阿里云通义千问目前已经在Huggingface.co开源,提供对外下载。
Qwen3-Embedding(也常写作 Qwen-3-Embedding)是针对中文优化的高性能嵌入模型,从 Hugging Face 下载并本地部署的步骤如下,涵盖环境准备、模型下载、验证使用全流程:
一、前置条件
-
环境要求
- Python ≥ 3.8(推荐 3.9-3.11,避免版本兼容问题);
- 显卡(可选但推荐):NVIDIA GPU(显存 ≥ 8G,推理更高效),需安装 CUDA + cuDNN;
- 网络:可访问 Hugging Face Hub(国内需配置镜像或代理)。
-
依赖安装
先安装核心依赖包:bash# 基础依赖(模型加载+推理) pip install torch transformers sentence-transformers accelerate huggingface-hub # 可选:镜像加速(国内用户) pip install -i https://pypi.tuna.tsinghua.edu.cn/simple torch transformers
二、核心步骤:下载 Qwen3-Embedding 模型
Qwen3-Embedding 已开源在 Hugging Face,官方仓库:Qwen/Qwen3-Embedding(含不同尺寸版本,如 base/large)。
方式 1:通过 huggingface-hub 命令行下载(推荐)
适合手动下载模型文件到本地目录,方便后续部署:
bash
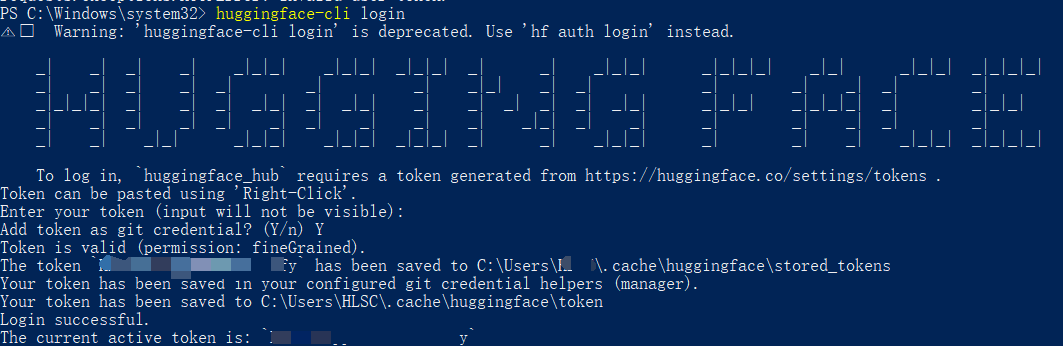
# 1. 登录 Hugging Face(需先注册账号,获取访问令牌)
huggingface-cli login
# 输入你的 Hugging Face Access Token(从 https://huggingface.co/settings/tokens 获取)
# 2. 下载模型到指定本地目录(如 ./qwen3-embedding)
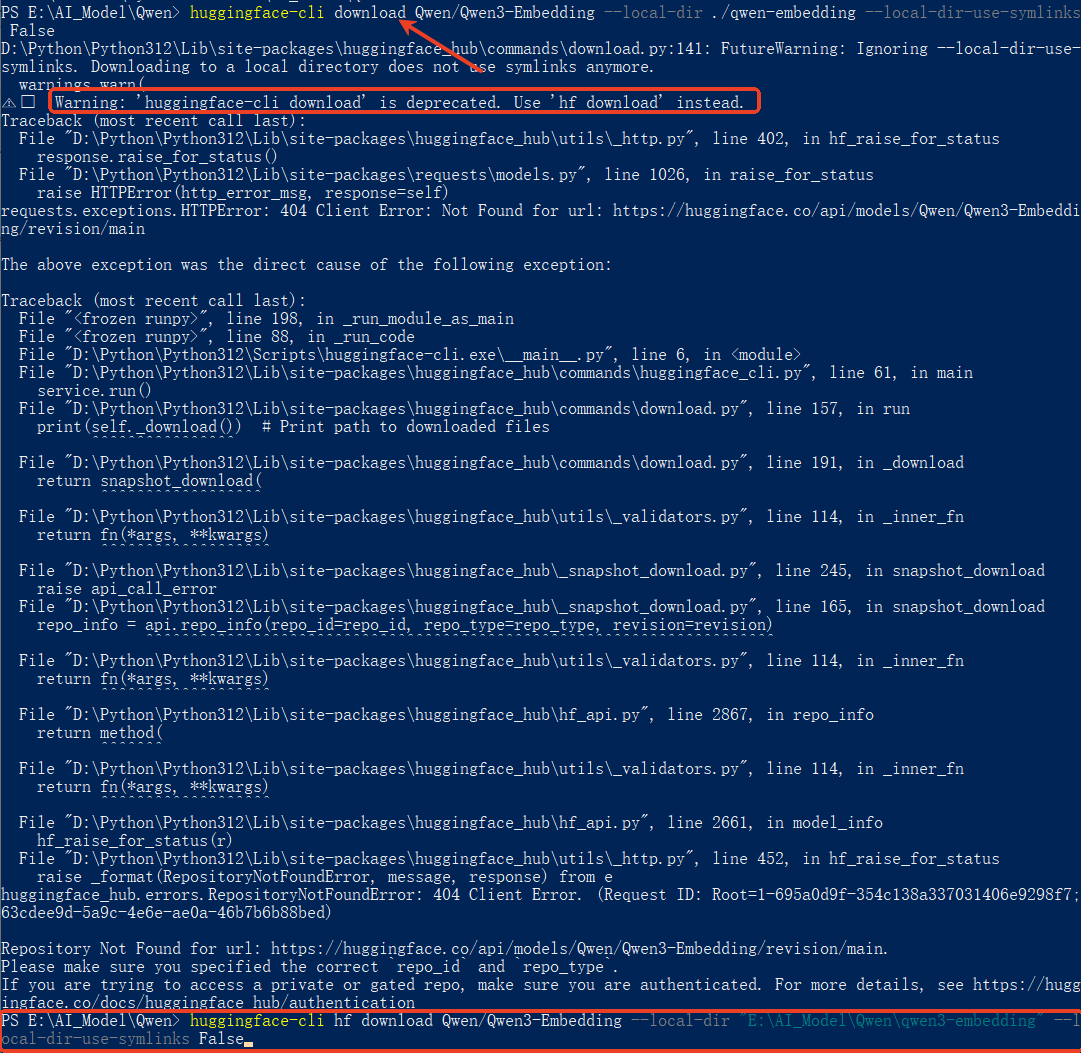
huggingface-cli download Qwen/Qwen3-Embedding --local-dir ./qwen3-embedding --local-dir-use-symlinks False-
参数说明:
-
--local-dir:指定模型保存路径; -
--local-dir-use-symlinks False:禁用符号链接,直接下载文件(避免跨系统问题)。 -
出现无法下载问题,参考下图提示,如果仍无法下载请使用另外一种方法。
- 配置国内镜像下载
临时配置(仅当前窗口有效)
$env:HF_ENDPOINT = "https://hf-mirror.com"
永久配置(写入系统环境变量,需重启终端)
[Environment]::SetEnvironmentVariable("HF_ENDPOINT", "https://hf-mirror.com", "User")
或者配置环境变量
HF_TOKEN为【你的token】,该信息在https://huggingface.co/settings/token中查找
HF_ENDPOINT为【https://hf_mirror.com】
-
-
Token添加成功示意:
-
检测登录信息
hf auth whoami
成功如下:

- 正常下载AI模型

方式 2:通过 Python 代码自动下载(运行时缓存)
适合代码中直接加载模型,Hugging Face 会自动下载并缓存到默认路径(~/.cache/huggingface/hub):
python
from transformers import AutoModel, AutoTokenizer
# 加载模型和分词器(首次运行自动下载,后续从缓存读取)
model_name = "Qwen/Qwen3-Embedding"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(
model_name,
torch_dtype=torch.float16, # 半精度,减少显存占用(GPU 推荐)
device_map="auto" # 自动分配到 GPU/CPU
)方式 3:国内镜像加速下载(解决访问慢/失败)
若直接访问 Hugging Face 超时,可配置镜像:
bash
# 临时配置(终端)
export HF_ENDPOINT=https://hf-mirror.com
# 永久配置(Linux/Mac):写入 ~/.bashrc 或 ~/.zshrc
echo "export HF_ENDPOINT=https://hf-mirror.com" >> ~/.bashrc
source ~/.bashrc
# Windows(PowerShell)
$env:HF_ENDPOINT = "https://hf-mirror.com"
# 之后再执行下载命令(方式1/2)即可走镜像三、验证模型下载与使用
下载完成后,可通过代码验证模型是否能正常生成嵌入向量:
python
import torch
from transformers import AutoModel, AutoTokenizer
# 加载本地模型(方式1下载的路径)
model_path = "./qwen3-embedding" # 若用方式2,直接填 "Qwen/Qwen3-Embedding"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModel.from_pretrained(
model_path,
torch_dtype=torch.float16,
device_map="auto"
)
# 文本向量化函数(遵循Qwen官方推荐的归一化+均值池化)
def get_qwen_embedding(text):
# 预处理:Qwen-Embedding 建议添加前缀(官方优化)
input_text = f"textembedding: {text}"
inputs = tokenizer(
input_text,
return_tensors="pt",
padding=True,
truncation=True,
max_length=8192 # Qwen3-Embedding 最大上下文8192
).to(model.device) # 移到模型所在设备(GPU/CPU)
# 推理
with torch.no_grad():
outputs = model(**inputs)
# 均值池化(CLS token 效果不如均值池化)
last_hidden_state = outputs.last_hidden_state
mask = inputs.attention_mask.unsqueeze(-1).expand(last_hidden_state.size())
sum_embeddings = torch.sum(last_hidden_state * mask, dim=1)
sum_mask = torch.clamp(mask.sum(1), min=1e-9)
embeddings = sum_embeddings / sum_mask
# 归一化(必须,否则影响检索效果)
embeddings = torch.nn.functional.normalize(embeddings, p=2, dim=1)
# 转为列表返回
return embeddings.cpu().numpy()[0].tolist()
# 测试
text = "Dify 配置 Embedding 模型的步骤"
embedding = get_qwen_embedding(text)
print(f"嵌入向量维度:{len(embedding)}") # Qwen3-Embedding 输出 1536 维
print(f"向量前5位:{embedding[:5]}")四、对接 Dify(适配 OpenAI 接口)
若要将 Qwen3-Embedding 接入 Dify,需封装为 OpenAI 兼容的 Embedding 接口,步骤如下:
步骤 1:编写 FastAPI 接口
python
from fastapi import FastAPI
from pydantic import BaseModel
import torch
from transformers import AutoModel, AutoTokenizer
# 初始化 FastAPI
app = FastAPI()
# 加载 Qwen3-Embedding 模型
model_path = "./qwen3-embedding"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModel.from_pretrained(
model_path,
torch_dtype=torch.float16,
device_map="auto"
)
# 定义请求体
class EmbeddingRequest(BaseModel):
input: list[str]
model: str = "Qwen3-Embedding"
# 封装向量化函数(批量处理)
def batch_embedding(texts):
# 预处理:添加官方前缀
input_texts = [f"textembedding: {text}" for text in texts]
inputs = tokenizer(
input_texts,
return_tensors="pt",
padding=True,
truncation=True,
max_length=8192
).to(model.device)
with torch.no_grad():
outputs = model(**inputs)
# 均值池化 + 归一化
last_hidden_state = outputs.last_hidden_state
mask = inputs.attention_mask.unsqueeze(-1).expand(last_hidden_state.size())
sum_embeddings = torch.sum(last_hidden_state * mask, dim=1)
sum_mask = torch.clamp(mask.sum(1), min=1e-9)
embeddings = sum_embeddings / sum_mask
embeddings = torch.nn.functional.normalize(embeddings, p=2, dim=1)
return embeddings.cpu().numpy().tolist()
# OpenAI 兼容接口
@app.post("/v1/embeddings")
def embeddings(request: EmbeddingRequest):
embeddings = batch_embedding(request.input)
return {
"object": "list",
"data": [
{"object": "embedding", "embedding": emb, "index": i}
for i, emb in enumerate(embeddings)
],
"model": request.model,
"usage": {
"prompt_tokens": sum(len(tokenizer.encode(text)) for text in request.input),
"total_tokens": sum(len(tokenizer.encode(text)) for text in request.input)
}
}
# 启动服务(端口 8082)
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8082)步骤 2:Dify 中配置
-
启动上述接口服务(
python qwen_embedding_api.py); -
登录 Dify 后台 → 「设置」→「模型配置」→「Embedding 模型」→「添加模型」;
-
选择「OpenAI Embedding」,填写参数:
参数名 取值 模型名称 自定义(如:Qwen3-Embedding) API Base URL http://<服务器IP>:8082/v1API Key 随意填写(如 dummy-key,无需鉴权) 模型 ID Qwen3-Embedding(需与接口一致) -
点击「测试连接」,成功后保存,即可在 Dify 应用中选择该模型。
五、注意事项
- 显存优化 :
-
GPU 显存 < 10G:使用
torch.float16(半精度),或开启 4-bit 量化:pythonmodel = AutoModel.from_pretrained( model_path, torch_dtype=torch.float16, device_map="auto", load_in_4bit=True, # 4-bit 量化 bnb_4bit_quant_type="nf4", bnb_4bit_compute_dtype=torch.float16 ) -
无 GPU:使用 CPU 推理(速度较慢,仅测试用),移除
torch_dtype和device_map参数。
-
- 官方最佳实践 :
- Qwen3-Embedding 必须添加前缀
textembedding:,否则效果大幅下降; - 必须对输出向量做 L2 归一化(
torch.nn.functional.normalize),确保检索时余弦相似度计算准确。
- Qwen3-Embedding 必须添加前缀
- 模型版本 :
- 若需更轻量化版本,可选择
Qwen/Qwen3-Embedding-Base(base 版,速度更快,效果略降)。
- 若需更轻量化版本,可选择
通过以上步骤,即可完成 Qwen3-Embedding 模型的下载、验证及 Dify 集成,适配中文场景的高性能文本向量化需求。
存在任何问题请随时与我联系。
我的email:code_captain@163.com