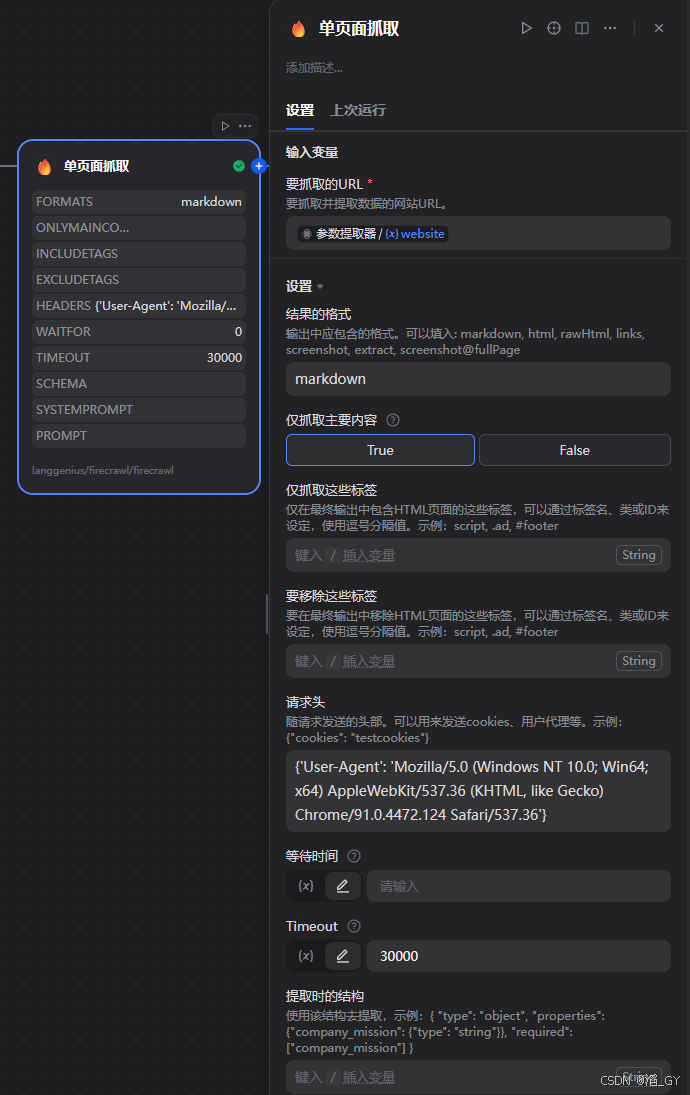
要抓取的URL:填写上一步返回的website
结果的格式:markdown
仅抓取主要内容:选择true
请求头: {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
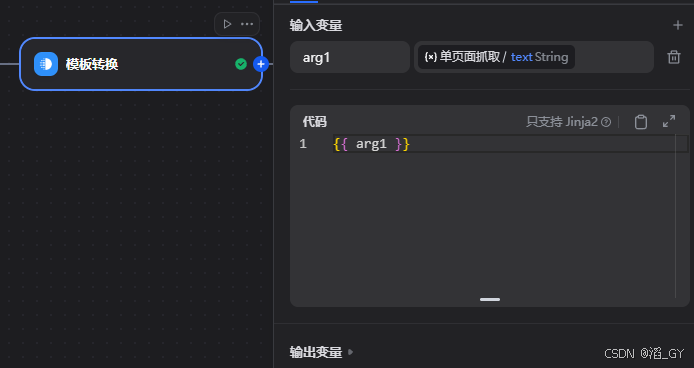
创建模板转换
模板转换的作用是获取上一步的爬虫内容的text,给下一步用。
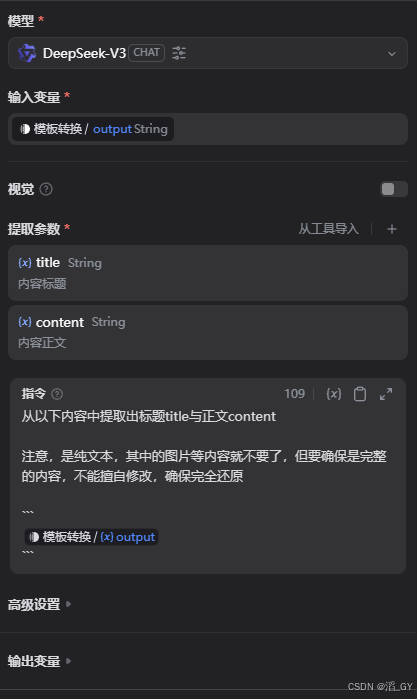
创建提取标题与正文
创建代码执行
过滤爬虫内容的特殊字符
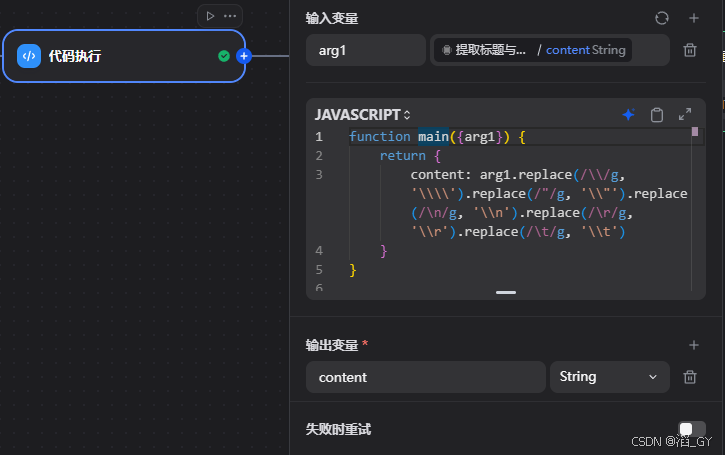
javascript
function main({arg1}) {
return {
content: arg1.replace(/\\/g, '\\\\').replace(/"/g, '\\"').replace(/\n/g, '\\n').replace(/\r/g, '\\r').replace(/\t/g, '\\t')
}
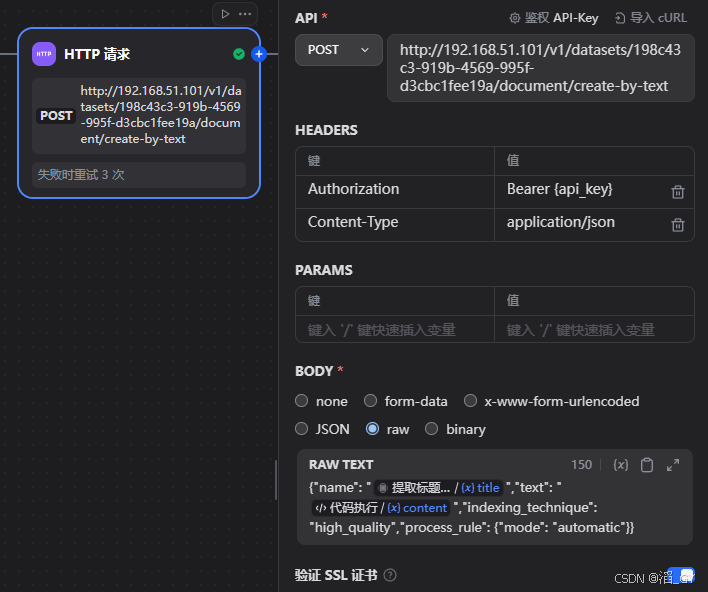
}创建HTTP 请求
将爬虫的数据通过知识库API保存到上面创建的知识库
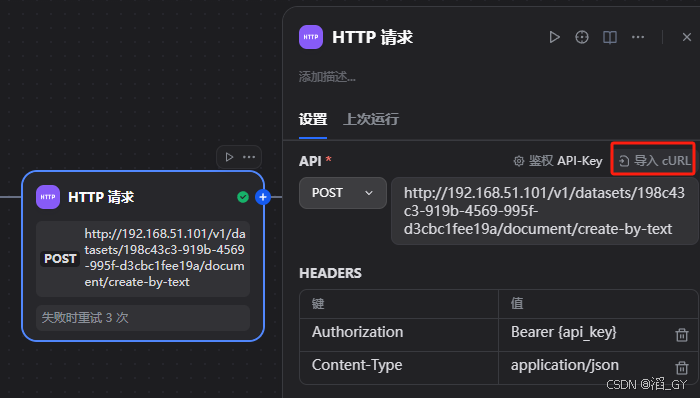
将上面复制的接口粘贴到这里
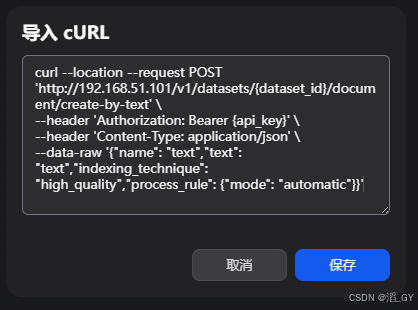
bash
curl --location --request POST 'http://192.168.51.101/v1/datasets/{dataset_id}/document/create-by-text' \
--header 'Authorization: Bearer {api_key}' \
--header 'Content-Type: application/json' \
--data-raw '{"name": "text","text": "text","indexing_technique": "high_quality","process_rule": {"mode": "automatic"}}'将dataset_id替换成上面保存的知识库id
添加接口的鉴权
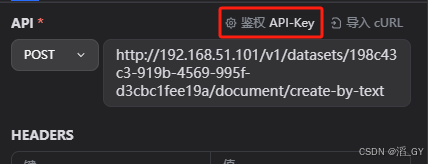
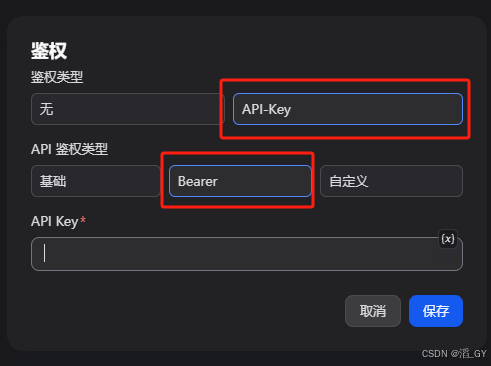
填写上面保存的API-Key
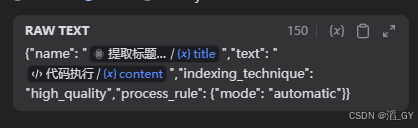
填写BODY
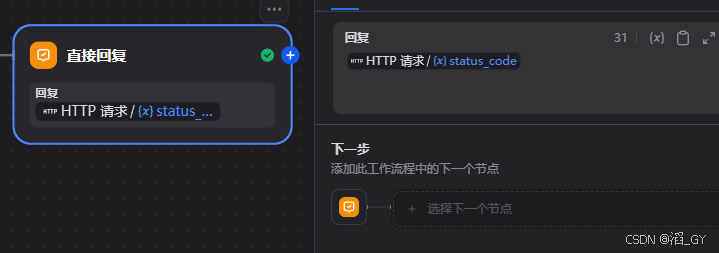
最后的回复
测试
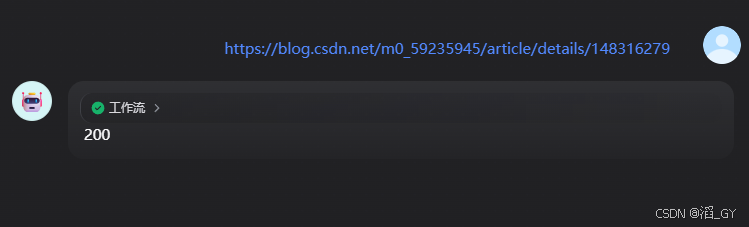

测试成功