摘要
本文将详细介绍如何使用腾讯混元(Hunyuan)模型进行本地部署,包括从模型下载到API服务封装的完整流程。我们将使用ModelScope SDK下载腾讯混元HY-MT1.5-1.8B模型,并利用FastAPI将其封装为OpenAI兼容的API接口,实现本地化的AI服务。

1. 引言
随着大语言模型技术的发展,越来越多的企业和个人开始关注如何将这些强大的AI能力部署到自己的环境中。腾讯混元(Hunyuan)作为腾讯推出的大规模语言模型,在多个领域展现出了卓越的能力。本文将带你一步步实现混元模型的本地部署,让你能够完全掌控模型的使用,保护数据隐私,同时享受高效的AI推理服务。
2. 环境准备
在开始之前,请确保安装以下依赖:
bash
pip install modelscope transformers torch fastapi uvicorn3. 模型下载 - d.py
首先,我们需要从ModelScope平台下载腾讯混元模型。以下是完整代码:
python
from modelscope import snapshot_download
model_dir = snapshot_download(
model_id="Tencent-Hunyuan/HY-MT1.5-1.8B",
cache_dir="./models"
)
print("模型下载到:", model_dir)代码解析:
- 导入ModelScope的
snapshot_download函数 - 指定模型ID为
Tencent-Hunyuan/HY-MT1.5-1.8B,这是腾讯混元的一个版本 - 设置缓存目录为
./models,模型将被下载到该目录下 - 打印模型下载路径
运行此脚本后,混元模型将被下载到本地,为后续的API服务提供支持。
4. API服务封装 - hunyuan_api2.py
接下来是最重要的部分------将本地模型封装为API服务。hunyuan_api2.py实现了这一功能:
python
from fastapi import FastAPI, Request
from fastapi.responses import StreamingResponse
from transformers import (
AutoTokenizer,
AutoModelForCausalLM,
TextIteratorStreamer
)
import torch
import threading
import json
import time
app = FastAPI()
MODEL_PATH = "./models/Tencent-Hunyuan/HY-MT1.5-1.8B"
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
MODEL_PATH,
device_map="auto",
torch_dtype=torch.float16,
trust_remote_code=True
)
@app.get("/v1/models")
async def list_models():
return {
"object": "list",
"data": [
{
"id": "local-hunyuan",
"object": "model",
"created": 1677610602,
"owned_by": "local"
}
]
}
@app.post("/v1/chat/completions")
async def chat_completions(request: Request):
body = await request.json()
messages = body.get("messages", [])
stream = body.get("stream", True)
max_tokens = body.get("max_new_tokens", body.get("max_tokens", 512))
temperature = body.get("temperature", 0.7)
top_p = body.get("top_p", 0.95)
do_sample = temperature > 0.01
current_time = int(time.time())
chat_id = f"chatcmpl-local-{current_time}"
input_ids = tokenizer.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_tensors="pt"
).to(model.device)
prompt_tokens = input_ids.shape[1]
# ---------- 非流式 ----------
if not stream:
outputs = model.generate(
input_ids,
max_new_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
do_sample=do_sample,
pad_token_id=tokenizer.eos_token_id
)
response_ids = outputs[0][input_ids.shape[1]:]
text = tokenizer.decode(response_ids, skip_special_tokens=True)
completion_tokens = response_ids.shape[0]
return {
"id": chat_id,
"object": "chat.completion",
"created": current_time,
"model": "local-hunyuan",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": text
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": prompt_tokens,
"completion_tokens": completion_tokens,
"total_tokens": prompt_tokens + completion_tokens
}
}
# ---------- 流式 ----------
streamer = TextIteratorStreamer(
tokenizer,
skip_prompt=True,
skip_special_tokens=True
)
def generate():
model.generate(
input_ids,
max_new_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
do_sample=do_sample,
streamer=streamer,
pad_token_id=tokenizer.eos_token_id
)
threading.Thread(target=generate).start()
def sse():
# 第一包:发送 role(定义成变量,避免嵌套语法问题)
role_payload = {
"id": chat_id,
"object": "chat.completion.chunk",
"created": current_time,
"model": "local-hunyuan",
"choices": [
{
"index": 0,
"delta": {"role": "assistant", "content": ""}
}
]
}
yield f"data: {json.dumps(role_payload, ensure_ascii=False)}\n\n"
# 后续 token
token_payload_base = {
"choices": [
{
"index": 0,
"delta": {}
}
]
}
for token in streamer:
token_payload = token_payload_base.copy()
token_payload["choices"][0]["delta"]["content"] = token
yield f"data: {json.dumps(token_payload, ensure_ascii=False)}\n\n"
# 结束包
finish_payload = {
"id": chat_id,
"object": "chat.completion.chunk",
"created": current_time,
"model": "local-hunyuan",
"choices": [
{
"index": 0,
"delta": {},
"finish_reason": "stop"
}
]
}
yield f"data: {json.dumps(finish_payload, ensure_ascii=False)}\n\n"
yield "data: [DONE]\n\n"
return StreamingResponse(sse(), media_type="text/event-stream")代码详细解析:
4.1 初始化部分
python
MODEL_PATH = "./models/Tencent-Hunyuan/HY-MT1.5-1.8B"
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
MODEL_PATH,
device_map="auto",
torch_dtype=torch.float16,
trust_remote_code=True
)- 加载预训练的分词器和模型
- 使用
device_map="auto"自动分配设备 - 使用
torch.float16减少内存占用 trust_remote_code=True允许加载自定义代码
4.2 模型列表接口
python
@app.get("/v1/models")
async def list_models():
# 返回可用模型列表此接口返回当前部署的模型信息,符合OpenAI API规范。
4.3 聊天补全接口
python
@app.post("/v1/chat/completions")
async def chat_completions(request: Request):这是核心接口,支持两种模式:
- 非流式模式:一次性返回完整回复
- 流式模式:实时返回token,提供更好的用户体验
4.4 流式传输实现
流式传输使用TextIteratorStreamer和多线程技术,确保响应能够实时传输给客户端。
5. 启动API服务
保存以上代码后,可以通过以下命令启动服务:
bash
uvicorn hunyuan_api2:app --host 0.0.0.0 --port 8000服务启动后,你就可以通过HTTP请求访问本地部署的混元模型了。
6. 调用示例
启动服务后,可以使用以下代码测试API:
python
import requests
url = "http://localhost:8000/v1/chat/completions"
headers = {
"Content-Type": "application/json"
}
data = {
"messages": [
{"role": "user", "content": "你好,请介绍一下你自己"}
],
"stream": False,
"temperature": 0.7
}
response = requests.post(url, headers=headers, json=data)
print(response.json())7. 优势与应用场景
dify中使用安装插件
https://marketplace.dify.ai/plugins/langgenius/openai_api_compatible
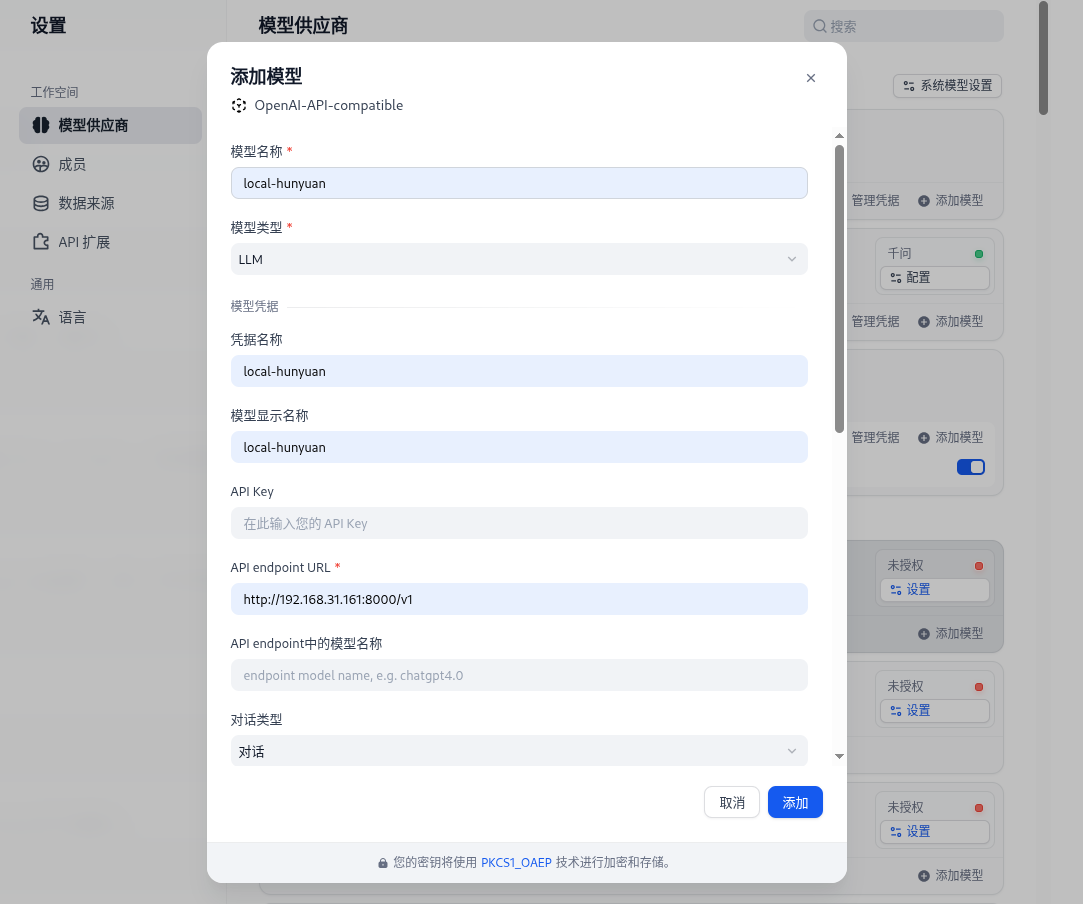
优势:
- 数据安全:所有数据都在本地处理,无需上传到云端
- 成本效益:一次部署,长期使用,无额外费用
- 定制化:可以根据需要调整模型参数
- 低延迟:本地推理,响应速度快
应用场景:
- 企业内部知识库问答系统
- 私有文档智能分析工具
- 数据脱敏和隐私保护场景
- 离线AI助手应用
8. 性能优化建议
- 显存优化:使用量化技术进一步减少显存占用
- 批处理:对多个请求进行批处理提高吞吐量
- 缓存机制:对常见查询结果进行缓存
- 负载均衡:部署多个实例处理高并发请求
9. 总结
本文详细介绍了如何将腾讯混元模型部署到本地,并封装为API服务。通过d.py下载模型,再通过hunyuan_api2.py构建API服务,我们成功实现了本地化的AI推理能力。这种部署方式不仅保证了数据的安全性,还提供了灵活的定制能力,适合多种实际应用场景。
本地部署大模型虽然需要一定的硬件资源,但随着技术的发展,越来越多的优化方案使得普通用户也能享受到大模型带来的便利。希望本文能帮助你成功部署属于自己的AI服务!