要在 Windows 10 局域网环境下完成「下载 Qwen3Guard-Gen-8B 模型 → 私有化部署 → 接入 Dify」的全流程,以下是分阶段、可落地的详细步骤清单,重点解决局域网内的路径、网络、部署适配问题:
前提条件(必做)
- 硬件:Windows 10 主机需有 NVIDIA GPU(显存 ≥ 24G,如 RTX 3090/A10/A100,8B 模型至少需要 16G 显存,推荐 24G+);
- 软件 :
- 已安装 Docker Desktop(开启 WSL2 后端,参考 微软教程);
- 已安装 NVIDIA 驱动(版本 ≥ 510)+ NVIDIA Container Toolkit(让 Docker 调用 GPU);
- 已部署 Dify(局域网内可访问,如
http://192.168.1.100:8000);
- 网络 :确保下载模型的主机和 Dify 主机在同一局域网(可互相 ping 通)。
阶段 1:局域网内下载 Qwen3Guard-Gen-8B 模型
步骤 1:获取模型(两种方式,选其一)
方式 1:通过 huggingface_hub 下载(推荐)
-
以管理员身份打开 PowerShell,安装依赖:
powershellpip install --upgrade huggingface_hub -
下载模型到本地(建议放到简单路径,避免中文/空格):
powershell# 下载模型到 D:\models\Qwen3Guard-Gen-8B(可自定义路径) python -m huggingface_hub snapshot download Qwen/Qwen3Guard-Gen-8B --local-dir D:\models\Qwen3Guard-Gen-8B --local-dir-use-symlinks False # 此处我使用以下命令下载Qwen3Guard-Gen-8B模型,用于本机测试 hf download Qwen/Qwen3Guard-Gen-8B --local-dir "E:\AI_Model\Qwen\Qwen3Guard-Gen-8B"下载完成截图如下:
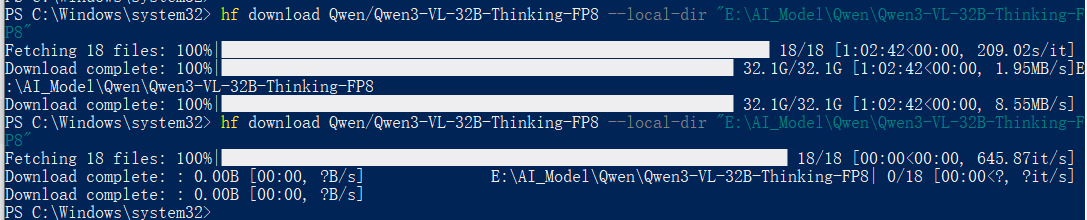
-
若下载慢,可配置 HF 镜像源(临时生效):
powershell$env:HUGGINGFACE_HUB_CACHE="D:\models\hf-cache" $env:HF_ENDPOINT="https://hf-mirror.com"
-
方式 2:手动下载(适合网络受限场景)
- 登录 Hugging Face 官网 Qwen3Guard-Gen-8B 仓库;
- 下载所有模型文件(
config.json、tokenizer.model、model.safetensors等); - 统一放到
D:\models\Qwen3Guard-Gen-8B目录下,确保文件完整。
步骤 2:验证模型文件
打开 D:\models\Qwen3Guard-Gen-8B,确认包含以下核心文件:
config.json(模型配置)tokenizer_config.json/tokenizer.model(分词器)model.safetensors(模型权重,可能分多个文件)
阶段 2:Win10 下用 Docker 启动 vLLM 服务(局域网可访问)
核心是让 vLLM 服务绑定局域网 IP,确保 Dify 能访问,同时适配 Windows 路径。
步骤 1:验证 Docker GPU 可用性
powershell
# 执行后输出显卡信息,说明 GPU 配置成功
docker run --rm --gpus all nvidia/cuda:12.1.0-base-ubuntu22.04 nvidia-smi拉取完成截图如下(此截图在Docker Desktop中完成):
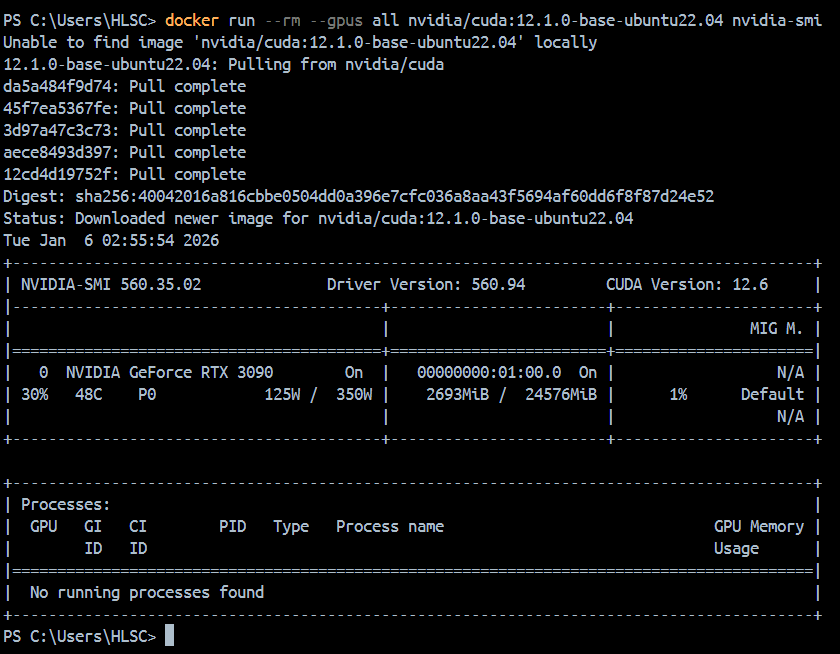
- 若报错,参考前文「Win10 Docker GPU 配置」修复。
步骤 2:启动 vLLM 服务(局域网版)
在 PowerShell 执行以下命令(关键:绑定 0.0.0.0 让局域网访问):
powershell
docker run --gpus all --shm-size 24g -p 0.0.0.0:8000:8000 `
# 映射 Windows 模型路径到容器(D:\models → /models)
-v /mnt/d/models/Qwen3Guard-Gen-8B:/models/Qwen3Guard-Gen-8B `
# vLLM 镜像(带 OpenAI 兼容 API)
vllm/vllm-openai:latest `
# 容器内模型路径
--model /models/Qwen3Guard-Gen-8B `
# Qwen 必须加:加载自定义代码
--trust-remote-code `
# 暴露的模型名称(Dify 需对应)
--served-model-name qwen3guard-gen-8b `
# Qwen3Guard 最大上下文长度(8192)
--max-model-len 8192 `
# 解决编码问题
--env LC_ALL=C.UTF-8 `
# 可选:限制显存使用(如 20G)
--gpu-memory-utilization 0.9 `
# 可选:添加 API 密钥(增强安全性)
--api-key your_secure_key_123关键参数说明:
-p 0.0.0.0:8000:8000:绑定所有网卡,局域网内其他设备可通过http://Win10主机IP:8000访问--shm-size 24g:8B 模型建议至少 24G 共享内存--api-key:可选,设置后 Dify 接入时需填写该密钥-v: 本地路径:容器内路径
拉取镜像中(如果命令有误,请及时在命令行中剔除注释再做镜像拉取):
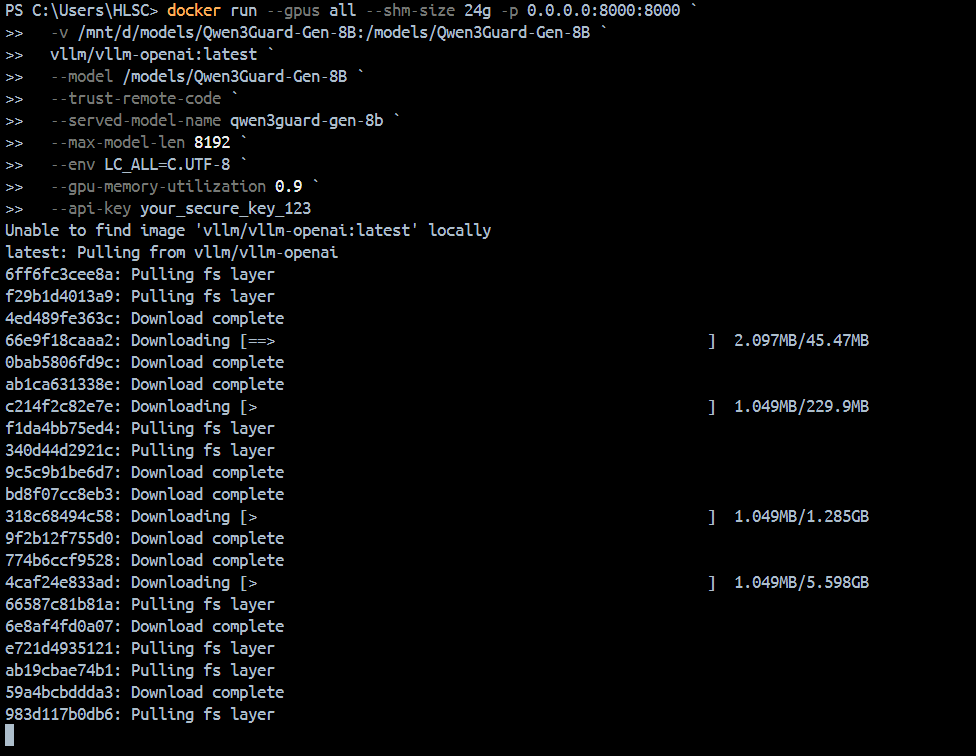
windows挂载本地绝对路径下的模型
docker run --gpus all --shm-size 24g -p 0.0.0.0:8000:8000 `
-v "E:/AI_Model/Qwen/Qwen3Guard-Gen-8B":/mnt/d/models/Qwen3Guard-Gen-8B `
vllm/vllm-openai:latest `
--model /models/Qwen3Guard-Gen-8B `
--trust-remote-code `
--served-model-name qwen3guard-gen-8b `
--max-model-len 8192 `
--env LC_ALL=C.UTF-8 `
--gpu-memory-utilization 0.9 `
--api-key your_secure_key_123- E:/AI_Model/Qwen/Qwen3Guard-Gen-8B为我的本地路径
- 本地路径转换:Windows 的反斜杠 \ 必须改成正斜杠 /,即 E:\AI_Model... → E:/AI_Model/...
- 挂载语法:-v 本地路径:容器内路径:权限,其中::rw 表示可读可写(默认也是 rw,可省略)如果只需要只读权限,可写 :ro
- Windows 路径需将 \ 替换为 /,挂载核心语法是 -v 本地路径:容器内路径;
- 必须在 Docker Desktop 中开启 E 盘的文件共享权限,否则挂载会提示无权限;
- 路径含空格时需用双引号包裹,本地目标文件夹必须提前存在。
步骤 3:验证 vLLM 服务(局域网可访问)
-
查看 Win10 主机的局域网 IP(如
192.168.1.101):powershellipconfig # 找到「以太网/WLAN」下的 IPv4 地址 -
测试 API(本地/局域网其他机器均可):
powershellcurl http://192.168.1.101:8000/v1/chat/completions ` -H "Content-Type: application/json" ` -H "Authorization: Bearer your_secure_key_123" ` # 若设置了 api-key 才需要 -d '{ "model": "qwen3guard-gen-8b", "messages": [{"role": "user", "content": "你好"}] }'
- 若返回 JSON 格式的回复,说明服务启动成功。
阶段 3:局域网内将模型接入 Dify
步骤 1:进入 Dify 模型配置
- 登录 Dify 后台(如
http://192.168.1.100:8000); - 点击「设置」→「模型配置」→「自定义模型」→「添加模型」。
步骤 2:填写 Qwen3Guard 模型信息
选择「OpenAI 兼容」模型类型,按以下配置填写:
| 配置项 | 填写内容 |
|---|---|
| 模型名称 | 自定义(如 Qwen3Guard-Gen-8B) |
| API 基础 URL | http://192.168.1.101:8000/v1(Win10 主机的局域网 IP + vLLM 端口) |
| API 密钥 | 若 vLLM 启动时设置了 --api-key,填对应的密钥(如 your_secure_key_123);无则留空 |
| 模型标识 | qwen3guard-gen-8b(必须和 vLLM 的 --served-model-name 一致) |
| 上下文窗口大小 | 8192(Qwen3Guard-Gen-8B 支持的最大长度) |
| 支持的模态 | 文本 |
步骤 3:测试连接并保存
- 点击「测试连接」,提示「连接成功」说明局域网内通信正常;
- 点击「保存」,模型会出现在 Dify 的模型列表中。
步骤 4:在 Dify 中使用模型
- 新建/打开 Dify 应用(如对话机器人);
- 进入「配置」→「模型设置」;
- 在「大语言模型」中选择
Qwen3Guard-Gen-8B; - 发布应用,即可在 Dify 中调用该模型。
阶段 4:常见问题排查(局域网场景重点)
- Dify 无法访问 vLLM 服务 :
- 检查 Win10 防火墙:放行 8000 端口(设置 → 网络和 Internet → 防火墙 → 高级设置 → 入站规则 → 新建规则,允许 8000 端口);
- 确认 Win10 主机和 Dify 主机在同一网段,且能互相 ping 通;
- 替换
192.168.1.101为localhost测试(仅限 Dify 和 vLLM 同主机)。
- 模型加载失败 :
- 确认模型路径映射正确(
/mnt/d/对应 D 盘,小写盘符); - 必须加
--trust-remote-code参数,Qwen 模型依赖自定义代码; - 检查模型文件是否完整(无缺失的
.safetensors文件)。
- 确认模型路径映射正确(
- 显存不足报错 :
- 降低
--gpu-memory-utilization(如改为 0.8); - 关闭其他占用 GPU 的程序(如浏览器、其他容器)。
- 降低
总结
- 局域网部署核心:vLLM 绑定
0.0.0.0并放行端口,确保 Dify 能访问 Win10 主机的 8000 端口; - 路径适配:Win10 本地路径
D:\xxx需转为 Docker 映射路径/mnt/d/xxx; - 关键参数:
--trust-remote-code是 Qwen 模型加载的必要条件,--served-model-name需和 Dify 模型标识一致。
按以上步骤操作后,就能在局域网内将 Qwen3Guard-Gen-8B 私有化部署并接入 Dify 正常使用了。